
Leaderboard

Popular Content
Showing content with the highest reputation since 05/27/13 in all areas
-
 To start, while new to DrivePool I love its potential I own multiple licenses and their full suite. If you only use drivepool for basic file archiving of large files with simple applications accessing them for periodic reads it is probably uncommon you would hit these bugs. This assumes you don't use any file synchronization / backup solutions. Further, I don't know how many thousands (tens or hundreds?) of DrivePool users there are, but clearly many are not hitting these bugs or recognizing they are hitting these bugs, so this IT NOT some new destructive my files are 100% going to die issue. Some of the reports I have seen on the forums though may be actually issues due to these things without it being recognized as such. As far as I know previously CoveCube was not aware of these issues, so tickets may not have even considered this possibility. I started reporting these bugs to StableBit ~9 months ago, and informed I would be putting this post together ~1 month ago. Please see the disclaimer below as well, as some of this is based on observations over known facts. You are most likely to run into these bugs with applications that: *) Synchronize or backup files, including cloud mounted drives like onedrive or dropbox *) Applications that must handle large quantities of files or monitor them for changes like coding applications (Visual Studio/ VSCode) Still, these bugs can cause silent file corruption, file misplacement, deleted files, performance degradation, data leakage ( a file shared with someone externally could have its contents overwritten by any sensitive file on your computer), missed file changes, and potential other issues for a small portion of users (I have had nearly all these things occur). It may also trigger some BSOD crashes, I had one such crash that is likely related. Due to the subtle nature some of these bugs can present with, it may be hard to notice they are happening even if they are. In addition, these issues can occur even without file mirroring and files pinned to a specific drive. I do have some potential workarounds/suggestions at the bottom. More details are at the bottom but the important bug facts upfront: Windows has a native file changed notification API using overlapped IO calls. This allows an application to listen for changes on a folder, or a folder and sub folders, without having to constantly check every file to see if it changed. Stablebit triggers "file changed" notifications even when files are just accessed (read) in certain ways. Stablebit does NOT generate notification events on the parent folder when a file under it changes (Windows does). Stablebit does NOT generate a notification event only when a FileID changes (next bug talks about FileIDs). Windows, like linux, has a unique ID number for each file written on the hard drive. If there are hardlinks to the same file, it has the same unique ID (so one File ID may have multiple paths associated with it). In linux this is called the inode number, Windows calls it the FileID. Rather than accessing a file by its path, you can open a file by its FileID. In addition it is impossible for two files to share the same FileID, it is a 128 bit number persistent across reboots (128 bits means the number of unique numbers represented is 39 digits long, or has the uniqueness of something like the MD5 hash). A FileID does not change when a file moves or is modified. Stablebit, by default, supports FileIDs however they seem to be ephemeral, they do not seem to survive across reboots or file moves. Keep in mind FileIDs are used for directories as well, it is not just files. Further, if a directory is moved/renamed not only does its FileID change but every file under it changes. I am not sure if there are other situations in which they may change. In addition, if a descendant file/directory FileID changes due to something like a directory rename Stablebit does NOT generate a notification event that it has changed (the application gets the directory event notification but nothing on the children). There are some other things to consider as well, DrivePool does not implement the standard windows USN Journal (a system of tracking file changes on a drive). It specifically identifies itself as not supporting this so applications shouldn't be trying to use it with a drivepool drive. That does mean that applications that traditionally don't use the file change notification API or the FileIDs may fall back to a combination of those to accomplish what they would otherwise use the USN Journal for (and this can exacerbate the problem). The same is true of Volume Shadow Copy (VSS) where applications that might traditionally use this cannot (and drivepool identifies it cannot do VSS) so may resort to methods below that they do not traditionally use. Now the effects of the above bugs may not be completely apparent: For the overlapped IO / File change notification This means an application monitoring for changes on a DrivePool folder or sub-folder will get erroneous notifications files changed when anything even accesses them. Just opening something like file explorer on a folder, or even switching between applications can cause file accesses that trigger the notification. If an application takes actions on a notification and then checks the file at the end of the notification this in itself may cause another notification. Applications that rely on getting a folder changed notification when a child changes will not get these at all with DrivePool. If it isn't monitoring children at all just the folder, this means no notifications could be generated (vs just the child) so it could miss changes. For FileIDs It depends what the application uses the FileID for but it may assume the FileID should stay the same when a file moves, as it doesn't with DrivePool this might mean it reads or backs up, or syncs the entire file again if it is moved (perf issue). An application that uses the Windows API to open a File by its ID may not get the file it is expecting or the file that was simply moved will throw an error when opened by its old FileID as drivepool has changed the ID. For an example lets say an application caches that the FileID for ImportantDoc1.docx is 12345 but then 12345 refers to ImportantDoc2.docx due to a restart. If this application is a file sync application and ImportantDoc1.docx is changed remotely when it goes to write those remote changes to the local file if it uses the OpenFileById method to do so it will actually override ImportantDoc2.docx with those changes. I didn't spend the time to read Windows file system requirements to know when Windows expects a FileID to potentially change (or not change). It is important to note that even if theoretical changes/reuse are allowed if they are not common place (because windows uses essentially a number like an md5 hash in terms of repeats) applications may just assume it doesn't happen even if it is technically allowed to do so. A backup of file sync program might assume that a file with specific FileID is always the same file, if FileID 12345 is c:\MyDocuments\ImportantDoc1.docx one day and then c:\MyDocuments\ImportantDoc2.docx another it may mistake document 2 for document 1, overriding important data or restore data to the wrong place. If it is trying to create a whole drive backup it may assume it has already backed up c:\MyDocuments\ImportantDoc2.docx if it now has the same File ID as ImportantDoc1.docx by the time it reaches it (at which point DrivePool would have a different FileID for Document1). Why might applications use FileIDs or file change notifiers? It may not seem intuitive why applications would use these but a few major reasons are: *) Performance, file change notifiers are a event/push based system so the application is told when something changes, the common alternative is a poll based system where an application must scan all the files looking for changes (and may try to rely on file timestamps or even hashing the entire file to determine this) this causes a good bit more overhead / slowdown. *) FileID's are nice because they already handle hardlink file de-duplication (Windows may have multiple copies of a file on a drive for various reasons, but if you backup based on FileID you backup that file once rather than multiple times. FileIDs are also great for handling renames. Lets say you are an application that syncs files and the user backs up c:\temp\mydir with 1000 files under it. If they rename c:\temp\mydir to c:\temp\mydir2 an application use FileIDS can say, wait that folder is the same it was just renamed. OK rename that folder in our remote version too. This is a very minimal operation on both ends. With DrivePool however the FileID changes for the directory and all sub-files. If the sync application uses this to determine changes it now uploads all these files to the system using a good bit more resources locally and remotely. If the application also uses versioning this may be far more likely to cause a conflict with two or more clients syncing, as mass amounts of files are seemingly being changed. Finally, even if an application is trying to monitor for FileIDs changing using the file change API, due to notification bugs above it may not get any notifications when child FileIDs change so it might assume it has not. Real Examples OneDrive This started with massive onedrive failures. I would find onedrive was re-uploading hundreds of gigabytes of images an videos multiple times a week. These were not changing or moving. I don't know if the issue is onedrive uses FileIDs to determine if a file is already uploaded, or if it is because when it scanned a directory it may have triggered a notification that all the files in that directory changed and based on that notification it reuploads. After this I noticed files were becoming deleted both locally and in the cloud. I don't know what caused this, it might have been because the old file it thought was deleted as the FileID was gone and while there was a new file (actually the same file) in its place there may have been some odd race condition. It is also possible that it queued the file for upload, the FileID changed and when it went to open it to upload it found it was 'deleted' as the FileID no longer pointed to a file and queued the delete operation. I also found that files that were uploaded into the cloud in one folder were sometimes downloading to an alternate folder locally. I am guessing this is because the folder FileID changed. It thought the 2023 folder was with ID XYZ but that now pointed to a different folder and so it put the file in the wrong place. The final form of corruption was finding the data from one photo or video actually in a file with a completely different name. This is almost guaranteed to be due to the FileID bugs. This is highly destructive as backups make this far harder to correct. With one files contents replaced with another you need to know when the good content existed and in what files were effected. Depending on retention policies the file contents that replaced it may override the good backups before you notice. I also had a BSOD with onedrive where it was trying to set attributes on a file and the CoveFS driver corrupted some memory. It is possible this was a race condition as onedrive may have been doing hundreds of files very rapidly due to the bugs. I have not captured a second BSOD due to it, but also stopped using onedrive on DrivePool due to the corruption. Another example of this is data leakage. Lets say you share your favorite article on kittens with a group of people. Onedrive, believing that file has changed, goes to open it using the FileID however that file ID could essentially now correspond to any file on your computer now the contents of some sensitive file are put in the place of that kitten file, and everyone you shared it with can access it. Visual Studio Failures Visual studio is a code editor/compiler. There are three distinct bugs that happen. First, when compiling if you touched one file in a folder it seemed to recompile the entire folder, this due likely to the notification bug. This is just a slow down, but an annoying one. Second, Visual Studio has compiler generated code support. This means the compiler will generate actual source code that lives next to your own source code. Normally once compiled it doesn't regenerate and compile this source unless it must