Search the Community
Showing results for tags 'DrivePool'.
-
Hello - I have tried searching the forums a bit and I did find this helpful post - But I was hoping for some clarification before I start work on my pools. 1. Since DrivePool uses UNC, are MaxPath restrictions not an issue if programs are accessing the pool drive directly AND if the pool drive's file length is under the maxpath length limit (256 characters)? By that, I mean - the PoolPart path length is around 45 characters, so if I have a file within the PoolPart folder that has a path length of 280, then it's over the maxpath limit. But, roughly 45 characters of that is due to the PoolPart foldername. DrivePool has no problems moving it around etc because DP is written using UNC. Within the pooled drive however, that same file will have a path length of roughly 235 (280-45). Does this mean that as long as I only access the files via the pooled drive, there will be no issues with Win32 API from programs that don't support UNC? 2. If the answer to #1 is yes, if I need to evacuate a drive from the pool and use the data somewhere else, can I use robocopy or another UNC compatible program to copy the data OUT of the PoolPart folder? The issue I have is that, like Drashna mentions in his post above, I'm meticulous with my folder and filenaming, but I'm trying in general to stay under the 256 limit and not regedit the maxpath restriction away. So I'm planning path lengths in a pool that will be in the 240s/250s, which will go over the limit in the PooPart folders, but still be copacetic in theory in the actual pooled drive itself. Sorry if I'm overcomplicating things and thanks Christopher/Drashna and the CoveCube team for all of your work on this amazing product.
-
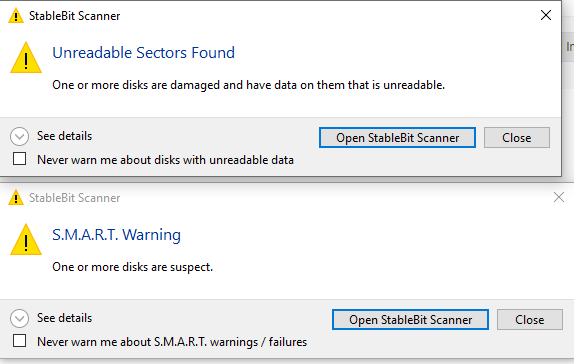
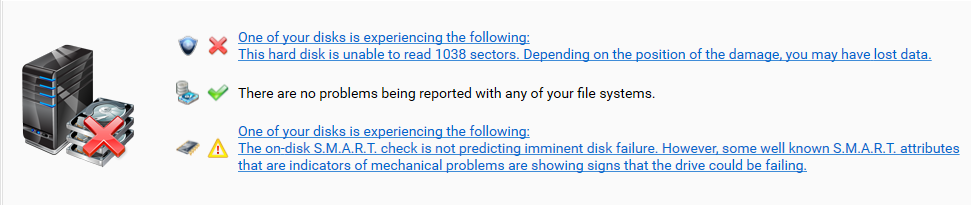
Hello all, So i will try to summarize as much as i can. I run my drivepool on WD RED drives, about 5 of them, i had 1 fail on me in the past and now a 2nd seems to have done the same. Im not sure why they are failing so much, i thought they were the best but the desktop pc i have them all cramped in is probably not the best place for and i dont have the vibration absorbing screws or anything special so maybe thats why. Is his failure message a result of drivepool and the drives are actually not damaged ? i will post a screen shot, my drives show lots of space, but 1 drive is completely empty !!! I thought it was not balancing the drives correctly, but im guessing due to the HDD failure message drivepool evacuated all data from that bad disk ? now i have no space to even download a file, not sure what to do. I also have things in my drivepool that i dont have to be duplicated to save space on pool, can i manually disable duplication on certain folders without effecting anything else ? Please advise Thank you all. (Side note this drivepool houses ONLY my PLEX media collection and is used for nothing else)
-
I have reached the limit of installable drives: I am pretty sure you know this situation My motherboard can handle 6 drives and I installed one SSD and five WD Reds. Due to the fact that my data appetite is still vast, I have to buy me my first storage controller I already read a lot of threads and reviews and decided to invest my money into a controller with a LSI chipset. By the way, I just need a "simple" storage controller, no RAID or other fancy functions are needed. I am fine in investing some extra money in the newest chipset generation, because I want to use the controller for a lot of years So far so good, I am completely new to SAS, HBA, JBOD etc., therefore I need an expert advice. I already figured out two potential storage controllers: [1] Intel RAID Controller RS3WC080 | Specs > http://ark.intel.com/products/77345/ [sorry cannot link them] [2] Intel RAID Controller RS3UC080 | Specs > http://ark.intel.com/products/76066/ [sorry cannot link them] As far as I understood I have to look for a storage controller with JBOD mode, because I do not need the RAID functions and simply want to attach new drives. Am I right that [2] is the right decision for my setup? Are there any issues/problems I might face in installing the storage controller? Do I you have to take something into account when I add the new drive into my (lovely) pool? Thanks so much for your help and patience!
