Search the Community
Showing results for tags 'drivepool'.
-
I removed a drive the other day. Didn't think much about it. After it was removed I changed the drive name. Everything was fine as far as i knew until today 4/21 when I went looking for a backup of a file I wanted to restore and I couldn't access the pool. I launched Stablebit and it came up with the warning that a disk was missing which I wasn't expecting. When it opened it showed that the one partition I removed was still participating but 6 partitions are missing. I'm not sure what to do at this point.
-
I’m using SnapRAID with Drivepool and recently did a rebalance as I realized I didn't leave enough space % in the "Prevent Drive Overfill" Balancer. Everything seemed to move correctly, and the drives were now balanced as I wanted. I ran the SnapRAID "sync" command and thought I was good to go. A few weeks later, I see that over a hundred files are missing including complete folders. I ran the SnapRAID "diff" command and see 175 removed differences- these are the missing files which are apparently still a part of the parity. What is the best way to restore these files and folders? Does "fix -m" simply solve my problem, or will it attempt to restore directly to the drives the files and folders were previously on? If so, does that cause a conflict with the Drivepool balance settings as I know if those files and folders are restored to the previous drives, it will be over the balance limit. Any help is greatly appreciated!
-
I added 3 new 20tb wd red pros to my pool which brings it to 160tb in total, and after 3 days it's only balanced 2.94tb. At this rate it will take forever. I checked stablebit scanner and the transfer rate is 18mbps. Why is this so slow. I've already tried clicking the arrows and noticed there was absolutely no difference in speed. Is there a setting that can be enabled or something? And another question. Is it possible to stop the current balance if i had to. I'm afraid of it losing data or stopping mid file. I'm open to any suggestions and I wonder if this is somehow a bottle neck in windows with drivepool causing this. Manual file transfer is around 250mbps so I know it's not the controller.
-
I recently had Scanner flag a disk as containing "unreadable" sectors. I went into the UI and ran the file scan utility to identify which files, if any, had been damaged by the 48 bad sectors Scanner had identified. Turns out all 48 sectors were part of the same (1) ~1.5GB video file, which had become corrupted. As Scanner spent the following hours scrubbing all over the platters of this fairly new WD RED spinner in an attempt to recover the data, it dawned on me that my injured file was part of a redundant pool, courtesy of DrivePool. Meaning, a perfectly good copy of the file was sitting 1 disk over. SO... Is Scanner not aware of this file? What is the best way to handle this manually if the file cannot be recovered? Should I manually delete the file and let DrivePool figure out the discrepancy and re-duplicate the file onto a healthy set of sectors on another drive in the pool? Should I overwrite the bad file with the good one??? IN A PERFECT WORLD, I WOULD LOVE TO SEE... Scanner identifies the bad sectors, checks to see if any files were damaged, and presents that information to the user. (currently i was alerted to possible issues, manually started a scan, was told there may be damaged files, manually started a file scan, then I was presented with the list of damaged files). At this point, the user can take action with a list of options which, in one way or another, allow the user to: Flag the sectors-in-question as bad so no future data is written to them (remapped). Automatically (with user authority) create a new copy of the damaged file(s) using a healthy copy found in the same pool. Attempt to recover the damaged file (with a warning that this could be a very lengthy operation) Thanks for your ears and some really great software. Would love to see what the developers and community think about this as I'm sure its been discussed before, but couldn't find anything relevant in the forums.
- 8 replies
-
- 4
-

-
- interoperability
- scanner
- (and 3 more)
-
Hi All, I purchased drivepool about a month ago and I am loving it. I have 44TB pooled up with an SSD cache it works great until yesterday. I downloaded backup and sync to sync my google drive to the pool and it synced the files I needed to the SSD then the SSD moved the data to the archive drives. Then backup and sync gave me an issue that the items are not synced and synced it again. It seems like backup and sync cannot sync to the pool for some reason. Did anyone else have this problem? Is this why we have clouddrive? I am really disappointed as If i knew it wouldn't work I wouldn't have bough drivepool or I would've bough the whole package at a discount instead of buying them one by one.
-
I'm 9 days into my DrivePool adventure. I saw my Read Striping vertical bar look like this tonight. It contains a color that isn't shown on the reference in the User Guide (reference link). The percentage also seems mysterious, as only all 3 colors combined would add up to 99.3% Anyone able to share some hard-earned knowledge with a curious mind? Thx in advance.
