Leaderboard

Popular Content
Showing content with the highest reputation since 06/30/24 in Posts
-

Japanese Translation does not work
DavidBrocho and 2 others reacted to Christopher (Drashna) for a question
Yup, something broke on our end. This should be fixed now, and updating should get the fixed version.3 points -
 To start, while new to DrivePool I love its potential I own multiple licenses and their full suite. If you only use drivepool for basic file archiving of large files with simple applications accessing them for periodic reads it is probably uncommon you would hit these bugs. This assumes you don't use any file synchronization / backup solutions. Further, I don't know how many thousands (tens or hundreds?) of DrivePool users there are, but clearly many are not hitting these bugs or recognizing they are hitting these bugs, so this IT NOT some new destructive my files are 100% going to die issue. Some of the reports I have seen on the forums though may be actually issues due to these things without it being recognized as such. As far as I know previously CoveCube was not aware of these issues, so tickets may not have even considered this possibility. I started reporting these bugs to StableBit ~9 months ago, and informed I would be putting this post together ~1 month ago. Please see the disclaimer below as well, as some of this is based on observations over known facts. You are most likely to run into these bugs with applications that: *) Synchronize or backup files, including cloud mounted drives like onedrive or dropbox *) Applications that must handle large quantities of files or monitor them for changes like coding applications (Visual Studio/ VSCode) Still, these bugs can cause silent file corruption, file misplacement, deleted files, performance degradation, data leakage ( a file shared with someone externally could have its contents overwritten by any sensitive file on your computer), missed file changes, and potential other issues for a small portion of users (I have had nearly all these things occur). It may also trigger some BSOD crashes, I had one such crash that is likely related. Due to the subtle nature some of these bugs can present with, it may be hard to notice they are happening even if they are. In addition, these issues can occur even without file mirroring and files pinned to a specific drive. I do have some potential workarounds/suggestions at the bottom. More details are at the bottom but the important bug facts upfront: Windows has a native file changed notification API using overlapped IO calls. This allows an application to listen for changes on a folder, or a folder and sub folders, without having to constantly check every file to see if it changed. Stablebit triggers "file changed" notifications even when files are just accessed (read) in certain ways. Stablebit does NOT generate notification events on the parent folder when a file under it changes (Windows does). Stablebit does NOT generate a notification event only when a FileID changes (next bug talks about FileIDs). Windows, like linux, has a unique ID number for each file written on the hard drive. If there are hardlinks to the same file, it has the same unique ID (so one File ID may have multiple paths associated with it). In linux this is called the inode number, Windows calls it the FileID. Rather than accessing a file by its path, you can open a file by its FileID. In addition it is impossible for two files to share the same FileID, it is a 128 bit number persistent across reboots (128 bits means the number of unique numbers represented is 39 digits long, or has the uniqueness of something like the MD5 hash). A FileID does not change when a file moves or is modified. Stablebit, by default, supports FileIDs however they seem to be ephemeral, they do not seem to survive across reboots or file moves. Keep in mind FileIDs are used for directories as well, it is not just files. Further, if a directory is moved/renamed not only does its FileID change but every file under it changes. I am not sure if there are other situations in which they may change. In addition, if a descendant file/directory FileID changes due to something like a directory rename Stablebit does NOT generate a notification event that it has changed (the application gets the directory event notification but nothing on the children). There are some other things to consider as well, DrivePool does not implement the standard windows USN Journal (a system of tracking file changes on a drive). It specifically identifies itself as not supporting this so applications shouldn't be trying to use it with a drivepool drive. That does mean that applications that traditionally don't use the file change notification API or the FileIDs may fall back to a combination of those to accomplish what they would otherwise use the USN Journal for (and this can exacerbate the problem). The same is true of Volume Shadow Copy (VSS) where applications that might traditionally use this cannot (and drivepool identifies it cannot do VSS) so may resort to methods below that they do not traditionally use. Now the effects of the above bugs may not be completely apparent: For the overlapped IO / File change notification This means an application monitoring for changes on a DrivePool folder or sub-folder will get erroneous notifications files changed when anything even accesses them. Just opening something like file explorer on a folder, or even switching between applications can cause file accesses that trigger the notification. If an application takes actions on a notification and then checks the file at the end of the notification this in itself may cause another notification. Applications that rely on getting a folder changed notification when a child changes will not get these at all with DrivePool. If it isn't monitoring children at all just the folder, this means no notifications could be generated (vs just the child) so it could miss changes. For FileIDs It depends what the application uses the FileID for but it may assume the FileID should stay the same when a file moves, as it doesn't with DrivePool this might mean it reads or backs up, or syncs the entire file again if it is moved (perf issue). An application that uses the Windows API to open a File by its ID may not get the file it is expecting or the file that was simply moved will throw an error when opened by its old FileID as drivepool has changed the ID. For an example lets say an application caches that the FileID for ImportantDoc1.docx is 12345 but then 12345 refers to ImportantDoc2.docx due to a restart. If this application is a file sync application and ImportantDoc1.docx is changed remotely when it goes to write those remote changes to the local file if it uses the OpenFileById method to do so it will actually override ImportantDoc2.docx with those changes. I didn't spend the time to read Windows file system requirements to know when Windows expects a FileID to potentially change (or not change). It is important to note that even if theoretical changes/reuse are allowed if they are not common place (because windows uses essentially a number like an md5 hash in terms of repeats) applications may just assume it doesn't happen even if it is technically allowed to do so. A backup of file sync program might assume that a file with specific FileID is always the same file, if FileID 12345 is c:\MyDocuments\ImportantDoc1.docx one day and then c:\MyDocuments\ImportantDoc2.docx another it may mistake document 2 for document 1, overriding important data or restore data to the wrong place. If it is trying to create a whole drive backup it may assume it has already backed up c:\MyDocuments\ImportantDoc2.docx if it now has the same File ID as ImportantDoc1.docx by the time it reaches it (at which point DrivePool would have a different FileID for Document1). Why might applications use FileIDs or file change notifiers? It may not seem intuitive why applications would use these but a few major reasons are: *) Performance, file change notifiers are a event/push based system so the application is told when something changes, the common alternative is a poll based system where an application must scan all the files looking for changes (and may try to rely on file timestamps or even hashing the entire file to determine this) this causes a good bit more overhead / slowdown. *) FileID's are nice because they already handle hardlink file de-duplication (Windows may have multiple copies of a file on a drive for various reasons, but if you backup based on FileID you backup that file once rather than multiple times. FileIDs are also great for handling renames. Lets say you are an application that syncs files and the user backs up c:\temp\mydir with 1000 files under it. If they rename c:\temp\mydir to c:\temp\mydir2 an application use FileIDS can say, wait that folder is the same it was just renamed. OK rename that folder in our remote version too. This is a very minimal operation on both ends. With DrivePool however the FileID changes for the directory and all sub-files. If the sync application uses this to determine changes it now uploads all these files to the system using a good bit more resources locally and remotely. If the application also uses versioning this may be far more likely to cause a conflict with two or more clients syncing, as mass amounts of files are seemingly being changed. Finally, even if an application is trying to monitor for FileIDs changing using the file change API, due to notification bugs above it may not get any notifications when child FileIDs change so it might assume it has not. Real Examples OneDrive This started with massive onedrive failures. I would find onedrive was re-uploading hundreds of gigabytes of images an videos multiple times a week. These were not changing or moving. I don't know if the issue is onedrive uses FileIDs to determine if a file is already uploaded, or if it is because when it scanned a directory it may have triggered a notification that all the files in that directory changed and based on that notification it reuploads. After this I noticed files were becoming deleted both locally and in the cloud. I don't know what caused this, it might have been because the old file it thought was deleted as the FileID was gone and while there was a new file (actually the same file) in its place there may have been some odd race condition. It is also possible that it queued the file for upload, the FileID changed and when it went to open it to upload it found it was 'deleted' as the FileID no longer pointed to a file and queued the delete operation. I also found that files that were uploaded into the cloud in one folder were sometimes downloading to an alternate folder locally. I am guessing this is because the folder FileID changed. It thought the 2023 folder was with ID XYZ but that now pointed to a different folder and so it put the file in the wrong place. The final form of corruption was finding the data from one photo or video actually in a file with a completely different name. This is almost guaranteed to be due to the FileID bugs. This is highly destructive as backups make this far harder to correct. With one files contents replaced with another you need to know when the good content existed and in what files were effected. Depending on retention policies the file contents that replaced it may override the good backups before you notice. I also had a BSOD with onedrive where it was trying to set attributes on a file and the CoveFS driver corrupted some memory. It is possible this was a race condition as onedrive may have been doing hundreds of files very rapidly due to the bugs. I have not captured a second BSOD due to it, but also stopped using onedrive on DrivePool due to the corruption. Another example of this is data leakage. Lets say you share your favorite article on kittens with a group of people. Onedrive, believing that file has changed, goes to open it using the FileID however that file ID could essentially now correspond to any file on your computer