-
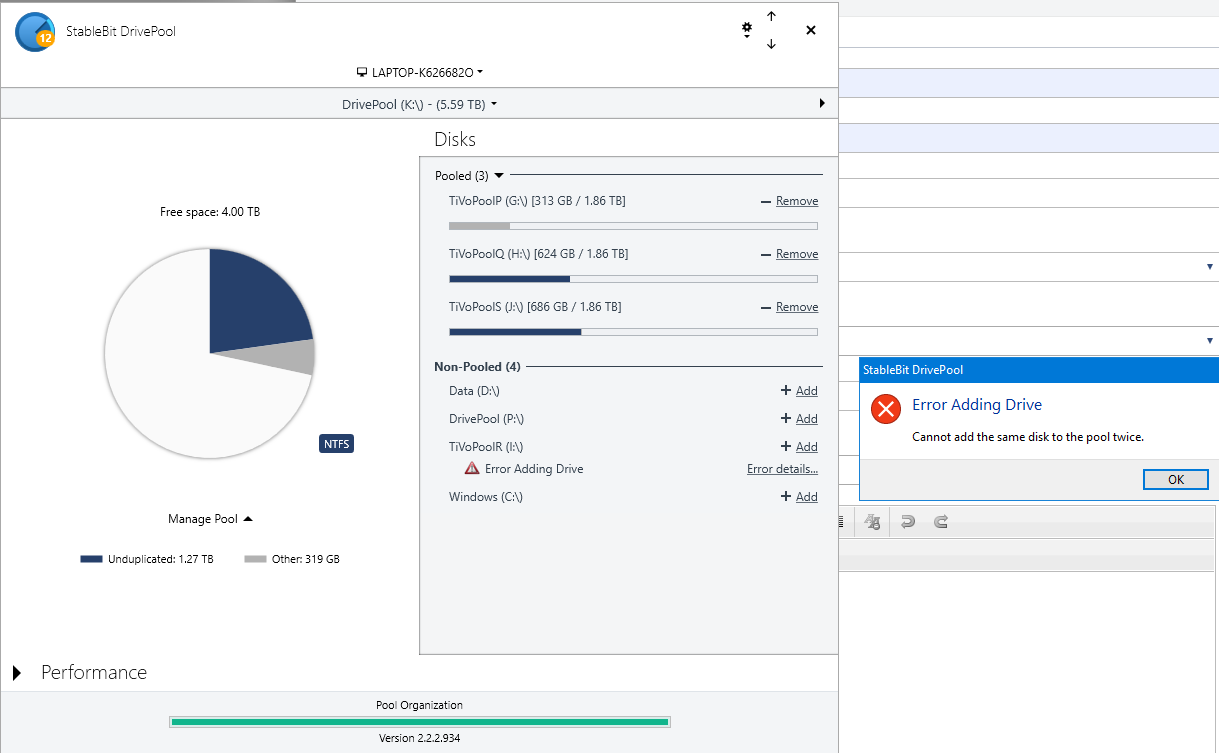
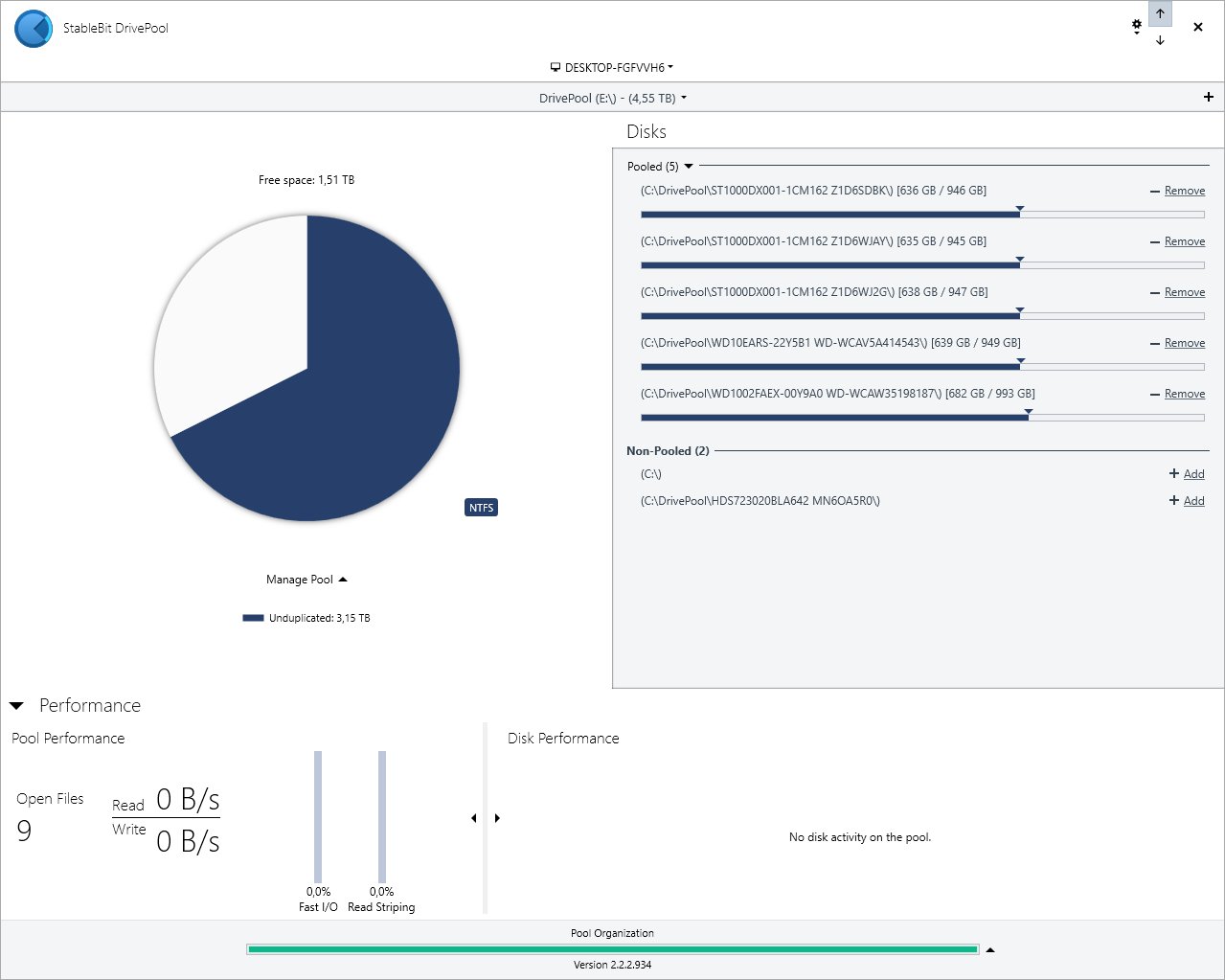
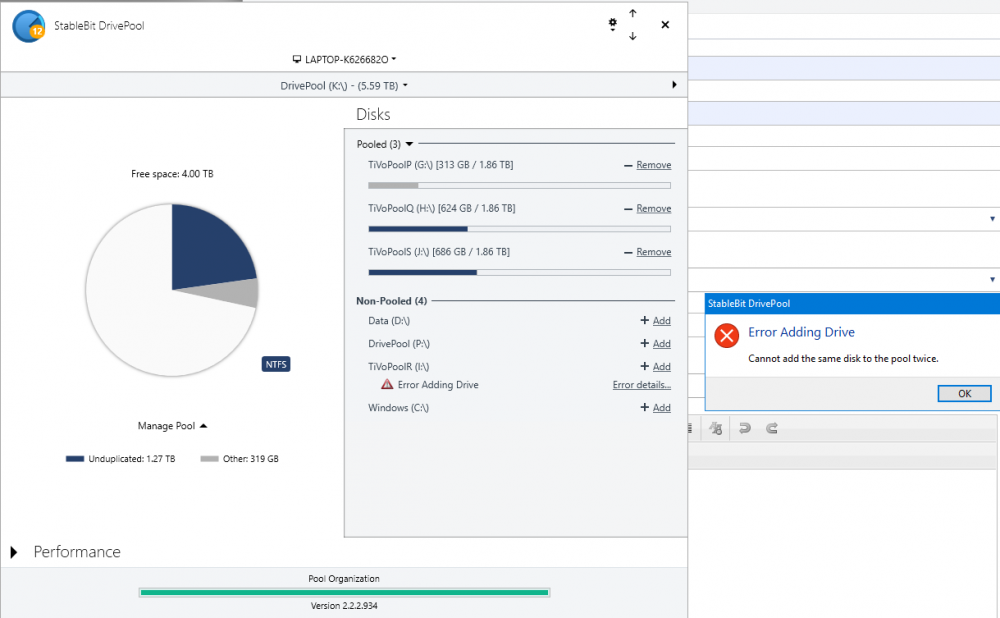
version 2.2.2.934 DP Error: "Error Adding Drive: cannot add the same disk to the pool twice" Hello, Need help resolving this error so that the disk with drive letter "I:" (as shown by the attached screenshot) may be returned to the pool. The error occurs when clicking the "+ Add" 'link'. Drive "I:" had stopped being recognized by DP after the system came out of sleep. Thank You
-
HI Folks: I am running drivepool and scanner - one of the drives dropped out of the pool according to Drivepool, but I got no notification from either Drivepool or Scanner that there was a problem although notifications were set up. I removed the drive from the pool under drivepool and checked it under disk management (Windows 10) - it seesm to want to be reinitialized? attempted this as it should be a mostly emplty drive, but get an error saying there is an I/O error and cant initialize it. Is this a drivepool / scanner issue or more likely a mother board issue? Anny assistance / comments would be appreciated - especially wondering why I got no notification from Drive Pool that the drive was missing (although it indicated it was) … until I removed it from the pool. It then shortly thereafter said it was not missing - but the drive was requiring initialization - which can't seem to be accomplished? Regards, Dave Melnyk
-
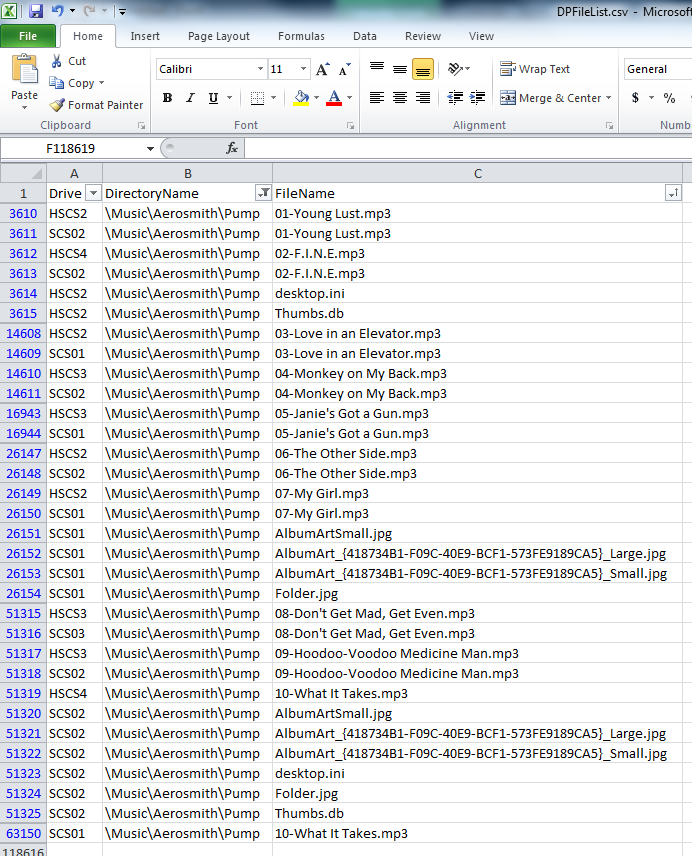
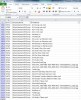
I've been seeing quite a few requests about knowing which files are on which drives in case of needing a recovery for unduplicated files. I know the dpcmd.exe has some functionality for listing all files and their locations, but I wanted something that I could "tweak" a little better to my needs, so I created a PowerShell script to get me exactly what I need. I decided on PowerShell, as it allows me to do just about ANYTHING I can imagine, given enough logic. Feel free to use this, or let me know if it would be more helpful "tweaked" a different way... Prerequisites: You gotta know PowerShell (or be interested in learning a little bit of it, anyway) All of your DrivePool drives need to be mounted as a path (I chose to mount all drives as C:\DrivePool\{disk name}) Details on how to mount your drives to folders can be found here: http://wiki.covecube.com/StableBit_DrivePool_Q4822624 Your computer must be able to run PowerShell scripts (I set my execution policy to 'RemoteSigned') I have this PowerShell script set to run each day at 3am, and it generates a .csv file that I can use to sort/filter all of the