


RG9400
-
Posts
28 -
Joined
-
Last visited
-
Days Won
3
RG9400's Achievements
-
 The Tran reacted to an answer to a question:
Google drive not supported after may 2024? Why?
The Tran reacted to an answer to a question:
Google drive not supported after may 2024? Why?
-
Mav1986 reacted to an answer to a question:
Google drive not supported after may 2024? Why?
-
Patrik_Mrkva reacted to an answer to a question:
Google drive not supported after may 2024? Why?
-
I would just like to say that this is fairly disappointing to hear. Though they added limits, a lot of people are still able to work within those limits. And the corruption issue hasn't been present for many years as far as I can tell -- the article in the announcement by Alex is from April 2019, so over 5 years ago. I get the desire to focus resources though, and I'm glad it still works in the background for now. Hopefully there are no breaking changes from Google, and I hope an individual API key is going to have reasonable limits for the drive to continue working. But yeah, switching providers is not very realistic in my case, so I guess I'll use it until it just breaks.
-
Version 1.2.0.1386 BETA I noticed a few versions ago/a week or two ago, that my CloudDrive was not uploading the same amount of data it normally did. It seems to get stuck at random points, and it would then start a pinning metadata task. After the task is done, the amount cached locally (at least reported by CloudDrive) decreases, and the amount to upload increases. The change is usually only around 5 GB, but since this happens every few hours, it compounds to slow down the overall upload. I ran a chkdsk on every partition in the drive, and I even forced a startup recovery in case it needed to reindex all the local data. However, it's started occurring again. Has anyone else noticed this or is aware of the solution? I don't see any actual errors
-
The DrivePool disk works in Docker containers using a WSL2 backend, but the performance is abysmal, especially compared to the CIFS mount I was using before. I've gone back to CIFS for now. A Plex library scan took almost 2 hours using the DrivePool automount. As a CIFS volume, the same folder was scanned in 5 minutes.
-
I can confirm, seems my DrivePool is accessible from WSL 2 now, and I can mount and use it from Docker containers like any other DrvFs mount (automounted Windows volumes).
-
In the meantime, if anyone wants to get this working with Docker for Win using WSL2 as a backend, you actually don't have to do too much complex stuff. If you use compose, you can create a named volume like below, and then mount this into other containers. Performance is what you would expect from a CIFS mount...not sure if DrvFs is better or not, but it works at least volumes: drivepool: driver_opts: type: cifs o: username=${DRIVEPOOLUSER},password=${DRIVEPOOLPASS},iocharset=utf8,rw,uid=${PUID},gid=${PGID},nounix,file_mode=0777,dir_mode=0777 device: \\${HOSTIP}\${DRIVEPOOLSHARE}
-
RG9400 reacted to a question:
WSL 2 support
-
RG9400 reacted to a question:
WSL2 Support for drive mounting
-
+1 from my side. I've been using WSL2 extensively, and it's been hard to work around DrivePool's lack of support. Windows is heading in a direction where it works in harmony with Linux, so it would be nice for the software to be able to support that. I am able to cd to various directories on the mount that Windows does natively, but I can't actually list out any files, and no software running within WSL2 can see them either.
-
I did some reorganizing, and I basically created a pool of pools. The pool contains an HDD pool (a bunch of local hard disks) and a CloudDrive pool (a bunch of CloudDrive partitions). Now the optimizer plugin seems to be available, and I can properly set the HDD pool as the SSD, and the CloudDrive pool as the Archive. This seems fairly close to what I want, but I still don't know how the balancing would work. 1. Does it try to move *all* files off the SSD into the archive in the first balancing run? Does it run for a set amount of time, or once it starts, it will try to move everything? Reason is that I have a ton of data on the HDD pool that cannot move to the SSD pool right away. I only see a way to immediately balance or to balance at a set time every day, maybe indicating there is no way to move the files over time 2. Are the files that are being moved inaccessible during this time? Can this create issues if applications like Plex are running? 3. If the balancing is running, and the files being moved are too large in size for my CloudDrive cache, I assume writes will be slowed, and the whole balancing task will still run as and when data is uploaded from the CloudDrive. If, during this time, I add a file, will it get placed on the HDD pool since that is still the SSD? Basically, could I theoretically be running balancing 24/7 where files are being added to the HDD pool as others are being moved to the CloudDrive pool? The concern would be that those files may be inaccessible while being moved, and I guess my cache drive would be perpetually be at 99% capacity with slowed writes and under heavy wear.