now the contents of some sensitive file are put in the place of that kitten file, and everyone you shared it with can access it. Visual Studio Failures Visual studio is a code editor/compiler. There are three distinct bugs that happen. First, when compiling if you touched one file in a folder it seemed to recompile the entire folder, this due likely to the notification bug. This is just a slow down, but an annoying one. Second, Visual Studio has compiler generated code support. This means the compiler will generate actual source code that lives next to your own source code. Normally once compiled it doesn't regenerate and compile this source unless it must change but due to the notification bugs it regenerates this code constantly and if there is an error in other code it causes an error there causing several other invalid errors. When debugging visual studio by default will only use symbols (debug location data) as the notifications from DrivePool happen on certain file accesses visual studio constantly thinks the source has changed since it was compiled and you will only be able to breakpoint inside source if you disable the exact symbol match default. If you have multiple projects in a solution with one dependent on another it will often rebuild other project deps even when they haven't changed, for large solutions that can be crippling (perf issue). Finally I often had intellisense errors showing up even though no errors during compiling, and worse intellisense would completely break at points. All due to DrivePool. Technical details / full background & disclaimer I have sample code and logs to document these issues in greater detail if anyone wants to replicate it themselves. It is important for me to state drivepool is closed source and I don't have the technical details of how it works. I also don't have the technical details on how applications like onedrive or visual studio work. So some of these things may be guesses as to why the applications fail/etc. The facts stated are true (to the best of my knowledge) Shortly before my trial expired in October of last year I discovered some odd behavior. I had a technical ticket filed within a week and within a month had traced down at least one of the bugs. The issue can be seen https://stablebit.com/Admin/IssueAnalysis/28720 , it does show priority 2/important which I would assume is the second highest (probably critical or similar above). It is great it has priority but as we are over 6 months since filed without updates I figured warning others about the potential corruption was important. The FileSystemWatcher API is implemented in windows using async overlapped IO the exact code can be seen: https://github.com/dotnet/runtime/blob/57bfe474518ab5b7cfe6bf7424a79ce3af9d6657/src/libraries/System.IO.FileSystem.Watcher/src/System/IO/FileSystemWatcher.Win32.cs#L32-L66 That corresponds to this kernel api: https://learn.microsoft.com/en-us/windows/win32/fileio/synchronous-and-asynchronous-i-o Newer api calls use GetFileInformationByHandleEx to get the FileID but with older stats calls represented by nFileIndexHigh/nFileIndexLow. In terms of the FileID bug I wouldn't normally have even thought about it but the advanced config (https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings) mentions this under CoveFs_OpenByFileId "When enabled, the pool will keep track of every file ID that it gives out in pageable memory (memory that is saved to disk and loaded as necessary).". Keeping track of files in memory is certainly very different from Windows so I thought this may be the source of issue. I also don't know if there are caps on the maximum number of files it will track as if it resets FileIDs in situations other than reboots that could be much worse. Turning this off will atleast break nfs servers as it mentions it right in the docs "required by the NFS server". Finally, the FileID numbers given out by DrivePool are incremental and very low. This means when they do reset you almost certainly will get collisions with former numbers. What is not clear is if there is the chance of potential FileID corruption issues. If when it is assigning these ids in a multi-threaded scenario with many different files at the same time could this system fail? I have seen no proof this happens, but when incremental ids are assigned like this for mass quantities of potential files it has a higher chance of occurring. Microsoft mentions this about deleting the USN Journal: "Deleting the change journal impacts the File Replication Service (FRS) and the Indexing Service, because it requires these services to perform a complete (and time-consuming) scan of the volume. This in turn negatively impacts FRS SYSVOL replication and replication between DFS link alternates while the volume is being rescanned.". Now DrivePool never has the USN journal supported so it isn't exactly the same thing, but it is clear that several core Windows services do use it for normal operations I do not know what backups they use when it is unavailable. Potential Fixes There are advanced settings for drivepool https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings beware these changes may break other things. CoveFs_OpenByFileId - Set to false, by default it is true. This will disable the OpenByFileID API. It is clear several applications use this API. In addition, while DrivePool may disable that function with this setting it doesn't disable FileID's themselves. Any application using FileIDs as static identifiers for files may still run into problems. I would avoid any file backup/synchronization tools and DrivePool drives (if possible). These likely have the highest chance of lost files, misplaced files, file content being mixed up, and excess resource usage. If not avoiding consider taking file hashes for the entire drivepool directory tree. Do this again at a later point and make sure files that shouldn't have changed still have the same hash. If you have files that rarely change after being created then hashing each file at some point after creation and alerting if that file disappears or hash changes would easily act as an early warning to a bug here being hit.2 points
To start, while new to DrivePool I love its potential I own multiple licenses and their full suite. If you only use drivepool for basic file archiving of large files with simple applications accessing them for periodic reads it is probably uncommon you would hit these bugs. This assumes you don't use any file synchronization / backup solutions. Further, I don't know how many thousands (tens or hundreds?) of DrivePool users there are, but clearly many are not hitting these bugs or recognizing they are hitting these bugs, so this IT NOT some new destructive my files are 100% going to die issue. Some of the reports I have seen on the forums though may be actually issues due to these things without it being recognized as such. As far as I know previously CoveCube was not aware of these issues, so tickets may not have even considered this possibility. I started reporting these bugs to StableBit ~9 months ago, and informed I would be putting this post together ~1 month ago. Please see the disclaimer below as well, as some of this is based on observations over known facts. You are most likely to run into these bugs with applications that: *) Synchronize or backup files, including cloud mounted drives like onedrive or dropbox *) Applications that must handle large quantities of files or monitor them for changes like coding applications (Visual Studio/ VSCode) Still, these bugs can cause silent file corruption, file misplacement, deleted files, performance degradation, data leakage ( a file shared with someone externally could have its contents overwritten by any sensitive file on your computer), missed file changes, and potential other issues for a small portion of users (I have had nearly all these things occur). It may also trigger some BSOD crashes, I had one such crash that is likely related. Due to the subtle nature some of these bugs can present with, it may be hard to notice they are happening even if they are. In addition, these issues can occur even without file mirroring and files pinned to a specific drive. I do have some potential workarounds/suggestions at the bottom. More details are at the bottom but the important bug facts upfront: Windows has a native file changed notification API using overlapped IO calls. This allows an application to listen for changes on a folder, or a folder and sub folders, without having to constantly check every file to see if it changed. Stablebit triggers "file changed" notifications even when files are just accessed (read) in certain ways. Stablebit does NOT generate notification events on the parent folder when a file under it changes (Windows does). Stablebit does NOT generate a notification event only when a FileID changes (next bug talks about FileIDs). Windows, like linux, has a unique ID number for each file written on the hard drive. If there are hardlinks to the same file, it has the same unique ID (so one File ID may have multiple paths associated with it). In linux this is called the inode number, Windows calls it the FileID. Rather than accessing a file by its path, you can open a file by its FileID. In addition it is impossible for two files to share the same FileID, it is a 128 bit number persistent across reboots (128 bits means the number of unique numbers represented is 39 digits long, or has the uniqueness of something like the MD5 hash). A FileID does not change when a file moves or is modified. Stablebit, by default, supports FileIDs however they seem to be ephemeral, they do not seem to survive across reboots or file moves. Keep in mind FileIDs are used for directories as well, it is not just files. Further, if a directory is moved/renamed not only does its FileID change but every file under it changes. I am not sure if there are other situations in which they may change. In addition, if a descendant file/directory FileID changes due to something like a directory rename Stablebit does NOT generate a notification event that it has changed (the application gets the directory event notification but nothing on the children). There are some other things to consider as well, DrivePool does not implement the standard windows USN Journal (a system of tracking file changes on a drive). It specifically identifies itself as not supporting this so applications shouldn't be trying to use it with a drivepool drive. That does mean that applications that traditionally don't use the file change notification API or the FileIDs may fall back to a combination of those to accomplish what they would otherwise use the USN Journal for (and this can exacerbate the problem). The same is true of Volume Shadow Copy (VSS) where applications that might traditionally use this cannot (and drivepool identifies it cannot do VSS) so may resort to methods below that they do not traditionally use. Now the effects of the above bugs may not be completely apparent: For the overlapped IO / File change notification This means an application monitoring for changes on a DrivePool folder or sub-folder will get erroneous notifications files changed when anything even accesses them. Just opening something like file explorer on a folder, or even switching between applications can cause file accesses that trigger the notification. If an application takes actions on a notification and then checks the file at the end of the notification this in itself may cause another notification. Applications that rely on getting a folder changed notification when a child changes will not get these at all with DrivePool. If it isn't monitoring children at all just the folder, this means no notifications could be generated (vs just the child) so it could miss changes. For FileIDs It depends what the application uses the FileID for but it may assume the FileID should stay the same when a file moves, as it doesn't with DrivePool this might mean it reads or backs up, or syncs the entire file again if it is moved (perf issue). An application that uses the Windows API to open a File by its ID may not get the file it is expecting or the file that was simply moved will throw an error when opened by its old FileID as drivepool has changed the ID. For an example lets say an application caches that the FileID for ImportantDoc1.docx is 12345 but then 12345 refers to ImportantDoc2.docx due to a restart. If this application is a file sync application and ImportantDoc1.docx is changed remotely when it goes to write those remote changes to the local file if it uses the OpenFileById method to do so it will actually override ImportantDoc2.docx with those changes. I didn't spend the time to read Windows file system requirements to know when Windows expects a FileID to potentially change (or not change). It is important to note that even if theoretical changes/reuse are allowed if they are not common place (because windows uses essentially a number like an md5 hash in terms of repeats) applications may just assume it doesn't happen even if it is technically allowed to do so. A backup of file sync program might assume that a file with specific FileID is always the same file, if FileID 12345 is c:\MyDocuments\ImportantDoc1.docx one day and then c:\MyDocuments\ImportantDoc2.docx another it may mistake document 2 for document 1, overriding important data or restore data to the wrong place. If it is trying to create a whole drive backup it may assume it has already backed up c:\MyDocuments\ImportantDoc2.docx if it now has the same File ID as ImportantDoc1.docx by the time it reaches it (at which point DrivePool would have a different FileID for Document1). Why might applications use FileIDs or file change notifiers? It may not seem intuitive why applications would use these but a few major reasons are: *) Performance, file change notifiers are a event/push based system so the application is told when something changes, the common alternative is a poll based system where an application must scan all the files looking for changes (and may try to rely on file timestamps or even hashing the entire file to determine this) this causes a good bit more overhead / slowdown. *) FileID's are nice because they already handle hardlink file de-duplication (Windows may have multiple copies of a file on a drive for various reasons, but if you backup based on FileID you backup that file once rather than multiple times. FileIDs are also great for handling renames. Lets say you are an application that syncs files and the user backs up c:\temp\mydir with 1000 files under it. If they rename c:\temp\mydir to c:\temp\mydir2 an application use FileIDS can say, wait that folder is the same it was just renamed. OK rename that folder in our remote version too. This is a very minimal operation on both ends. With DrivePool however the FileID changes for the directory and all sub-files. If the sync application uses this to determine changes it now uploads all these files to the system using a good bit more resources locally and remotely. If the application also uses versioning this may be far more likely to cause a conflict with two or more clients syncing, as mass amounts of files are seemingly being changed. Finally, even if an application is trying to monitor for FileIDs changing using the file change API, due to notification bugs above it may not get any notifications when child FileIDs change so it might assume it has not. Real Examples OneDrive This started with massive onedrive failures. I would find onedrive was re-uploading hundreds of gigabytes of images an videos multiple times a week. These were not changing or moving. I don't know if the issue is onedrive uses FileIDs to determine if a file is already uploaded, or if it is because when it scanned a directory it may have triggered a notification that all the files in that directory changed and based on that notification it reuploads. After this I noticed files were becoming deleted both locally and in the cloud. I don't know what caused this, it might have been because the old file it thought was deleted as the FileID was gone and while there was a new file (actually the same file) in its place there may have been some odd race condition. It is also possible that it queued the file for upload, the FileID changed and when it went to open it to upload it found it was 'deleted' as the FileID no longer pointed to a file and queued the delete operation. I also found that files that were uploaded into the cloud in one folder were sometimes downloading to an alternate folder locally. I am guessing this is because the folder FileID changed. It thought the 2023 folder was with ID XYZ but that now pointed to a different folder and so it put the file in the wrong place. The final form of corruption was finding the data from one photo or video actually in a file with a completely different name. This is almost guaranteed to be due to the FileID bugs. This is highly destructive as backups make this far harder to correct. With one files contents replaced with another you need to know when the good content existed and in what files were effected. Depending on retention policies the file contents that replaced it may override the good backups before you notice. I also had a BSOD with onedrive where it was trying to set attributes on a file and the CoveFS driver corrupted some memory. It is possible this was a race condition as onedrive may have been doing hundreds of files very rapidly due to the bugs. I have not captured a second BSOD due to it, but also stopped using onedrive on DrivePool due to the corruption. Another example of this is data leakage. Lets say you share your favorite article on kittens with a group of people. Onedrive, believing that file has changed, goes to open it using the FileID however that file ID could essentially now correspond to any file on your computer now the contents of some sensitive file are put in the place of that kitten file, and everyone you shared it with can access it. Visual Studio Failures Visual studio is a code editor/compiler. There are three distinct bugs that happen. First, when compiling if you touched one file in a folder it seemed to recompile the entire folder, this due likely to the notification bug. This is just a slow down, but an annoying one. Second, Visual Studio has compiler generated code support. This means the compiler will generate actual source code that lives next to your own source code. Normally once compiled it doesn't regenerate and compile this source unless it must change but due to the notification bugs it regenerates this code constantly and if there is an error in other code it causes an error there causing several other invalid errors. When debugging visual studio by default will only use symbols (debug location data) as the notifications from DrivePool happen on certain file accesses visual studio constantly thinks the source has changed since it was compiled and you will only be able to breakpoint inside source if you disable the exact symbol match default. If you have multiple projects in a solution with one dependent on another it will often rebuild other project deps even when they haven't changed, for large solutions that can be crippling (perf issue). Finally I often had intellisense errors showing up even though no errors during compiling, and worse intellisense would completely break at points. All due to DrivePool. Technical details / full background & disclaimer I have sample code and logs to document these issues in greater detail if anyone wants to replicate it themselves. It is important for me to state drivepool is closed source and I don't have the technical details of how it works. I also don't have the technical details on how applications like onedrive or visual studio work. So some of these things may be guesses as to why the applications fail/etc. The facts stated are true (to the best of my knowledge) Shortly before my trial expired in October of last year I discovered some odd behavior. I had a technical ticket filed within a week and within a month had traced down at least one of the bugs. The issue can be seen https://stablebit.com/Admin/IssueAnalysis/28720 , it does show priority 2/important which I would assume is the second highest (probably critical or similar above). It is great it has priority but as we are over 6 months since filed without updates I figured warning others about the potential corruption was important. The FileSystemWatcher API is implemented in windows using async overlapped IO the exact code can be seen: https://github.com/dotnet/runtime/blob/57bfe474518ab5b7cfe6bf7424a79ce3af9d6657/src/libraries/System.IO.FileSystem.Watcher/src/System/IO/FileSystemWatcher.Win32.cs#L32-L66 That corresponds to this kernel api: https://learn.microsoft.com/en-us/windows/win32/fileio/synchronous-and-asynchronous-i-o Newer api calls use GetFileInformationByHandleEx to get the FileID but with older stats calls represented by nFileIndexHigh/nFileIndexLow. In terms of the FileID bug I wouldn't normally have even thought about it but the advanced config (https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings) mentions this under CoveFs_OpenByFileId "When enabled, the pool will keep track of every file ID that it gives out in pageable memory (memory that is saved to disk and loaded as necessary).". Keeping track of files in memory is certainly very different from Windows so I thought this may be the source of issue. I also don't know if there are caps on the maximum number of files it will track as if it resets FileIDs in situations other than reboots that could be much worse. Turning this off will atleast break nfs servers as it mentions it right in the docs "required by the NFS server". Finally, the FileID numbers given out by DrivePool are incremental and very low. This means when they do reset you almost certainly will get collisions with former numbers. What is not clear is if there is the chance of potential FileID corruption issues. If when it is assigning these ids in a multi-threaded scenario with many different files at the same time could this system fail? I have seen no proof this happens, but when incremental ids are assigned like this for mass quantities of potential files it has a higher chance of occurring. Microsoft mentions this about deleting the USN Journal: "Deleting the change journal impacts the File Replication Service (FRS) and the Indexing Service, because it requires these services to perform a complete (and time-consuming) scan of the volume. This in turn negatively impacts FRS SYSVOL replication and replication between DFS link alternates while the volume is being rescanned.". Now DrivePool never has the USN journal supported so it isn't exactly the same thing, but it is clear that several core Windows services do use it for normal operations I do not know what backups they use when it is unavailable. Potential Fixes There are advanced settings for drivepool https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings beware these changes may break other things. CoveFs_OpenByFileId - Set to false, by default it is true. This will disable the OpenByFileID API. It is clear several applications use this API. In addition, while DrivePool may disable that function with this setting it doesn't disable FileID's themselves. Any application using FileIDs as static identifiers for files may still run into problems. I would avoid any file backup/synchronization tools and DrivePool drives (if possible). These likely have the highest chance of lost files, misplaced files, file content being mixed up, and excess resource usage. If not avoiding consider taking file hashes for the entire drivepool directory tree. Do this again at a later point and make sure files that shouldn't have changed still have the same hash. If you have files that rarely change after being created then hashing each file at some point after creation and alerting if that file disappears or hash changes would easily act as an early warning to a bug here being hit.2 points -
Do you duplicate everything?
