Search the Community
Showing results for tags 'Duplication'.
-
Long time user of DrivePool. Currently using file duplication for specific folders. Scenario: data gets corrupted on one of the disks, either uncaught physical sector failure or bit rot. Is DrivePool aware of the duplicated data inconsistency? What is the current DrivePool strategy when ejecting a potentially failing drive for duplicated data - does the duplication continue on the rest of the disks in the pool, even if they were not selected by user for duplication? Is the team currently working on expanding on file protection functionality? Specifically: An option to the file placement strategy where the newest disks in the pool with most recent good SMART status and/or surface scan pass are considered Ability to generate hash checks of the duplicated data, before initial duplication (or re-generate it per user or if it does not exist) Use the hash checks to verify consistency of duplicated data across drives When inconsistency is found, copy over from the "good" drive Expand data resiliency with a mechanism like parity archives (PAR2) with options to: Choose the amount of parity check archives to generate, maybe as percentage of the actual data Choose location (disk) to store parity data - can be same drives as duplicated data or separate ones Data integrity checks of the PAR2 files (hashes - if this kind of thing is actually needed, not sure) Intelligent PAR2 cleanup when files are deleted through user action Intelligent data integrity check option: on user / program access of a duplicated file Scheduled data integrity check option: configurable, to do full hash checks of duplicated data, present user with info and option when inconsistencies were found (this is where the PAR2 data re-generation happens)
-
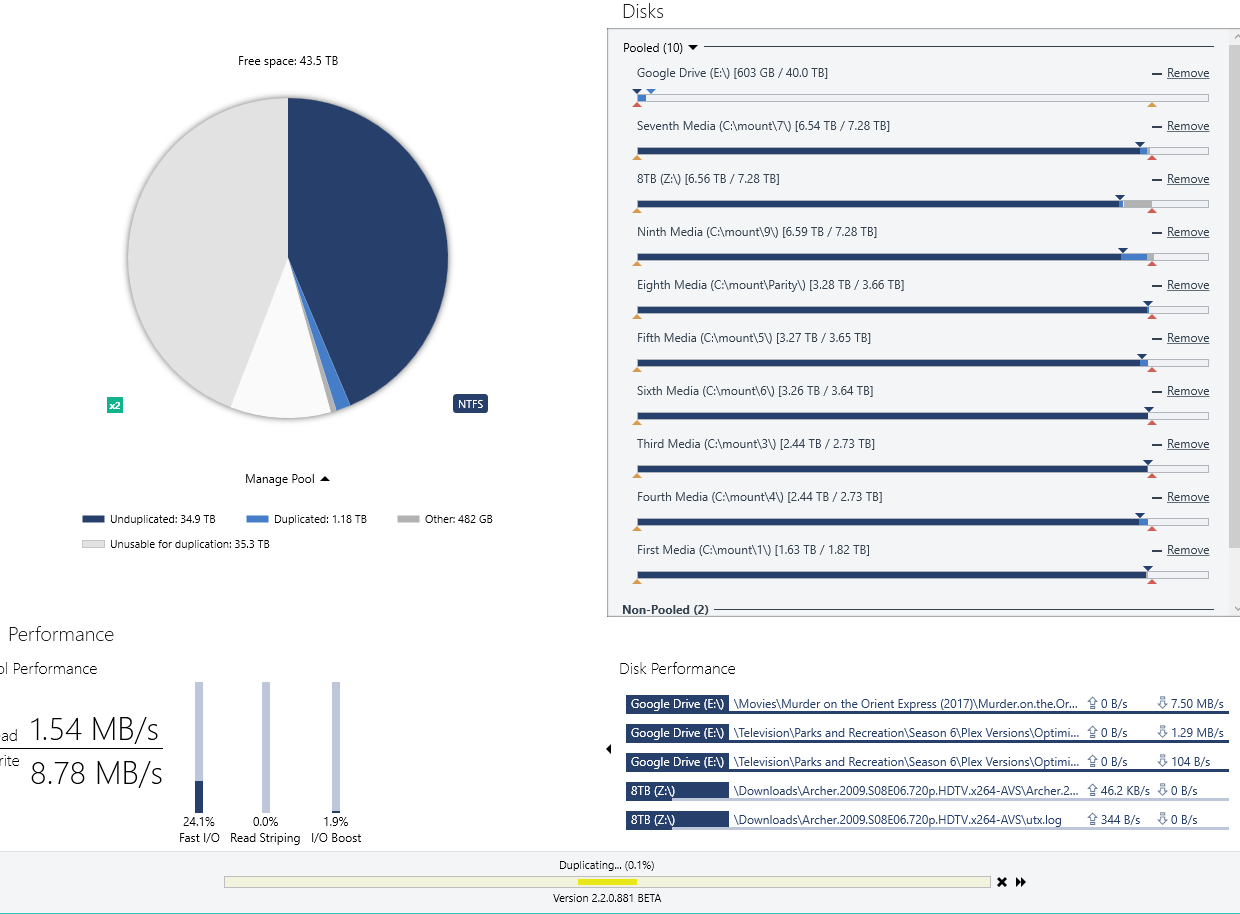
I recently had to remove a drive from a pool when I realized it was failing during a duplication check. The drive was emptied OK, but I was left with 700MB of "unusable for duplication" even after repairing duplication and remeasuring the pool. Then I decided to move a 3GB file off of the pool, and now it's saying it has 3.05GB of "unusable for duplication." But 700MB + 3GB != 3.05 GB... I'm lost. What is going on? How can I see what is unusable for duplication? Did I lose data? How do I fix this? EDIT: I also have 17.9GB marked "Other" but even after mounting each component drive as its own drive letter, no other files/folders are present than the hidden pool folder.
