Alex
-
Posts
254 -
Joined
-
Last visited
-
Days Won
50
1 Follower

About Alex

Recent Profile Visitors






Alex's Achievements
Advanced Member (3/3)
106
Reputation
-
 Shane reacted to a question:
How to access your cloud drive data after May 15 2024 using your own API key
Shane reacted to a question:
How to access your cloud drive data after May 15 2024 using your own API key
-
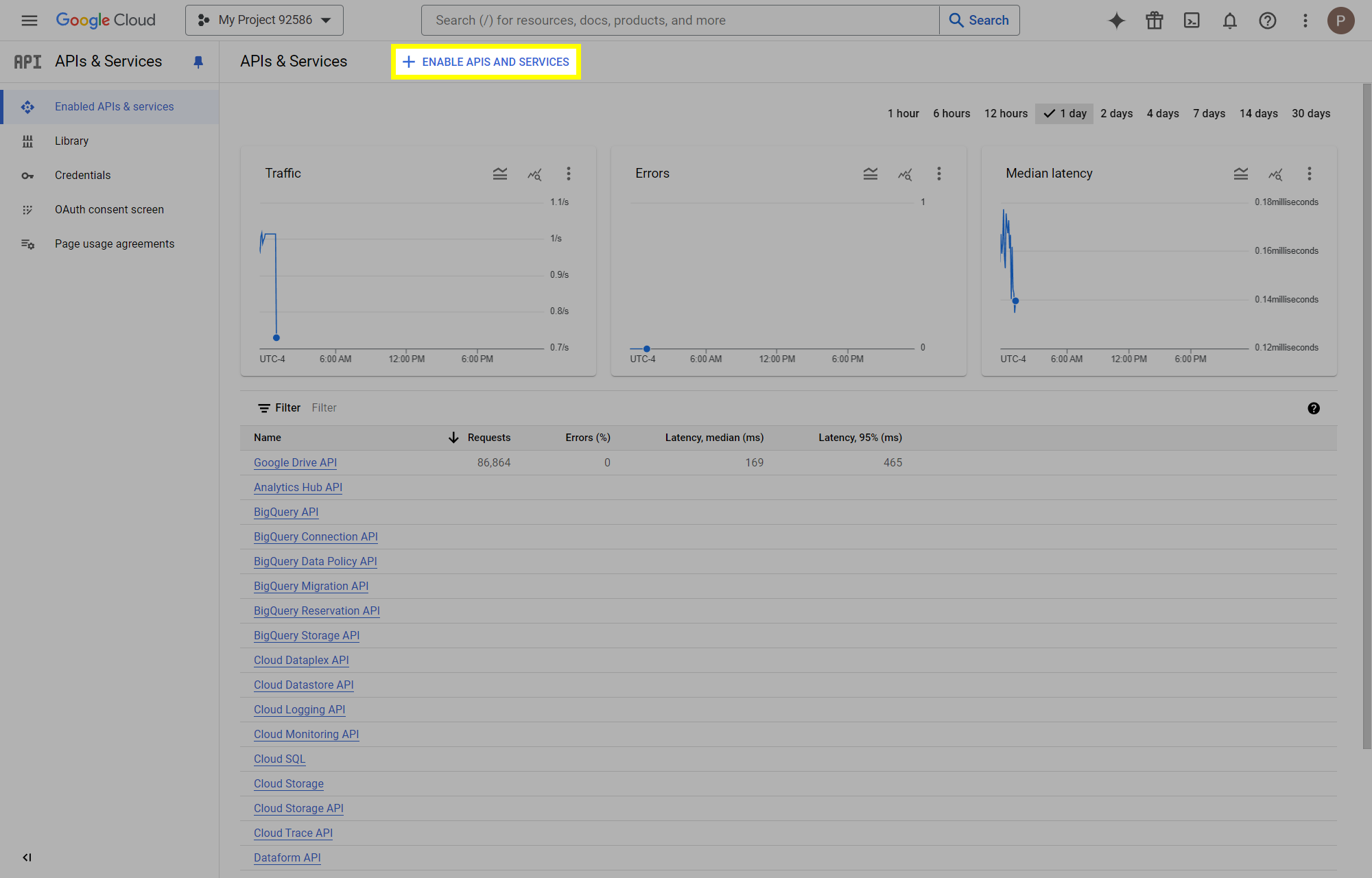
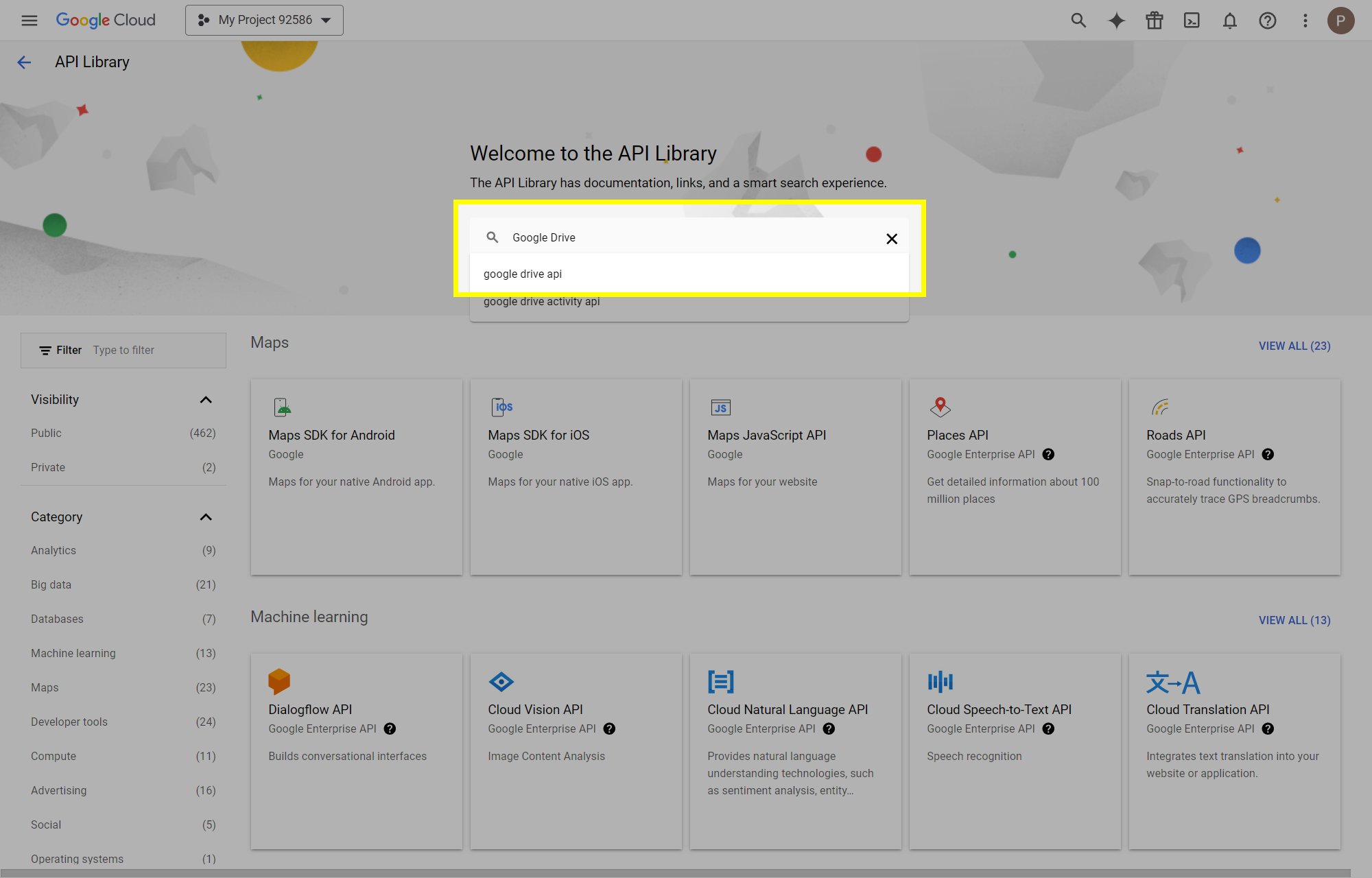
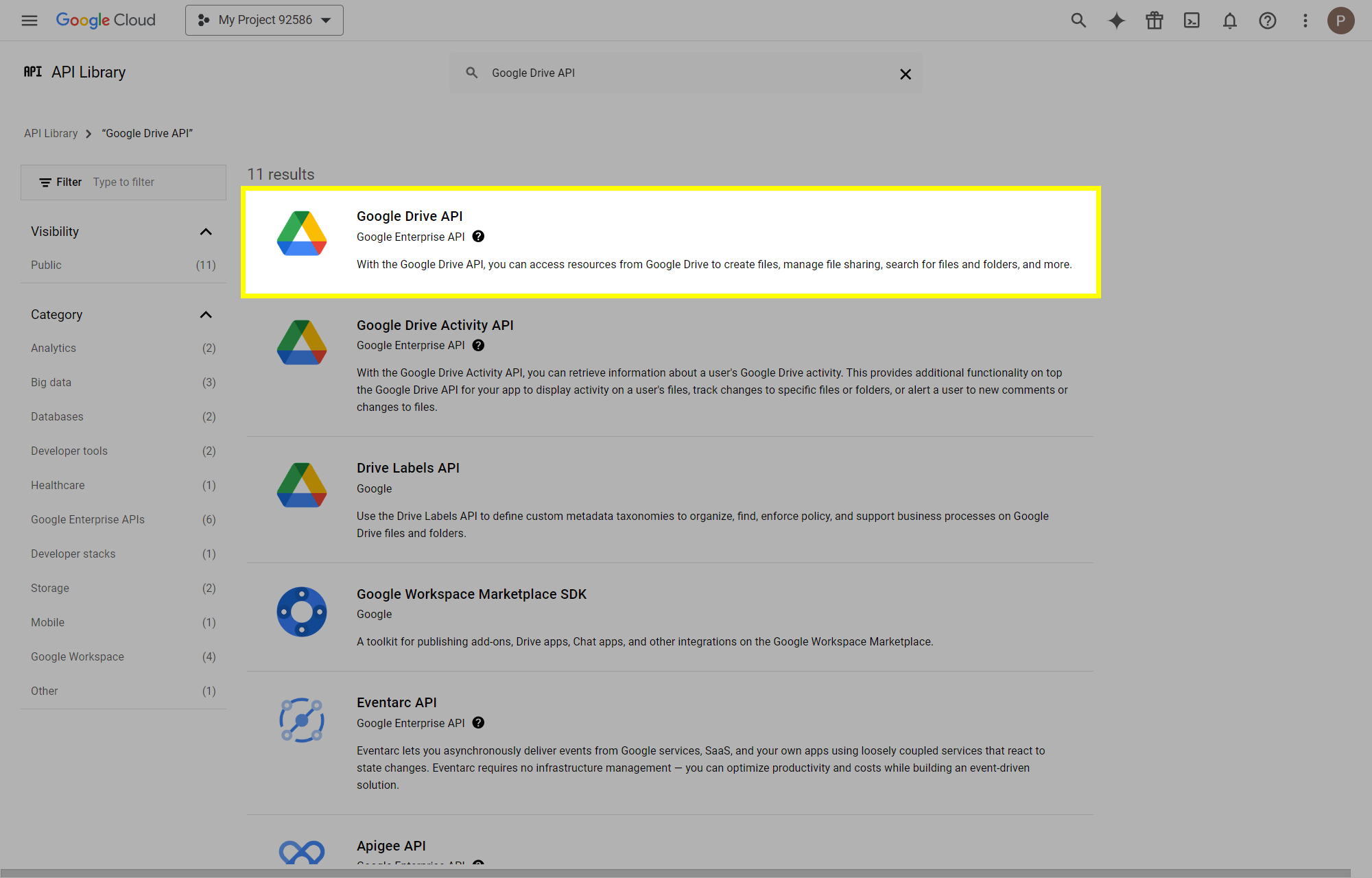
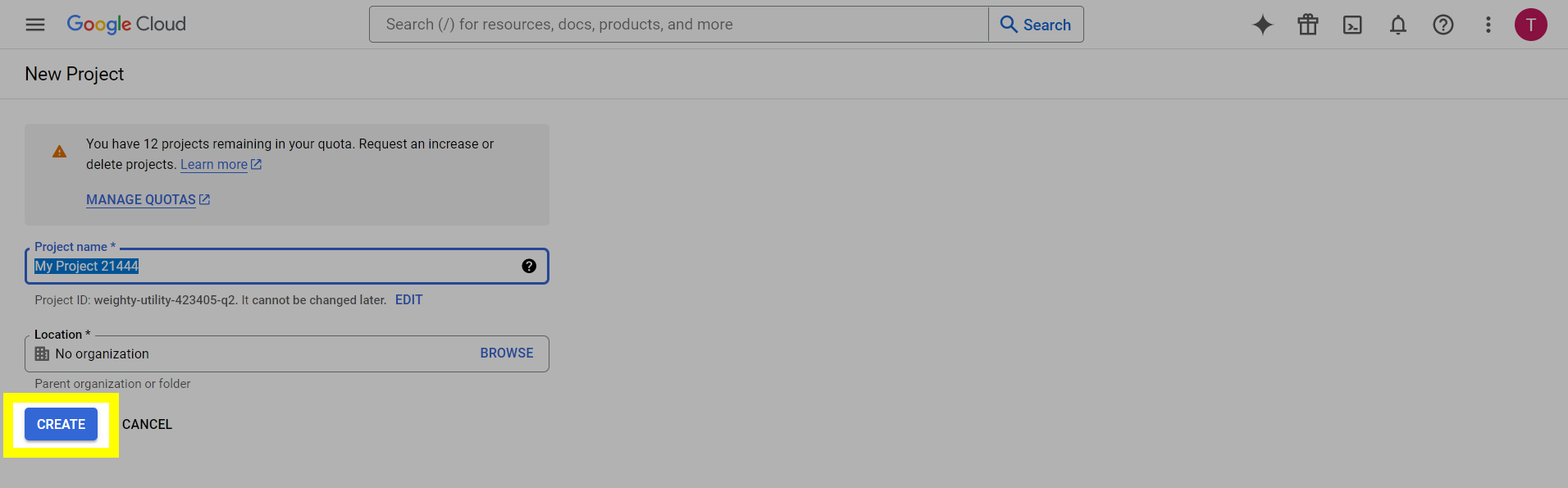
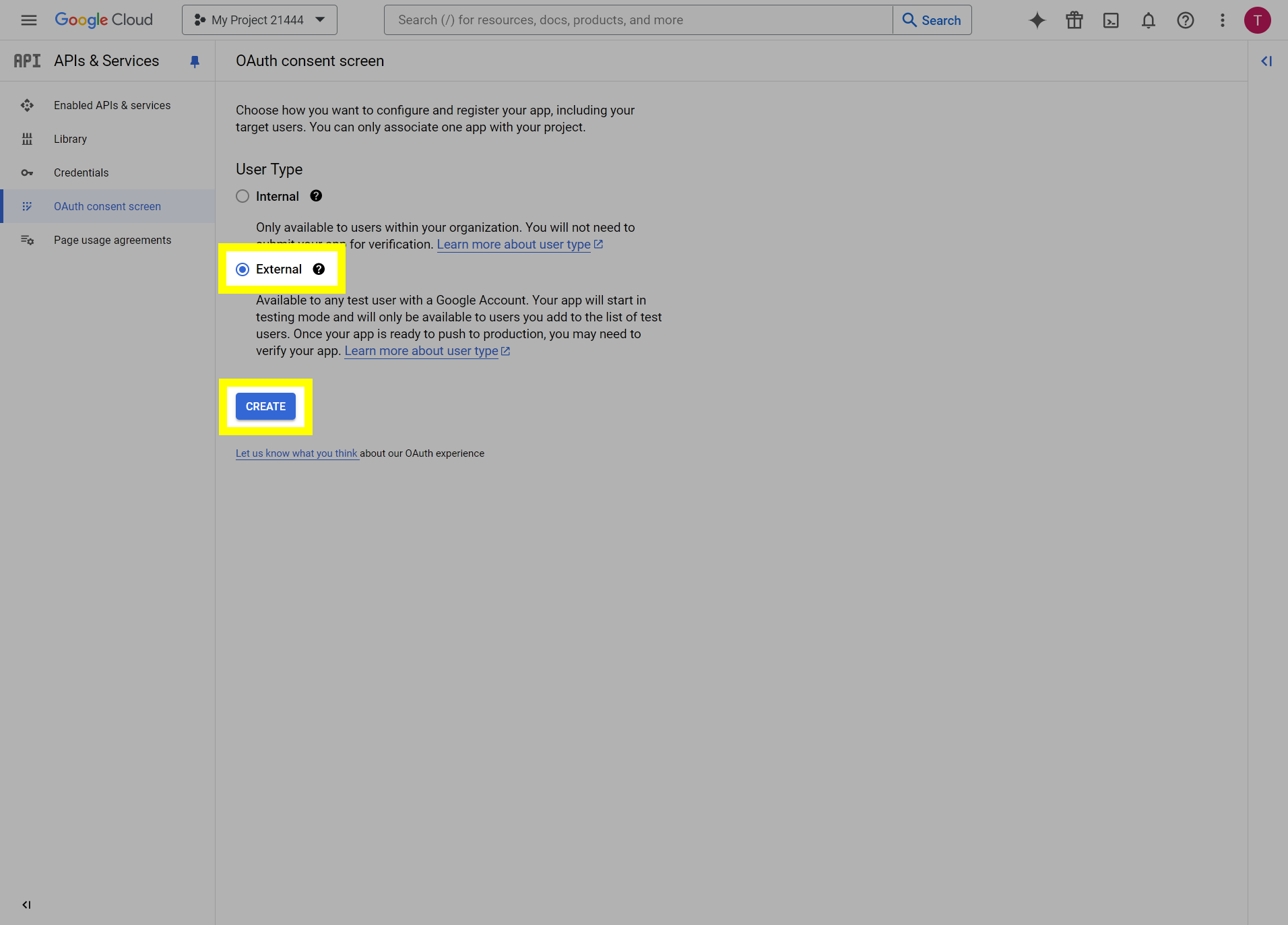
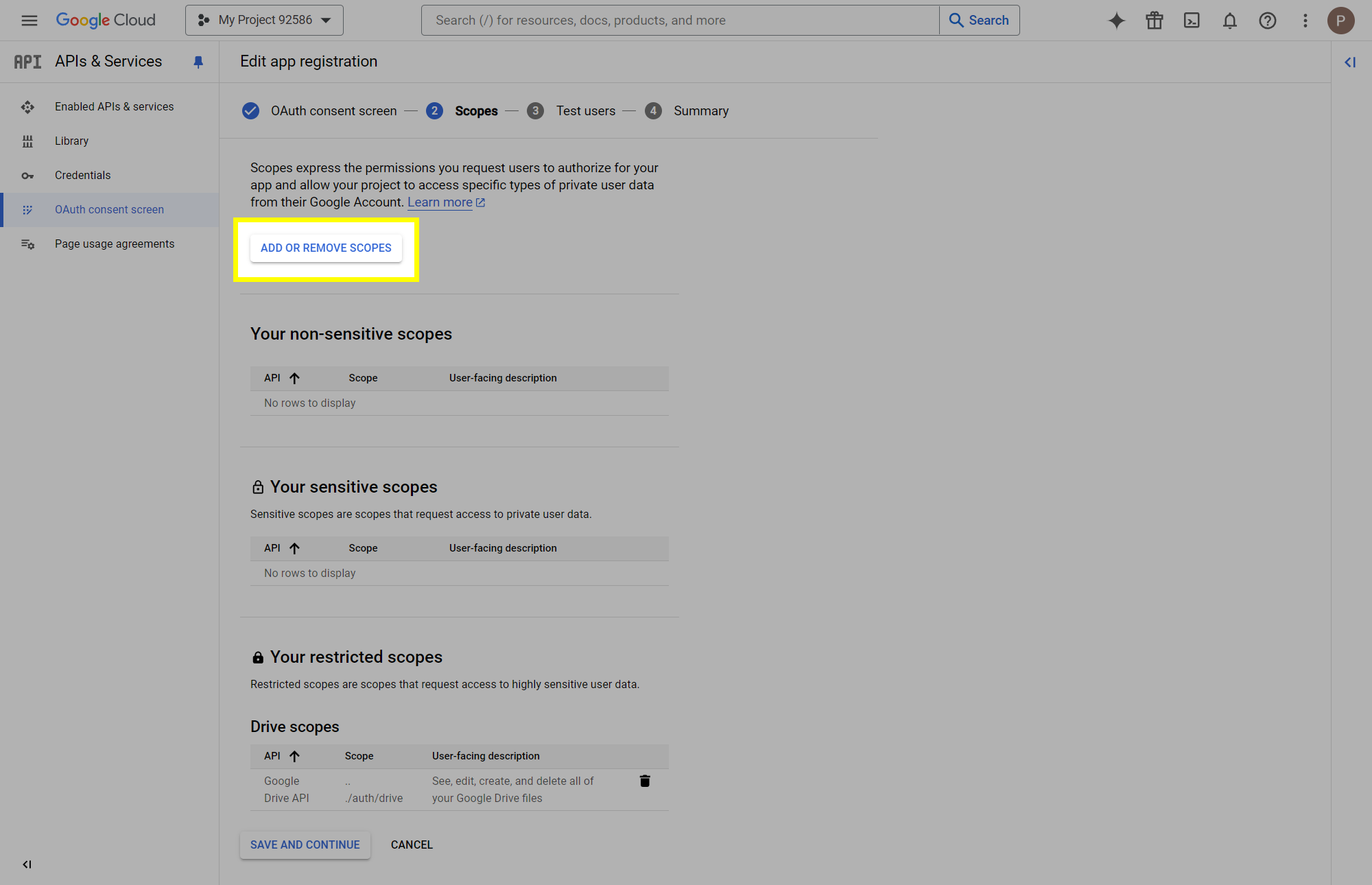
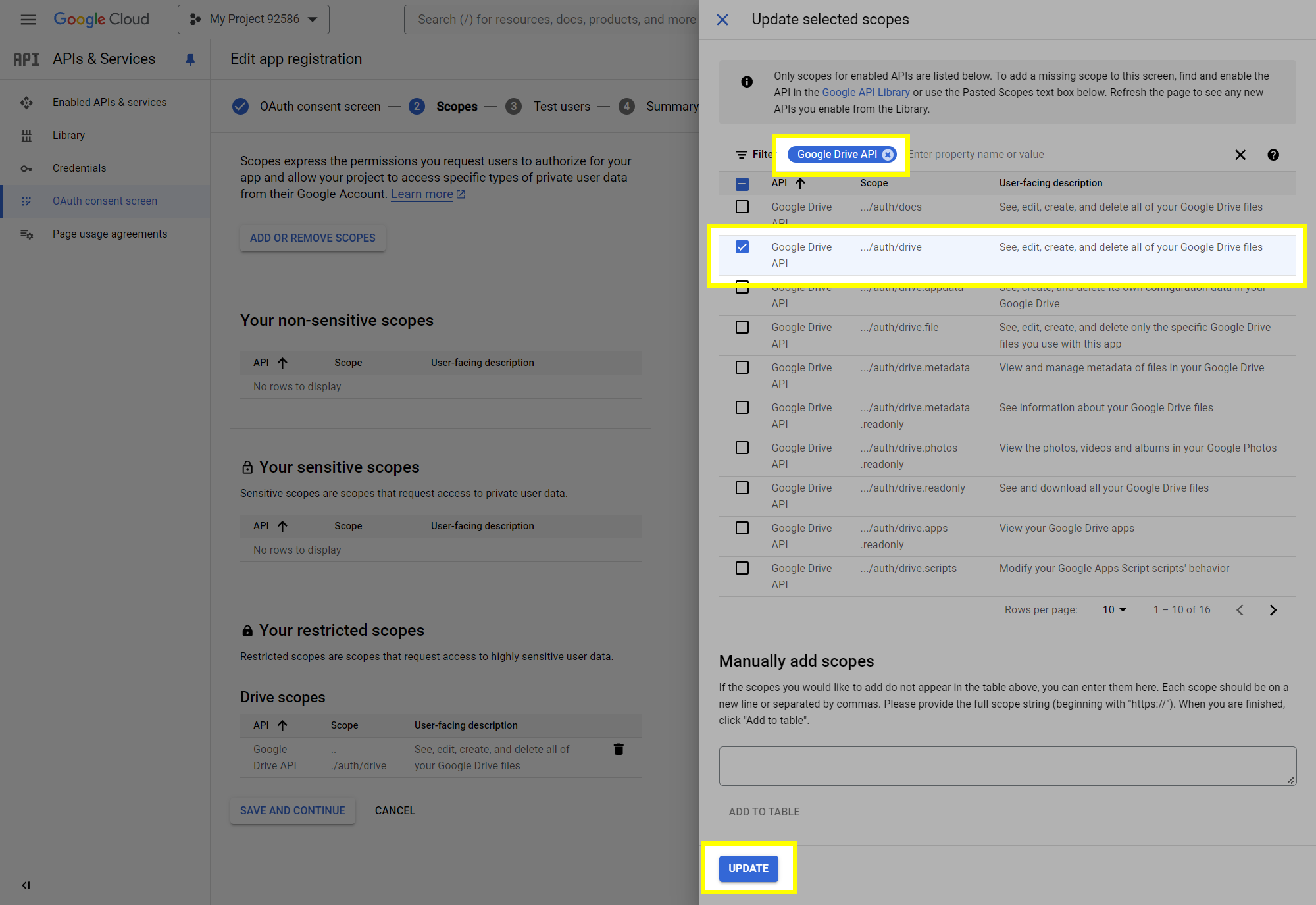
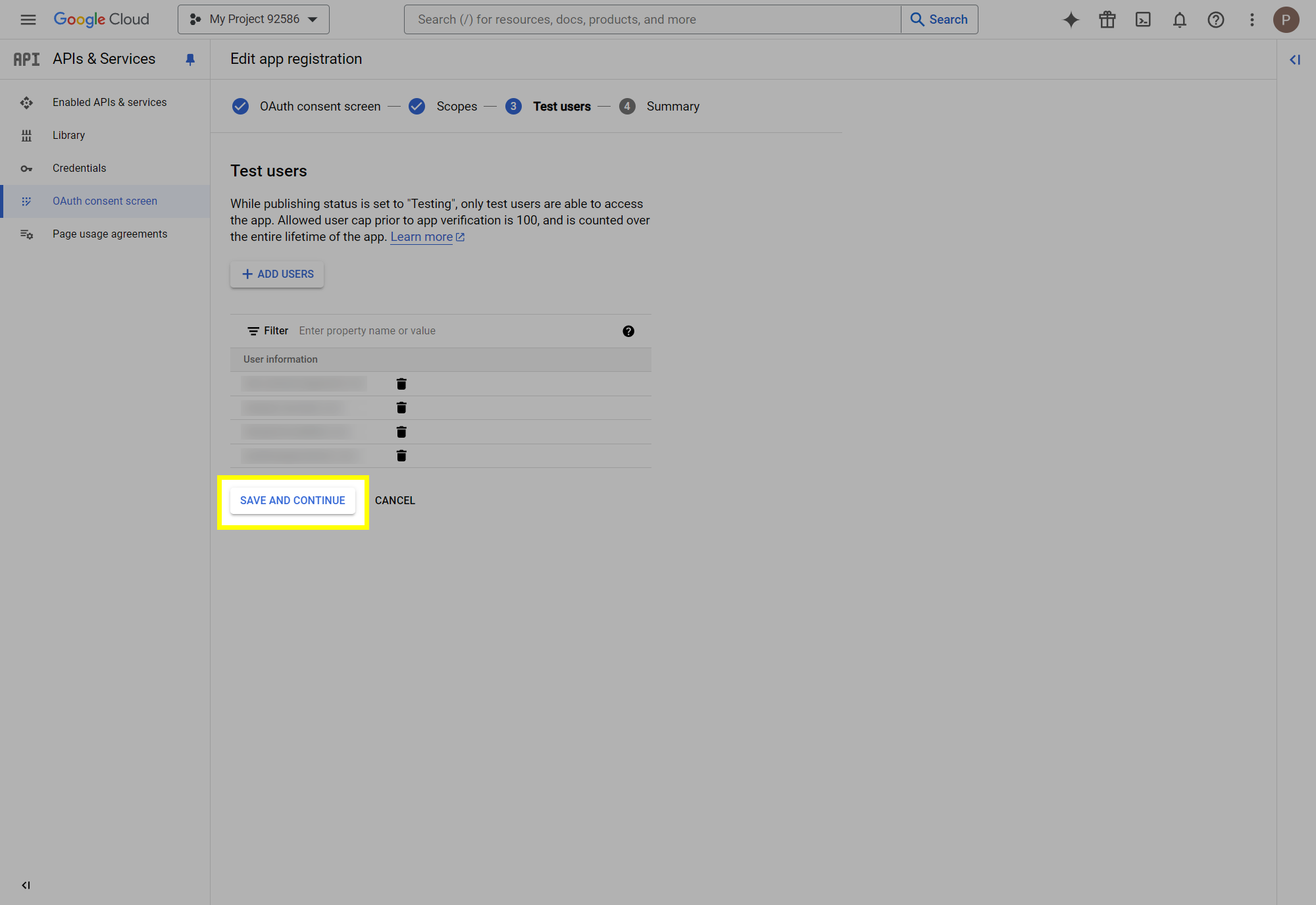
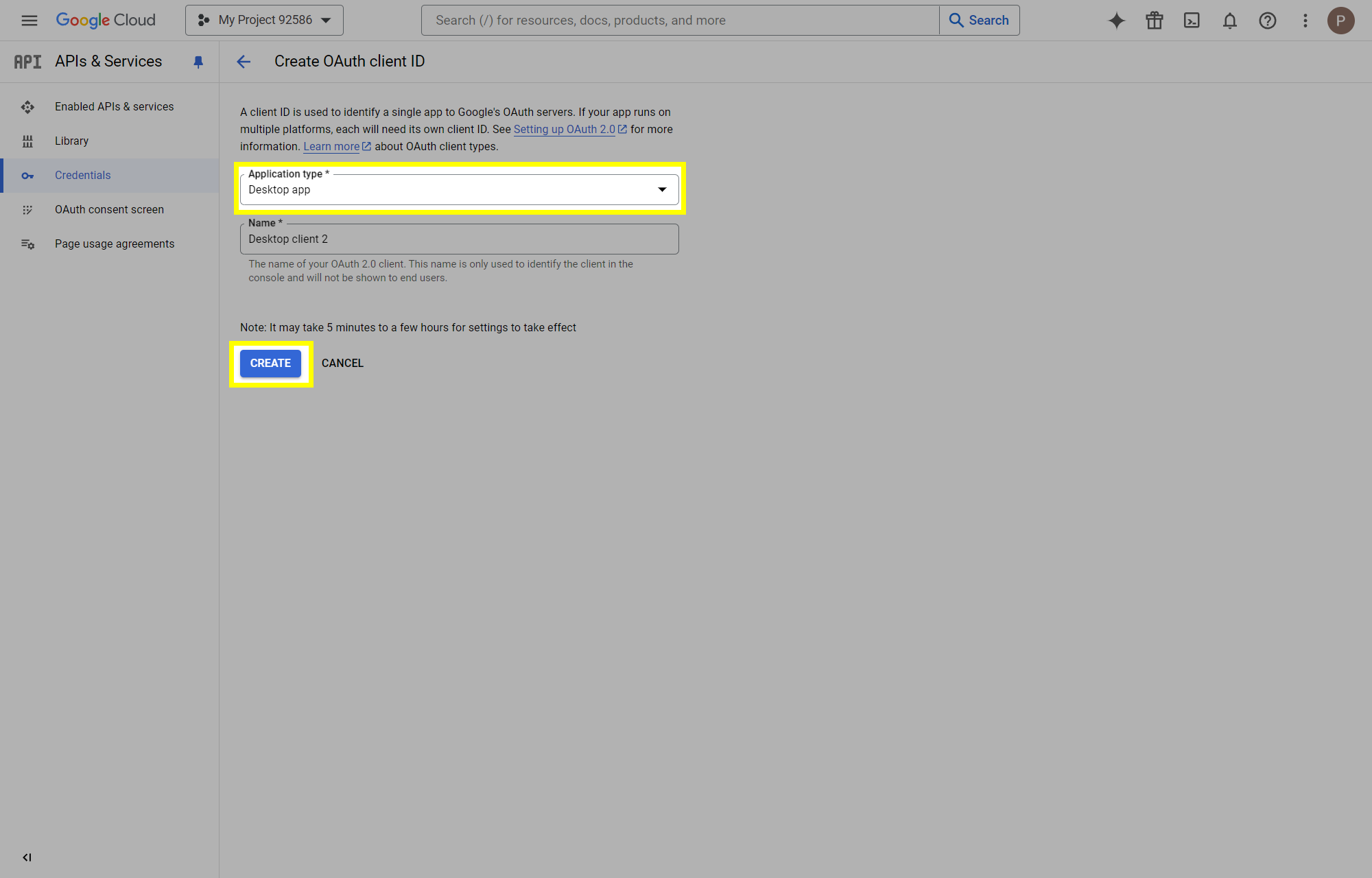
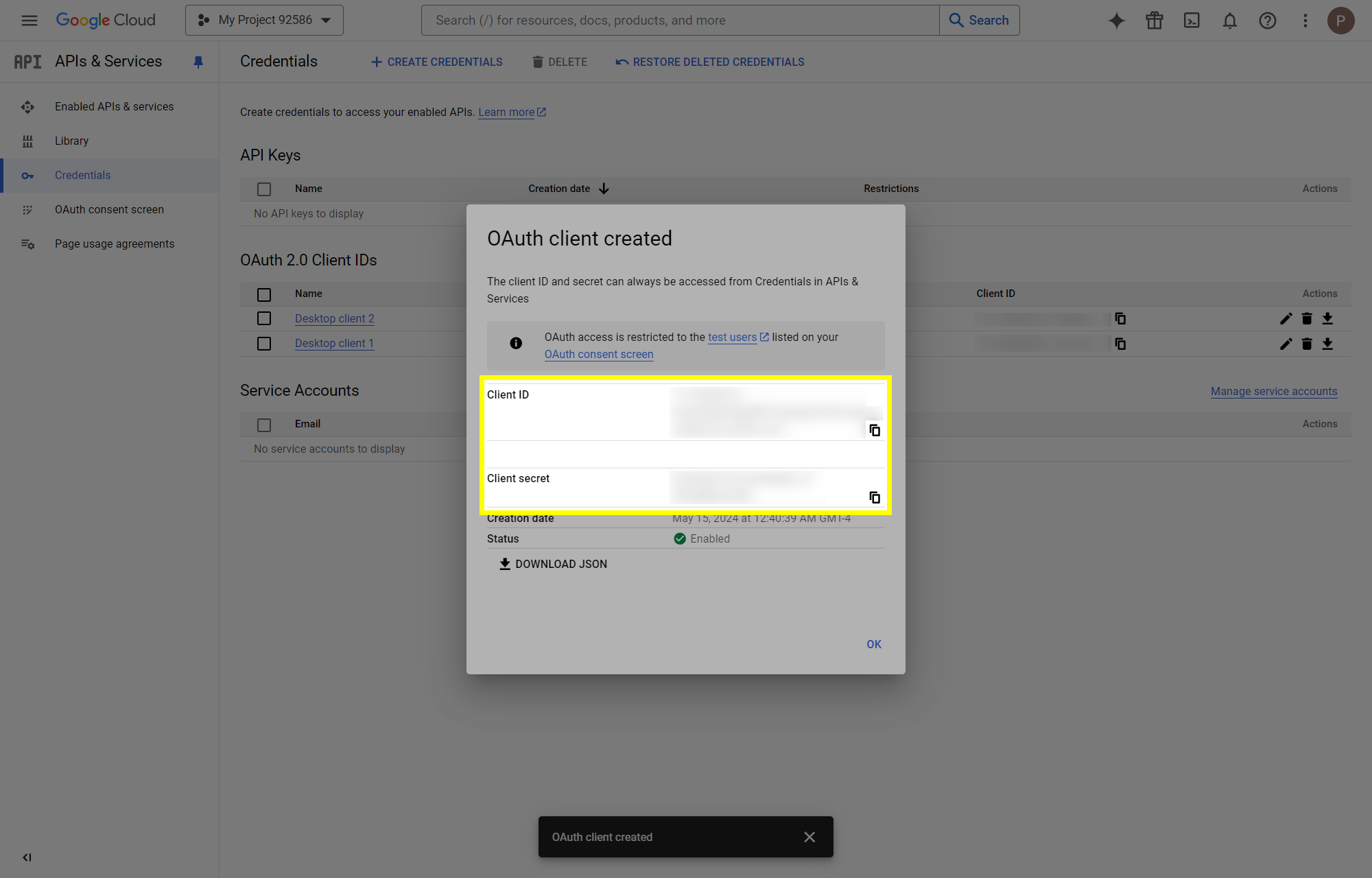
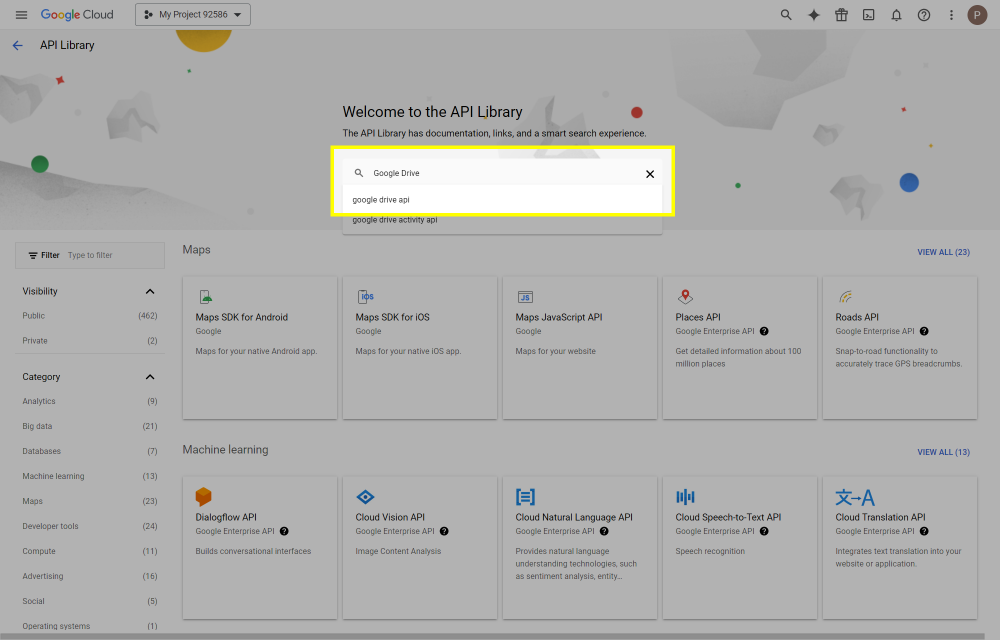
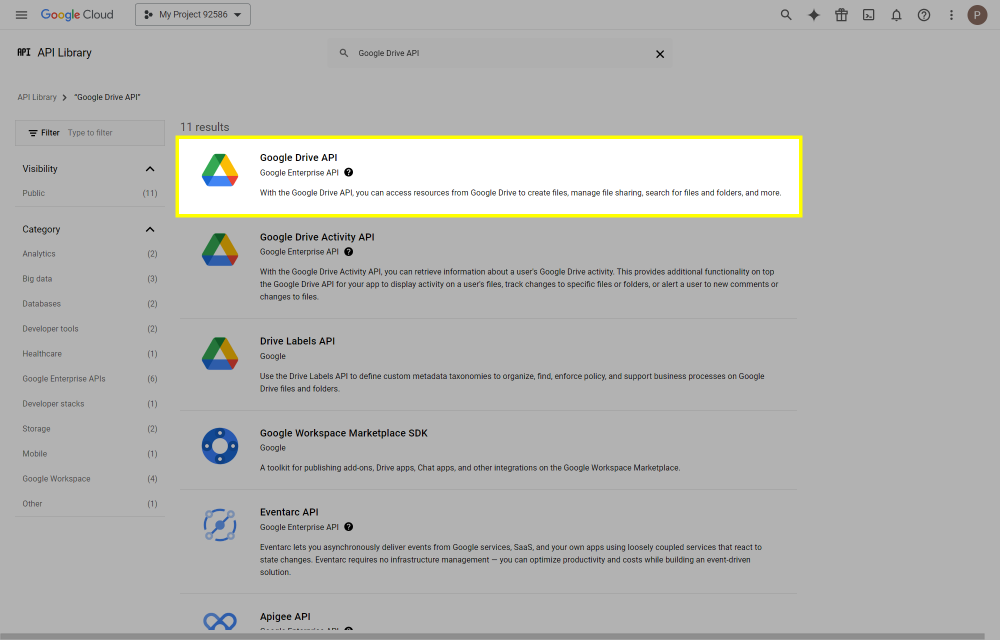
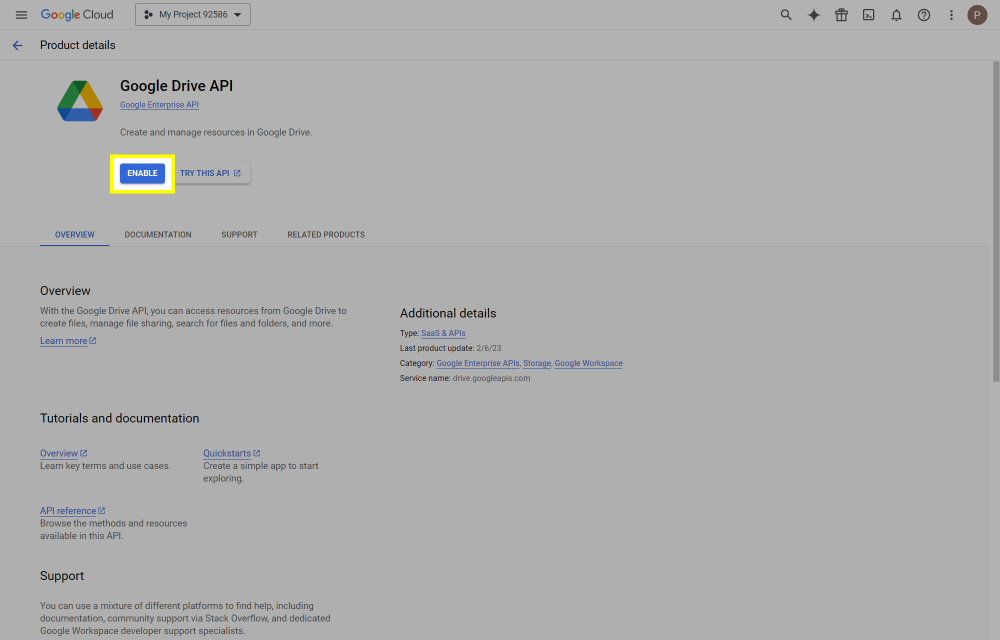
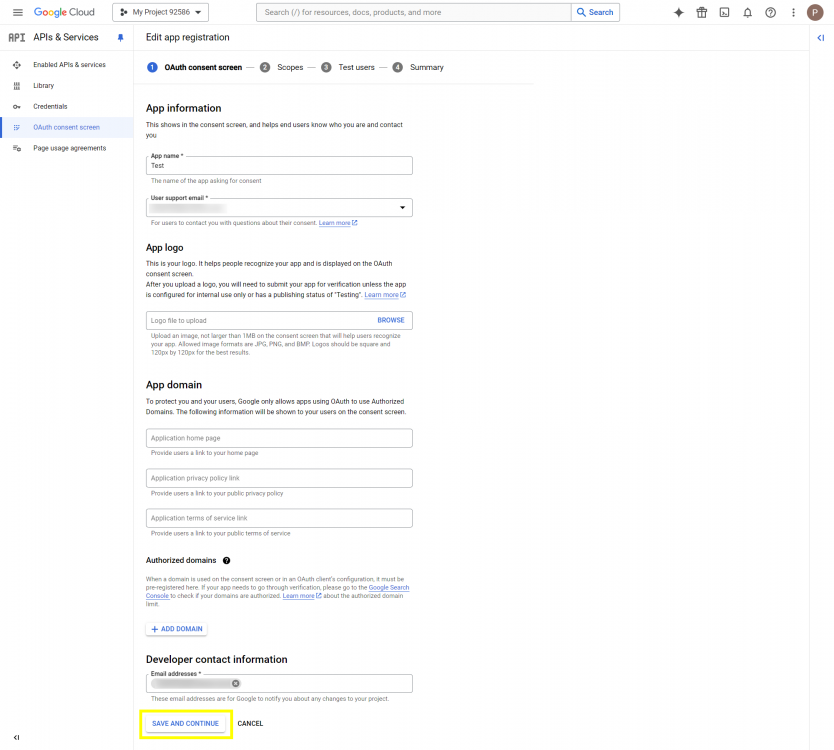
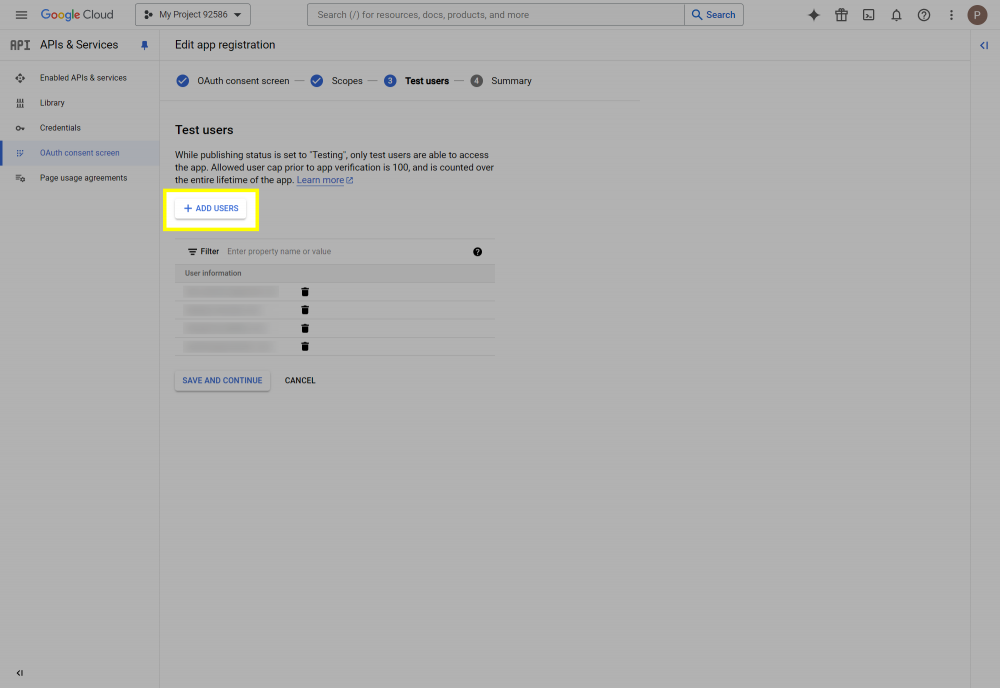
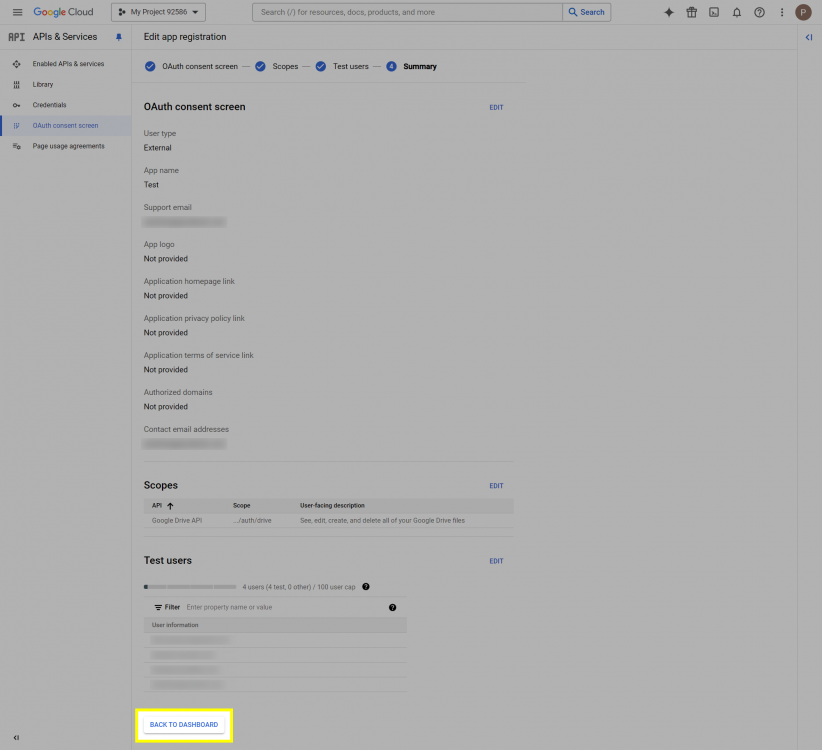
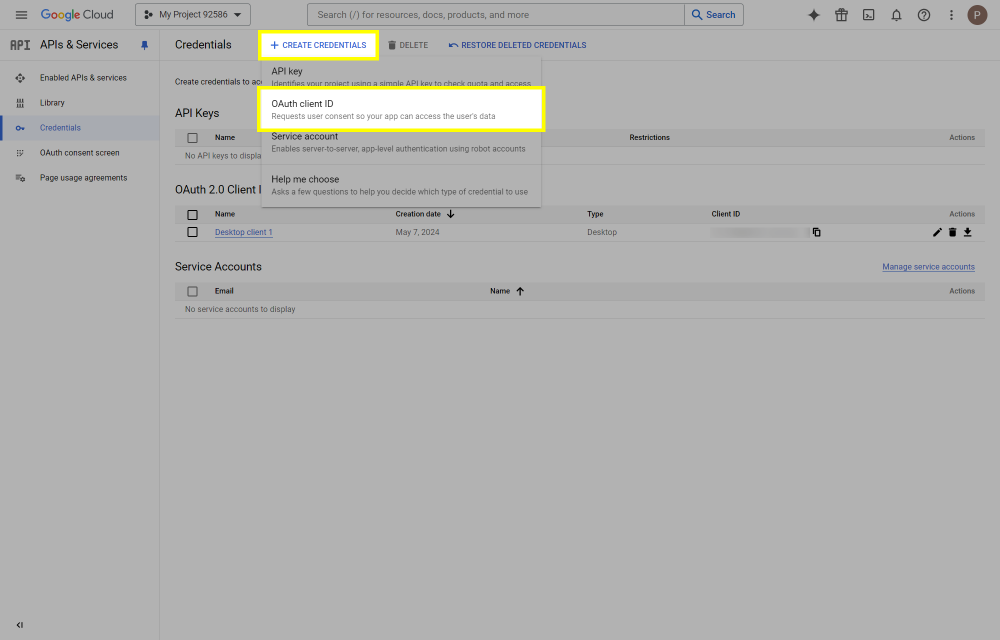
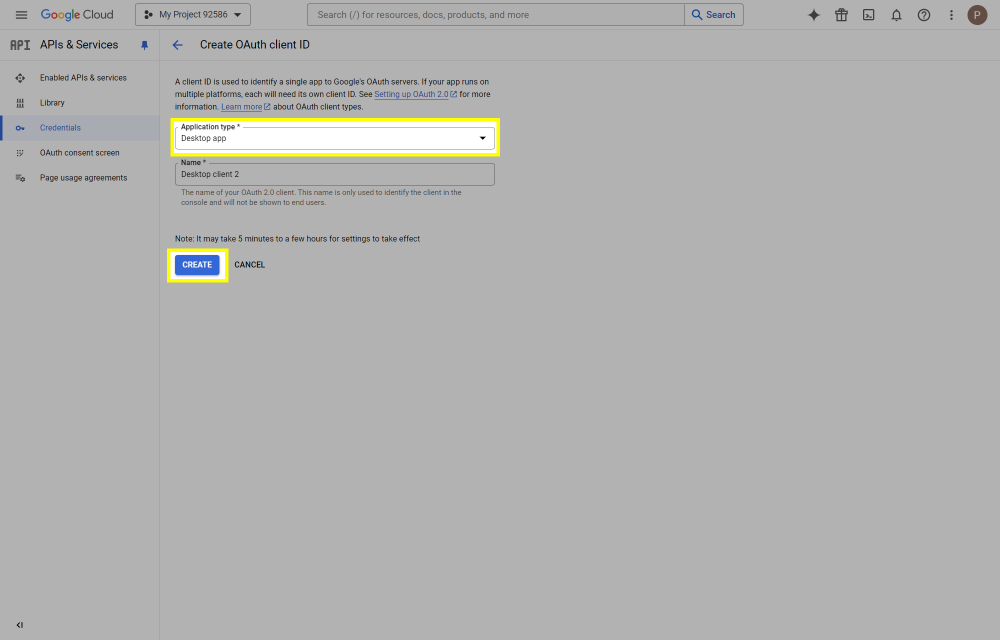
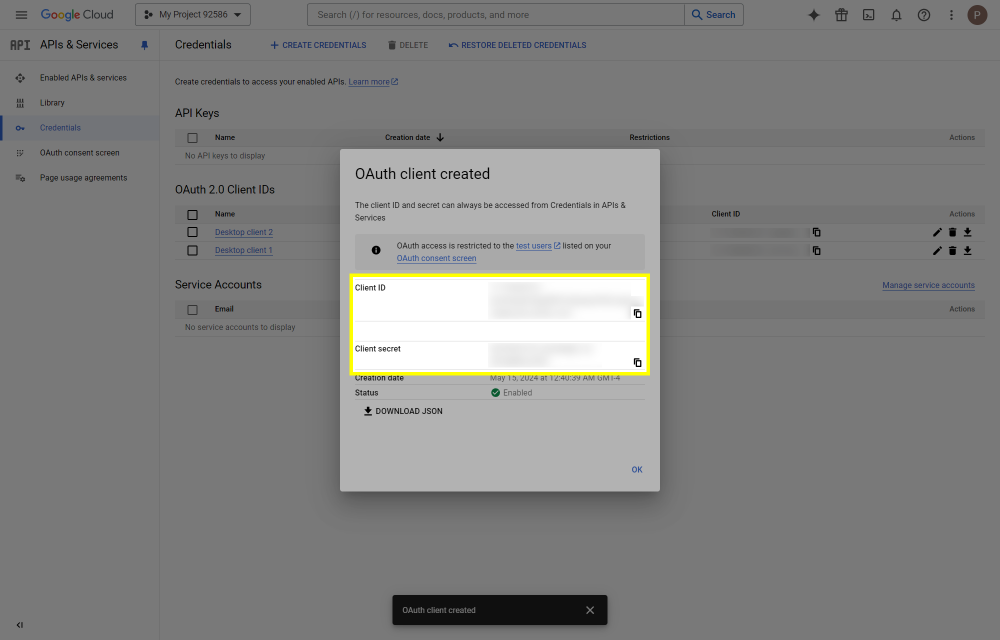
 This post will outline the steps necessary to create your own Google Drive API key for use with StableBit CloudDrive. With this API key you will be able to access your Google Drive based cloud drives after May 15 2024 for data recovery purposes. Let's start by visiting https://console.cloud.google.com/apis/dashboard You will need to agree to the Terms of Service, if prompted. If you're prompted to create a new project at this point, then do so. The name of the project does not matter, so you can simply use the default. Now click ENABLE APIS AND SERVICES. Enter Google Drive API and press enter. Select Google Drive API from the results list. Click ENABLE. Next, navigate to: https://console.cloud.google.com/apis/credentials/consent (OAuth consent screen) Choose External and click CREATE. Next, fill in the required information on this page, including the app name (pick any name) and your email addresses. Once you're done click SAVE AND CONTINUE. On the next page click ADD OR REMOVE SCOPES. Type in Google Drive API in the filter (enter) and check Google Drive API - .../auth/drive Then click UPDATE. Click SAVE AND CONTINUE. Now you will be prompted to add email addresses that correspond to Google accounts. You can enter up to 100 email addresses here. You will want to enter all of your Google account email addresses that have any StableBit CloudDrive cloud drives stored