Shane and one other reacted to Christopher (Drashna) for a question
Ah, okay. So just another term like "spinning rust" And that's ... very neat! You are very welcome! And I'm in that same boat, TBH. Zfs and btrfs look like good pooling solutions, but a lot that goes into them. Unraid is another option, but honestly, one I'm not fond of, mainly because of how the licensing works (I ... may be spoiled by our own licensing, I admit). And yeah, the recovery and such for the software is great. A lot of time and effort has gone into making it so easy, and we're glad you appreciate that! And the file recovery does make things nice, when you're in a pinch! And I definitely understand why people keep asking for a linux and/or mac version of our software. There is a lot to say about something that "just works".2 points -
LAN control. Sometimes remote devices appear in the drop down, sometimes they don't.
dmaker and one other reacted to Christopher (Drashna) for a question
It's flaky because multicast detection can be flaky. That said, you can manually add entries, if you need to: https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings#RemoteControl.xml2 points -
100% Once I disabled it, all my data corruption issues vanished. I haven't turned it back on since. It was a nightmare restoring all my backups and re-doing days of work from scratch.2 points
-

Pool file duplication causing file corruption under certain circumstances
Shane and one other reacted to number_one for a question
Yes, I haven't heard of any update from Covecube about any resolution to this (or even that they're working on it), so you should DEFINITELY disable read striping. I'm quite frankly a bit alarmed at how there seems to be no official acknowledgement of the issue at present. The only post in this thread from an actual employee is from nearly five years ago. I do understand that it likely involves specific edge cases to be affected by the issue, but those edge cases are clearly not rare or hard to demonstrate. In my case all it took was using rsync through a Git Bash environment to have the bug cause massive corruption. And it is easily repeatable (as in if I sync files using rsync from a Drivepool volume there were essentially NO instances where there wasn't at least some corruption when read striping was enabled).2 points -
Windows 2025 Support
lhartje and one other reacted to Christopher (Drashna) for a question
Yes, it is supported.2 points -
With 1600 Installed, go into Settings -> Select Updates... -> Settings -> Disable Automatic Updates Mine now runs without the constant notification that an update is available.2 points
-
The light blue, dark blue, orange and red triangle markers on a Disk's usage bar indicates the amounts of those types of data that DrivePool has calculated should be on that particular Disk to meet certain Balancing limits set by the user, and it will attempt to accomplish that on its next balancing run. If you hover your mouse pointed over a marker you should get a tooltip that provides information about it. https://stablebit.com/Support/DrivePool/2.X/Manual?Section=Disks List (the section titled Balancing Markers)2 points
-
Mostly. As I think you mentioned earlier in this thread that doesn't disable FileIds and applications could still get the FileID of a file. Depending how that ID is used it could still cause issues. An example below is snapraid which doesn't use OpenByFileID but does trust that the same FileID is the same file. For the biggest problems (data loss, corruption, leakage) this is correct. Of course, one generally can't know if an application is using FileIDs (especially if not open source) it is likely not mentioned in the documentation. It also doesn't mean your favorite app may not start to do so tomorrow, and then all the sudden the application that worked perfectly for 4 years starts to silently corrupt random data. By far the most likely apps to do this are backup apps, data sync apps, cloud storage apps, file sharing apps, things that have some reason to potentially try to track what files are created/moved/deleted/etc. The other issue (and sure if I could go back in time I would split this thread in two) of the change notification bugs in DrivePool won't directly lead to data loss (although can greatly speed up the process above) . It will, however, have the potential for odd errors and performance issues in a wide range of applications. The file change API is used by many applications, not just the app types listed above (which often will use it if they run 24/7) but any app that interfaces with many files at once (IE coding IDE's/compilers, file explorers, music or video catalogs, etc). This API is common, easy to use for developers, and generally can greatly increase performance of apps as they no longer need to manually check if every file they can just install one event listener on a parent directory and even if they only care about the notifications for some of the files in the directories under it they can just ignore the change events they don't care about. It may be very hard to trace these performance issues or errors to drive pool due to how they may present themselves. You are far more likely to think the application is buggy or at fault. Short Example of Disaster As it is a complex issue to understand I will give a short example of how FileIDs being reused can be devastating. Lets say you use Google Drive or some other cloud backup / sharing application and it relies on the fact that as long as FileID 123 around it is always pointing to the same file. This is all but guaranteed with NTFS. You only use Google Drive to backup your photos from your phone, from your work camera, or what have you. You have the following layout on your computer: c:\camera\work\2021\OfficialWiringDiagram.png with file ID 1005 c:\camera\personal\nudes\2024Collection\VeryTasteful.png with file ID 3909 c:\work\govt\ClassifiedSatPhotoNotToPostOnTwitter.png with file ID 6050 You have OfficialWiringDiagram.png shared with the office as its an important reason anytime someone tries to figure out where the network cables are going. Enter drive pool. You don't change any of these files but DrivePool generates a file changed notification for OfficialWiringDiagram.png. GoogleDrive says OK I know that file, I already have it backed up and it has file ID 1005. It then opens File ID 1005 locally reads the new contents, and uploads it to the cloud overriding the old OfficialWiringDiagram.png. Only problem is you rebooted, so 1005 was OfficialWiringDiagram.png before, but now file 1005 is actually your nude file VeryTasteful.png. So it has just backed up your nude file into the cloud but as "OfficialWiringDiagram.png", and remember that file is shared to the cloud. Next time someone goes to look at the office wiring diagram they are in for a surprise. Depending on the application if 'ClassifiedSatPhotoNotToPostOnTwitter.png' became FileID 1005 even though it got a change notification for the path "c:\camera\work\2021\OfficialWiringDiagram.png" which is under the main folder it monitors ("c:\camera") when it opens File 1005 it instead now gets a file completely outside your camera folder and reads the highly sensitive file from c:\work\govt and now a file that should never be uploaded is shared to the entire office. Now you follow many best practices. Google drive you restrict to only the c:\camera folder, it doesn't backup or access files anywhere else. You have a Raid 6 SSD setup incase of drive failure, and image files from prior years are never changed, so once written to the drive they are not likely to move unless the drive was de-fragmented meaning pretty low chance of conflicts or some abrupt power failure causing it to be corrupted. You even have some photo scanner that checks for corrupt photos just to be safe. Except none of these things will save you from the above example. Even if you kept 6 months of backup archives offsite in cold storage (made perfectly and not effected by the bug) and all deleted files are kept for 5 years, if you don't reference OfficialWiringDiagram.png but once a year you might not notice it was changed and the original data overwritten until after all your backups are corrupted with the nude and the original file might be lost forever. FileIDs are generally better than relying on file paths, if they used file paths when you renamed or moved file 123 to a new name in the same folder it would break anyone you previously had shared the file with if only file names are used. If instead when you rename "BobsChristmasPhoto.png" to "BobsHolidayPhoto.png" the application knows it is the file being renamed as it still has File ID 123 then it can silently update on the backend the sharing data so when people click the existing link it still loads the photo. Even if an application uses moderate de-duplication techniques like hashing the file to tell if it has just moved, if you move a file and slightly change it (say you clear the photo location metadata out that your phone put there) it would think it is an all new file without File IDs. FileID collisions are not just possible but basically guaranteed with drive pool. With the change notification bug a sync application might think all your files are changing often as even reading the file or browsing the directory might trigger a notification it has changed. This means it is backing up all those files again, which might be tens of thousands of photos. As any time you reboot the File ID changes that means if it syncs that file after the reboot uploading the wrong contents (as it used File ID) and then you had a second computer it downloaded that file to you could put yourself in a never ending loop for backups and downloads that overrides one file with another file at random. As the FileID it was known last time for might not exist when it goes to back it up (which I assume would trigger many applications to fall back to path validation) only part of your catalog would get corrupted each iteration. The application might also