-
Hello together, I just optimized my Drivepool a bit and set a 128 GB SSD as write cache. I had another SSD with 1GB I had left I put into the pool and set drivepool to write only folders on it which I use most and should be fast available. This folders have also a duplication (the other Archive drives are HDDs). I'm not sure if this is working or the SSD is useless for more speed. How is drivepool working: - does drivepool read both the original und the duplicated folders if I use them from the Client? - will drive pool recognize which drive is faster and read from this first? best regards and thanks for your answers
-
I am a complete noob and forgetful on top of everything. I've had one pool for a long time and last week I tried to add a new pool using clouddrive. I added my six 1TB onedrive accounts in cloudpool and I may or may not have set them up in drivepool (that's my memory for you). But whatever I did was not use drivepool to combine all six clouddrives into a single 6TB drive and I ran out of space something was duplicating data from one specific folder in my pool to the clouddrive. So I removed the clouddrive accounts, added them back, and did use drivepool to combine the six accounts into one drive. And without doing anything else, data from the one folder I had and want duplicated to the clouddrive started duplicating again - but I don't know how and I'd like to know how I did that. I've read nested pools, hierarchy duplication topics but I'm sure that's not something I set-up because it would have been too complicated for me. Is there another, simpler way that I might have made this happen? I know this isn't much information to go on and I don't expect anyone to dedicate a lot of time to this, but I've spent yesterday and today trying to figure out what I did and I just can't. I've checked folder duplication under the original pool, and the folder is 1x because I don't want it duplicated on the same pool so I assume that's not what I did.
-
I posted about this last year or earlier this year and never really got an answer, then it went away, and now it is back again... At seemingly random intervals (I have been unable to figure out what triggers it) my drive pool will decide that I didn't *really* want those folders to be duplicated and will turn off folder duplication. It then takes me literally days of waiting for it to reduplicate after I tell it to do so. It does not turn off all folder duplication - just certain folders, and not even the same ones consistently. For example, today it decided that I didn't need my TV show MKV files duplicated. It seems that the folders I have protected from drive failure remain (3x), but the ones where I just want two copies of everything randomly reset themselves. What do I need to do to figure out what is causing this and stop it from happening again?
-
Hello! I'm fairly new to StableBit, but liking the setup so far! I've got a few pools for various resources in my server. In case it's important, here's a quick idea of what I've got running: Dell R730 running Windows Server 2019 Datacenter, connected to a 24 disk shelf via SAS. Each drive shows up individually, so I've used DrivePool to create larger buckets for my data. I'd like to have them redundant against a single drive failure, but I know that means duplicating everything. I will eventually have a pool dedicated to my VMs, and VMs deduplicate very well since each one requires essentially a copy of the base data, and while I will have backups of this data, I'd still like to have a quicker recovery from a drive failure in case that does happen so they'd also be duplicated... (Scanner currently tells me one of my disks is throwing a SMART error, but i don't know how bad it is... I'd like to run it into the ground before replacing it to save money on purchasing new hardware before it's actually dead...) So, I know deduplication isn't supported against the pool itself, but I was curious if people have deduplicated the physical disks, and if windows dedupe sees the pool data and tries to deduplicate it? I noticed this thread, unfortunately it's locked for further comments as it's fairly old, was talking about deduplicating the drives that a pool uses, but I don't know if they meant the files that weren't part of a pool, or if they were talking about the files from the pool. If possible, I'd love to hear an official answer, since I'd rather not run this in an unsupported way, but I'm really hoping there's a way to deduplicate some of these files before I run myself out of space... Thanks for any info that you can provide!
-
Is it possible to schedule duplication so that it is not real time?
-
1.) Is there any way to override the default 3x duplication for reparse points? They're stored on my C Drive (I know, I know) which is backed up once a week. 2.) Are files verified when they're balanced? Is that why my poor drives are pegged at 100% utilization? Again, any way to turn this off?
-
I suspect the answer is 'No', but have to ask to know: I have multiple gsuite accounts and would like to use duplication across, say, three gdrives. The first gdrive is populated already by CloudDrive. Normally you would just add two more CloudDrives, create a new DrivePool pool with all three, turn on 3X duplication and DrivePool would download from the first and reupload to the second and third CloudDrives. No problem. If I wanted to do this more quickly, and avoid the local upload/download, would it be possible to simply copy the existing CloudDrive folder from gdrive1 to gdrive2 and 3 using a tool like rclone, and then to attach gdrive2/3 to the new pool? In this case using a GCE instance at 600MB/s. Limited of course by the 750GB/day/account. And for safety I would temporarily detach the first cloud drive during the copy, to avoid mismatched chunks.