change but due to the notification bugs it regenerates this code constantly and if there is an error in other code it causes an error there causing several other invalid errors. When debugging visual studio by default will only use symbols (debug location data) as the notifications from DrivePool happen on certain file accesses visual studio constantly thinks the source has changed since it was compiled and you will only be able to breakpoint inside source if you disable the exact symbol match default. If you have multiple projects in a solution with one dependent on another it will often rebuild other project deps even when they haven't changed, for large solutions that can be crippling (perf issue). Finally I often had intellisense errors showing up even though no errors during compiling, and worse intellisense would completely break at points. All due to DrivePool. Technical details / full background & disclaimer I have sample code and logs to document these issues in greater detail if anyone wants to replicate it themselves. It is important for me to state drivepool is closed source and I don't have the technical details of how it works. I also don't have the technical details on how applications like onedrive or visual studio work. So some of these things may be guesses as to why the applications fail/etc. The facts stated are true (to the best of my knowledge) Shortly before my trial expired in October of last year I discovered some odd behavior. I had a technical ticket filed within a week and within a month had traced down at least one of the bugs. The issue can be seen https://stablebit.com/Admin/IssueAnalysis/28720 , it does show priority 2/important which I would assume is the second highest (probably critical or similar above). It is great it has priority but as we are over 6 months since filed without updates I figured warning others about the potential corruption was important. The FileSystemWatcher API is implemented in windows using async overlapped IO the exact code can be seen: https://github.com/dotnet/runtime/blob/57bfe474518ab5b7cfe6bf7424a79ce3af9d6657/src/libraries/System.IO.FileSystem.Watcher/src/System/IO/FileSystemWatcher.Win32.cs#L32-L66 That corresponds to this kernel api: https://learn.microsoft.com/en-us/windows/win32/fileio/synchronous-and-asynchronous-i-o Newer api calls use GetFileInformationByHandleEx to get the FileID but with older stats calls represented by nFileIndexHigh/nFileIndexLow. In terms of the FileID bug I wouldn't normally have even thought about it but the advanced config (https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings) mentions this under CoveFs_OpenByFileId "When enabled, the pool will keep track of every file ID that it gives out in pageable memory (memory that is saved to disk and loaded as necessary).". Keeping track of files in memory is certainly very different from Windows so I thought this may be the source of issue. I also don't know if there are caps on the maximum number of files it will track as if it resets FileIDs in situations other than reboots that could be much worse. Turning this off will atleast break nfs servers as it mentions it right in the docs "required by the NFS server". Finally, the FileID numbers given out by DrivePool are incremental and very low. This means when they do reset you almost certainly will get collisions with former numbers. What is not clear is if there is the chance of potential FileID corruption issues. If when it is assigning these ids in a multi-threaded scenario with many different files at the same time could this system fail? I have seen no proof this happens, but when incremental ids are assigned like this for mass quantities of potential files it has a higher chance of occurring. Microsoft mentions this about deleting the USN Journal: "Deleting the change journal impacts the File Replication Service (FRS) and the Indexing Service, because it requires these services to perform a complete (and time-consuming) scan of the volume. This in turn negatively impacts FRS SYSVOL replication and replication between DFS link alternates while the volume is being rescanned.". Now DrivePool never has the USN journal supported so it isn't exactly the same thing, but it is clear that several core Windows services do use it for normal operations I do not know what backups they use when it is unavailable. Potential Fixes There are advanced settings for drivepool https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings beware these changes may break other things. CoveFs_OpenByFileId - Set to false, by default it is true. This will disable the OpenByFileID API. It is clear several applications use this API. In addition, while DrivePool may disable that function with this setting it doesn't disable FileID's themselves. Any application using FileIDs as static identifiers for files may still run into problems. I would avoid any file backup/synchronization tools and DrivePool drives (if possible). These likely have the highest chance of lost files, misplaced files, file content being mixed up, and excess resource usage. If not avoiding consider taking file hashes for the entire drivepool directory tree. Do this again at a later point and make sure files that shouldn't have changed still have the same hash. If you have files that rarely change after being created then hashing each file at some point after creation and alerting if that file disappears or hash changes would easily act as an early warning to a bug here being hit.8 points
To start, while new to DrivePool I love its potential I own multiple licenses and their full suite. If you only use drivepool for basic file archiving of large files with simple applications accessing them for periodic reads it is probably uncommon you would hit these bugs. This assumes you don't use any file synchronization / backup solutions. Further, I don't know how many thousands (tens or hundreds?) of DrivePool users there are, but clearly many are not hitting these bugs or recognizing they are hitting these bugs, so this IT NOT some new destructive my files are 100% going to die issue. Some of the reports I have seen on the forums though may be actually issues due to these things without it being recognized as such. As far as I know previously CoveCube was not aware of these issues, so tickets may not have even considered this possibility. I started reporting these bugs to StableBit ~9 months ago, and informed I would be putting this post together ~1 month ago. Please see the disclaimer below as well, as some of this is based on observations over known facts. You are most likely to run into these bugs with applications that: *) Synchronize or backup files, including cloud mounted drives like onedrive or dropbox *) Applications that must handle large quantities of files or monitor them for changes like coding applications (Visual Studio/ VSCode) Still, these bugs can cause silent file corruption, file misplacement, deleted files, performance degradation, data leakage ( a file shared with someone externally could have its contents overwritten by any sensitive file on your computer), missed file changes, and potential other issues for a small portion of users (I have had nearly all these things occur). It may also trigger some BSOD crashes, I had one such crash that is likely related. Due to the subtle nature some of these bugs can present with, it may be hard to notice they are happening even if they are. In addition, these issues can occur even without file mirroring and files pinned to a specific drive. I do have some potential workarounds/suggestions at the bottom. More details are at the bottom but the important bug facts upfront: Windows has a native file changed notification API using overlapped IO calls. This allows an application to listen for changes on a folder, or a folder and sub folders, without having to constantly check every file to see if it changed. Stablebit triggers "file changed" notifications even when files are just accessed (read) in certain ways. Stablebit does NOT generate notification events on the parent folder when a file under it changes (Windows does). Stablebit does NOT generate a notification event only when a FileID changes (next bug talks about FileIDs). Windows, like linux, has a unique ID number for each file written on the hard drive. If there are hardlinks to the same file, it has the same unique ID (so one File ID may have multiple paths associated with it). In linux this is called the inode number, Windows calls it the FileID. Rather than accessing a file by its path, you can open a file by its FileID. In addition it is impossible for two files to share the same FileID, it is a 128 bit number persistent across reboots (128 bits means the number of unique numbers represented is 39 digits long, or has the uniqueness of something like the MD5 hash). A FileID does not change when a file moves or is modified. Stablebit, by default, supports FileIDs however they seem to be ephemeral, they do not seem to survive across reboots or file moves. Keep in mind FileIDs are used for directories as well, it is not just files. Further, if a directory is moved/renamed not only does its FileID change but every file under it changes. I am not sure if there are other situations in which they may change. In addition, if a descendant file/directory FileID changes due to something like a directory rename Stablebit does NOT generate a notification event that it has changed (the application gets the directory event notification but nothing on the children). There are some other things to consider as well, DrivePool does not implement the standard windows USN Journal (a system of tracking file changes on a drive). It specifically identifies itself as not supporting this so applications shouldn't be trying to use it with a drivepool drive. That does mean that applications that traditionally don't use the file change notification API or the FileIDs may fall back to a combination of those to accomplish what they would otherwise use the USN Journal for (and this can exacerbate the problem). The same is true of Volume Shadow Copy (VSS) where applications that might traditionally use this cannot (and drivepool identifies it cannot do VSS) so may resort to methods below that they do not traditionally use. Now the effects of the above bugs may not be completely apparent: For the overlapped IO / File change notification This means an application monitoring for changes on a DrivePool folder or sub-folder will get erroneous notifications files changed when anything even accesses them. Just opening something like file explorer on a folder, or even switching between applications can cause file accesses that trigger the notification. If an application takes actions on a notification and then checks the file at the end of the notification this in itself may cause another notification. Applications that rely on getting a folder changed notification when a child changes will not get these at all with DrivePool. If it isn't monitoring children at all just the folder, this means no notifications could be generated (vs just the child) so it could miss changes. For FileIDs It depends what the application uses the FileID for but it may assume the FileID should stay the same when a file moves, as it doesn't with DrivePool this might mean it reads or backs up, or syncs the entire file again if it is moved (perf issue). An application that uses the Windows API to open a File by its ID may not get the file it is expecting or the file that was simply moved will throw an error when opened by its old FileID as drivepool has changed the ID. For an example lets say an application caches that the FileID for ImportantDoc1.docx is 12345 but then 12345 refers to ImportantDoc2.docx due to a restart. If this application is a file sync application and ImportantDoc1.docx is changed remotely when it goes to write those remote changes to the local file if it uses the OpenFileById method to do so it will actually override ImportantDoc2.docx with those changes. I didn't spend the time to read Windows file system requirements to know when Windows expects a FileID to potentially change (or not change). It is important to note that even if theoretical changes/reuse are allowed if they are not common place (because windows uses essentially a number like an md5 hash in terms of repeats) applications may just assume it doesn't happen even if it is technically allowed to do so. A backup of file sync program might assume that a