validate that if the file is renamed it stayed within the root directory it interacts with. This means if your christmas photo's file ID now pointed to something under "c:\windows" it would fall back to file paths as it knows that is not under the "c:\camera" directory it works with. This is not some hypothetical situation these are actual occurrences and behaviors I have seen happen to files I have hosted on drivepool. These are not two-bit applications written by some one person dev team these are massively used first party applications, and commercial enterprise applications. If you can and you care about your data I would. The convenience of drivepool is great, there are countless users it works fine for (at least as far as they know), but even with high technical understanding it can be quite difficult to detect what applications are effected by this. If you thought you were safe because you use something like snapraid it won't stop this sort of corruption. As far as snapraid is concerned you just deleted a file and renamed another on top of it. Snapraid may even contribute further to the problem as it (like many) uses the windows FileID as the Windows equivalent of an inode number https://github.com/amadvance/snapraid/blob/e6b8c4c8a066b184b4fa7e4fdf631c2dee5f5542/cmdline/mingw.c#L512-L518 . Applications assume inodes and FileIDs that are the same as before are the same file. That is unless you use DrivePool, oops. Apps might use timestamps in addition to FileIDs although timestamps can overlap say if you downloaded a zip archive and extracted it with Windows native (by design choice it ignores timestamps even if the zip contained them). SnapRAID can even use some advanced checks with syncing but in a worst case where a files content has actually changed but the FileID in question has the same size/timestamp SnapRAID assumes it is actually unmodified and leaves the parity data alone. This means if you had two files with the same size/timestamp anywhere on the drive and one of them got the FileID of the other it would end up with incorrect parity data associated with that file. Running a snapraid fix could actually result in corruption as snapraid would believe the parity data is correct but the content on disk it thinks go with it does not. Note: I don't use snapraid but was asked this question and reading the manual here and the source above I believe this is technically correct. It is great SnapRAID is open source and has such technical documentation plenty of backup / sync programs don't and you don't know what checking they do.2 points
-
To be fair to Stablebit I used Drivepool for the past few years and have NEVER lost a single file because of Drivepool. The elaborateness OR simpleness of how you use Drivepool within itself is not really of concern. What is being warned of here though is if you use any special applications that might expect FileID to behave as per NTFS there will be risks with that. My example is that I use Freefilesync quite a bit to maintain files between my pool, my htpc and another backup location. When I move files on one drive, freefilesync using fileid recognises the file was moved so syncs a "move" on the remote filesystem as well. This saves potentially hours of copying and then deleting. It does not work on Drivepool because the fileid changes on each reboot. In this case Freefilesync fails "SAFE" in that it does the copy and delete instead, so I only suffer performance issues. What could happen though is that you use another app that say cleans old files, or moves files around that does not fail safe if a fileid is repeated for a different file etc and in doing so you do suffer file loss. This will only happen if you use some third party application that makes changes to files. It's not the type of thing a word processor or a pc game etc are going to be doing (typically in case someone jumps in with a it could be possible argument). So generally Drivepool is safe, and for you most likely of nothing to worry about, but if you do use an application now or in the future that is for cleaning up or syncing etc then be very careful in case it uses fileid and causes data loss because of this issue. For day to day use, in my experience you can continue to use it as is. If you want to add to the group of us that would like this improved, feel free to add your voice to the request as otherwise I don't see any update for this in the foreseeable future.2 points
-

"Duplication Inconsistant" for files that don't exist!?
Christopher (Drashna) and one other reacted to dslabbekoorn for a question
Hard Disk Sentinel Pro found an additional three HDD's that were "bad" or failing, on top of the 2 i already replaced, all due to bad sectors & running out of space to replace them. Some were over 10 years old & all were over 5 years. Pulled out the bad ones and went shopping. Got my money's worth from them. All new drives are server grade refurbs from the same company I bought one of the old drives from, they're online now, but still stand by their products & honor warranties so I feel pretty secure. And as I read in another post, a sever crash/issue is a great excuse to upgrade your hardware. My pool "accidentally" grew by 12Tb after I got it fixed. 😁 Best news was I turned on Pool Duplication and when I looked at was duplicating at the folder level, I found 2 miscellaneous folders that were not duplicating, changed them manually and YAY! Measuring, Duplication and Balancing all finished OK. Amazing what a hundred bucks or so of new equipment will do. So my original issues were all equipment related after all.2 points -
Japanese Translation does not work
DavidBrocho and one other reacted to Christopher (Drashna) for a question
Thank you for the investigation! That definitely helps a lot! And there looks like there were UI fixes in 1600, so likely something broke there, accidentally. That said, I've created an issue for this: https://stablebit.com/Admin/IssueAnalysis/289562 points -
I know the chance of this is near zero, but the most recent Windows screenshotting AI shenanigans is the last straw for me. The incredible suite of Stablebit tools is the ONLY thing that has kept me using Windows (seriously, it’s the best software ever - I don’t even think that’s an exaggeration). I will pay for the entire suite again, or hell Stablebit can double the price for Linux, I’ll pay it. Is there ANY chance a Linux version of DrivePool/Scanner would be developed?2 points
-
 Hi haoma. The corruption isn't being caused by DrivePool's duplication feature (and while read-striping EDIT: can have some issues with some older or... I'll say "edge-case" utilities, so I usually just leave it off anyway is buggy and should be turned off, that's also not the cause here). The corruption risk comes in if any app relies on a file's ID number to remain unique and stable unless the file is modified or deleted, as that number is being changed by DrivePool even when the file is simply renamed, moved or if the drivepool machine is restarted - and in the latter case being re-used for completely different files. TLDR: far as I know currently the most we can do is to change the Override value for CoveFs_OpenByFileId from null to false (see Advanced Settings). At least as of this post date it doesn't fix the File ID problem, but it does mean affected apps should either safely fall back to alternative methods or at least return some kind of error so you can avoid using them with a pool drive.1 point
Hi haoma. The corruption isn't being caused by DrivePool's duplication feature (and while read-striping EDIT: can have some issues with some older or... I'll say "edge-case" utilities, so I usually just leave it off anyway is buggy and should be turned off, that's also not the cause here). The corruption risk comes in if any app relies on a file's ID number to remain unique and stable unless the file is modified or deleted, as that number is being changed by DrivePool even when the file is simply renamed, moved or if the drivepool machine is restarted - and in the latter case being re-used for completely different files. TLDR: far as I know currently the most we can do is to change the Override value for CoveFs_OpenByFileId from null to false (see Advanced Settings). At least as of this post date it doesn't fix the File ID problem, but it does mean affected apps should either safely fall back to alternative methods or at least return some kind of error so you can avoid using them with a pool drive.1 point -
Hello, I have a 12 disk pool using identical Toshiba N300 8TB drives. This system runs on Server 2022, and for years I've had no issues. This morning, I noticed that my 89.1 TB pool has 62.3 TB of Duplicated files, 1.21 TB of Unduplicated files, and 52.7 GB of "other". I have pool duplication enabled across the entire array, to include two 1 TB SATA SSDs used as scratch discs, for a total of 14 disks in the array. I have Manage Pool>File Protection>Pool File Duplication enabled. I am also using the SSD plugin. Up to now, everything has worked perfectly. After many years of using your software, this is my first issue. Please let me know if there's any other info I can provide to assist in figuring this out. Thank you Edit: I am running v2.3.8.1600 Second Edit: I have solved the problem. I forgot that I had excluded a folder from the duplication process. The software works perfectly as always... the problem was located directly behind the screen.1 point
-
RESULT: Success!! Thank you Drashna. I installed StableBit.DrivePool_2.3.10.1661_x64_Release.exe. Successfully converted to Japanese! Thanks for the quick fix. Index of /DrivePoolWindows/release/download URL https://covecube.download/DrivePoolWindows/release/download/1 point
-