results. Need to know what files were on drive A? Done. Need to know which drives are holding all of the files in your Movies folder? Done. Your imagination is the limit. Here is a screenshot of the .CSV file it generates, showing the location of all of the files in a particular directory (as an example): Here is the code I used (it's also attached in the .zip file): # This saves the full listing of files in DrivePool $files = Get-ChildItem -Path C:\DrivePool -Recurse -Force | where {!$_.PsIsContainer} # This creates an empty table to store details of the files $filelist = @() # This goes through each file, and populates the table with the drive name, file name and directory name foreach ($file in $files) { $filelist += New-Object psobject -Property @{Drive=$(($file.DirectoryName).Substring(13,5));FileName=$($file.Name);DirectoryName=$(($file.DirectoryName).Substring(64))} } # This saves the table to a .csv file so it can be opened later on, sorted, filtered, etc. $filelist | Export-CSV F:\DPFileList.csv -NoTypeInformation Let me know if there is interest in this, if you have any questions on how to get this going on your system, or if you'd like any clarification of the above. Hope it helps! -Quinn gj80 has written a further improvement to this script: DPFileList.zip And B00ze has further improved the script (Win7 fixes): DrivePool-Generate-CSV-Log-V1.60.zip
- 50 replies
-
- 2
-

-

-
- powershell
- drivepool
- (and 3 more)
-
I went to open Calibre and an error message popped up and said that the calibre library location isn't available. I then noticed that there was no drivepool. I opened Stablebit drivepool and noticed that one disk went bad, but instead of having all of my other 7 disks I don't even have a drivepool. The Stablebit DRivepool program was asking me to start a new drivepool, which should not have happened. I decided to just begin another drivepool, but as I added the disks to the drivepool, none of the folders and files were being shown. The disks look like they were all wiped clean. Windows Disk management reflects the same thing. I would like to recreate my drivepool, but I guess the pool configuration information cannot be located or indexed. Is this fixable? The disks only show a poolpart file and nothing else. I have a very good hard drive restore program, should I just scan each disk and try to recover all of my files. This looks like a nightmare at this point. I did notice that when I discovered I no longer had my files I did notice that the stablebit service was not running. I re-started the service, which still resulted in not being able to see any of my files or folders.