in their Google Drives. Click ADD USERS and add as many users as necessary. Once all of the users have been added, click SAVE AND CONTINUE. Here you can review all of the information that you've entered. Click BACK TO DASHBOARD when you're done. Next, you will need to visit: https://console.cloud.google.com/apis/credentials (Credentials) Click CREATE CREDENTIALS and select OAuth client ID. You can simply leave the default name and click CREATE. You will now be presented with your Client ID and Client Secret. Save both of these to a safe place. Finally, we will configure StableBit CloudDrive to use the credentials that you've been given. Open C:\ProgramData\StableBit CloudDrive\ProviderSettings.json in a text editor such as Notepad. Find the snippet of JSON text that looks like this: "GoogleDrive": { "ClientId": null, "ClientSecret": null } Replace the null values with the credentials that you were given by Google surrounded by double quotes. So for example, like this: "GoogleDrive": { "ClientId": "MyGoogleClientId-1234", "ClientSecret": "MyPrivateClientSecret-4321" } Save the ProviderSettings.json file and restart your computer. Or, if you have no cloud drives mounted currently, then you can simply restart the StableBit CloudDrive system service. Once everything restarts you should now be able to connect to your Google Drive cloud drives from the New Drive tab within StableBit CloudDrive as usual. Just click Connect... and follow the instructions given.
This post will outline the steps necessary to create your own Google Drive API key for use with StableBit CloudDrive. With this API key you will be able to access your Google Drive based cloud drives after May 15 2024 for data recovery purposes. Let's start by visiting https://console.cloud.google.com/apis/dashboard You will need to agree to the Terms of Service, if prompted. If you're prompted to create a new project at this point, then do so. The name of the project does not matter, so you can simply use the default. Now click ENABLE APIS AND SERVICES. Enter Google Drive API and press enter. Select Google Drive API from the results list. Click ENABLE. Next, navigate to: https://console.cloud.google.com/apis/credentials/consent (OAuth consent screen) Choose External and click CREATE. Next, fill in the required information on this page, including the app name (pick any name) and your email addresses. Once you're done click SAVE AND CONTINUE. On the next page click ADD OR REMOVE SCOPES. Type in Google Drive API in the filter (enter) and check Google