file with specific FileID is always the same file, if FileID 12345 is c:\MyDocuments\ImportantDoc1.docx one day and then c:\MyDocuments\ImportantDoc2.docx another it may mistake document 2 for document 1, overriding important data or restore data to the wrong place. If it is trying to create a whole drive backup it may assume it has already backed up c:\MyDocuments\ImportantDoc2.docx if it now has the same File ID as ImportantDoc1.docx by the time it reaches it (at which point DrivePool would have a different FileID for Document1). Why might applications use FileIDs or file change notifiers? It may not seem intuitive why applications would use these but a few major reasons are: *) Performance, file change notifiers are a event/push based system so the application is told when something changes, the common alternative is a poll based system where an application must scan all the files looking for changes (and may try to rely on file timestamps or even hashing the entire file to determine this) this causes a good bit more overhead / slowdown. *) FileID's are nice because they already handle hardlink file de-duplication (Windows may have multiple copies of a file on a drive for various reasons, but if you backup based on FileID you backup that file once rather than multiple times. FileIDs are also great for handling renames. Lets say you are an application that syncs files and the user backs up c:\temp\mydir with 1000 files under it. If they rename c:\temp\mydir to c:\temp\mydir2 an application use FileIDS can say, wait that folder is the same it was just renamed. OK rename that folder in our remote version too. This is a very minimal operation on both ends. With DrivePool however the FileID changes for the directory and all sub-files. If the sync application uses this to determine changes it now uploads all these files to the system using a good bit more resources locally and remotely. If the application also uses versioning this may be far more likely to cause a conflict with two or more clients syncing, as mass amounts of files are seemingly being changed. Finally, even if an application is trying to monitor for FileIDs changing using the file change API, due to notification bugs above it may not get any notifications when child FileIDs change so it might assume it has not. Real Examples OneDrive This started with massive onedrive failures. I would find onedrive was re-uploading hundreds of gigabytes of images an videos multiple times a week. These were not changing or moving. I don't know if the issue is onedrive uses FileIDs to determine if a file is already uploaded, or if it is because when it scanned a directory it may have triggered a notification that all the files in that directory changed and based on that notification it reuploads. After this I noticed files were becoming deleted both locally and in the cloud. I don't know what caused this, it might have been because the old file it thought was deleted as the FileID was gone and while there was a new file (actually the same file) in its place there may have been some odd race condition. It is also possible that it queued the file for upload, the FileID changed and when it went to open it to upload it found it was 'deleted' as the FileID no longer pointed to a file and queued the delete operation. I also found that files that were uploaded into the cloud in one folder were sometimes downloading to an alternate folder locally. I am guessing this is because the folder FileID changed. It thought the 2023 folder was with ID XYZ but that now pointed to a different folder and so it put the file in the wrong place. The final form of corruption was finding the data from one photo or video actually in a file with a completely different name. This is almost guaranteed to be due to the FileID bugs. This is highly destructive as backups make this far harder to correct. With one files contents replaced with another you need to know when the good content existed and in what files were effected. Depending on retention policies the file contents that replaced it may override the good backups before you notice. I also had a BSOD with onedrive where it was trying to set attributes on a file and the CoveFS driver corrupted some memory. It is possible this was a race condition as onedrive may have been doing hundreds of files very rapidly due to the bugs. I have not captured a second BSOD due to it, but also stopped using onedrive on DrivePool due to the corruption. Another example of this is data leakage. Lets say you share your favorite article on kittens with a group of people. Onedrive, believing that file has changed, goes to open it using the FileID however that file ID could essentially now correspond to any file on your computer now the contents of some sensitive file are put in the place of that kitten file, and everyone you shared it with can access it. Visual Studio Failures Visual studio is a code editor/compiler. There are three distinct bugs that happen. First, when compiling if you touched one file in a folder it seemed to recompile the entire folder, this due likely to the notification bug. This is just a slow down, but an annoying one. Second, Visual Studio has compiler generated code support. This means the compiler will generate actual source code that lives next to your own source code. Normally once compiled it doesn't regenerate and compile this source unless it must change but due to the notification bugs it regenerates this code constantly and if there is an error in other code it causes an error there causing several other invalid errors. When debugging visual studio by default will only use symbols (debug location data) as the notifications from DrivePool happen on certain file accesses visual studio constantly thinks the source has changed since it was compiled and you will only be able to breakpoint inside source if you disable the exact symbol match default. If you have multiple projects in a solution with one dependent on another it will often rebuild other project deps even when they haven't changed, for large solutions that can be crippling (perf issue). Finally I often had intellisense errors showing up even though no errors during compiling, and worse intellisense would completely break at points. All due to DrivePool. Technical details / full background & disclaimer I have sample code and logs to document these issues in greater detail if anyone wants to replicate it themselves. It is important for me to state drivepool is closed source and I don't have the technical details of how it works. I also don't have the technical details on how applications like onedrive or visual studio work. So some of these things may be guesses as to why the applications fail/etc. The facts stated are true (to the best of my knowledge) Shortly before my trial expired in October of last year I discovered some odd behavior. I had a technical ticket filed within a week and within a month had traced down at least one of the bugs. The issue can be seen https://stablebit.com/Admin/IssueAnalysis/28720 , it does show priority 2/important which I would assume is the second highest (probably critical or similar above). It is great it has priority but as we are over 6 months since filed without updates I figured warning others about the potential corruption was important. The FileSystemWatcher API is implemented in windows using async overlapped IO the exact code can be seen: https://github.com/dotnet/runtime/blob/57bfe474518ab5b7cfe6bf7424a79ce3af9d6657/src/libraries/System.IO.FileSystem.Watcher/src/System/IO/FileSystemWatcher.Win32.cs#L32-L66 That corresponds to this kernel api: https://learn.microsoft.com/en-us/windows/win32/fileio/synchronous-and-asynchronous-i-o Newer api calls use GetFileInformationByHandleEx to get the FileID but with older stats calls represented by nFileIndexHigh/nFileIndexLow. In terms of the FileID bug I wouldn't normally have even thought about it but the advanced config (https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings) mentions this under CoveFs_OpenByFileId "When enabled, the pool will keep track of every file ID that it gives out in pageable memory (memory that is saved to disk and loaded as necessary).". Keeping track of files in memory is certainly very different from Windows so I thought this may be the source of issue. I also don't know if there are caps on the maximum number of files it will track as if it resets FileIDs in situations other than reboots that could be much worse. Turning this off will atleast break nfs servers as it mentions it right in the docs "required by the NFS server". Finally, the FileID numbers given out by DrivePool are incremental and very low. This means when they do reset you almost certainly will get collisions with former numbers. What is not clear is if there is the chance of potential FileID corruption issues. If when it is assigning these ids in a multi-threaded scenario with many different files at the same time could this system fail? I have seen no proof this happens, but when incremental ids are assigned like this for mass quantities of potential files it has a higher chance of occurring. Microsoft mentions this about deleting the USN Journal: "Deleting the change journal impacts the File Replication Service (FRS) and the Indexing Service, because it requires these services to perform a complete (and time-consuming) scan of the volume. This in turn negatively impacts FRS SYSVOL replication and replication between DFS link alternates while the volume is being rescanned.". Now DrivePool never has the USN journal supported so it isn't exactly the same thing, but it is clear that several core Windows services do use it for normal operations I do not know what backups they use when it is unavailable. Potential Fixes There are advanced settings for drivepool https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings beware these changes may break other things. CoveFs_OpenByFileId - Set to false, by default it is true. This will disable the OpenByFileID API. It is clear several applications use this API. In addition, while DrivePool may disable that function with this setting it doesn't disable FileID's themselves. Any application using FileIDs as static identifiers for files may still run into problems. I would avoid any file backup/synchronization tools and DrivePool drives (if possible). These likely have the highest chance of lost files, misplaced files, file content being mixed up, and excess resource usage. If not avoiding consider taking file hashes for the entire drivepool directory tree. Do this again at a later point and make sure files that shouldn't have changed still have the same hash. If you have files that rarely change after being created then hashing each file at some point after creation and alerting if that file disappears or hash changes would easily act as an early warning to a bug here being hit.8 points -
Hi im using Windows 10 2004 with WSL2. I have 3x drives: C:\ (SSD), E:\ (NVME), D:\ (Drivepool of 2x 4TB HDD) When the drives are mounted on Ubuntu, I can run ls -al and it shows all the files and folders on C and E drives. This is not possible on D When I run ls -al on D, it returns 0 results. But I can cd into the directories in D stragely enough. Is this an issue with drivepool being mounted? Seems like it is the only logical difference (aside from it being mechanical) between the other drives. They are all NTFS.5 points
-
I tried to access my drivepool drive via WSL 2 and got this. Any solution? I'm using 2.3.0.1124 BETA. ➜ fludi cd /mnt/g ➜ g ls ls: reading directory '.': Input/output error Related thread: https://community.covecube.com/index.php?/topic/5207-wsl2-support-for-drive-mounting/#comment-312124 points
-
I just wanted to say that @Christopher (Drashna)has been very helpful each time I've created a topic. I have found him and the others I've worked with to be thoughtful and professional in their responses. Thanks for all the work you all do. Now we can all stop seeing that other thread previewed every time we look at the forum home.4 points
-
If you haven't uploaded much, go ahead and change the chunk size to 20MB. You'll want the larger chunk size both for throughput and capacity. Go with these settings for Plex: 20MB chunk size 50+ GB Expandable cache 10 download threads 5 upload threads, turn off background i/o upload threshold 1MB or 5 minutes minimum download size 20MB 20MB Prefetch trigger 175MB Prefetch forward 10 second Prefetch time window4 points
-