-
Hello, I had asked this question in the cloud drive forum... the short version is, can you pool two machines together? and it was suggested to try my luck here instead. I'm sure the answer is "no", but can I pool two different machines together into one pool? I know I can do this: create pool --> place pool in virtual cloud drive --> place cloud drive into pool on second machine because I did exactly that. However, if I have existing data on the pool, that does not get reflected in the cloud, it can only use the empty space to create the virtual drive. If it is possible to see the existing data in a pool in a cloud drive, I'd be interested in knowing how to do that. Thanks, TD
-
Hello, I have had Drivepool for about a year now and have just installed a second copy on another physical machine. Each machine has ~12TB of data on it. is it possible to use CloudDrive to put the two pools together if data already exists on each? I am thinking of creating a 1TB cloud on machine ONE, pointing it to a Windows share on machine TWO. Then, I want to add the CloudDrive to to the pool on machine ONE... will that show me the existing data from TWO in the pool on ONE? Can the clouddrive be smaller than the data on TWO? Thanks for any help you can provide! TD
-
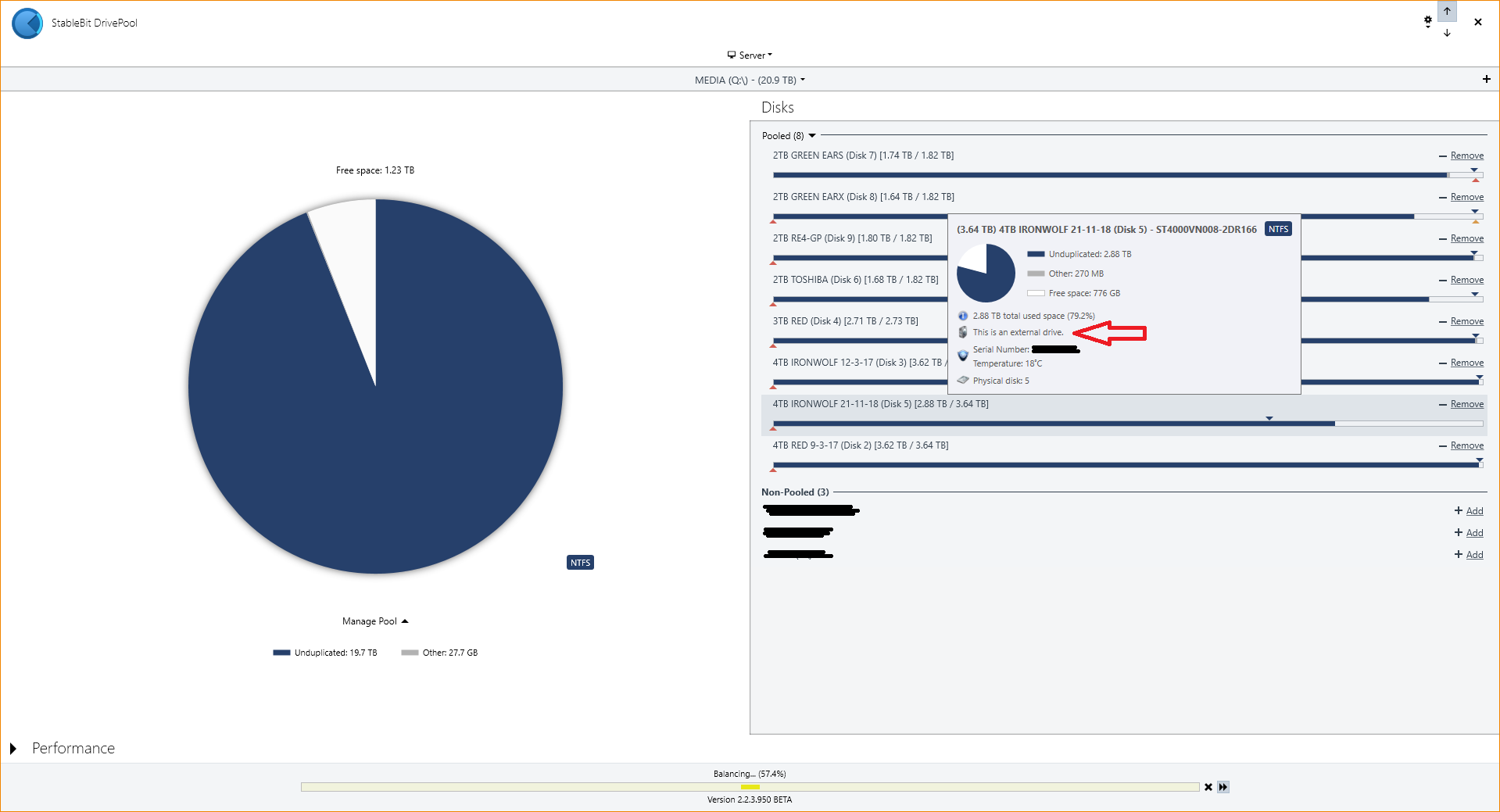
hi! i've got the package, so i get the more details in Drivepool when highlighting a drive. the latest drive i added, it started in my USB3 dock whilst i set it up [do the checks before adding in to the pool] and its now in the server on SATA connection. but it still says "this is an external drive" as per the attached image. is there any way to correct this? regard,
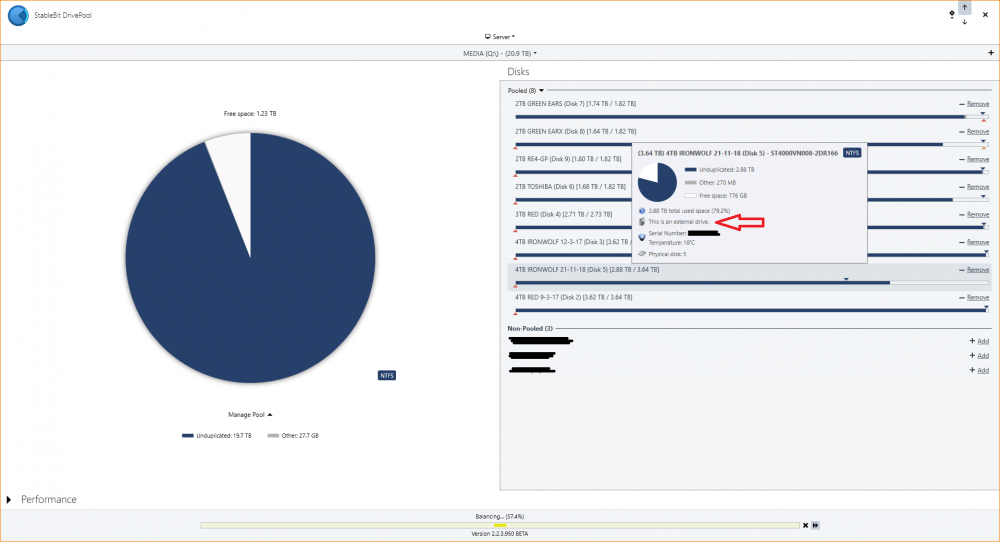
-
Hi, I've got a drive in my pool that Scanner is reporting that the File system is not healthy, and repairs have been unsuccessful. So I added another drive the same size to the pool, and attempted to remove the damaged drive (thinking this would migrate the data, after which I can reformat the original drive and re-add to the pool). I'm getting "Error Removing Drive" though, and the detail info indicates "The file or directory is corrupted and unreadable". Yet I can reach into the PoolPart folder and can copy at least some* of the files (every test I've done copies fine). How do I migrate whatever I can recover manually? Or is there a step I'm missing to get DP to do this for me automatically?