Drive API - .../auth/drive Then click UPDATE. Click SAVE AND CONTINUE. Now you will be prompted to add email addresses that correspond to Google accounts. You can enter up to 100 email addresses here. You will want to enter all of your Google account email addresses that have any StableBit CloudDrive cloud drives stored in their Google Drives. Click ADD USERS and add as many users as necessary. Once all of the users have been added, click SAVE AND CONTINUE. Here you can review all of the information that you've entered. Click BACK TO DASHBOARD when you're done. Next, you will need to visit: https://console.cloud.google.com/apis/credentials (Credentials) Click CREATE CREDENTIALS and select OAuth client ID. You can simply leave the default name and click CREATE. You will now be presented with your Client ID and Client Secret. Save both of these to a safe place. Finally, we will configure StableBit CloudDrive to use the credentials that you've been given. Open C:\ProgramData\StableBit CloudDrive\ProviderSettings.json in a text editor such as Notepad. Find the snippet of JSON text that looks like this: "GoogleDrive": { "ClientId": null, "ClientSecret": null } Replace the null values with the credentials that you were given by Google surrounded by double quotes. So for example, like this: "GoogleDrive": { "ClientId": "MyGoogleClientId-1234", "ClientSecret": "MyPrivateClientSecret-4321" } Save the ProviderSettings.json file and restart your computer. Or, if you have no cloud drives mounted currently, then you can simply restart the StableBit CloudDrive system service. Once everything restarts you should now be able to connect to your Google Drive cloud drives from the New Drive tab within StableBit CloudDrive as usual. Just click Connect... and follow the instructions given.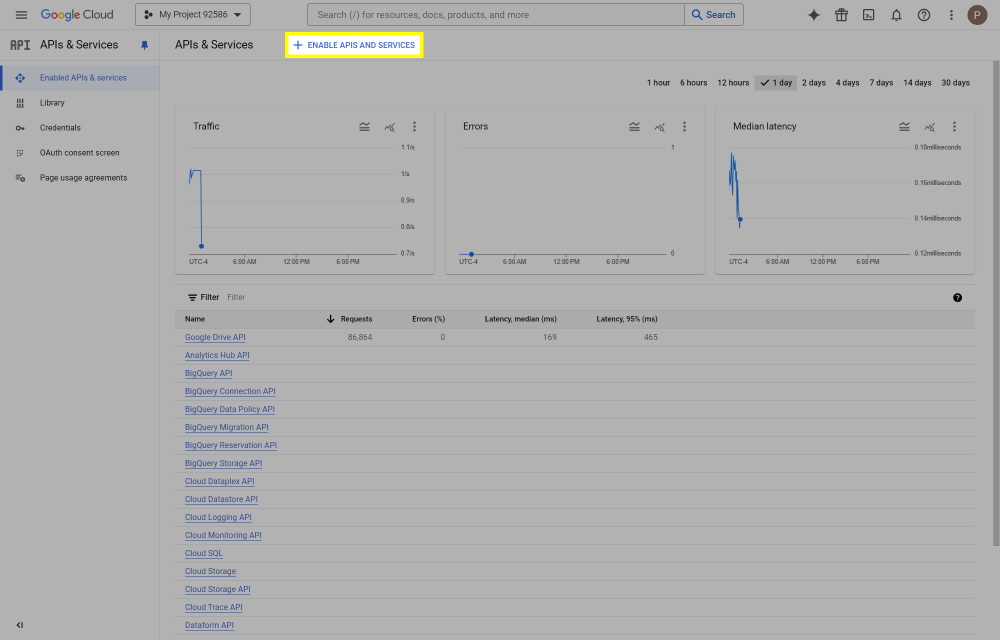






-
Shane reacted to a post in a topic:
Google Drive is Discontinued in StableBit CloudDrive
-
Google Drive support is being discontinued in StableBit CloudDrive. Please make sure to back up all of your data on any existing Google Drive cloud drives to a different location as soon as possible. Google Drive cloud drives will not be accessible after May 15, 2024. FAQ Q: What does this mean? Do I have to do anything with the data on my existing cloud drives that are using the Google Drive storage provider? A: Yes, you do need to take action in order to continue to have access to your data stored on Google Drive. You need to make a copy of all of the data on your Google Drive cloud drives to another