-
Hey everyone, New to the drivepool game here, absolutely loving this software. Has made storage and backup so much easier. Sorry if these are stupid questions here. 1. I seem to be a bit confused how the "Folder duplication" process works. I have one of my movies folders set to duplicate, it's around 2.5tb. However, when I turn on duplication, the duplication across all my drives is around ~5.7tb. I don't have any other folders set for duplication, why would this figure be so high? I guess I was expecting duplication to be around the same size as the folder I was duplicating (2.5tb). Is the duplication figure the size of original folder plus the size of the duplication? 2. Am I able to safely add my C:/ drive to my pool? It's a 1TB SSD, I was hoping to harness some of its speed as a cache drive as it's mostly empty right now. Is this safe/possible? Thanks again for the phenomenal product, probably the happiest I've been with a software purchase in a long time.
-
Not sure if this is possible or easy... Right now I have my pool 3x duplicated (upgraded from 2x duplicated) and I have 1.51TB marked in a dark blue which is keyed as "unduplicated." Does that mean it's only x1 on the pool, or it's x2 but not yet x3 duplicated? If you had colors for how many copies of a file are on the pool that would be great! (i.e. Red for 1x copy, Blue x2 Copy, Green x3 Copy, etc.) * Of course, not sure how this would work if folks are doing a full pool duplication like I am and instead duplicating some folders only.
-
I am a newbie to StableBit. My son has been using it for over a year and introduced it to me after I nearly lost 48TB of data at home due to Windows 2016/10 poor Storage Spaces [I'd never make that mistake again and pity anyone who does. They're asking for problems!]. Thank goodness for tape backups! Anyway, I installed it and added QTY (23) 4TB drives to create my pool. Then began restoring data to the new pool. This afternoon I saw a warning that one of my 4TB drives went from 100% health to 9% in 3 hours. I guess the stress of writing data was too much. I keep the server room at 70 degrees and excessive airflow through the drives to keep them cool. Ask my wife, she has to wear ear protection when she steps into the server room. I do to if I spend more than 5 minutes. See box of foam earplugs on wall as you enter. Sorry, got sidetracked. Anyway. I removed the failing hard drive from the pool and gave it a drive letter. I thought the data on it was the only copy but to my surprise when I tried to move it to the existing pool the data was already there? Did I set it up wrong? I don't want any sort of duplication turned on because I back it up to a separate server which backs up to LTO5 every day. Where/how do I turn off duplication? Thanks in advance, Terry
-
Started a duplication of my 40 tb drivepool and read this answer which confused me and seems to contradict how i'm going about this I made a 40 tb clouddrive and thought that if i selected the original drives as unduplicated and the cloud drive as duplicated and selected duplication for the entire array it would put a copy of every file in the original pool on the cloud drive. If a drive failed i could easily rebuild from the cloud drive. Here are some settings In that other example you told the user to make another pool with the original pool and the cloud drive and set duplicated and unduplicated on both. I am missing the (probably easily apparent) issue with my setup. Also if i do need to do that what is the most efficient way to start that work without losing anything or having wasted time uploading to cloud drive
-
I've read Drashna's post here: http://community.covecube.com/index.php?/topic/2596-drivepool-and-refs/&do=findComment&comment=17810 However I have a few questions about ReFS support, and DrivePool behavior in general: 1) If Integrity Streams are enabled on a DrivePooled ReFS partition and corruption occurs, doesn't the kernel emit an error when checksums don't match? 2) As I understand it, DrivePool automatically chooses the least busy disk to support read striping. Suppose an error occurs reading a file. Regardless of the underlying filesystem, would DrivePool automatically switch to another disk to attempt to read the same file? 3) Does DrivePool attempt to rewrite a good copy of a file that is corrupt? Thanks!
-
Hello, I recently started upgrading my 3TB & 4TB disks to 8TB disks and started 'removing' the smaller disks in the interface. It shows a popup : Duplicate later & force removal -> I check yes on both... Continue 2 days it shows 46% as it kept migrating files off to the CloudDrives (Amazon Cloud Drive & Google Drive Unlimited). I went and toggled off those disks in 'Drive Usage' -> no luck. Attempt to disable Pool Duplication -> infinite loading bar. Changed File placement rules to populate other disks first -> no luck. Google Drive uploads with 463mbp/s so it goes decently fast; Amazon Cloud Drive capped at 20mbps... and this seems to bottleneck the migration. I don't need to migrate files to the cloud at the moment, as they are only used for 'duplication'... It looks like it is migrating 'duplicated' files to the cloud, instead of writing unduplicated data to the other disks for a fast removal. Any way to speed up this process ? CloudDrive: 1.0.0.592 BETA DrivePool: 2.2.0.651 BETA
-
I'd like to pool 1 SSD and 1 HDD and with pool duplication [a] and have the files written & read from the SSD and then balanced to the HDD with the files remaining on the SSD (for the purpose of [a] and ). The SDD Optimizer balancing plug-in seems to require the files be removed from the SSD, which seems to prevent [a] and (given only 1 HDD). Can the above be accomplished using DrivePool? (without 3rd party tools) Thanks, Tom
-
Maybe this is a feature request...I migrated (happily) from Drive Bender. And for the past year, I've been very satisfied with Drivepool/Scanner combo. However, one tool that Drivebender had (that I miss) is the ability to run a duplication check. It would identify any files marked for duplication that it can't find a duplicate of. After that, I could force duplication and it would begin creating those duplicates. Of course, this is supposed to be automatic. I have my entire pool duplicated. But when one lone 3TB drive fails, I'd like to run a duplicate check to see if all the files have been duplicated or if I lost any.