-
Removing a pool apparently causes my server to reboots, thus i have to repeat the removal process.. I'm positive cause it happens third time already, I have checked all 3 options on remove menu, but it still reboots my PC, so what should i do? I also tried searching and deleting files inside the pool but it wont help, the drive currently looks like this, this is after the reboot I have also unmark the both options in drive usage limiter plugin after i post this but i havent tried removing again
-
Hello everyone! I plan to integrate DrivePool with SnapRAID and CloudDrive and require your assistance regarding the setup itself. My end goal is to pool all data drives together under one drive letter for ease of use as a network share and also have it protected from failures both locally (SnapRAID) and in the cloud (CloudDrive) I have the following disks: - D1 3TB, D: drive (data) - D2 3TB, E: drive (data) - D3 3TB, F: drive (data) - D4 3TB, G: drive (data) - D5 5TB, H: drive (parity) Action plan: - create LocalPool X: in DrivePool with the four data drives (D-G) - configure SnapRAID with disks D-G as data drives and disk H: as parity - do an initial sync and scrub in SnapRAID - use Task Scheduler (Windows Server 2016) to perform daily synchs (SnapRAID.exe sync) and weekly scrubs (SnapRAID.exe -p 25 -o 7 scrub) - create CloudPool Y: in CloudDrive, 30-50GB local cache on an SSD to be used with G Suite - create HybridPool Z: in DrivePool and add X: and Y: - create the network share to hit X: Is my thought process correct in terms of protecting my data in the event of a disk failure (I will also use Scanner for disk monitoring) or disks going bad? Please let me know if I need to improve the above setup or if there is soemthing that I am doing wrong. Looking forward to your feedback and thank you very much for your assistance!