location by May 15, 2024. Q: What happens after Google Drive support is discontinued in StableBit CloudDrive? What happens to any data that is still remaining on my drives? A: Your Google Drive based cloud drives will become inaccessible after May 15, 2024. Therefore, any data on those drives will also be inaccessible. It will technically not be deleted, as it will still continue to be stored on Google Drive. But because StableBit CloudDrive will not have access to it, you will not be able to mount your drives using the app. Q: Is there any way to continue using Google Drive with StableBit CloudDrive after the discontinue date? A: You can, in theory, specify your own API keys in our ProviderSettings.json file and continue to use the provider beyond the discontinue date, but this is not recommended for a few reasons: Google Drive is being discontinued because of reliability issues with the service. Continuing to use it puts your data at risk, and is therefore not recommended. We will not be actively updating the Google Drive storage provider in order to keep it compatible with any changes Google makes to their APIs in the future. Therefore, you may lose access to the drive because of some future breaking change that Google makes. Q: What happens if I don't backup my data in time? Is there any way to access it after the discontinue date? A: Yes. Follow the instructions here: Alternatively, it's also possible to download your entire CloudPart folder from Google Drive. The CloudPart folder represents all of your cloud drive data. You can then run our conversion tool to convert this data to a format that you can mount locally using the Local Disk storage provider. The conversion tool is located here: C:\Program Files\StableBit\CloudDrive\Tools\Convert\CloudDrive.Convert.exe The steps to do this would be: Log in to your Google Drive web interface ( https://drive.google.com/ ). Find the CloudPart... folder that you would like to recover under the root "StableBit CloudDrive" folder. Each CloudPart folder represents a cloud drive, identified by a unique number (UID). Download the entire CloudPart folder (from the Google Drive web interface, click the three dots to the right of the folder name and click Download). This download may consist of multiple files, so make sure to get them all. Decompress the downloaded file(s) to the same location (e.g. G:\CloudPart-1ddb5a50-cae2-456a-a017-b48c254088b3) Run our conversion tool from the command line like so: CloudDrive.Convert.exe GoogleDriveToLocalDisk