-
Hi, I am running DP 2.x with WHS 2011. I have 2 Pools of 2x2TB HDDs, duplication is set to x2 for everything. I backup everything using WHS 2011 Server Backup. One Pool (392 GB net) contains all the shares except for the Client Backups. The other (1.16 TB net) contains only the Client Backups. Of each Pool, I backup one underlying HDD. Given that the Client Backup database changes, the Server Backup .vhd fills up tracking changes and reaches its limit of 2TB. At that time, all Server Backups are deleted and WHS Server Backup starts over again with a full backup. This is fine in principle but it does mean that the history I actually keep is not as long as I would like. Also, should a HDD fail then there is no HDD to which it can migrate the data. So I would like to create one Pool of 4 x 2TB, x2 duplication. That way, each HDD would contain about 750GB so that the history I keep is longer. The problem is though that files may be placed on the two HDDs that I do not backup. So I am wondering whether it is possible to tell DP to, in a way, group the HDDs in a 2x2 fashion, e.g., keep one duplicate on either E: of F: and the other on either G: or H:? Or, put otherwise, keep an original on E: or F: and the copy on G: or H: (I realise the concept of orginal/copy is not how DP works but as an example/explanation of what I want it to do), to the extent possible. It would not be possible if, for instance: - E: or F: failed, I would still have duplicates after migration but some will be on G: and H: - G: or H: failed, I would still have duplicates but some would be on both E: and F: I do realise that once either E: or F: fails, my Server Backup will be incomplete. However, that is true for my current setup as well. The intention would be to replace E: of F: and then ensure that the duplication/placement scheme is correct again (and I would hope this works automatically if the new HDD as the appropriate drive letter and gets added to the Pool). I have looked at the File Placement tab but I don't see how I should set up rules to accomplish what I want. Kind rgds, Umf
-
Hello, I moved most of my hard drives from my main PC to my Storage / HTPC server. Now currently I am running a - Windows Raid 1 (duplication) two 3 TB drives (personal Media up to 2011) - 1 Single 3 TB harddrive (personal other files) - 1 single 2 TB files which seems to be slowly failing (personal Media 2012+) - adding two new 3 TB drives next week all of those are backed up to the cloud with crashplan. Crashplan is re-synchronizing right now. I heard much good about drivepool. BUT I am really confused why I hardly cant find any YOUtube videos like reviews or hands one videos (is it not that popular) I just installed a trial and what i read was that it will always write data on the harddrive that is the least full. Now I always like a backdoor. And it seems drivepool gives you that backdoor. BUT and that seems to be a BIG BUT... files might be randomly on different harddrives...!!! With 5TB of Photos (lets say 200.000 photos) I see a NIGHTMARE ever wanting to change back....! I DO like the idea that drivepool could duplicate everything, but I am really scared off making a HUGH Mess!!! Why do I want to use drivepool... for example i like to have all Media in one drive... since i have more than 3 TB data i cannot physically store it in only one HD. Also currently my Raid1 cant be used from drivepool. I would have to "unraid" and go from there... (but how) any thoughts would really be appreciated!!! Let say I want to Migrate... what would be the best way to do so? Alex
-
I have a drive, C;, the system drive which has suddenly decided to dump all its duplicated files on the other drives. Why? Doesn't seem very efficient. I've attached a screen capture of what I see. Richard
-
Hi, I'm currently evaluating DrivePool to figure out if it's for me. So far, things are looking very positive. The flexibility compared to Storage Spaces and the newly added folder placement feature are exactly what I need . One thing I would like to do however is to place my user accounts on a pool for redundancy. I know i can redirect documents and things easily within Windows, but this doesn't include AppData and all the other special folders. My plan is to keep the administrator acount on my root install so if the pool's not available I can still login. I created a user account, "pool" and used this to redirect it to the pool storage. Everything worked fine, I could login to the PC and my data was being written into the pool. Can you see anything wrong with redirecting my individual user accounts using this method? Or is there a better way I shouild be aware of to do this? (by the way, one issue I did have is I tried rebooting into safemode just to see what happened and as expected it didn't work as the user folder wasn't available. It logged me into a temporary profile and even after trying to reset the user account back to normal through HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList it still wouldn't work even when back in normal Windows - I'm assumng Windows corrupted something as I restored the user's folder prior to going into the temp profile and it worked fine. Not to worry, I'll just disable temporary logon accounts via GPO so it can't happen again.) Many thanks .