-
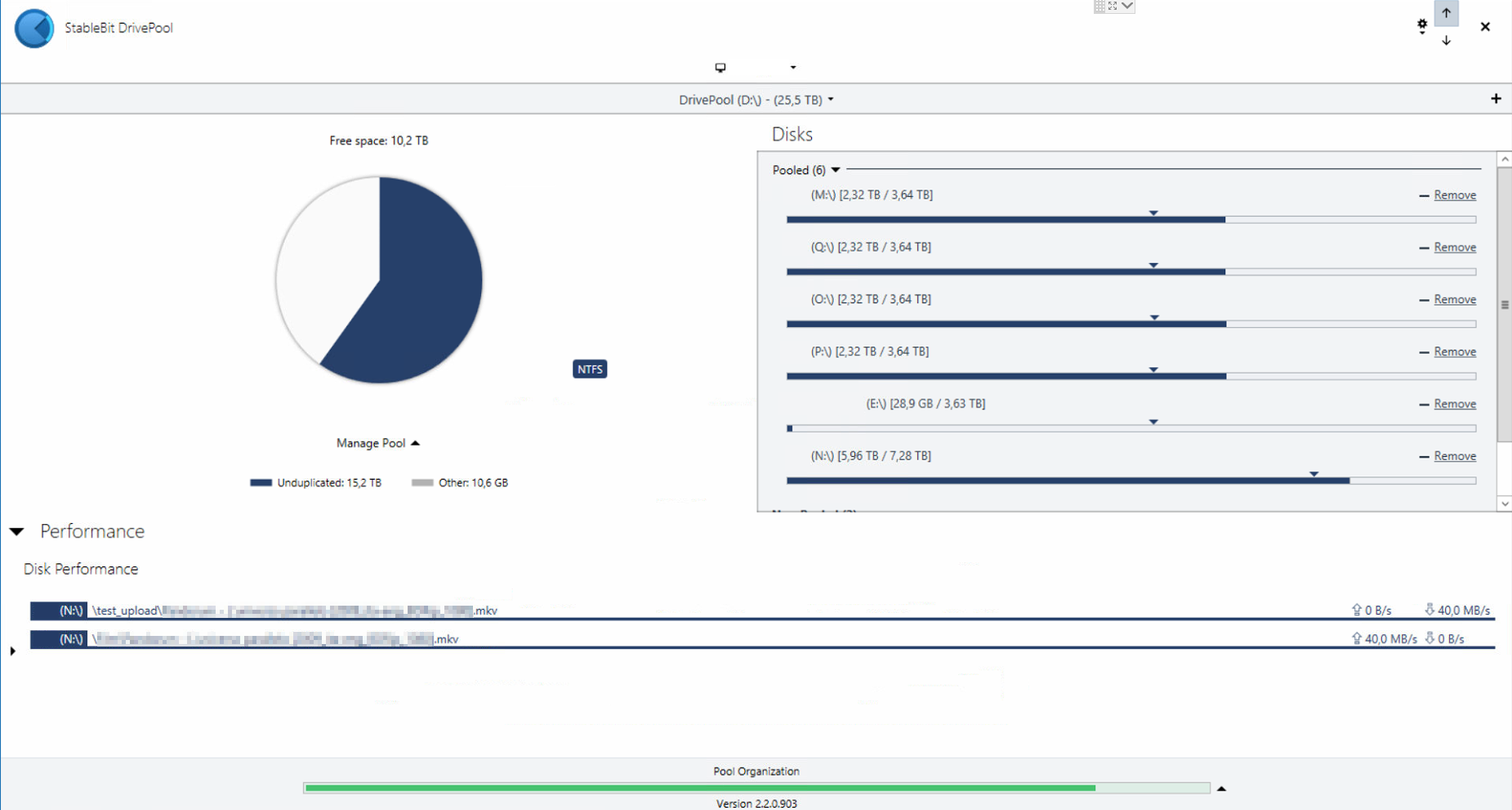
 Hello. I ihink that I might have encountered a bug in DrivePool behavior when using torrent. Here shown on 5x1TB pool. When on disk (that is a part of Pool) is created a new file that reserve X amount of space in MFT but does not preallocate it, DrivePool adds that X amount of space to total space avaliable on this disk. DrivePool is reporting correct HDD capacity (931GB) but wrong volume (larger than possible on particular HDD). To be clear, that file is not created "outside" of pool and then moved onto it, it is created on virtual disk (in my case E:\Torrent\... ) on that HDD where DrivePool decide to put it. Reported capacity goes back to normal after deleting that file:
Hello. I ihink that I might have encountered a bug in DrivePool behavior when using torrent. Here shown on 5x1TB pool. When on disk (that is a part of Pool) is created a new file that reserve X amount of space in MFT but does not preallocate it, DrivePool adds that X amount of space to total space avaliable on this disk. DrivePool is reporting correct HDD capacity (931GB) but wrong volume (larger than possible on particular HDD). To be clear, that file is not created "outside" of pool and then moved onto it, it is created on virtual disk (in my case E:\Torrent\... ) on that HDD where DrivePool decide to put it. Reported capacity goes back to normal after deleting that file: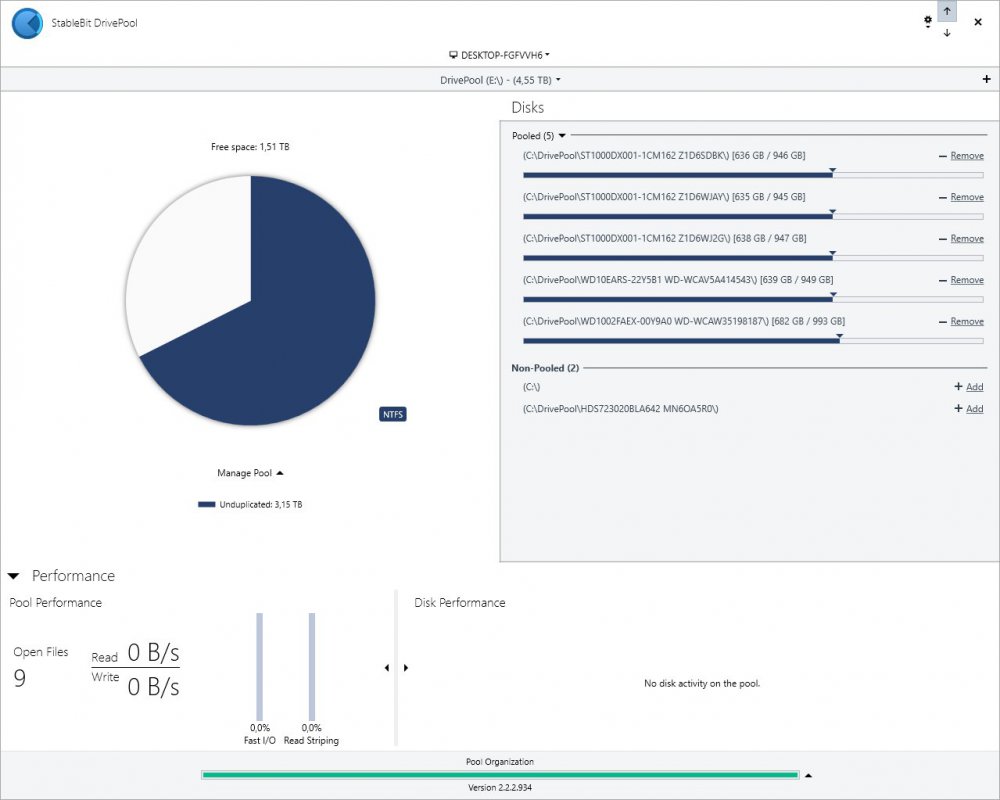



-
Hi, I decided to give Drivepool a try, see how I like it, and almost immediately after installing and setting up a trial activation, and fixing an issue I had with my bios settings, I get a notification saying I must activate to continue. All it says is "Get a trial license or enter your retail license code" and "Get a license", with all other UI blocked. Clicking Get a license shows me a screen with "Your trial license expires in 29.7 days" and asks for an Activation ID. I tried uninstalling and reinstalling, and same thing. Uninstalling failed to remove the pooled drive, so I'm not really sure what's going on there.