G:\CloudPart-1ddb5a50-cae2-456a-a017-b48c254088b3 After the conversion, the folder will be renamed to: G:\StableBit CloudDrive Data (1e6884be-b748-43db-a78c-a4a2c720ceef) After the conversion completes, open StableBit CloudDrive and connect the Local Disk provider to the parent folder where the converted CloudPart folder is stored. For example, If your cloud part is stored in G:\StableBit CloudDrive Data (1e6884be-b748-43db-a78c-a4a2c720ceef), connect your Local Disk provider to G:\ (you can also use the three dots (...) to connect to any sub-folder, if necessary). You will now see your Google Drive listed as a local cloud drive, and you can attach it just like any other cloud drive. If you need further assistance with this, feel free to get in touch with technical support, and we will do our best to help out: https://stablebit.com/Contact Q: Why is Google Drive being discontinued? A: Over the years we've seen a lot of data consistency issues with Google Drive (spontaneously duplicating chunks, disappearing chunks, chunks reverting to a previous historic state, and service outages), some of which were publicized: https://www.zdnet.com/article/google-heres-what-caused-sundays-big-outage For that last one, we actually had to put in an in-app warning cautioning people against the use of Google Drive because of these issues. Recently, due to a change in policy, Google is forcing all third-party apps (that are using a permissive scope) to undergo another reverification process. For the reasons mentioned above, we have chosen not to pursue this reverification process and are thus discontinuing Google Drive support in StableBit CloudDrive. We do apologize for the great inconvenience that this is causing everyone, and we will aim not to repeat this in the future with other providers. Had we originally known how problematic this provider would be, we would have never added it in the first place. To this end, in the coming months, we will be refocusing StableBit CloudDrive to work with robust object-based storage providers such as Amazon S3 and the like, which more closely align with the original design goals for the app. If you have any further questions not covered in this FAQ, please feel free to reach out to us and we will do our best to help out: https://stablebit.com/Contact Thank you for your continued support, we do appreciate it.
-
- 1
-
-