-

ParityDuplication FAQ - Parity and Duplication and DrivePool
Shane posted a question in Nuts & Bolts
The topic of adding RAID-style parity to DrivePool was raised several times on the old forum. I've posted this FAQ because (1) this is a new forum and (2) a new user asked about adding folder-level parity, which - to mangle a phrase - is the same fish but a different kettle. Since folks have varying levels of familiarity with parity I'm going to divide this post into three sections: (1) how parity works and the difference between parity and duplication, (2) the difference between drive-level and folder-level parity, (3) the TLDR conclusion for parity in DrivePool. I intend to update the post if anything changes or needs clarification (or if someone points out any mistakes I've made). Disclaimer: I do not work for Covecube/Stablebit. These are my own comments. You don't know me from Jack. No warranty, express or implied, in this or any other universe. Part 1: how parity works and the difference between parity and duplication Duplication is fast. Every file gets simultaneously written to multiple disks, so as long as all of those disks don't die the file is still there, and by splitting reads amongst the copies you can load files faster. But to fully protect against a given number of disks dying, you need that many times number of disks. That doesn't just add up fast, it multiplies fast. Parity relies on the ability to generate one or more "blocks" of a series of reversible checksums equal to the size of the largest protected "block" of content. If you want to protect three disks, each parity block requires its own disk as big as the biggest of those three disks. For every N parity blocks you have, any N data blocks can be recovered if they are corrupted or destroyed. Have twelve data disks and want to be protected against any two of them dying simultaneously? You'll only need two parity disks. Sounds great, right? Right. But there are tradeoffs. Whenever the content of any data block is altered, the corresponding checksums must be recalculated within the parity block, and if the content of any data block is corrupted or lost, the corresponding checksums must be combined with the remaining data blocks to rebuild the data. While duplication requires more disks, parity requires more time. In a xN duplication system, you xN your disks, for each file it simultaneously writes the same data to N disks, but so long as p<=N disks die, where 'p' depends on which disks died, you replace the bad disk(s) and keep going - all of your data is immediately available. The drawback is the geometric increase in required disks and the risk of the wrong N disks dying simultaneously (e.g. if you have x2 duplication, if two disks die simultaneously and one happens to be a disk that was storing duplicates of the first disk's files, those are gone for good). In a +N parity system, you add +N disks, for each file it writes the data to one disk and calculates the parity checksums which it then writes to N disks, but if any N disks die, you replace the bad disk(s) and wait while the computer recalculates and rebuilds the lost data - some of your data might still be available, but no data can be changed until it's finished (because parity needs to use the data on the good disks for its calculations). (sidenote: "snapshot"-style parity systems attempt to reduce the time cost by risking a reduction in the amount of recoverable data; the more dynamic your content, the more you risk not being able to recover) Part 2: the difference between drive-level and folder-level parity Drive-level parity, aside from the math and the effort of writing the software, can be straightforward enough for the end user: you dedicate N drives to parity that are as big as the biggest drive in your data array. If this sounds good to you, some folks (e.g. fellow forum moderator Saitoh183) use DrivePool and the FlexRAID parity module together for this sort of thing. It apparently works very well. (I'll note here that drive-level parity has two major implementation methods: striped and dedicated. In the dedicated method described above, parity and content are on separate disks, with the advantages of simplicity and readability and the disadvantage of increased wear on the parity disks and the risk that entails. In the striped method, each disk in the array contains both data and parity blocks; this spreads the wear evenly across all disks but makes the disks unreadable on other systems that don't have compatible parity software installed. There are ways to hybridise the two, but it's even more time and effort). Folder-level parity is... more complicated. Your parity block has to be as big as the biggest folder in your data array. Move a file into that folder, and your folder is now bigger than your parity block - oops. This is a solvable problem, but 'solvable' does not mean 'easy', sort of how building a skyscraper is not the same as building a two-storey home. For what it's worth, FlexRAID's parity module is (at the time of my writing this post) $39.95 and that's drive-level parity. Conclusion: the TLDR for parity in DrivePool As I see it, DrivePool's "architectural imperative" is "elegant, friendly, reliable". This means not saddling the end-user with technical details or vast arrays of options. You pop in disks, tell the pool, done; a disk dies, swap it for a new one, tell the pool, done; a dead disk doesn't bring everything to a halt and size doesn't matter, done. My impression (again, I don't speak for Covecube/Stablebit) is that parity appears to be in the category of "it would be nice to have for some users but practically it'd be a whole new subsystem, so unless a rabbit gets pulled out of a hat we're not going to see it any time soon and it might end up as a separate product even then (so that folks who just want pooling don't have to pay twice+ as much)". -
So I recently updated my HTPC drivepool from 2x 320GB, 1x 1TB, and 1x 3TB hard drives by swapping the 320's and 1TB for 3x 3TB's. Decided to enable duplication for some sanity checking (would hate to have to redownload everything) and everything went smoothly. Old drives were removed from the pool quickly enough, new drives added, everything is duplicated and working fine. But I've noticed that DrivePool seems to be filling the original 3TB more than the other drives, instead of an equal distribution of files as I would except. So, is this correct? I haven't changed any default balancing or duplication settings yet, and the Volume Equalization plug-in has second priority, right after the stablebit scanner. Am I wrong or will the first drive get priority and fill before the others?