-
I have a bunch of older 3, 4 and 6TB drives that aren't currently in my main system that i want to make use of. What are some suggested options to externally adding these to a drive pool? I saw this in one post IB-3680SU3 and have seen something like this before as well Mediasonic H82-SU3S2 is there anything i should be aware of to make this work optimally? I'll also have a few drives in my main system that would be part of the pool as well.
-
I recently added 2 8TB HHDs to my das that had a 5TB and 8TB drive already in it. I've used DrivePool on another machine but not this one. I added all 4 HHDs to a new pool and moved the old data to the hidden "PoolPart" folders. The problem now is that the balancer won't pick up those "other" files and redistribute them amongst the new drives. How can I get this is data to be apart of the new pool?
-
Hi, I am posting here to see if anyone has any similar experiences when trying to upload data to GDrive via Cloud Drive using a similar setup. First, I have two hard drives connected, which are used as my cache disks. Not sure if the size matters, but one is 1 TB and the other is 1.5 TB. They were created about 1 year ago using the default allocation sizes, so the maximum each cloud drive can be is 32 TB each. I also use DrivePool to pool the Cloud Drives created on GDrive into one combined 64 TB drive. This is on an I5 2600k 3.6 Ghz with 16 GB ram on a Windows 10 Home OS. I have been having trouble recently while trying to upload from the local disks in that it seems that the PC needs to have the user logged in and active in order to upload anything. This isn't ideal because while I have a "decent" connection at 1 Gbps down, I only have 50 Mbps upload. I can usually achieve close to 50 Mbps during non-peak times, but throughout the day / busy hours, I usually max out around 30 - 35 Mbps. For this reason (and others), I typically try to let any data upload overnight while I'm sleeping. However, recently as in the last 3 to 4 weeks or so, I've noticed that even though my connection appears to be uploading throughout the night, the "To Upload" figure remains pretty close to what it was prior to going to sleep. For example, last night it said I had 199 GB left to upload to the cloud. I left my computer unattended uploading for 12+ hours (combined sleep and running errands throughout today) and when I checked just now, it says there is 184 GB left to upload. It seems kind of odd that I would have only uploaded around 15 GB in over 12 hours. My connection was steady throughout the night and no errors reported by Cloud Drive. Something may be related is that prior to going to sleep, I had cleared cache on the drive and the "To Upload" data (199 GB) and "Local" data (201 GB) were very close, around 2 GB difference. Upon returning to my computer, as mentioned the to upload was 184 GB, but my local was now at 534 GB. It almost seems as if the difference between 534 GB and 201 GB is what my connection should have uploaded during the 12 hrs, but for some reason it did not happen. This is not the first time something like this has happened either, it seems much more prevalent over the last several weeks, but I am not 100% sure when this behavior started. At first, I thought I was doing something wrong somehow, which still might be true. However, I think I found the pattern of this potential issue. It seems that when I "lock" my computer and am away from it, the issue described where my connection uploads, but doesn't actually upload much data will occur. It seems like this issue does NOT occur if I log on to the PC and just leave it unlocked and "active". I am doing a test now to see if this is true. To be clear, I am NOT logging the user out of Windows prior to letting it try to upload. I am simply locking the computer so it prompts for a password when someone tries to use it. I am also aware of the 750 GB max upload to GDrive per 24 hours. I don't think my upload speed is fast enough for that to come into play, but I have also tried waiting a few days by pausing the upload and the same thing would happen. Has anyone experienced anything remotely similar to this? If so, is there anything that can be done? I don't understand why it would upload while I am active on the PC, but not upload while its locked. Thanks for taking the time to read this.
-
Sorry about the n00bness of this question but I'm not a Windows Server setup expert and any help/guidance would be much appreciated. I've got a new Microserver :16Gb, 4 core, 512MB SSD (OS) and 2x10TB NAS drives. I was hoping to set this up as Windows Server 2016 (with desktop experience) to act as a file server for a Linux based Kodi box. I've got various other Windows machines which would looking to access Shares on the server. Once 3-6 months has gone by, hopefully Disk prices have fallen a bit I was planning on getting a third disk and hooking up Snap RAID. I'm looking to run HyperV so that I can fire up VMs to use my MSDN sub to set up some test labs for work/community stuff. As well as using the improved docker support to dig into Containers. I was hoping to avoid having to set the box up as a DC or does DrivePool require "Server Essentials Experience" to be enabled? Or would I be better going with Win 10 Pro and just turn everything off. Finally is ReFS still proving problematic, and SnapRAID covers that anyway?
-
So I'm a bit confused with the HybridPool concept. I have a LocalPool with about 6 hard drives totalling 30TB. I have about 25TB populated and with this new hybrid concept I'm trying to know if I can use another pool (cloudpool) for duplication. The part that I'm a litte confused is when I create a hybridpool with my cloudpool and my localpool I have to add all my 25TB of data on the new Hybridpool drive. On the localpool all my data appear in the "Other" section. I really have to transfer all the data from the localpool to the hybridpool, or am I missing something? Thanks
-
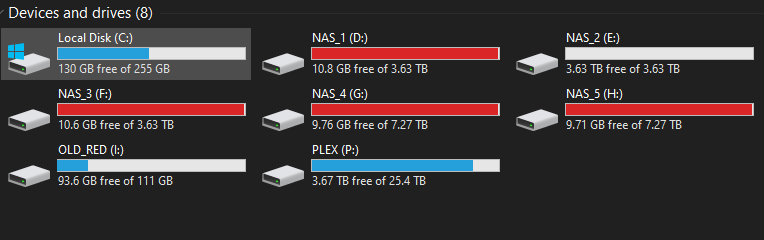
Suddenly I cannot write to my pool. I can write to individual drives, and can create folders, etc. but any copy says there is zero space, even though there is plenty. I have installed the latest Drivepool, restarted, and tried a number of usual tricks. Halp!
