


Sonicmojo
-
Posts
58 -
Joined
-
Last visited
-
Days Won
2
Recent Profile Visitors
1844 profile views

Sonicmojo's Achievements
-
 Shane reacted to an answer to a question:
Removing CREATOR OWNER permissions from Drivepool root drive locks out Admin users when creating folders for shares
Shane reacted to an answer to a question:
Removing CREATOR OWNER permissions from Drivepool root drive locks out Admin users when creating folders for shares
-
Found out the cause. On Windows Server 2022 (and presumably 2019) - if you are logged in with ANY account that is NOT the actual "Administrator" - even if that account is a member of the Administrators group and has admin rights -it appears that File Explorer de-escalates itself - and requires "approval" for simple stuff like my screencap above. I was chatting with a user on Reddit who asked me - if you click Continue on my screencap - does the folder get renamed? And yes it does. So this is simply a User Account Control thing. Which BTW - I never saw on my other 2019 server - because you guessed it - I am running using the real Administrator account on that box. So now I just did the same on this new server. This is a home network so I am not worried about the "enterprise best practices" of never using the Admin account. One less box to click though a few hundred times is good enough for me. Solved. S
-
Another update here. So I added another drive to the server via the hotdock slot - and the same weird thing is occurring on the this stand alone drive as well. So it appears not to be Drive pool related after all. Now I need to figure out where this is coming from and how to fix it. Seems something is sorely messed up here. S
-
Chris And that is what I do have - a very freshly formatted drive. And it is very odd. But I need to be able to ctrust this build for the long term and be able to create folders both on the fly or using Server tools on this pool whenever the mood strikes So I need to figure out exactly what Windows specific thing this is. Will keep testing this. Sonic.
-
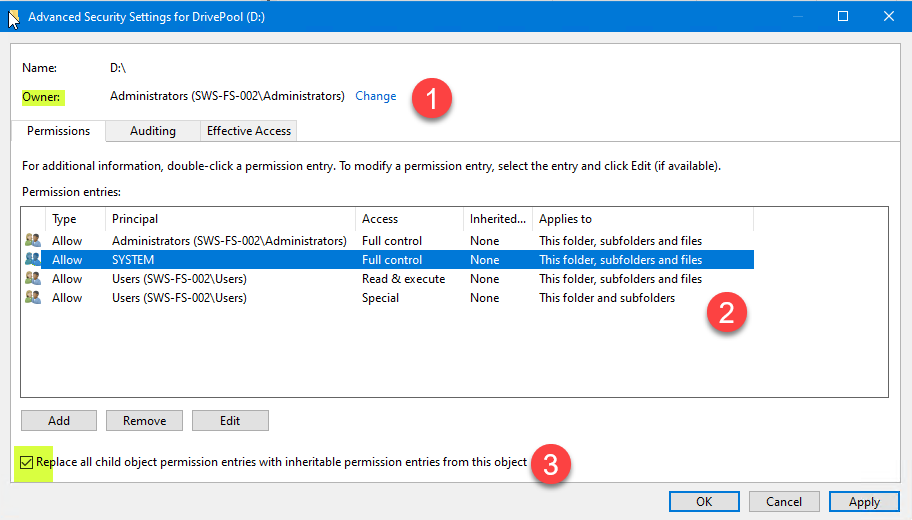
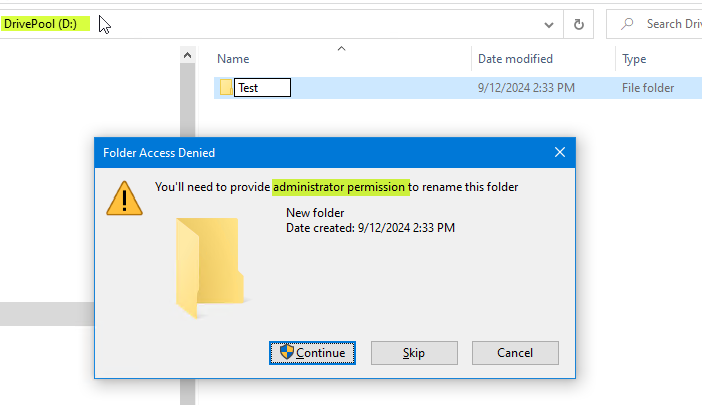
Long story short. New Windows 2022 Server. Latest Drivepool. New pool created moments ago (2 8TB EXOS drives). Pool created perfectly. Used this Covecube Knowledge Base Article to preset the pool NTFS defaults BEFORE creating any shares: StableBit DrivePool Q5510455 - Covecube - Wiki 1. Owner - check 2. Permissions - check (removed CREATOR OWNER) 3. Enable inheritance - check Click OK - applied successfully (minus a couple of benign errors about Recycle Bin etc) Whether I restart the server after this - OR just go right in the now empty pool drive and attempt to create a folder - I get