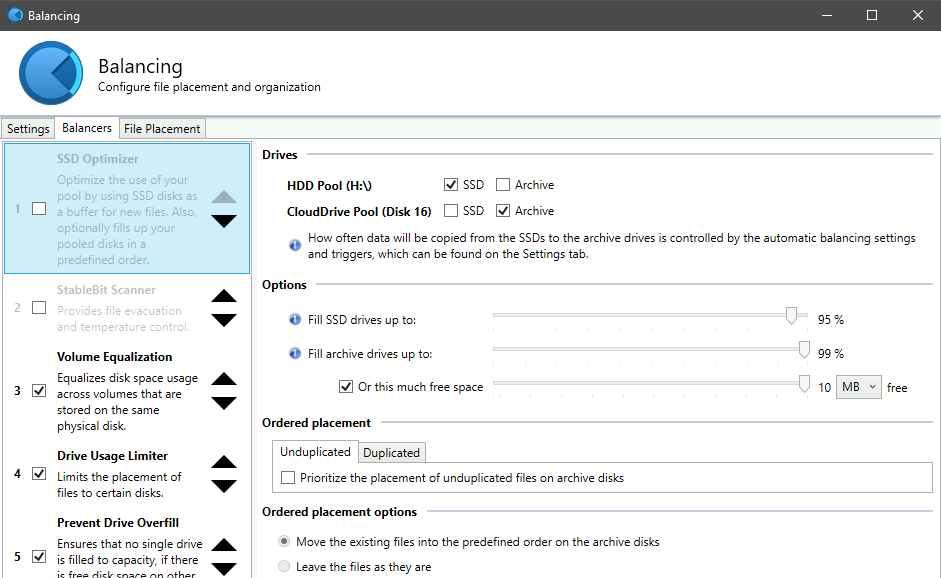

-
Yeah, I knew the cache drive limitation which is unfortunate. I was actually thinking to do it the other way around. Basically the CloudDrive remains on a single SSD cache, and then I add a local hard drive to a pool with the CloudDrive. I set DrivePool to download to the local HDD first, and then use the SSD Optimizer or some other balancing mechanism to move files from the HDD to the CloudDrive. In this manner, the CloudDrive cache remains on a single SSD, but I have an upload buffer via the HDDs. I am not sure if the above is feasible. I think the biggest concern would be how to move the files from local to CloudDrive given that the pool will not see the space of the underlying cache. EDIT: It does not seem like my pool with CloudDrives in it allows the balancing plugins to actually work. The options seem disabled, though I felt the SSD Optimizer Plugin was close to what I wanted in theory where the HDD acted as an "SSD" and the CloudDrive acted as the Archive.
-
I've been thinking about a new setup, and I wanted to float an idea to see if it works (pros/cons). Basically, right now, I have my clouddrive mounted to a single Optane SSD (C:). This works great with speeds, but the drive is limited to 1TB, and with slow upload, this drive is full almost always, so it's hard to copy new data over. For this purpose, I have a bunch of HDDs that I added to a DrivePool pool along with the CloudDrive, and I copy over new data to those pools before manually moving it to the PoolPart folder in C: when the most recent data is uploaded. It is manual and cumbersome. Could I do something like this instead? I create a pool of my HDDs, then add that to the CloudDrive pool. I set up the CloudDrive pool to download new data to the HDD pool, and then use the plugin to move data from the HDD pool to the CloudDrives? This way, my pool sees all the data, but the underlying locations are being managed automatically. If this scenario is feasible, I do have a few questions. 1. If I have a file on the HDD portion, and I do a "move" via my Pool, will it remain on the HDD portion? Will it remain on the same disk it was downloaded to initially? 2. Can I control the plugin so it moves to CloudDrives based on the cache drive space? The CloudDrives will always look empty/have tons of space but my underlying cache may not. I am concerned that the plugin will constantly be trying to move data to the cache drive, resulting in it being full 100% of the time and slowing writes down.
-
 Nick reacted to an answer to a question:
Google Drive API Key switch
Nick reacted to an answer to a question:
Google Drive API Key switch
-
You should be able to Re-Authorize the drive, which would start using the new API key
- 2 replies
-
- 1
-
-
- googledrive
- (and 2 more)
-
I just "Re-Authorized" the drive. You can check by going to the API console, and you should see queries for the Google Drive API -- the Quotas tab is what I am using to monitor it.
-
The main reason is that Windows cannot run various fixes and maintenance on drives more than 64TB (e.g. chkdsk). It cannot mount a partition larger than 128TB either. Some people are also concerned that historically, various partitions got corrupted due to outages at Google, so by limiting the size of any individual partition, you also limit the potential losses
-
Appreciate it, and love the vision for this cloud dashboard. Very excited to see future new features.
-
That makes sense, and it was also my experience after enabling this new feature. One extra development that could really help is to display a changelog against the release notification. It helps to know what new features/bugfixes are being pushed in each release, and it's a bit cumbersome to find the various changelogs for each application (seems beta and final releases for each app have separate txt files).
-
I saw that the latest dev Beta version of CloudDrive allows for automated updates via StableBit Cloud. This seems like a useful feature, but I wanted to know exactly what that meant before I turned it on. Basically, right now, after updating CloudDrive, I have to restart the computer due to something with the drivers. If I get an automated update downloaded, would that mean my computer would restart automatically, or would it need to be manually restarted, or can the various applications now update without a need for restarting the computer? My main worry is that by enabling automatic updates, I end up with something like Windows updates where an update is pushed that causes (either instantly or on a delay) the computer to have to restart.