This was a little tricky because this glitch actually had to do with the CSS prefers-reduced-motion feature and not the resolution. In order to improve the responsiveness of the web site, the StableBit Cloud will turn off most animations on the site if the browser makes a request to do so. That particular offset issue only showed up when prefers-reduced-motion was requested. It should now be fixed as of 7788.4522. E.g. RDP can trigger prefers-reduced-motion when launching a browser from within a connected session.
-
 TPham reacted to a post in a topic:
Cloud Providers
TPham reacted to a post in a topic:
Cloud Providers
-
 johnnymc reacted to an answer to a question:
My Rackmount Server
johnnymc reacted to an answer to a question:
My Rackmount Server
-
Shane reacted to a question:
check-pool-fileparts
-
Thanks for signing up and testing! Just to clarify how centralized licensing works: If you don't enter any Activation IDs into the StableBit Cloud then the existing licensing system will continue to work exactly as it did before. You are not required to enter your Activation IDs into the StableBit Cloud in order to use it. So you can absolutely keep using your existing activated apps as they were and simply link them to the cloud. Now there was a bug on the Dashboard (which I've just corrected) that incorrectly told you that you didn't have a valid license when using legacy licensing. But normally, that warning should not be there. Refresh the page and it should go away (hopefully). However, as soon as you enter at least 1 Activation ID into the StableBit Cloud then the old licensing system turns off and the new cloud licensing system goes into effect. I cannot reproduce the HTTP 400 error that you're seeing when adding a license. Please open a support case with the Activation ID that you're using and we'll look into it: https://stablebit.com/Contact Thank you,
-
KingfisherUK reacted to a post in a topic:
Introducing the StableBit Cloud
-
The StableBit Cloud is a brand new online service developed by Covecube Inc. that enhances our existing StableBit products with cloud-enabled features and centralized management capabilities. The StableBit Cloud also serves as a foundational technology platform for the future development of new Covecube products and services. To get started, visit: https://stablebit.cloud Read more about it in our blog post: https://blog.covecube.com/2021/01/stablebit-cloud/
-
- 1
-
-
Sorry about that, it's fixed now. Google changed some code on their end for the recaptcha that we're using, and that started conflicting with one of the javascript libraries that stablebit.com uses (mootools).
-