OMG I love the activation system
withwolf1987 and 3 others reacted to GreatScott for a question
VERY IMPRESSED! Didn't need to create an account and password Same activation code covers EVERY product on EVERY computer! Payment information remembered so additional licenses are purchased easily Nice bundle and multi-license discount I'm in love with the Drive Pool and Scanner. Thanks for a great product and a great buying experience. -Scott4 points -

Japanese Translation does not work
DavidBrocho and 2 others reacted to Christopher (Drashna) for a question
Yup, something broke on our end. This should be fixed now, and updating should get the fixed version.3 points -
I know the chance of this is near zero, but the most recent Windows screenshotting AI shenanigans is the last straw for me. The incredible suite of Stablebit tools is the ONLY thing that has kept me using Windows (seriously, it’s the best software ever - I don’t even think that’s an exaggeration). I will pay for the entire suite again, or hell Stablebit can double the price for Linux, I’ll pay it. Is there ANY chance a Linux version of DrivePool/Scanner would be developed?3 points
-
I would just like to say that this is fairly disappointing to hear. Though they added limits, a lot of people are still able to work within those limits. And the corruption issue hasn't been present for many years as far as I can tell -- the article in the announcement by Alex is from April 2019, so over 5 years ago. I get the desire to focus resources though, and I'm glad it still works in the background for now. Hopefully there are no breaking changes from Google, and I hope an individual API key is going to have reasonable limits for the drive to continue working. But yeah, switching providers is not very realistic in my case, so I guess I'll use it until it just breaks.3 points
-
Sorry, should also mention this is confirmed by StableBit and can be easily reproduced. The attached powershell script is a basic example of the file monitoring api. Run it by "monitor.ps1 my_folder" where my folder is what you want to monitor. Have a file say hello.txt inside. Open that file in notepad. It should instantly generate a monitoring file change event. Further tab away from notepad and tab back to it, you will again get a changed event for that file. Run the same thing on a true NTFS system and it will not do the same. You can also reproduce the lack of notifications for other events by changing the IncludeSubdirectories variable in it and doing some of the tests I mention above. watcher.ps13 points
-
So this is correct, as the documentation you linked to states. One item I mentioned though, is the fact that even if it can be re-used if in practice it isn't software may make the wrong assumption that it won't. Not good on that software but it may be a practical exception that one might try to meet. Further, that documentation also states: "In the NTFS file system, a file keeps the same file ID until it is deleted. " As DrivePool identifies itself as NTFS it is breaking that expectation. I am not sure how well things work if you just disable File IDs, maybe software will fallback to a more safe behavior (even if less performant). In addition, I think the biggest issue is silent file corruption. I think that can only happen due to File ID collisions (rather than just the FIle ID changing). It is a 128 bit number, GUID's are 128 bits. Just randomize the sucker the first time you assign a file ID (rather than using the incremental behavior currently). Aside from it being more thread safe as you don't have a single locked increment counter it is highly unlikely you would hit a collision. Could you run into a duplicate ? sure. Likely? Probably not. Maybe over many reboots (or whatever resets the ID's in drivepool beside that) but as long as whatever app that uses the FileID has detected it is gone before it is reused it eventually colliding would likely not have much effect. Not perfect but probably an easier solution. Granted apps like onedrive may still think all the files are deleted and re-upload them if the FileID's change (although that may be more likely due to the notification bug). Sure. Except one doesn't always know how tools work. I am only making a highly educated guess this is what OneDrive is using, but only made this after significant file corruption and research. One would hope you don't need to have corruption before figuring out the tool you are using uses the FileID. In addition, FileID may not be the primary item a backup/sync tool uses but something like USF may be a much more common first choice. It may only fall back to other options when that is not available. Is it possible the 5-6 apps I have found that run into issues are the only ones out there that uses these things? Sure. I just would guess I am not that lucky so there are likely many more that use these features. I did see either you (or someone else) who posted about the file hashing issue with the read striping. It is a big shame, reporting data corruption (invalid hash values or rather returning the wrong read data which is what would lead to that) is another fairly massive problem. Marking good data bad because of an inconsistent read can lead to someone thinking they lost data and trashing it, or restoring an older version that may cause newer data to be lost in an attempt to fix. I would look into a more consistent read striping repro test but at the end of the day these other things stop me from being able to use drivepool for most things I would like to.3 points
-

How do I remove a pool inside a pool?
andrewds and 2 others reacted to RumbleDrum for a question
@Shane and @VapechiK - Thank you both for the fantastic, detailed information! As it seemed like the easiest thing to start with, I followed VapechiK's instructions from paragraph 4 of their reply to simply remove the link for DP (Y:) under DP (E:) and it worked instantly, and without issue! Again, I thanks for taking the time to provide solutions, it really is appreciated! Thanks much!3 points -

Google Drive: The limit for this folder's number of children (files and folders) has been exceeded
Patrik_Mrkva and 2 others reacted to ezek1el3000 for a question
My advice; contact support and send them Troubleshooter data. Christopher is very keen in resolving problems around the "new" google way of handling folders and files.3 points -
Go to My Computer, or My PC Icon, if you have the icons turned on, on your Desktop Screen. Right click on it and select more option. And click on manage. In the Computer Management Window you will see Disk Management. Click on that and all your hard drives will show up. Select one of the drives and right click. You will see Change Drive Letter and Paths. Click on that. Select remove. You will get a warning. But that's ok if the hard drive is only for storing data. (Videos, documents and pictures. Stuff like that). No programs installed on the drives or looking for a drive letter to work. ( Just Data Storage. StableBit will still work. It does not use the drive letters to function properly). If later you need to access that drive or drives outside of the storage pool. Just do the same thing and click add instead of remove the drive letter.2 points
-
Do you duplicate everything?
Shane and one other reacted to Christopher (Drashna) for a question
Ah, okay. So just another term like "spinning rust" And that's ... very neat! You are very welcome! And I'm in that same boat, TBH. Zfs and btrfs look like good pooling solutions, but a lot that goes into them. Unraid is another option, but honestly, one I'm not fond of, mainly because of how the licensing works (I ... may be spoiled by our own licensing, I admit). And yeah, the recovery and such for the software is great. A lot of time and effort has gone into making it so easy, and we're glad you appreciate that! And the file recovery does make things nice, when you're in a pinch! And I definitely understand why people keep asking for a linux and/or mac version of our software. There is a lot to say about something that "just works".2 points -
LAN control. Sometimes remote devices appear in the drop down, sometimes they don't.
dmaker and one other reacted to Christopher (Drashna) for a question
It's flaky because multicast detection can be flaky. That said, you can manually add entries, if you need to: https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings#RemoteControl.xml2 points -