-
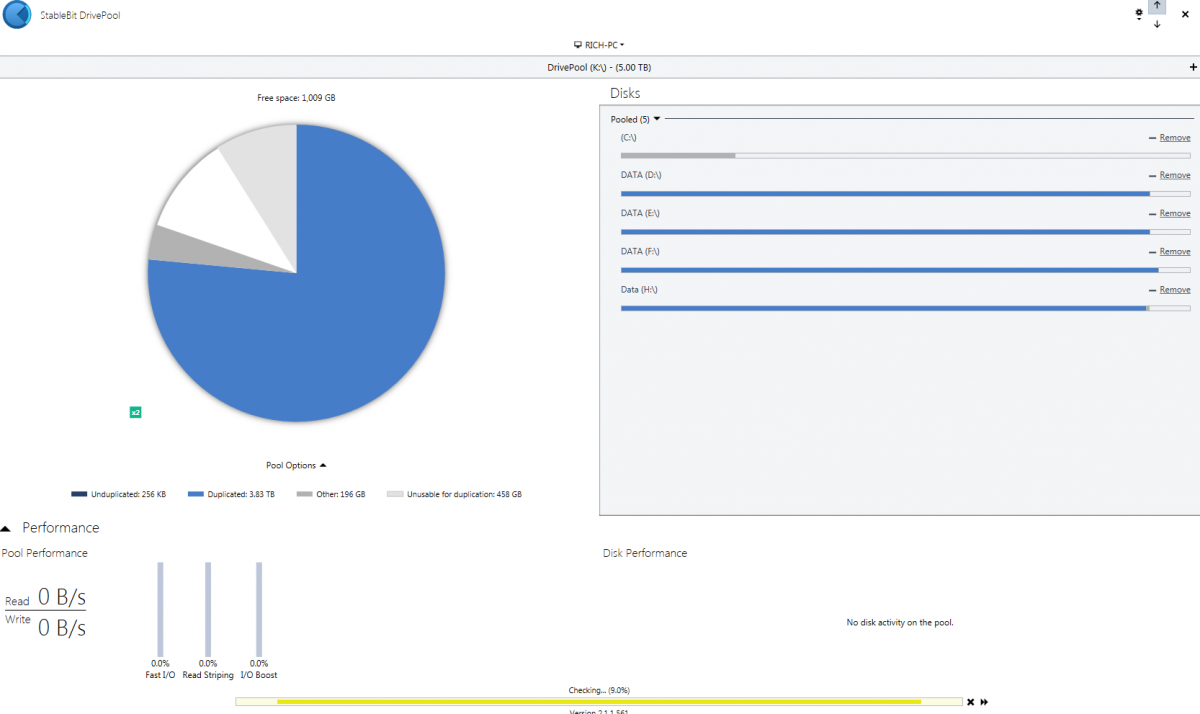
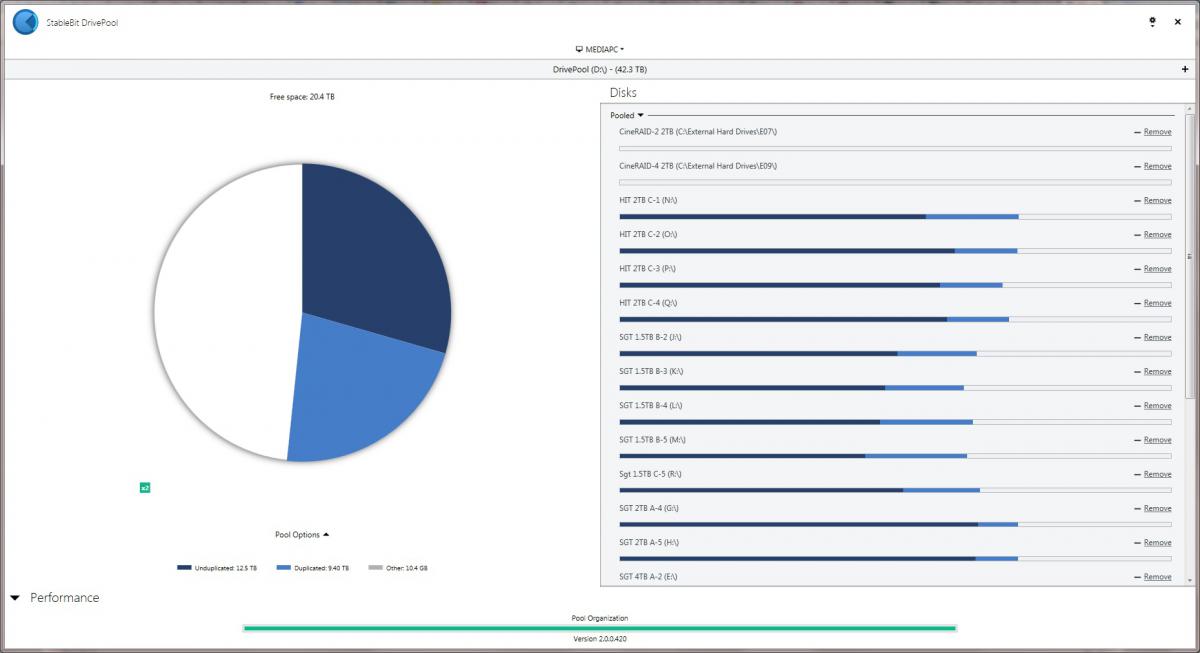
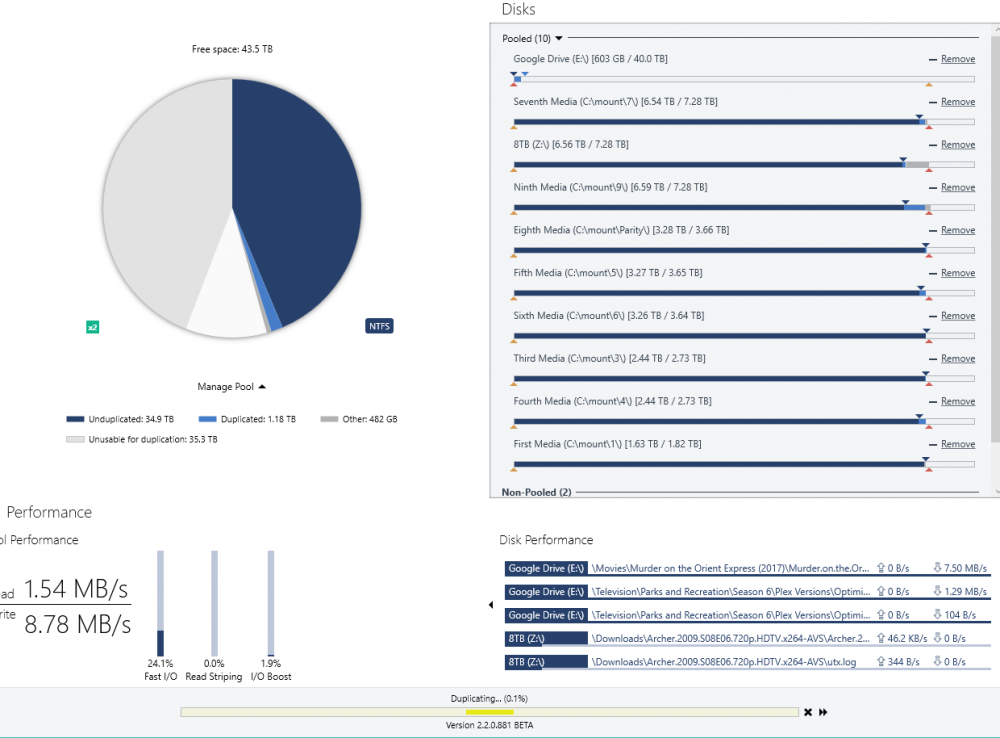
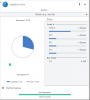
DrivePool quit duplicating even though there is plenty of space remaining. I have 20 drives comprising a 42.3 TB pool. I have approximately 17 TB of data stored on the pool. Per the attached snapshot of the interface, there are 9.40 TB of duplicated and 12.5 TB unduplicated (and 10.4 GB of Other), even though duplication for the entire pool is selected. I started the duplication process by first going folder by folder, but it quit duplicating with less than half duplicated. I then turned on duplication for the entire pool to see if that would restart the duplicating, but no luck. I have tried manually reinstalling DrivePool following the procedure in Q3017479, but no change. When I ask it to Re-measure, it first goes through the "Checking" process, and then it starts the "Duplicating" process. In this "Duplicating" process, it starts from zero and goes by tenths of a percent all the way to 100% over a period of about 15 minutes, but the amounts shown as duplicated does not change. I have tried everything I could think of, short of reinstalling the OS. Please help!!