this: For the record - I AM signed in with a Admin Account. This account is part of the Administrators group. AND only that group. Account is not even in the Users group. I have read other users out on the net have had this issue - specifically with DrivePool - in other similar situations. I should also mention that I have another older Windows 2019 Server running here and this was never an issue. If CREATOR OWNER is left in the permissions - any folders that I create on the fly on the server - immediately get owned by the account that created them - I do not want that. And the article above specifically says to clean everything out but what I have left in as above. Should also mention that I create a share using the Server Manager->Add Share Wizard - the share is created correctly WITH the right defaults as above. However - if I am on the server logged in as WSA (windows server admin) - I still get nailed with the message above. Conversely - if I move over to a VM that I have, log into it with the same WSA account - I am able to browse to this new share, create, rename and delete a folder with no issues whatsoever. What is going on? Sonic.
-
Sounds good. Thanks for the update! Cheers Sonic.
-
Understood - but this error is a result of updating to the latest? Or do I need to manually update and then this will go away for the future? Sonic.
-
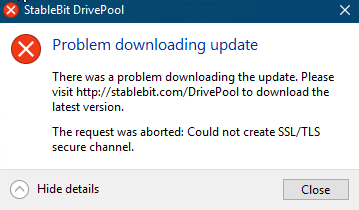
Noticed the two new updates for Drivepool and Scanner and when I click on the tray notification for each - I see the attached message. On two servers. For the first time ever. Comments? Sonic.
-
Yesterday Scanner tells me we have an impeding drive failure so I evacuated the drive and swapped a new one into the pool. But even after forcing a Rebalance (using the Disk Space EQ plugin) - Drivepool has been sitting here for over an hour "building bucket lists" and not moving anything. What is the deal with this plugin - does it actually do anything or is it conflicting with the other 5 plugins I have installed - which seemingly never seem to balance anything either? I remember a few year back - I would swap in a new drive, add it to the pool and almost immediately Drive Pool would start balancing and moving files to ensure each drive was nicely filled - now it seems no matter what I throw at the problem - it does not want to do anything unless forced? Sonic.
-
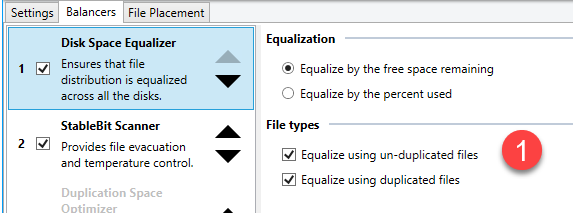
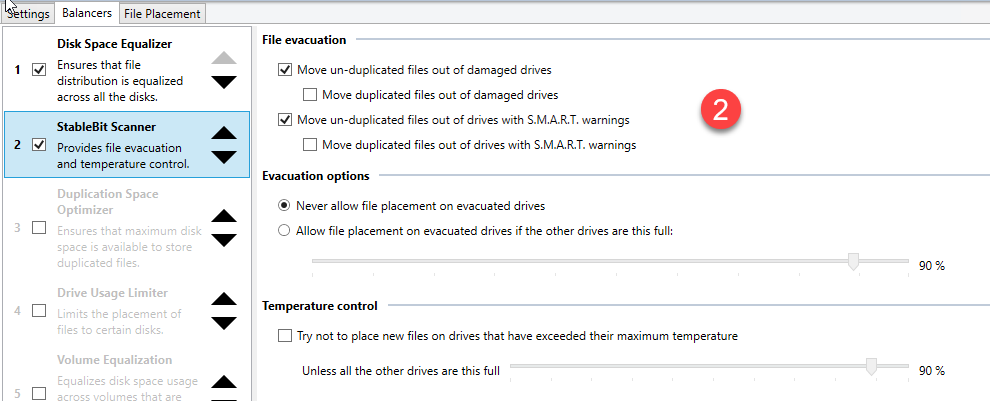
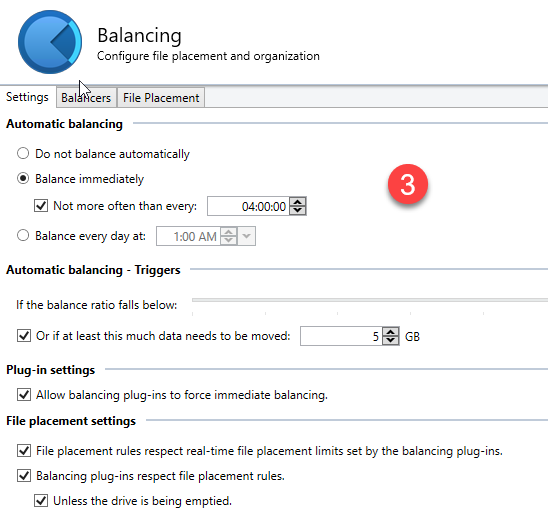
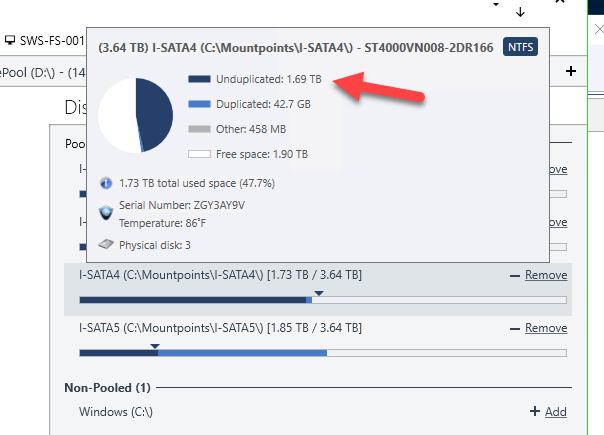