Pool file duplication causing file corruption under certain circumstances
Shane and one other reacted to number_one for a question
Yes, I haven't heard of any update from Covecube about any resolution to this (or even that they're working on it), so you should DEFINITELY disable read striping. I'm quite frankly a bit alarmed at how there seems to be no official acknowledgement of the issue at present. The only post in this thread from an actual employee is from nearly five years ago. I do understand that it likely involves specific edge cases to be affected by the issue, but those edge cases are clearly not rare or hard to demonstrate. In my case all it took was using rsync through a Git Bash environment to have the bug cause massive corruption. And it is easily repeatable (as in if I sync files using rsync from a Drivepool volume there were essentially NO instances where there wasn't at least some corruption when read striping was enabled).2 points -
Spend long enough working with Windows and you may become familiar with NTFS permissions. As an operating system intended to handle multiple users, Windows maintains records that describe which user owns each file and folder and how much access each user has to those files and folders. These records are kept on the same volumes as those files and folders. Unfortunately, in the course of moving or copying folders and files around, Windows may fail to properly update these settings for a variety of reasons (e.g. bugs, bit errors, power interruptions, failing hardware). This can mean files and folders that you can no longer delete, access or even have ownership of anymore, sometimes for no obvious reason when you check via the Security tab of the file/folder's Properties (they can look fine but actually be broken inside). So, first up, here’s what the default permissions for a pool drive should look like: And now here’s what the default permissions for the hidden poolpart folder on any drive added to the pool should look like: The above are taken from a freshly created pool using a previously unformatted drive, on a computer named CASTLE that is using Windows 10 Professional. I believe it should be the same for all supported versions of Windows so far. Any entries that are marked Deny override entries that are marked Allow. There are limited exceptions for SYSTEM. It is optional for a hidden poolpart folder to Inherit its permissions from its parent drive. It is recommended that the Administrators account have Full control of all poolpart folders, subfolders and files. It is necessary that the SYSTEM account have Full control of all poolpart folders, subfolders and files. The permissions of files and folders in a pool drive are the permissions of those files and folders in the constituent poolpart folders. Caveat: duplicates are expected to have identical permissions (because in normal practice, only DrivePool should be creating them). My next post in this thread will describe how I go about fixing these permissions when they go bad.
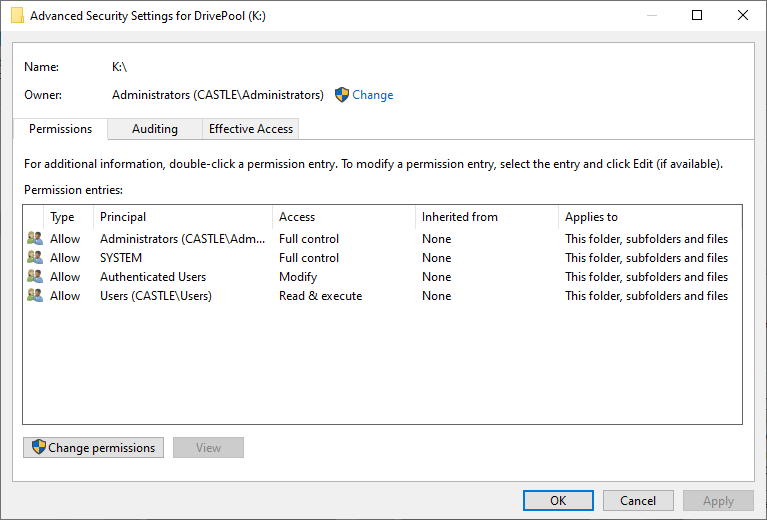
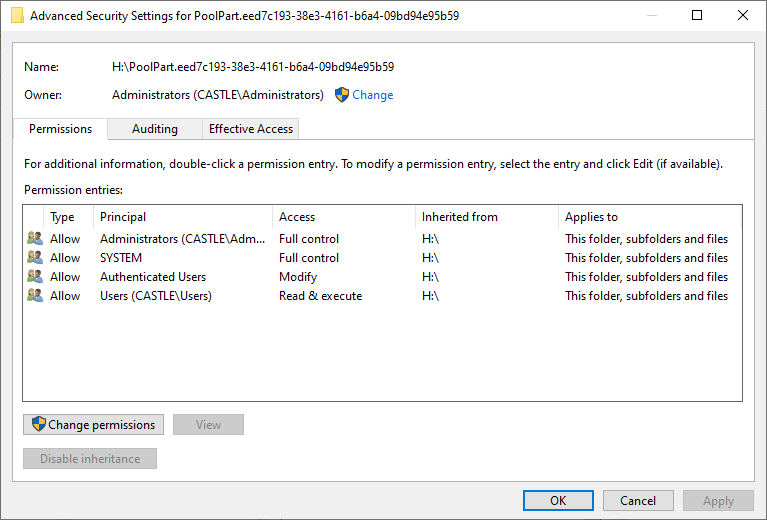 2 points
2 points -
To be fair to Stablebit I used Drivepool for the past few years and have NEVER lost a single file because of Drivepool. The elaborateness OR simpleness of how you use Drivepool within itself is not really of concern. What is being warned of here though is if you use any special applications that might expect FileID to behave as per NTFS there will be risks with that. My example is that I use Freefilesync quite a bit to maintain files between my pool, my htpc and another backup location. When I move files on one drive, freefilesync using fileid recognises the file was moved so syncs a "move" on the remote filesystem as well. This saves potentially hours of copying and then deleting. It does not work on Drivepool because the fileid changes on each reboot. In this case Freefilesync fails "SAFE" in that it does the copy and delete instead, so I only suffer performance issues. What could happen though is that you use another app that say cleans old files, or moves files around that does not fail safe if a fileid is repeated for a different file etc and in doing so you do suffer file loss. This will only happen if you use some third party application that makes changes to files. It's not the type of thing a word processor or a pc game etc are going to be doing (typically in case someone jumps in with a it could be possible argument). So generally Drivepool is safe, and for you most likely of nothing to worry about, but if you do use an application now or in the future that is for cleaning up or syncing etc then be very careful in case it uses fileid and causes data loss because of this issue. For day to day use, in my experience you can continue to use it as is. If you want to add to the group of us that would like this improved, feel free to add your voice to the request as otherwise I don't see any update for this in the foreseeable future.2 points
-
USB so-called DAS/JBOD/etc units usually internally use a SATA Port multiplier setup, and is likely the source of your issues. A SATA Port multiplier is a way of connecting multiple SATA Devices to one root port, and due to the way that the ATA Protocol works, when I/O is performed it essentially takes the entire bus that is created from that root port hostage until the requested data is returned. it also is important to know that write caching will skew any write benchmarks results if the enclosure uses UASP or you have explicitly enabled it. these devices perform even worse with a striping filesystem (like raidz, btrfs raid 5/6 or mdraid 5/6), and having highly fragmented data (which will cause a bunch of seek commands that again, will hold the bus hostage until they complete, which with spinning media does create a substantial I/O burden) honestly, your options are either accept the loss of performance (it is tolerable but noticeable on a 4 drive unit, no idea how it is on your 8 drive unit), or invest in something like a SAS JBOD which will actually have sane real world performance. USB isn't meant for more than a disk or two, and between things like this and hidden overhead (like the 8/10b modulation, root port and chip bottlenecks, general inability to pass SMART and other data, USB disconnects, and other issues that aren't worth getting into) it may be worth just using a more capable solution2 points
-
 FWIW, digging through Microsoft's documentation, I found these two entries in the file system protocols specification: https://learn.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/2d3333fe-fc98-4a6f-98a2-4bb805aff407 https://learn.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/98860416-1caf-4c80-a9ab-8d61e1ccf5a5 In short, if a file system cannot provide a file ID that is both unique within a given volume and stable until deleted, then it must set the field to either zero (indicating the file system does not support file IDs) or maxint (indicating the file system cannot given a particular file a unique ID) as per the specification.2 points
FWIW, digging through Microsoft's documentation, I found these two entries in the file system protocols specification: https://learn.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/2d3333fe-fc98-4a6f-98a2-4bb805aff407 https://learn.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/98860416-1caf-4c80-a9ab-8d61e1ccf5a5 In short, if a file system cannot provide a file ID that is both unique within a given volume and stable until deleted, then it must set the field to either zero (indicating the file system does not support file IDs) or maxint (indicating the file system cannot given a particular file a unique ID) as per the specification.2 points -
 Response from Freefilesync developer. I read through the Microsoft docs you posted earlier and others, and I agree with the Freefilesync developer. It appears the best way to track all files on a volume on NTFS is to use fileid which is expected to stay persistent. This requires no extra overhead or work as the Filesystem maintains FileID’s automatically. ObjectID requires extra overhead and is only really intended to track special files like shortcuts for link tracking etc. Any software that is emulating an NTFS system should therefore provide FileID’s and guarantee they stay persistent with a file on that volume. I am seeing the direct performance impact from this and agree with Mitch that there can be other adverse side affects potentially much worse than just performance issues if someone uses software that expects FileID’s to behave as per Microsoft’s documentation. Finally also note that ObjectID is not supported by the Refs filesystem, whereas FileID is. https://learn.microsoft.com/en-us/windows-hardware/drivers/ddi/ntifs/ns-ntifs-_file_objectid_information ReFS doesn't support object IDs. ReFS uses 128-bit file IDs, so can't cleanly distinguish between file ID versus object ID when processing an open by ID.2 points
Response from Freefilesync developer. I read through the Microsoft docs you posted earlier and others, and I agree with the Freefilesync developer. It appears the best way to track all files on a volume on NTFS is to use fileid which is expected to stay persistent. This requires no extra overhead or work as the Filesystem maintains FileID’s automatically. ObjectID requires extra overhead and is only really intended to track special files like shortcuts for link tracking etc. Any software that is emulating an NTFS system should therefore provide FileID’s and guarantee they stay persistent with a file on that volume. I am seeing the direct performance impact from this and agree with Mitch that there can be other adverse side affects potentially much worse than just performance issues if someone uses software that expects FileID’s to behave as per Microsoft’s documentation. Finally also note that ObjectID is not supported by the Refs filesystem, whereas FileID is. https://learn.microsoft.com/en-us/windows-hardware/drivers/ddi/ntifs/ns-ntifs-_file_objectid_information ReFS doesn't support object IDs. ReFS uses 128-bit file IDs, so can't cleanly distinguish between file ID versus object ID when processing an open by ID.2 points -