-
Hi, referring to this post and how DrivePool acts with different size drives, I found myself copy/pasting a file and DrivePool used the same drive for the entire operation (as the source and the destination). This resulted in a really poor performance (see attachments; just ignore drive "E:", there are some rules that exclude it from the general operations). Same thing extracting some .rar files. Is there a way to make DP privilege performance over "available space" rules? I mean, if there is available space on the other drives it can use the other drives instead of the "source" one. Thanks
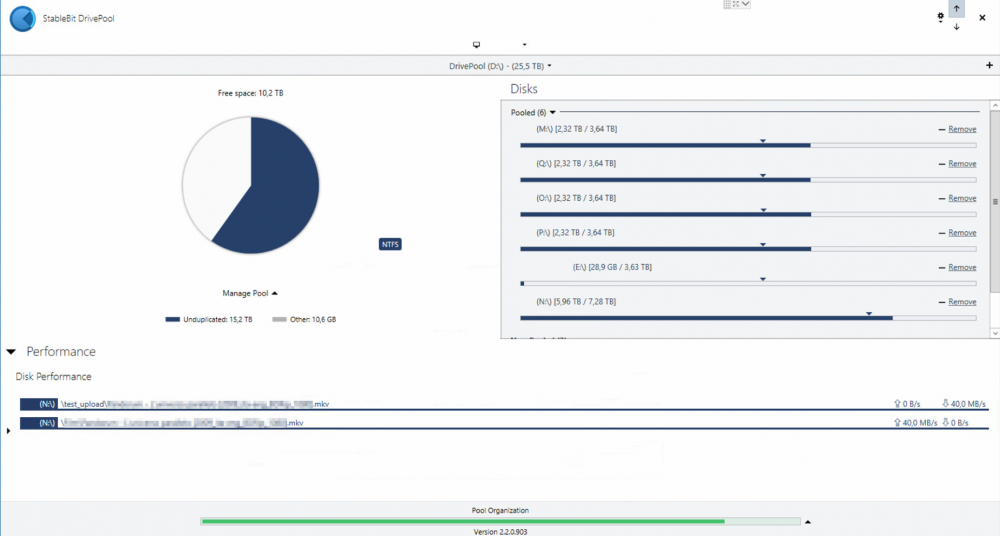
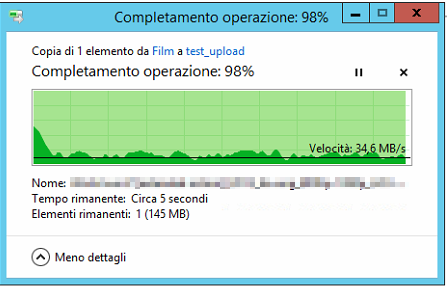
-
I'm designing a replacement for my current server. Goals are modest. Less heat and power draw than my existing server. Roles are file server with drivepool, emby for media with very light encoding needs. Local backups are with Macroum Reflect. Off site backups with Spideroak. OS will be win 10 Pro. My current rig is here: New build: PCPartPicker part list: https://pcpartpicker.com/list/yhdVqk Price breakdown by merchant: https://pcpartpicker.com/list/yhdVqk/by_merchant/ Memory: Crucial - 8GB (2 x 4GB) DDR3-1600 Memory ($63.17 @ Amazon) Case: Fractal Design - Node 304 Mini ITX Tower Case ($106.72 @ Newegg) Power Supply: EVGA - B3 450W 80+ Bronze Certified Fully-Modular ATX Power Supply ($53.73 @ Amazon) Operating System: Microsoft - Windows 10 Pro OEM 64-bit ($139.99 @ Other World Computing) Other: ASRock Motherboard & CPU Combo Motherboards J3455B-ITX ($73.93 @ Newegg) Total: $437.54 Prices include shipping, taxes, and discounts when available Generated by PCPartPicker 2018-01-16 10:30 EST-0500 Storage: LSI SAS 2 port HBA flashed to IT mode. Boot: PNY 120GB SSD Data Pool: 4 x 2TB WD Red Backup Pool: 1x5TB Seagate (Shelled USB drive) When this is built my old rig goes up for sale. My only thought is on the CPU. Could I go with a dual core Celeron for about 80 bucks? Will it handle a single encoding stream and not draw more power than the i3T? The Celeron will do fine as a file server.
-
I have two networks, one which is connected to the internet (1), and one which is not (2). I have a machine (A) running drivepool and scanner on (2), and a machine (B) connected to both (1) and (2). Machine (B) is set up to remote monitor (A). Will any notifications generated on (A), which is being remote monitored by (B), be sent from machine (B) to my email? When sending a test message from Scanner on machine (A), since it is not connected to the internet, creates the error "Test email could not be sent to blank@blank.com. Object reference not set to an instance of an object." When sending a test message from Drivepool on machine (A), Drivepool claims to have successfully sent the test email. In both instances, I do not receive an email. When I attempt to send a test message from machine (B), I get the same response and error: Drivepool successful, and scanner "object reference" error, and I do not receive an email for either attempt. Aside from the "object reference" error, should I be able to funnel any notifications through another machine in the way that I am attempting to do it? Drivepool: 2.1.1.561 x64 Scanner: 2.5.1.3062 Thank you.
-
Hi, I have an office 365 account where I get 5 - 1TB onedrives. I am trying to link 3 of them together using clouddrive and drivepool. I have on my pc as storage drives: x4 - Toshiba HDWE160 6TB x1 - Seagate ST3000DM001-9YN166 3TB I have all the drives pooled together using drivepool. When creating the OneDrive drivepool, how should I create the clouddrive cache? Should I put all 3 cache partitions on a single, dedicated, cache disk? Can I put a single cache partition on 3 different drives in the storage drivepool? Or do I need a dedicated cache drive for each of my onedrive cloud connections? What are your recommendations for this? I've tried putting the cache partitions on the same dedicated cache disk and get BSOD every time I write a lot of files to it. Thank you.