-
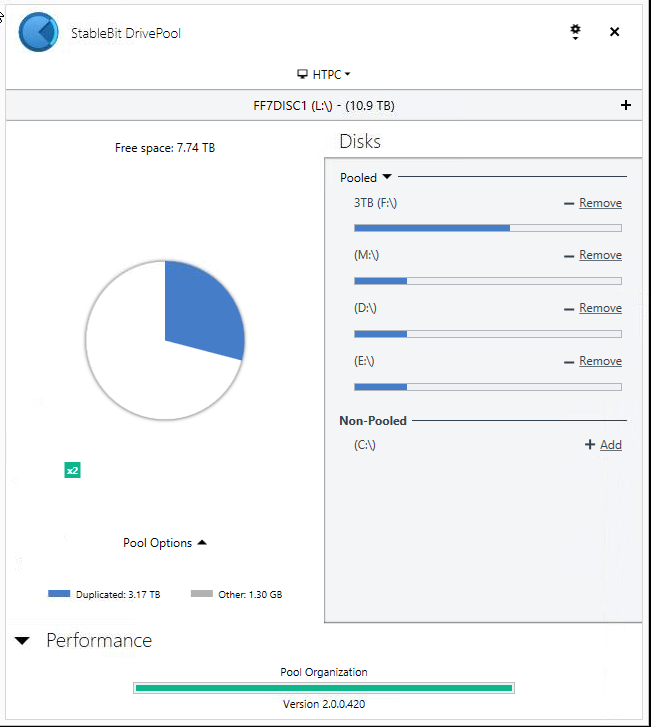
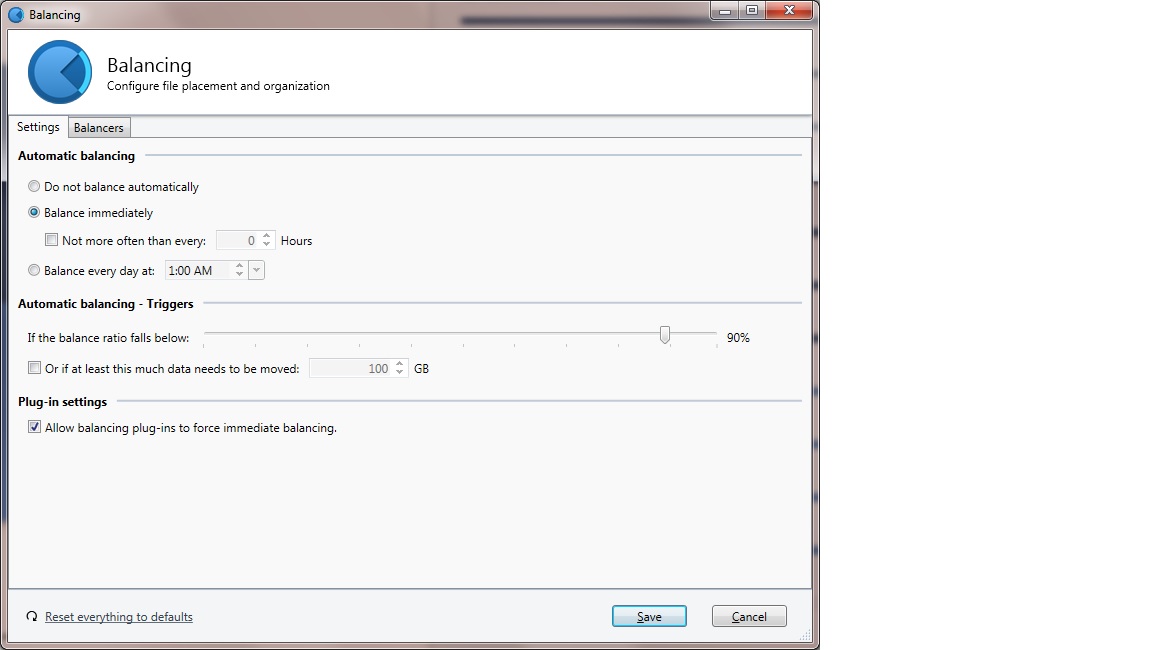
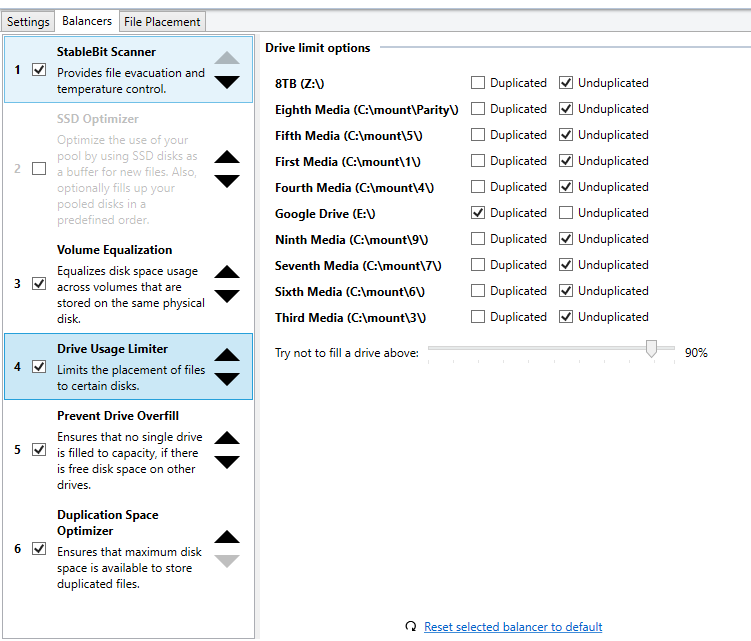
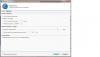
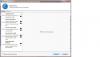
 I set balancing options to exclude my 3rd pool disk "G:" from duplicated files. But duplicated files are still placed on G:. See attached. I have rebalanced and re-measured but there was no change. I would like to keep this disk from storing duplicated files. I am using release 2.0.0.420. Thanks! Duplic exclusion not working.pdf
I set balancing options to exclude my 3rd pool disk "G:" from duplicated files. But duplicated files are still placed on G:. See attached. I have rebalanced and re-measured but there was no change. I would like to keep this disk from storing duplicated files. I am using release 2.0.0.420. Thanks! Duplic exclusion not working.pdf