Upgrading from WHS2011 to Windows 10 and keeping Drivepool alive.
Michael Lee and one other reacted to GaPony for a question
All my drives are installed inside the server chassis, so I'll just remove the HBAs which will have the same effect. Reading back through many, many old posts on the subject, I believe I've been looking at this all wrong. The actual information Drivepool uses to build and maintain the pool is stored on the pooled drives, not on the system disk, so its just a matter of reinstalling Drivepool and it goes looking for the poolpart folders on the physical drives in order to rebuild the pool. I'm not sure why I've been thinking I needed to worry about what was on the C: Drive, other than that's where I placed the junctions for the drives on my system, but that seems to be more of a housekeeping feature to get around the 26 drive letter limit more than anything to do with Drivepool itself. If this is correct, I believe I'm ready to go. It would seem that Stablebit Drivepool is quite a feat of engineering. Thanks again Shane.2 points -
I duplicate all HDD's, except the ones that have the OS's on them, with those, I use 'minitool partition wizard'. The 4 bay enclosures I linked to above, I have 2 of the 8 bay ones, with a total of 97.3TB & I now have only 6.34TB free space out of that. It works out cheaper to get the little 4 bay ones, and they take HDD's up to 18TB - sweet If you like the black & green, you could always get a pint of XXXX & put green food dye into it, you don't have to wait till St. Patrick's Day. That would bring back uni days as well 🤣 🍺 👍 " A pirate walks into a bar with a steering wheel down his daks He walks up to the bar & orders a drink The barman looks over the bar and says, "do you know you have a steering wheel down your daks?" The pirate goes, "aye, and it's driving me nuts"" 🤣 🤣 🤣 🍺 👍 🍺 cheers2 points
-

I cannot work
PBUK and one other reacted to thestillwind for a topic
Well, this is why always online functionnality is really bad. They need to add at least a grace period or something because my tools aren't working. Before the stablebit cloud thing, I never had any problem with stablebit software.2 points -
Note that hdparm only controls if/when the disks themselves decide to spin down; it does not control if/when Windows decides to spin the disks down, nor does it prevent them from being spun back up by Windows or an application or service accessing the disks, and the effect is (normally?) per-boot, not permanent. If you want to permanently alter the idle timer of a specific hard drive, you should consult the manufacturer. An issue here is that DrivePool does not keep a record of where files are stored, so I presume it would have to wake up (enough of?) the pool as a whole to find the disk containing the file you want if you didn't have (enough of?) the pool's directory stucture cached in RAM by the OS (or other utility).2 points
-
hhmmm yes, seems a hierarchal pool was inadvertently/unintentionally created. i have no idea of your skill level so if you're not comfortable with any of the below... you should go to https://stablebit.com/Contact and open a ticket. in any event removing drives/pools from DrivePool in the DrivePool GUI should NEVER delete your files/data on the underlying physical drives, as any 'pooled drive' is just a virtual placeholder anyway. if you haven't already, enable 'show hidden files and folders.' then (not knowing what your balancing/duplication settings are), under 'Manage Pool ^ > Balancing...' ensure 'Do not balance automatically' IS checked, and 'Allow balancing plug-ins to force etc. etc...' IS NOT checked for BOTH pools. SAVE. we don't want DP to try to run a balance pass while resolving this. maybe take a SS of the settings on DrivePool (Y:) before changing them. so DrivePool (E:) is showing all data to be 'Other' and DrivePool (Y:) appears to be duplicated (x2). i say this based on the shade of blue; the 2nd SS is cut off before it shows a green 'x2' thingy (if it's even there), and drives Q & R are showing unconventional total space available numbers. the important thing here is that DP (E:) is showing all data as 'Other.' under the DrivePool (E:) GUI it's just as simple as clicking the -Remove link for DP (Y:) and then Remove on the confirmation box. the 3 checkable options can be ignored because DrivePool (E:) has no actual 'pooled' data in the pool and those are mostly evacuation options for StableBit Scanner anyway. once that's done DrivePool (E:) should just poof disappear as Y: was the only 'disk' in it, and the GUI should automatically switch back to DrivePool (Y:). at this point, i would STOP the StableBit DrivePool service using Run > services.msc (the DP GUI will disappear), then check the underlying drives in DrivePool (Y:) (drives P, Q, & R in File Explorer) for maybe an additional PoolPart.XXXXXXXX folder that is EMPTY and delete it (careful don't delete the full hidden PoolPart folders that contain data on the Y: pool). then restart the DP service and go to 'Manage Pool^ > Balancing...' and reset any changed settings back the way you had/like them. SAVE. if a remeasure doesn't start immediately do Manage Pool^ > Re-measure > Re-measure. i run a pool of 6 spinners with no duplication. this is OK for me because i am OCD about having backups. i have many USB enclosures and have played around some with duplication and hierarchal pools with spare/old hdds and ssds in the past and your issue seems an easy quick fix. i can't remember whether DP will automatically delete old PoolPart folders from removed hierarchal pools or just make them 'unhidden.' perhaps @Shane or @Christopher (Drashna) will add more. Cheers2 points
-
hi. in windows/file explorer enable 'show hidden files and folders.' then go to: https://wiki.covecube.com/Main_Page and bookmark for future reference. from this page on the left side click StableBit DrivePool > 2.x Advanced Settings. https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings if you are using BitLocker to encrypt your drives you will NOT want to do this, and will just have to live with the drive LEDs flashing and disc pings i assume. i don't use it so i don't know much about it. the given example on this page just happens to be the exact .json setting you need to change to stop DP from pinging your discs every ~5secs. set "BitLocker_PoolPartUnlockDetect" override value from null to false as shown. if StableBit CloudDrive is also installed you will need to change the same setting for it also. opening either of these json files, it just happens to be the very top entry on the file. you may need to give your user account 'full control' on the 'security' tab (right click the json > properties > security) in order to save the changes. this worked immediately for me, no reboot necessary. YMMV... good luck2 points
-
Reparse point information is stored in the .covefs folder in the root of the pool. Worst case, delete the link, remove the contents of the .covefs folder, and then reboot.2 points
-
I recently found out these two products were compatible, so I wanted to check performance characteristics of a pool with a cache assigned to it's underlying drives. Pleasantly, I found there was a huge increase in pool drive throughput using Primocache and a good sized Level-1 RAM cache. This pool uses a simple configuration: 3 WD 4TB Reds with 64KB block size (both volume and DrivePool). Here are the raw tests on the Drivepool volume, without any caching going on yet: After configuring and enabling a sizable Level-1 read/write cache in Primocache on the actual drives (Z: Y: and X:), I re-ran the test on the DrivePool volume and got these results: As you can see, not only do both pieces of software work well with each other, the speed increase on all DrivePool operations (the D: in the benchmarks was my DrivePool letter) was vastly greater. For anyone looking to speed up their pool, Primocache is a viable and effective means of doing so. It would even work well with the SSD Cache feature in DrivePool - simply cache the SSD with Primocache, and boost read (and write if you use a UPS) speeds. Network speeds are of course, still limited by bandwidth, but any local pool operations will run much, much faster. I can also verify this setup works well with SnapRAID, especially if you also cache the Parity drive(s). I honestly wasn't certain if this was going to work when I started thinking about it, but I'm very pleased with the results. If anyone else would like to give it a spin, Primocache has a 60-day trial on their software.2 points
-
Is dark mode planned for DrivePool & CloudDrive?
zeoce and one other reacted to Christopher (Drashna) for a topic
Not currently, but I definitely do keep on bringing it up.2 points -