Chris The disk checks out perfectly in Scanner. The only issue presented was this massively excessive "head parking" which looks like was being caused BY Scanner. All other SMART data is fine and I cannot see any evidence of anything else wrong with it. Regarding the "evacuation" by Drivepool/Scanner - I did have a number of the built in balancers activated for a long time but have since cut it back to just two: Disk Space EQ And StableBit Scanner - with a specific focus on ensuring my "unduplicated" files are being targeted - if there's a problem with a drive. And here are my "balancing" settings: What is most concerning to me is that Scanner is NOT honoring the logic of moving "unduplicated" files away for "possible" problematic drives. In this case - here is the drive that exhibited the excessive head parking (But nothing more) and now Scanner/Drivepool have filled this drive to max with unduped files - leaving me in a nasty state if something does happen here: Ideally - I need to see this drive looking more like the rest of the drives with a balance leaning more to "duplicated" files rather than not duplicated. Any ideas with the balancers or balance settings that might make this even out a bit better. Also - this drive is less than a year old - and while I am certainly not saying that problems are not possible - Scanner is not indicating any issues that are obvious. I have also checked the drive extensively with Seagate tools and nothing negative is coming back from that toolset either. As of right now - this drive appears to be as normal as the other three - except for the ridiculous head parking count - which as of now looks to be driven by Scanner itself. I have another server - running a pair of smaller 2TB Seagate drives (from the same series as the server above)- which have been up and running for a year and 4 months - and each drive has a load cycle count of 109 and 110 respectively. The 4x4TB drives in the server above have been running for just over a year and each drive has load cycle counts in 490000 range. The one drive that Scanner started reporting SMART issues with had a load cycle count of over 600000 before I shut it off. Even Seagate themselves were shocked to see that load cycle number so high - indicating that all of these NAS drives should really never exceed 1000-2000 for the life of the drive. So I am not sure exactly what SCANNER is doing to one set of my drives and not the other - but it's a problem just the same. As I mentioned - my File Server (4x4TB) does not see a lot of action daily and anything it does see should be handled with ease by the OS. It is unfortunate that there is some sort of issue with the Advanced Power Management settings on Scanner for the File Server but even with APM enabled on the other server - there appears to be no issues with the Load Cycle or any other issue. Appreciate any additional tips. Cheers Sonic.