Sorry but even in my mission-not important environment I am not a fan of data loss or leakage. Also, extremely low is an understatement. NTFS supports 2^32 possible files on a drive. The MFT file index is actually a 48 bit entry, that means you could max out your new MFT records 65K times prior to it needing to loop around. The sequence number (how many times that specific MFT record is updated) is an additional 16 bits on its own so if you could delete and realloc a file to the exact same MFT record you still would need to do so with that specific record 65K times. If an application is monitoring for file changes, hopefully it catches one of those:) It is nearly impossible to know how an application may use FileID especially as it may only be used as a fallback due to other features drivepool does not implement and maybe they combine FileID with something else. If an application says hey I know file 1234 and on startup it checks file 1234. If that file exists it can be near positive its the same file if is gone it simply removes file 1234 from its known files and by the time 1234 it reused it hasn't known about it in forever. The problem here is not necessarily when FileIDs change id wager most applications could probably handle file ids changing even though the file has not fine (you might get extra transfer, or backed up extra data, or performance loss temporarily). It is the FileID reuse that is what leads to the worst effects of data loss, data leakage, and corruption. The file id is 64 bits, the max file space is 32 bits (and realistically most people probably have a good bit fewer than 4 billion files). DrivePool could randomly assign file ids willy nilly every boot and probably cause far fewer disasters. DrivePool could use underlying FIleIDs likely through some black magic hackery. The MFT counter is 48 bit, but I doubt those last 9 bits are touched on most normal systems. If DrivePool assigned an incremental number to each drive and then overwrote those 9 bits of the FileID from the underlying system with the drive ID you would support 512 hard drives in one drive 'pool' and still have nearly the same near zero file collision of FileID, while also having a stable file ID. It would only change the FIleID if a file moved in the background from one drive to another(and not just mirrored). It could even keep it the same with a zero byte ID file left behind on a ghost folder if so desired, but the file ID changing is probably far less a problem. A backup restore program that deleted the old file and created it again would also change the FileID and I doubt that causes issues. That said, it is not really my job to figure out how to solve this problem in a commercial product. As you mentioned back in December it is unquestionable that drivepool is doing the wrong thing: it uses MUST in caps. My problem isn't that this bug exists (although that sucks). My problem is this has been and continues to be handled exceptionally poorly by Stablebit even though it can pose significant risk to users without them even knowing it. I likely spent more of my time investigating their bug then they have. We are literally looking at nearly two years now since my initial notification and users can make the same mistakes now as back then despite the fact they could be warned or prevented from doing so.1 point
-
Shane, as always, has done a great job summarizing everything and I certainly agree with most of it. I do want to provide some clarification, and also differ on a few things: *) This is not about DrivePool being required to precisely emulate NTFS and all its features, that is probably a never going to happen. At best DrivePool may be able to provide a driver level drive implementation that could allow it to be formatted in the way Shane describes CloudDrive does. One of the things this critical bug is made worse by is the fact DrivePool specifically doesn't implement VSS or similar *) The two issues here are not the same, or one causing the other. They are distinct, but the incorrect file changed bug makes the FileID problem potentially so much worse (or maybe in unlucky situations it to happen at all). Merely by browsing a folder can cause file change notifications to fire on the files on it in certain situations. This means unmodified files an application listening to the notification would believe have been modified. It is possible if this bug did not exist then only would written files have the potential for corruption rather than all files. These next two points are not facts but IMO: *) DrivePool claims to be NTFS if it cannot support certain NTFS features it should break them as cleanly as possible (not as compatible as possible as it might currently). FileID support should be as disabled as possible by DrivePool. Open by file ID clearly banned. I don't know what would happen if FileID returned 0 or claimed not available on the system even thought it is an NTFS volume. There are things DrivePool could potentially due to minimize the fatal damage this FileID bug can cause (ie not resetting to zero) but honestly even then all FileID support should be as turned off as possible. If a user wants to enable these features DrivePool should provide a massive disclaimer about the possible damage this might cause. *) DrivePool has an ethical responsibility to its users it is currently violating. It has a feature that can cause massive performance problems, data loss, and data corruption. It has other bugs that accelerate these issues. DrivePool is aware of this, they should warn users using these features that unexpected behaviors and possible irreversible damage could occur. It annoys me the effort I had to exert to research this bug. As a developer if I had a file system product users were paying for and it could cause silent corruption I would find this highly disturbing and do what I could to protect other users. It is critical to remember this can result in corruption of the worst kind. Corruption that normal health monitoring tools would not detect (files can still be read and written) but it can corrupt files that are not being 'changed' in the background at random rates. It wouldn't matter if you kept daily backups for 6 months if you didn't detect this for 9 months you would have archived the corruption into those backups and have no way of recovering that data. It can happen slowly and literally only validating the file contents against some known good would show it. Now StableBit may feel they skirt some of the responsibility as they don't do the corruption directly, some other application relying on drivepool's drive acting as NTFS says it will, and DrivePool tries to pretend to do to get the data loss. The problem is drivepools incorrect implementation is the direct reason this corruption occurs, and the applications that can cause it are not doing anything wrong.1 point
-
As I understood it the original goal was always to aim for having the OS see DrivePool as of much as a "real" NTFS volume as possible. I'm probably not impressed nearly enough that Alex got it to the point where DrivePool became forget-it's-even-there levels of reliable for basic DAS/NAS storage (or at least I personally know three businesses who've been using it without trouble for... huh, over six years now?). But as more applications exploit the fancier capabilities of NTFS (if we can consider File ID to be something fancy) I guess StableBit will have to keep up. I'd love a "DrivePool 3.0" that presents a "real" NTFS-formatted SCSI drive the way CloudDrive does, without giving up that poolpart readability/simplicity. On that note while I have noticed StableBit has become less active in the "town square" (forums, blogs, etc) they're still prompt re support requests and development certainly hasn't stopped with beta and stable releases of DrivePool, Scanner and CloudDrive all still coming out. Dragging back on topic - any beta updates re File ID, I'll certainly be posting my findings.1 point
-
Hi ToooN, try also editing the section of the 'Settings.json' file as below, then close the GUI, restart the StableBit DrivePool service and re-open the GUI? 'C:\ProgramData\StableBit DrivePool\Service\Settings.json' "DrivePool_CultureOverride": { "Default": "", "Override": null to "DrivePool_CultureOverride": { "Default": "", "Override": "ja" I'm not sure if "ja" needs to be in quotes or not in the Settings.json file. Hope this helps! If it still doesn't change you may need to open a support ticket directly so StableBit can investigate.1 point
-
 As I interpreted it, the first is largely caused due to second. Interesting. I won't consider that critical, for me, as long as it creates a gentle userspace error and won't cause covefs to bsod. That's kind of my point. Hoping and projecting what should be done, doesn't help anyone or anything. Correctly emulating a physical volume with exact NTFS behavior, would. I strongly want to add I mean no attitude or any kind of condescension here, but don't want to use unclear words either - just aware how it may come across online. As a programmer working with win32 api for a few years (though never virtual drive emulation) I can appreciate how big of a change it can be to change now. I assume DrivePool was originally meant only for reading and writing media files, and when a project has gotten as far as this has, I can respect that it's a major undertaking - in addition to mapping strict NTFS proprietary behavior in the first place - to get to a perfect emulation. It's just a particular hard case of figuring out which hardware is bugging out. I never overclock/volt in BIOS - I'm very aware of its pitfalls and also that some MB may do so by default - it's checked. If it was a kernel space driver problem I'd be getting bsod and minidumps, always. But as the hardware freezes and/or turns off... smells like hardware issue. RAM is perfect, so I'm suspecting MB or PSU. First I'll try to see if I can replicate it at will, at that point I'd be able to push in/outside the pool to see if DP matters at all. But this is my own problem... Sorry for mentioning it here. Thank you for taking the time to reply on a weekend day. It is what it is, I suppose.1 point