Hello good night from Granada, Spain. I need to know if a version of your Stablebit.cloudDrive product is possible for use on the Android operating system (Nvidia SHIELD TV). I am willing to pay the price that you indicate for a version of your application for use on NVIDIA SHIELD TV (Android TV box). Thank you very much and receive a cordial and affectionate greeting.
I would like to be able to use your program "Stablebit.CloudDriver" on my Nvidia Shield TV ( Android TV Box ) to be able to mount or map or virtualize my Gdrive unit on my Nvidia Shield TV player and use PLEX with that Gdrive unit BUT I need to be able to install "Stablebit.CloudDriver" on my Nvidia Shield TV ( Android )
Is an Android version possible? Please
I can't find any Android application capable of "emulating or mounting or mapping or virtualizing" my Gdrive on my Android system and I need it to be able to use PLEX with that drive, because PLEX is not capable of reading from Gdrive since the Plex-Cloud service was disabled.Thank you very much for your attention and time
-
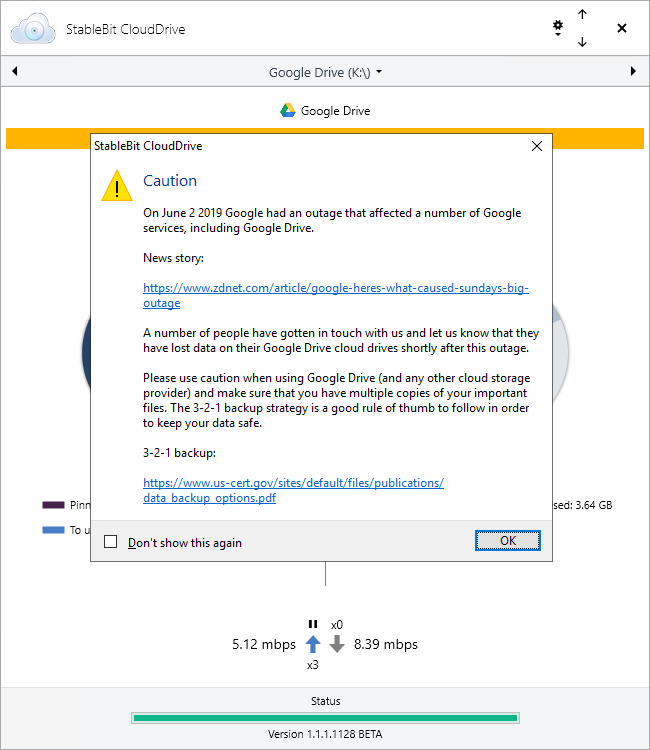
As a response to multiple reports of cloud drive corruption from the Google Drive outage of June 2 2019, we are posting this warning starting with StableBit CloudDrive 1.1.1.1128 BETA on all Google Drive cloud drives. News story: https://www.zdnet.com/article/google-heres-what-caused-sundays-big-outage/ Please use caution and always backup your data by keeping multiple copies of your important files.
-
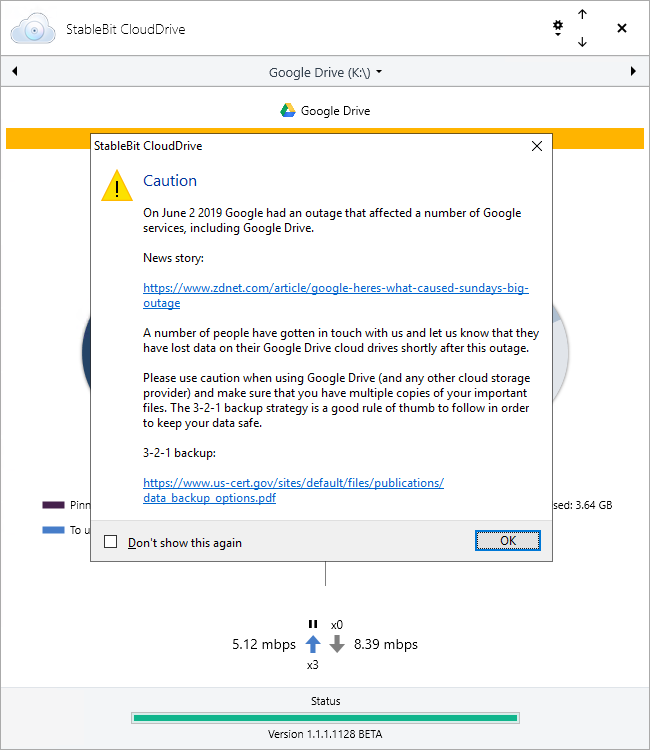
I just want to clarify this. We cannot guarantee that cloud drive data loss will never happen again in the future. We ensure that StableBit CloudDrive is as reliable as possible by running it through a number of very thorough tests before every release, but ultimately a number of issues are beyond our control. First and foremost, the data itself is stored somewhere else, and there is always the change that it could get mangled. Hardware issues with your local cache drive, for example, could cause corruption as well. That's why it is always a good idea to keep multiple copies of your important files, using StableBit DrivePool or some other means. With the latest release (1.1.1.1128, now in BETA) we're adding a "Caution" message to all Google Drive cloud drives that should remind everyone to use caution when storing data on Google Drive. The latest release also includes cloud data duplication (more info: http://blog.covecube.com/2019/06/stablebit-clouddrive-1-1-1-1128-beta/) which you can enable for extra protection against future data loss or corruption.