-
That may be true - but it looks like the beta action stopped around Mar 12-15. Would not surprise me if this is COVID related but it would be nice to at least get a one liner status update. Sonic
-
Just wondering what is happening in here lately? I have asked a couple questions in the last week to 10 days and usually get an answer after a day or two? Is Covecube support no longer coming round or is the actual company not active? I realize the world is in a crap state right now but it would be nice to know if anyone is home? Sonic.
-
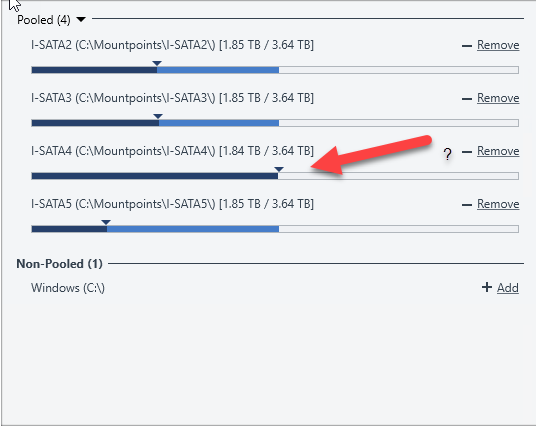
Updated Data I did some reading on the forum here and found this tidbit from a few years back: In theory, the "Disk Control" option in StableBit Scanner is capable of doing this as well, and persistent after reboot. To do so: Right click on the disk in question Select "Disk Control" Uncheck "Advanced Power Management" Hit "Set". I have enabled this on all my drives to see if the "parking" will settle down But then I noticed that DrivePool was acting strange last night as well. It had begun an "Evacuation" of all the files from this specific drive - acting as if there was some sort of data emergency. When I checked into the server around dinner time last night - DP was displaying a message saying 63.5% Building data buckets (Or something similar) - it seems like it was hanging there forever. So I hit Reset in Drivepool and let it run the inspection routines etc to confirm the pools and ensure the data was sound (it was). But when I went into server again this morning - I saw that my Balancers had been altered. The "disk space" balancer (at the top of the stack) had been disabled - leaving the Stablebit Scanner balancer next in line. I believe it's parameters took priority which some lead to the emergency evacuation action. I re-enabled the Disk Space Balancer and now ended up[ with this: Any ideas what is going on? Sonic
-
For the first time ever - I received this message from Scanner on a SEAGATE Ironwolf NAS drive that is about a year old: ST4000VN008-2DR166 - 1 warnings The head of this hard drive has parked 600,001 times. After 600,000 parking cycles the drive may be in danger of developing problems. Drives normally park their head when they are powered down and activate their head when they are powered back up. Excessive head parking can be caused by overzealous power management settings either in the Operating System or in the hard drive's firmware. This drive (and 3 other identical ones) are part of my Windows Server 2016 file server which really sees very little action on a daily basis. What is the story with this message and why would this drive be "parking" Itself so frequently - considering the server is never powered down (only rebooted one per month following standard maintenance). I have not had a chance to look into the other 3 drives yet - but this is concerning just the same. Is there a possibility that DrivePool or Scanner are the cause of this message? Appreciate any info on this. Cheers Sonic.
-
Well - I am not about to remove a drive to test this version but it's nice to know something new is available. Also glad I am not the only one experiencing this issue. S
-
This makes complete sense - but how come the actual "Remove drive" process never completed? Is it not supposed to go to 100% (while leaving the dupe files on the drive) and conclude in a correct fashion? In my case - DP simply stopped doing anything at 94% and sat there for hours and hours and hours. This feels very uncomfortable on many levels - yet I had no choice but to kill the process. Luckily - there was no residual damage to my hard stop as all that was left on the drive where dupes. But this experience does not make me feel very trustworthy toward this app if a process cannot wrap up gracefully and correctly - especially when user data is being manipulated. S