As I interpreted it, the first is largely caused due to second. Interesting. I won't consider that critical, for me, as long as it creates a gentle userspace error and won't cause covefs to bsod. That's kind of my point. Hoping and projecting what should be done, doesn't help anyone or anything. Correctly emulating a physical volume with exact NTFS behavior, would. I strongly want to add I mean no attitude or any kind of condescension here, but don't want to use unclear words either - just aware how it may come across online. As a programmer working with win32 api for a few years (though never virtual drive emulation) I can appreciate how big of a change it can be to change now. I assume DrivePool was originally meant only for reading and writing media files, and when a project has gotten as far as this has, I can respect that it's a major undertaking - in addition to mapping strict NTFS proprietary behavior in the first place - to get to a perfect emulation. It's just a particular hard case of figuring out which hardware is bugging out. I never overclock/volt in BIOS - I'm very aware of its pitfalls and also that some MB may do so by default - it's checked. If it was a kernel space driver problem I'd be getting bsod and minidumps, always. But as the hardware freezes and/or turns off... smells like hardware issue. RAM is perfect, so I'm suspecting MB or PSU. First I'll try to see if I can replicate it at will, at that point I'd be able to push in/outside the pool to see if DP matters at all. But this is my own problem... Sorry for mentioning it here. Thank you for taking the time to reply on a weekend day. It is what it is, I suppose.1 point -
is there any update on this? I'm interested in buying drivepool and i want to use it not just for storage but also gaming.1 point
-

drivepool access
Shane reacted to dominator99 for a question
ps I don't like the term 'duplication' which suggests 2 copies of files/folders are created. I store 3 copies therefore 'replication' is a more appropriate term for more than 2 copies of files/folders. Call me pedantic!1 point -
drivepool access
VapechiK reacted to Christopher (Drashna) for a question
Are you sure that this was with StableBit DrivePool, and not Drive Bender? The reason I ask, is that we don't disable duplication, and we don't use the term "mirror" for file protection (it's always duplication). And because of the section in the licensing FAQ, and experience: https://stablebit.com/Support/DrivePool/Licensing This is a topic that has come up from time to time, and we do have plans on if this were to happen. Obviously, we don't want it to ever happen, but the future is uncertain. I believe the plan in that case was basically, disable the licensing altogether, and stop support completely for the software.1 point -
 Found out the cause. On Windows Server 2022 (and presumably 2019) - if you are logged in with ANY account that is NOT the actual "Administrator" - even if that account is a member of the Administrators group and has admin rights -it appears that File Explorer de-escalates itself - and requires "approval" for simple stuff like my screencap above. I was chatting with a user on Reddit who asked me - if you click Continue on my screencap - does the folder get renamed? And yes it does. So this is simply a User Account Control thing. Which BTW - I never saw on my other 2019 server - because you guessed it - I am running using the real Administrator account on that box. So now I just did the same on this new server. This is a home network so I am not worried about the "enterprise best practices" of never using the Admin account. One less box to click though a few hundred times is good enough for me. Solved. S1 point
Found out the cause. On Windows Server 2022 (and presumably 2019) - if you are logged in with ANY account that is NOT the actual "Administrator" - even if that account is a member of the Administrators group and has admin rights -it appears that File Explorer de-escalates itself - and requires "approval" for simple stuff like my screencap above. I was chatting with a user on Reddit who asked me - if you click Continue on my screencap - does the folder get renamed? And yes it does. So this is simply a User Account Control thing. Which BTW - I never saw on my other 2019 server - because you guessed it - I am running using the real Administrator account on that box. So now I just did the same on this new server. This is a home network so I am not worried about the "enterprise best practices" of never using the Admin account. One less box to click though a few hundred times is good enough for me. Solved. S1 point -

disk not shown in drivepool suddenly
Shane reacted to DenSataniskeHest for a question
Thanks for the answer. I manage dto get it converted back with a free tool: https://www.hdd-tool.com/download.html without dataloss.. Mabye that can help someone else1 point -
My issue is fixed! I had an accumulation of reparse files in the .covefs folder. The quantity must have gotten to a number that the program could no longer deal with causing the hangs. The root cause being symbolic links. Once I moved the folder out of the hidden one everything started acting as it should. The links no longer work but that is fine. I will figure a way around it. I stumbled on to this thanks to another forum post; The problem he was facing sounded all too familiar. Thanks for those who responded to my issue. Since these files can cripple a system when they get to a certain quantity it may be good idea for the program to throw an error as the number is reaching a level that can cause the system to become non-functional. Maybe an entry in the Wiki? I guess it might just be an edge case... Thanks1 point
-
Is Windows 7 still supported?
CyberSimian reacted to Christopher (Drashna) for a question
To clarify, Windows 7 (and 8,) are no longer supported by Microsoft, and no longer receiving updates. We follow suite with the Microsoft support lifecycles, since we can't ensure stability of the OS outside of the support lifecycle. Additionally, key components (such as .NET Framework and Visual C++ runtimes) may not be supported, anymore. Especially in the case where we need/want to update this components. However, we haven't done anything to explicitly disable support for these OSes, so they may still work just fine. However, the longer it's been since they've exited the support lifecycle, the more likely you are to have issues. Additionally, Windows 10 leaves extended support Oct 2025. Yay....1 point -

Is Windows 7 still supported?
CyberSimian reacted to The Doctor for a question
It is not listed as a supported operating system. That does not mean it will not work on Windows 7, I just installed it on a Windows 7 machine a few days ago and it works absolutely brilliant. A major upgrade from the pulling part of FlexRAID. Not supported just means that they are no longer providing active support for Windows 7. So if you have a problem, you may not get a lot of help with it. The other thing it means is that they are probably no longer testing new releases on Windows 7, so the next update may no longer work properly if at all. It's nothing to worry about, as long as you can accept these limitations. Ed1 point -
This applies to full disk array backup. But I chose specific folders to backup in SnapRAID config. So the parity file would be as large as the size of those folders + some overhead due to block size -> I chose here the smallest possible: 32k.1 point
-
The only con/issue that comes to mind is that there's no "one-click" way of splitting an existing pool into two pools let alone into a pool of two pools. If you stick to using the GUI, you have to remove half your drives (problematic if your pool is over half full!), create a new pool using them, then create the new super pool that adds the other two pools, then transfer all your content from the original pool into the super pool (which, because the pools are separate drives as far as Windows is concerned, involves the slow copy-across-drives-then-delete-original process rather than the fast moving-within-a-drive process). But if you don't mind the wait involved in basically emptying half of the drives into the other half and then filling them back up again, it is definitely the simplest procedure. Alternatively, if you're comfortable "opening the hood" and messing with hidden folders, you can manually seed the super pool instead - it is much quicker but also more fiddly (and thus a risk of making mistakes). Note also that nested duplication is multiplicative; if the super pool folder that will show up in your hub pools when setting per-folder duplication is x2 and your super pool is itself x2, your total duplication of files in the super pool will be x4. So I'd suggest setting each hub pool's super pool folder to x1, setting the super pool itself to x2 and only then commencing the transfer of your content from the hub pools to the super pool. I hope that makes sense.1 point
-
I am aware that I can set duplication to be delayed, which sets it to happen at "night". This system is a backup target so most activity happens overnight. Is it possible to schedule the duplication tasks to a specific start time e.g. 8 AM when the system is idle? [edit] I see that the settings.json file located in C:\ProgramData\StableBit DrivePool\Service contains "FileDuplication_DuplicateTime": { "Default": "02:00", "Override": null } Which might be my solution. Thanks.1 point
-
Re 1, DrivePool does not scrub duplicates at the content level, only by size and last modified date; it relies on the file system / hardware for content integrity. Some users make use of SnapRaid to do content integrity. Re 2, DrivePool attempts to fulfill any duplication requirements when evacuating a bad disk from the pool. It appears to override file placement rules to do so (which I feel is a good thing, YMMV). However, your wording prompted me to test the Drive Usage Limiter balancer (I don't use it) and I found that it overrides evacuation by the StableBit Scanner balancer even when the latter is set to a higher priority. @Christopher (Drashna) Re 3, I'd also like to know *hint hint*1 point
-
Is Windows 7 still supported?