Best way to replace a drive in my Drivepool to a larger drive?
igobythisname and one other reacted to Umfriend for a question
AFAIK, copying, even cloning does not work. The easiest way is: 1. Install/connect new HDD 2. Add HDD to the Pool 3. And now you can either click on Remove for the 6TB HDD or use Manage Pool -> Balancing -> Balancers -> Drive Usage Limiter -> uncheck Duplicated and Unduplicated -> Save -> Remeasure and Rebalance. 4. Wait. Until. It. Is. Done. (though you can reboot normally if you want/need to and it'll continue after boot. Not entirely sure if you go the Remove route.2 points -
Clouddrive continues to attempt uploading when at gdrive upload limit
otravers and one other reacted to Christopher (Drashna) for a question
Just a heads up, yes, it does continue to attempt to upload, but we use an exponential backoff when the software gets throttling requests like this. However, a daily limit or schedular is something that has been requested and is on our "to do"/feature request list. I just don't have an ETA for when it would be considered or implemented.2 points -
Have you determined what speed your TV streaming device pulls movies from your Storage Spaces or DrivePool? For example, when I watch my DrivePool GUI, I can see that my Fire TV Stick is pulling about ~4 MB/s tops for streaming 1080p movies. I don't suffer any stuttering or caching on my system. If I try to stream movies >16GB, then I start to see problems and caching issues. But, at that point, I know I have reached the limits of my Fire TV Stick with limited memory storage and its low power processor. It is not a limit of how fast DrivePool can send data over my wifi. Well, there is how many bars are available to indicate how strong the connection is, but bars does not equal speed. On my old 56K router, I would also have 4 or 5 bars indicating a strong connection, but I was constantly fighting buffering issues while streaming. I upgraded to a 1 gigabit router, which is much faster, and that took care of my buffering problems. Well, good questions but beyond my level of tech expertise with that equipment. I get my internet service from a local telephone company, and they have a computer support team on staff to answer questions and help customers with their equipment. If you are leasing your equipment from ATT, then they might have a support team you could contact for assistance. At least you have something that is currently working for you, so it's not like you are in a panic. After years of running Storage Spaces on my system, and now with DrivePool for just less than 1 year, I don't yet understand why you are experiencing streaming issues with DrivePool. On my system, it made no difference at all in regards to streaming, which I have stated runs at about 4 MB/s tops and usually much less on my system.2 points
-
Yes, DrivePool, like many of my Windows programs, sometimes hangs and requires a reboot. Most of the time DrivePool works without any problems, but I have run into some circumstances where DrivePool misbehaves and does not correct itself until after a reboot. I ran Windows Storage Spaces for ~7 years, and the small problems I occasionally experience with DrivePool are nothing compared to the problems I had with Storage Spaces trying to manage the same size pool (currently 70TB). IF I had any real complaint about DrivePool, it would be that it really keeps you in the dark on background tasks it performs. I personally would like more status info displayed in the DrviePool GUI in those cases, because background tasks might have a really low priority and it may look like nothing is happening. Well, it may be happening but not very fast. Or, maybe the task got hung up and needs a reboot. Sometimes you can go into Task Manager and check for disk activity there. I have done that on occasion to verify activity was really going on in the background tasks. It would be nice to have the option of seeing some of that background activity on the DrivePool GUI. Most of the time I don't care as long as it gets done. Sometimes I want to verify work is actually going on. FWIW, I had the same idea as you when I was testing out DrivePool. I did a couple disk removals, but they worked just fine on my system, so I started off with a positive experience.2 points
-

Plugin Source
Shane and one other reacted to methejuggler for a question
I actually wrote a balancing plugin yesterday which is working pretty well now. It took a bit to figure out how to make it do what I want. There's almost no documentation for it, and it doesn't seem very intuitive in many places. So far, I've been "combining" several of the official plugins together to make them actually work together properly. I found the official plugins like to fight each other sometimes. This means I can have SSD drop drives working with equalization and disk usage limitations with no thrashing. Currently this is working, although I ended up re-writing most of the original plugins from scratch anyway simply because they wouldn't combine very well as originally coded. Plus, the disk space equalizer plugin had some bugs in a way which made it easier to rewrite than fix. I wasn't able to combine the scanner plugin - it seems to be obfuscated and baked into the main source, which made it difficult to see what it was doing. Unfortunately, the main thing I wanted to do doesn't seem possible as far as I can tell. I had wanted to have it able to move files based on their creation/modified dates, so that I could keep new/frequently edited files on faster drives and move files that aren't edited often to slower drives. I'm hoping maybe they can make this possible in the future. Another idea I had hoped to do was to create drive "groups" and have it avoid putting duplicate content on the same group. The idea behind that was that drives purchased at the same time are more likely to fail around the same time, so if I avoid putting both duplicated files on those drives, there's less likelihood of losing files in the case of multiple drive failure from the same group of drives. This also doesn't seem possible right now.2 points -