-
JesterEE reacted to an answer to a question:
Surface scan and SSD
-
Spider99 reacted to a post in a topic:
M.2 Drives - No Smart data - NVME and Sata
-
Jaga reacted to a post in a topic:
M.2 Drives - No Smart data - NVME and Sata
-
As per your issue, I've obtained a similar WD M.2 drive and did some testing with it. Starting with build 3193 StableBit Scanner should be able to get SMART data from your M.2 WD SATA drive. I've also added SMART interpretation rules to BitFlock for these drives as well. You can get the latest development BETAs here: http://dl.covecube.com/ScannerWindows/beta/download/ As for Windows Server 2012 R2 and NVMe, currently, NVMe support in the StableBit Scanner requires Windows 10 or Windows Server 2016.
-
Penryn reacted to a post in a topic:
Ridiculous questions on CloudDrive
-
1c. If a cloud drive fails the checksum / HMAC verification, the error is returned to the OS in the kernel (and eventually the app caller). It's treated exactly the same as a physical drive failing a checksum error. StableBit DrivePool won't automatically pull the data from a duplicate, but you have a few options here. First, you will see error notifications in the StableBit CloudDrive UI, and at this point you can either: Ignore the the verification failure and pull in the corrupted data to continue using your drive. In StableBit CloudDrive, see Options -> Troubleshooting -> Chunks -> Ignore chunk verification. This may be a good idea if you don't care about that particular file. You can simply delete it and continue normally. Remove the affected drive from the pool and StableBit DrivePool will automatically reduplicated the data onto another known good drive. And thank you for your support, we really appreciate it. As far as Issue #27859, I've got a potential fix that looks good. It's currently being qualified for the Microsoft Server 2016 certification, Normally this takes about 12 hours, so a download should be ready by Monday (could even be as soon as tomorrow if all goes well).
-
1. By default, no. But you can easily enable checksumming by checking Verify chunk integrity in the Create a New Cloud Drive window (under Advanced Settings). 1a. For unencrypted drives, chunk verification works by applying a checksum at the end of every 1 MB block of data inside every chunk. When that data is downloaded, the checksum is verified to make sure that the data was not corrupted. If the drive is encrypted, an HMAC is used in order to ensure that the data has not been modified maliciously (the exact algorithm is described in the manual here https://stablebit.com/Support/CloudDrive/Manual?Section=Encryption#Chunk Integrity Verification). 1b. No, ECC correction is not supported / applied by StableBit CloudDrive. 2. It's perfectly fine. The chunk data can be safely stored on a StableBit DrivePool pool. 3. Yep, you should absolutely be able to do that, however, it looks like you've found a bug here with your particular setup. But no worries, I'm already working on a fix. One issue has to do with how cloud drives are unmounted when you reboot or shutdown your computer. Right now, there is no notion of drive unmount priority. But because of the way you set up your cloud drives (cloud drive -> pool -> cloud drive), we need to make sure that the root cloud drive gets unmounted first before unmounting the cloud drive that is part of the pool. So essentially, each cloud drive needs to have an unmount priority, and that priority needs to be based on how those drives are organized in the overall storage hierarchy. Like I said, I'm already working on a fix and that should be ready within a day or so. It'll take a few days after that to run the driver through the Microsoft approval process. A fix should be ready sometime next week. Bug report: https://stablebit.com/Admin/IssueAnalysis/27859 Watch the bug report for progress updates and you can always download the latest development builds here: http://wiki.covecube.com/Downloads http://dl.covecube.com/CloudDriveWindows/beta/download/ As far as being ridiculous, I don't think so I think what you want to do should be possible. In one setup, I use a cloud drive to power a Hyper-V VM server, storing the cache on a 500GB SSD and backing that with a 30+ TB hybrid (cloud / local) pool of spinning drives using the Local Disk provider.
-
Alex changed their profile photo
-
Alex reacted to a question:
Yay - B2 provider added :)
-
Just to reply to some of these concerns (without any of the drama of the original post): Scattered files By default, StableBit DrivePool places new files on the volume with the most free disk space (queried at the time of file creation). It's as simple as that. Grouping files "together" has been requested a bunch, but I personally, don't see a need for it. There will always be a need to split across folders even with a best-effort "grouping" algorithm. The only foolproof way to protect yourself from file loss is file duplication. But I will be looking into the possibility of implementing this in the future. Why is there no database that keeps track of your files? It would degrade performance, introduce complexity, and be another point of failure. The file system is already a database that keeps track of your files, and a very good one. What you're asking for is a backup database of your files (i.e. an indexing engine). StableBit DrivePool is a simple high performance disk pooling application, and it was specifically designed to not require a database. As for empty folders in pool parts, yes StableBit DrivePool doesn't delete empty folders if they don't affect the functionality of the pool. The downside of this is some extra file system metadata on your pool parts. The upside is that, when placing a new file on that pool part, the folder structure doesn't have to be recreated if it's already there. The cons don't justify the extra work in my opinion, and that's why it's implemented like that. Per-file balancing is excluded by design. The #1 requirement of the balancing engine is scalability, which implies no periodic balancing. I could be wrong, but just an observation, it appears that you may want to use StableBit DrivePool exclusively as a means of organizing the data in your pool parts (and not as a pooling engine). That's perhaps why empty folders, no exact per-file balancing rules, and databases of missing files bother you. The pool parts are designed to be "invisible" in normal use, and all file access is supposed to be happening through the pool. The main scenario for accessing pool parts is to perform manual file recovery, not much more. Duplication x2 duplication protects your files from at most 1 drive failure at a time. x3 can handle 2 drive failures concurrently. You can have 2 groups of drives and duplicate everything among those 2 groups with hierarchical pooling. Simply set up a pool of your "old" drives, and then a pool of your "new" drives. Then add both pools to another pool, and enable x2 pool duplication on the parent pool. That's really how StableBit DrivePool works. If you want something different, that's not what this is. Balancing The architecture of the balancing engine is not to enable "Apple-like" magic (although, sometimes, apple-like magic is pretty cool). The architecture was based on answering the question "How can you design a balancing engine that scales very well, and that doesn't require periodic balancing?". First you would need to keep track of file sizes on the pool parts, so that requires either an indexing engine (which was the first idea), but better yet, if you had full control of the file system, you could measure file sizes in real-time very quickly. You then need to take that concept and combine it with some kind of balancing rules. The result is what you see in StableBit DrivePool. The rest of the points here are either already there or don't make any sense. One area that I do agree with you on is improving the transparency of what each balancer is doing. We do already have the balancing markers on the horizontal UI's Disks list, but it would be nice to see what each balancer is trying to do and how they're interacting. Settings Setting filters by size is not possible. Filters are implemented as real-time (kernel-based) new file placement rules. At the time of file creation, the file size is not known. Implementing a periodic balancing pass is not ideal due to performance (as we've seen in Drive Extender IMO). UI UI is subjective. The UI is intended to be minimalistic. Performance is meant to give you a quick snapshot into what your pool is doing, not to be a comprehensive UI like the Resource Monitor. There are 2 types of settings / actions. Global application settings and per-pool settings / actions. That's why you see 2 menus. Per-pool settings are different for each pool. "Check-all", "Uncheck-all". Yeah, good idea. It should probably be there. Will add it. As for wrap panels for lists of drives in file placement, I think that would be harder to scan through in this case. In some places in the UI, selecting a folder will start a size calculation of that folder in the background. The size calculation will never interrupt another ongoing task, it's automatically abortable, and it's asynchronous. It doesn't block or affect the usage of the UI. Specifically in file placement, the chart at the bottom left is meant to give you a quick snapshot of how the files in the selected folder are organized. It's sorted by size to give you a quick at-a-glance view of the top 5 drives that contain those files, or how duplicated vs. non-duplicated space is used. So yes, there's definitely a reason for why it's like that. The size of the buttons in the Balancing window reflects traditional WinForms (or Win32) design. It's a bit different than the rest of the program, and that's intentional. The balancing window was meant to be a little more advanced, and I feel Win32 is a little better at expressing more complex UIs, while WPF is good at minimalistic design. I would not want to build an application that only has a web UI. A desktop application has to first and foremost have a desktop user interface. As for an API, I feel that if we have a comprehensive API then we could certainly make a StableBit DrivePool SDK available for integration into 3rd party solutions. Right now, that's not on the roadmap, but it's certainly an interesting idea. I think that the performance of the UIs for StableBit DrivePool and CloudDrive are very good right now. You keep referring to Telerik, but that's simply not true. Both of those products don't use Telerik. By far, it's using mostly standard Microsoft WPF controls, along with some custom controls that were written from scratch.Very sparingly it does use some other 3rd party controls where it makes sense. All StableBit UIs are entirely asynchronous and multithreaded. That was one of the core design principles. The StableBit Scanner UI is a bit sluggish, yes I do agree, especially when displaying many drives. I do plan on addressing that for the next release. Updates Yes, it has been a while since the last stable release of StableBit DrivePool (and Scanner). But as you can see, there has been a steady stream of updates since that time: http://dl.covecube.com/DrivePoolWindows/beta/download/ We are working with an issue oriented approach, in order to ensure a more stable final release: Customer reports potential issue to stablebit.com/Contact (or publicly here on the forum). Technical support works with customer and software development to determine if the issue is a bug. Bugs are entered into the system with a priority. Once all bugs are resolved for a given product, a public BETA is pushed out to everyone. Meanwhile, as bugs are resolved, internal builds are made available to the community who wants to test them and report more issues (see dev wiki http://wiki.covecube.com/Product_Information). Simple really. And as you can see, there has been a relatively steady stream of builds for StableBit DrivePool. When StableBit CloudDrive was released, there were 0 open bugs for it. Not to say that it was perfect, but just to give everyone an idea of how this works. Up until recently, StableBit DrivePool had a number of open bugs, they are now all resolved (as of yesterday actually). There are still some open issues (not bugs) through, when those are complete, we'll have our next public BETA. I don't want to add anymore features to StableBit DrivePool at this point, but just concentrate on getting a stable release out. I'm not going to comment on whether I think your post is offensive and egotistic. But I did skip most of the "Why the hell do you...", "Why the fuck would you...", "I have no clue what the hell is going on" parts.
-
There was a certificate issue on bitflock.com (cert expired, whoops). Fixing it now, should be back in a few minutes. Sorry about that. Additionally, there were some load / scalability issues and that's now resolved as well. BitFlock is running on Microsoft Azure, so everything scales quite nicely.
-
We've been having a few more database issues within the past 24 hours due to a database migration that took place recently. There was a problem with login authentication and general database load issues which I believe are now all ironed out. Once again, this was isolated to the forum / wiki / blog.