CyberSimian reacted to Shane for a question
Hi, I'd guess the answer is that if it seems to be working - e.g. you were able to create a pool and it shows up in Explorer and you copied a file to it okay - then you likely won't have problems (besides having to use Windows). That doesn't guarantee that future updates to the program will work on 7 down the line, so you might want to avoid updating unless it's necessary / carefully check the changelog / be ready to revert.1 point -
The issue seemed to resolve itself. I did not have any rules set on D:\System Volume Information. But I didn't have to do the troubleshooting steps you recommended either. This is very strange. Anyway, thanks for all your help.1 point
-

"Error Adding Drive": cannot add the same disk to the pool twice
Shane reacted to Vittorio Zamparella for a question
It worked! I did three things: I evacuated my poolpart.uuid folder (moving content to another folder) Deleted everything in C:\ProgramData\StableBit DrivePool\Service\Store\Json. Deleted everything in %AppData%\StableBit DrivePool I think what made it was the last step because I had already reset the settings from withing the gui and I think that has to do with the configuration store in Json folder. Now I'm adding my data back. Hopefully everything will go smooth from now on. Thank you!1 point -
If Plex is accessing the files in the pool via network and the others are local, you could try enabling Manage Pool -> Performance -> Network I/O boost. If your pool has duplication enabled you could try enabling Manage Pool -> Performance -> Read striping, if it isn't already. Some old hashing utilities have trouble with it, your mileage may vary. There is also Manage Pool -> Performance -> Bypass file system filters, but that can cause issues with other software (read the tooltip carefully and then decide). You might also wish to check if Windows 11 is doing some kind of automatic content indexing, AV scanning or other whatever on the downloaded files that you could turn off / exclude?1 point
-
Hi xelu01. DrivePool is great for pooling a bunch of mixed size drives; I wouldn't use windows storage spaces for that (not that I'm a fan of wss in general; have not had good experiences). As for duplication it's a matter of how comfortable/secure you feel. One thing to keep in mind with backups is that if you only have one backup, then if/when your primary or your backup is lost you don't have any backups until you get things going again. Truenas's raidz1 means your primary can survive one disk failure, but backups are also meant to cover for primary deletions (accidental or otherwise) so I'd be inclined to have duplication turned on, at least for anything I was truly worried about (you can also set duplication on/off for individual folders). YMMV. Regarding the backups themselves, if you're planning to back up your nas as one big file then do note that DrivePool can't create a file that's larger than the largest free space of its individual volumes (or in the case of duplication, the two largest free spaces) since unlike raidz1 the data is not striped (q.v. this thread on using raid vs pool vs both). E.g. if you had a pool with 20TB free in total but the largest free space of any given volume in it was 5TB then you couldn't copy a file larger than 5TB to the pool.1 point
-
That's ok to do, won't cause any harm.1 point
-
I also got a little brave/creative/foolish and had the thought that maybe I could kick off the duplication process on P manually via command line since the GUI wouldn't come up and it wasn't duplicating on it's own from the nightly job. So I did a dpcmd check-pool-fileparts P:\ 1 which completed successfully. When I checked F in clouddrive, the usage has increased and there's 1TB+ queued. So it looks like it's duplicating. That's one good thing so far!
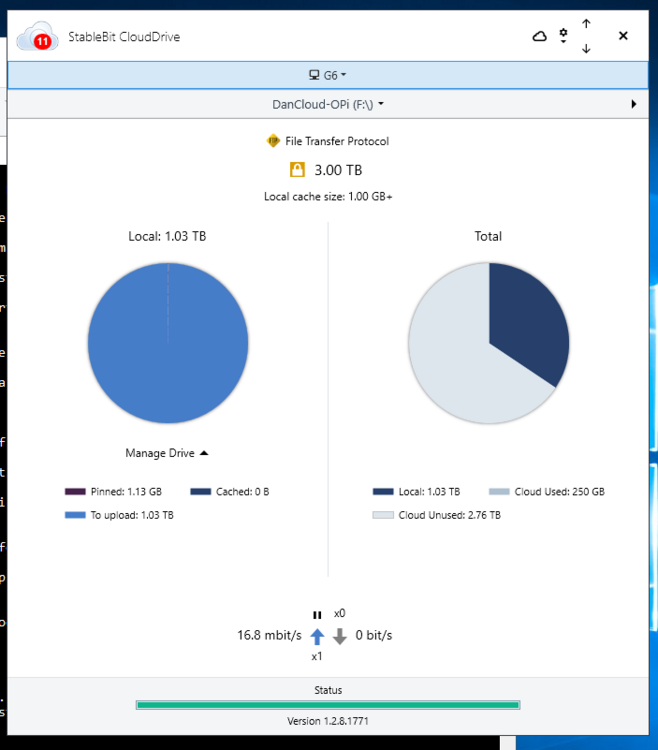 1 point
1 point -
Applied some more Google-Fu and found this command GWMI -namespace root\cimv2 -class win32_volume | FL -property DriveLetter, DeviceID which gave me different GUIDs than from diskpart. I was able to match the volume from the logs to the GUIDs provided by that command. I think I have corrected the permissions from https://community.covecube.com/index.php?/topic/5810-ntfs-permissions-and-drivepool/ and will try a balancing pass. Thanks again,1 point
-
The detach was successful. I had to do a reboot between the detach and the re-attach. However when I re-attached F, the configuration screen came up, I selected another physical drive on which to put the cache. That was some time ago and it has not yet appeared in the GUI. I believe it's adding it, but maybe very slowly, as the Clouddrive app is using about 40% of the CPU. The other detached clouddrives (formerly M & K) are visible in the GUI but have lost their drive letters. Also the Drivepool GUI will not come up, though I have access to all the lettered drives via windows explorer and command prompt. I guess I'll give it overnight and hope that F: gets re-attached and that is the cause of the Drivepool GUI not responding.1 point
-
Wrong SSD size report in DrivePool
Slaughty101 reacted to Shane for a question
I'd suggest opening a support ticket with StableBit.1 point -
For anyone that finds this later. The system is now balancing for free space on each drive. At this point the only thing I can assume was that because one drive was over 90% full it just completely broke balancing with the Drive Space Equalizer plugin, and that failure cascaded and broke balancing for all plugins. I had the Prevent Drive Overfill set to not go over 90%, but I'm wondering if any plugin will actually bring a drive under 90% usage (if that's what it's set too) once it's already gone over. All the text seems to imply it will just stop it going over 90%, nothing about recovering from such a situation. I disabled all plugins except the disk usage limiter and told it not to put any unduplicated data on DRIVE2. That ran successfully and got DRIVE2 under 90%, and after that and enabling the other plugins it started working exactly as I'd expected it to do so for the last year.1 point
-
regarding power: to use a PSU without a motherboard An "ATX Jumpstarter" AKA an ATX connector that connects Pin 14 to ground. you can also tie this to a power switch but it must be a latching type (most cases have push button style power buttons) if you want a little future expandability (and the ability to use less and longer cables) you can replace the SAS breakout brackets with a SAS expander. my personal pick would be the AEC-82885T (although that uses Mini-SAS HD connectors, 8643+8644). this would allow you to use SATA disks using longer cables (SATA cables use a lower signaling voltage) and allow you to connect just one SAS cable to each JBOD. (yes, you are connecting 8 disks using one 4 lane 6Gb or 12Gb link, but it's barely noticeable for spinning drives)1 point
-

Moving files directly out of the poolpart folders
smitthhna reacted to tylerdotdo for a topic
Hey guys, Drivepool has served me well for over 10 years. Unfortunately, I'm moving over to Unraid. Nothing to do with Drivepool itself; it works fantastic. I just can't get Snapraid to work in conjunction with it, and I need that extra layer of backup. So my question is, I do need to evacuate off of the Drivepool one drive at a time, and I don't have enough room to empty a drive, remove it, and then go to the next drive. I was wondering if it was possible to move files directly off of a particular drive's poolpart folder instead? Will it cause Drivepool to freak out in any way?1 point -

Reformatted Drives not appearing in the Non-Pooled list
Lane reacted to Rob Manderson for a question
Aha! Found a hint to the answer on about page 86 of this forum. I deleted the volume and created a new one and voila - there the new drive is in the non-pooled section. I think volume id's are the culprit!1 point -
Scanner compatibility with Hard Disk Sentinel.
BIFFTAZ reacted to Christopher (Drashna) for a question
There should be absolutely no issue with doing so. Neither product does anything that takes exclusive control over anything, so it should be safe to run both products concurrently. What are you trying to monitor specifically, here? If you don't mind me asking.1 point -
StableBit.com Contact Site issues
smitthhna reacted to Christopher (Drashna) for a topic
Due to an unexpected glitch while updating the site, the Contact site is broken. We're working on fixing this issue as quickly as possible. We have fixed the issue with the Contact site. However, if you experience any issues with it, please let us know know right away. You can do so, by contacting me directly at "christopher@covecube.com". Just let us know what the issue with the site is, and what the issue that brought you to the site was. We apologize for any trouble that this may have caused.1 point