Google Drive: The limit for this folder's number of children (files and folders) has been exceeded
ezek1el3000 and one other reacted to Chase for a question
Unintentional Guinea Pig Diaries. Day 8 - Entry 1 I spent the rest of yesterday licking my wounds and contemplating a future without my data. I could probably write a horror movie script on those thoughts but it would be too dark for the people in this world. I must learn from my transgressions. In an act of self punishment and an effort to see the world from a different angle I slept in the dogs bed last night. He never sleeps there anyways but he would never have done the things I did. For that I have decided he holds more wisdom than his human. This must have pleased the Data God's because this morning I awoke with back pain and two of my drives mounted and functioning. The original drive which had completed the upgrade, had been working, and then went into "drive initializing"...is now working again. The drive that I had tried to mount and said it was upgrading with no % given has mounted (FYI 15TB Drive with 500GB on it). However my largest drive is still sitting at "Drive queued to perform recovery". Maybe one more night in the dogs bed will complete the offering required to the Data God's End Diary entry. (P.S. Just in case you wondered...that spoiled dog has "The Big One" Lovesac as a dog bed.. In a pretty ironic fashion their website is down. #Offering)2 points -
They are not comparable products. Both applications are more similar to the popular rClone solution for linux. They are file-based solutions that effectively act as frontends for Google's API. They do not support in-place modification of data. You must download and reupload an entire file just to change a single byte. They also do not have access to genuine file system data because they do not use a genuine drive image, they simply emulate one at some level. All of the above is why you do not need to create a drive beyond mounting your cloud storage with those applications. CloudDrive's solution and implementation is more similar to a virtual machine, wherein it stores an image of the disk on your storage space. None of this really has anything to do with this thread, but since it needs to be said (again): CloudDrive functions exactly as advertised, and it's certainly plenty secure. But it, like all cloud solutions, is vulnerable to modifications of data at the provider. Security and reliability are two different things. And, in some cases, is more vulnerable because some of that data on your provider is the file system data for the drive. Google's service disruptions back in March caused it to return revisions of the chunks containing the file system data that were stale (read: had been updated since the revision that was returned). This probably happened because Google had to roll back some of their storage for one reason or another. We don't really know. This is completely undocumented behavior on Google's part. These pieces were cryptographically signed as authentic CloudDrive chunks, which means they passed CloudDrive verifications, but they were old revisions of the chunks that corrupted the file system. This is not a problem that would be unique to CloudDrive, but it is a problem that CloudDrive is uniquely sensitive to. Those other applications you mentioned do not store file system data on your provider at all. It is entirely possible that Google reverted files from those applications during their outage, but it would not have resulted in a corrupt drive, it would simply have erased any changes made to those particular files since the stale revisions were uploaded. Since those applications are also not constantly accessing said data like CloudDrive is, it's entirely possible that some portion of the storage of their users is, in fact, corrupted, but nobody would even notice until they tried to access it. And, with 100TB or more, that could be a very long time--if ever. Note that while some people, including myself, had volumes corrupted by Google's outage, none of the actual file data was lost any more than it would have been with another application. All of the data was accessible (and recoverable) with volume repair applications like testdisk and recuva. But it simply wasn't worth the effort to rebuild the volumes rather than just discard the data and rebuild, because it was expendable data. But genuinely irreplaceable data could be recovered, so it isn't even really accurate to call it data loss. This is not a problem with a solution that can be implemented on the software side. At least not without throwing out CloudDrive's intended functionality wholesale and making it operate exactly like the dozen or so other Google API frontends that are already on the market, or storing an exact local mirror of all of your data on an array of physical drives. In which case, what's the point? It is, frankly, not a problem that we will hopefully ever have to deal with again, presuming Google has learned their own lessons from their service failure. But it's still a teachable lesson in the sense that any data stored on the provider is still at the mercy of the provider's functionality and there isn't anything to be done about that. So, your options are to either a) only store data that you can afford to lose or b) take steps to backup your data to account for losses at the provider. There isn't anything CloudDrive can do to account for that for you. They've taken some steps to add additional redundancy to the file system data and track chksum values in a local database to detect a provider that returns authentic but stale data, but there is no guarantee that either of those things will actually prevent corruption from a similar outage in the future, and nobody should operate based on the assumption that they will. The size of the drive is certainly irrelevant to CloudDrive and its operation, but it seems to be relevant to the users who are devastated about their losses. If you choose to store 100+ TB of data that you consider to be irreplaceable on cloud storage, that is a poor decision. Not because of CloudDrive, but because that's a lot of ostensibly important data to trust to something that is fundamentally and unavoidably unreliable. Contrarily, if you can accept some level of risk in order to store hundreds of terabytes of expendable data at an extremely low cost, then this seems like a great way to do it. But it's up to each individual user to determine what functionality/risk tradeoff they're willing to accept for some arbitrary amount of data. If you want to mitigate volume corruption then you can do so with something like rClone, at a functionality cost. If you want the additional functionality, CloudDrive is here as well, at the cost of some degree of risk. But either way, your data will still be at the mercy of your provider--and neither you nor your application of choice have any control over that. If Google decided to pull all developer APIs tomorrow or shut down drive completely, like Amazon did a year or two ago, your data would be gone and you couldn't do anything about it. And that is a risk you will have to accept if you want cheap cloud storage.2 points
-

Drivepool apperantly causing BSOD after 1803 update
Christopher (Drashna) and one other reacted to gamechld for a question
Issue resolved by updating DrivePool. My version was fairly out of date, and using the latest public stable build fixed everything.2 points -

Correct way to apply PrimoCache write cache
Christopher (Drashna) and one other reacted to zeroibis for a question
I think I found where my issue was occurring, I am being bottle necked by the windows OS cache because I am running the OS off a SATA SSD. I need to move that over to part of the 970 EVO. I am going to attempt that OS reinstall move later and test again. Now the problem makes a lot more sense and is why the speeds looked great in benchmarks but did not manifest in real world file transfers.2 points -
Ok solution is that you need to manually create the virtual drive in powershell after making the pool: 1) Create a storage pool in the GUI but hit cancel when it asks to create a storage space 2) Rename the pool to something to identify this raid set. 3) Run the following command in PowerShell (run with admin power) editing as needed: New-VirtualDisk -FriendlyName VirtualDriveName -StoragePoolFriendlyName NameOfPoolToUse -NumberOfColumns 2 -ResiliencySettingName simple -UseMaximumSize2 points
-
Moving from WHS V1
TAdams and one other reacted to Christopher (Drashna) for a question
Windows Server 2016 Essentials is a very good choice, actually! It's the direct successor to Windows Home Server, actually. The caveat here is that it does want to be a domain controller (but that's 100% optional). Yeah, the Essentials Experience won't really let you delete the Users folder. There is some hard coded functionality here, which ... is annoying. Depending on how you move the folders, "yes". Eg, it will keep the permissions from the old folder, and not use the ones from the new folder. It's quite annoying, and why some of my automation stuff uses a temp drive and then moves stuff to the pool. If you're using the Essentials stuff, you should be good. But you should check out this: https://tinkertry.com/ws2012e-connector https://tinkertry.com/how-to-make-windows-server-2012-r2-essentials-client-connector-install-behave-just-like-windows-home-server2 points -

Recommended SSD setting?
Christopher (Drashna) and one other reacted to Jaga for a question
Even 60 C for a SSD isn't an issue - they don't have the same heat weaknesses that spinner drives do. I wouldn't let it go over 70 however - Samsung as an example rates many of their SSDs between 0 and 70 as far as environmental conditions go. As they are currently one of the leaders in the SSD field, they probably have some of the stronger lines - other manufacturers may not be as robust.2 points -
The Disk Space Equalizer plug-in comes to mind. https://stablebit.com/DrivePool/Plugins2 points
-

Q: 2 x M1015 or 1 x M1015 + RES2CV360?
Christopher (Drashna) and one other reacted to p3x-749 for a question
...just to chime in here...remember that expanders have firmware too. I am running 1x M1015 + 1x RES2SV240 in my 24bay rig for 5+ years now....I remember that there was a firmware update for my expander that improved stability with S-ATA drives (which is the standard usecase for the majority of the semi-pro users here, I think). Upgrading the firmware could be done with the same utility as for the HBA, as far as I remember...instructions were in the firmware readme Edit: here's a linbk for a howto: https://lime-technology.com/forums/topic/24075-solved-flashing-firmware-to-an-intel-res2xxxxx-expander-with-your-9211-8i-hba/?tab=comments#comment-218471 regards, Fred2 points -
As per your issue, I've obtained a similar WD M.2 drive and did some testing with it. Starting with build 3193 StableBit Scanner should be able to get SMART data from your M.2 WD SATA drive. I've also added SMART interpretation rules to BitFlock for these drives as well. You can get the latest development BETAs here: http://dl.covecube.com/ScannerWindows/beta/download/ As for Windows Server 2012 R2 and NVMe, currently, NVMe support in the StableBit Scanner requires Windows 10 or Windows Server 2016.2 points
-
is DrivePool 3 being worked on?
evaG and one other reacted to Christopher (Drashna) for a question
"Release Final" means that it's a stable release, and will be pushed out to everyone. Not that it's the final build. Besides, we have at least 7 more major features to add, before even considering a 3.0.2 points -

Using Clouddrive on Windows Server Datacenter 2016 - Never Mounts
Christopher (Drashna) and one other reacted to qwiX for a question
I'm using Windows Server 2016 Datacenter (GUI Version - newest updates) on a dual socket system in combination with CloudDrive (newest version). The only problem I had, was to connect with the Internet Explorer to the cloud service. Using a 3rd party browser solved this. But I'm always using ReFS instead of NTFS...2 points -
not authorized, must reauthorize
Renstur and one other reacted to wolfhammer for a question
I need to do this daily, is there a way to auto authorize? otherwise i cant really use this app.2 points -

Build Advice Needed
RJGNOW and one other reacted to HellDiverUK for a question
Ah yes, I meant to mention BlueIris. I run it at my mother-in-law's house on an old Dell T20 that I upgraded from it's G3220 to a E3-1275v3. It's running a basic install of Windows 10 Pro. I'm using QuickSync to decode the video coming from my 3 HikVision cameras. Before I used QS, it was sitting at about 60% CPU use. With QS I'm seeing 16% CPU at the moment, and also a 10% saving on power consumption. I have 3 HikVision cameras, two are 4MP and one is 5MP, and are all running at their maximum resolution. I record 24/7 on to an 8TB WD Purple drive, with events turned on. QuickSync also seems to be used for transcoding video that's accessed by the BlueIris app (can highly recommend the app, it's basically the only way we access the system apart from some admin on the server's console). Considering Quicksync has improved greatly in recent CPUs (basically Skylake or newer), you should have no problems with an i7-8700K. I get great performance from a creaky old Haswell.2 points