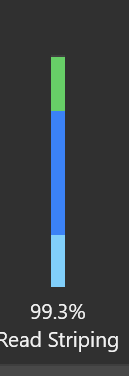

-
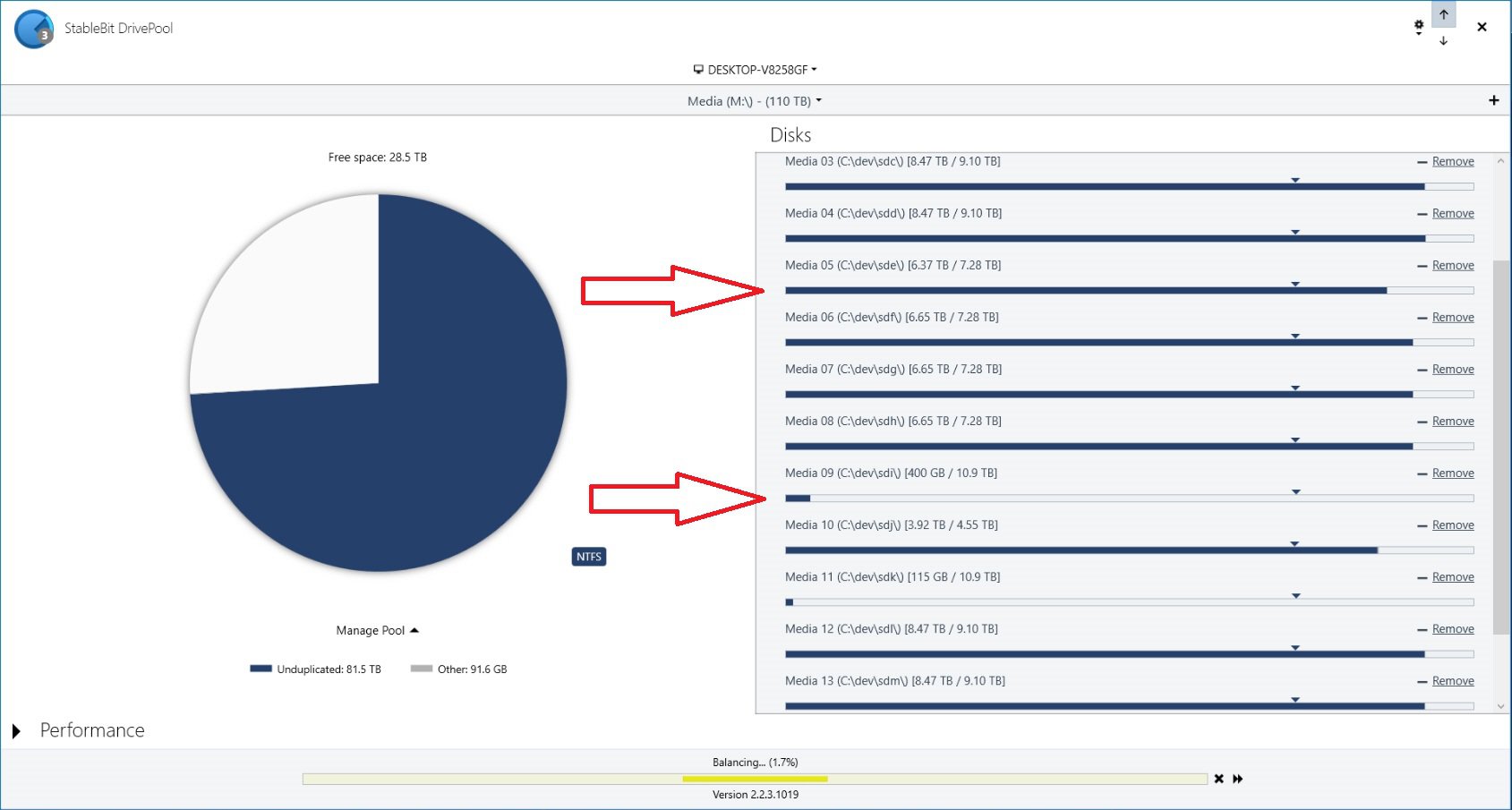
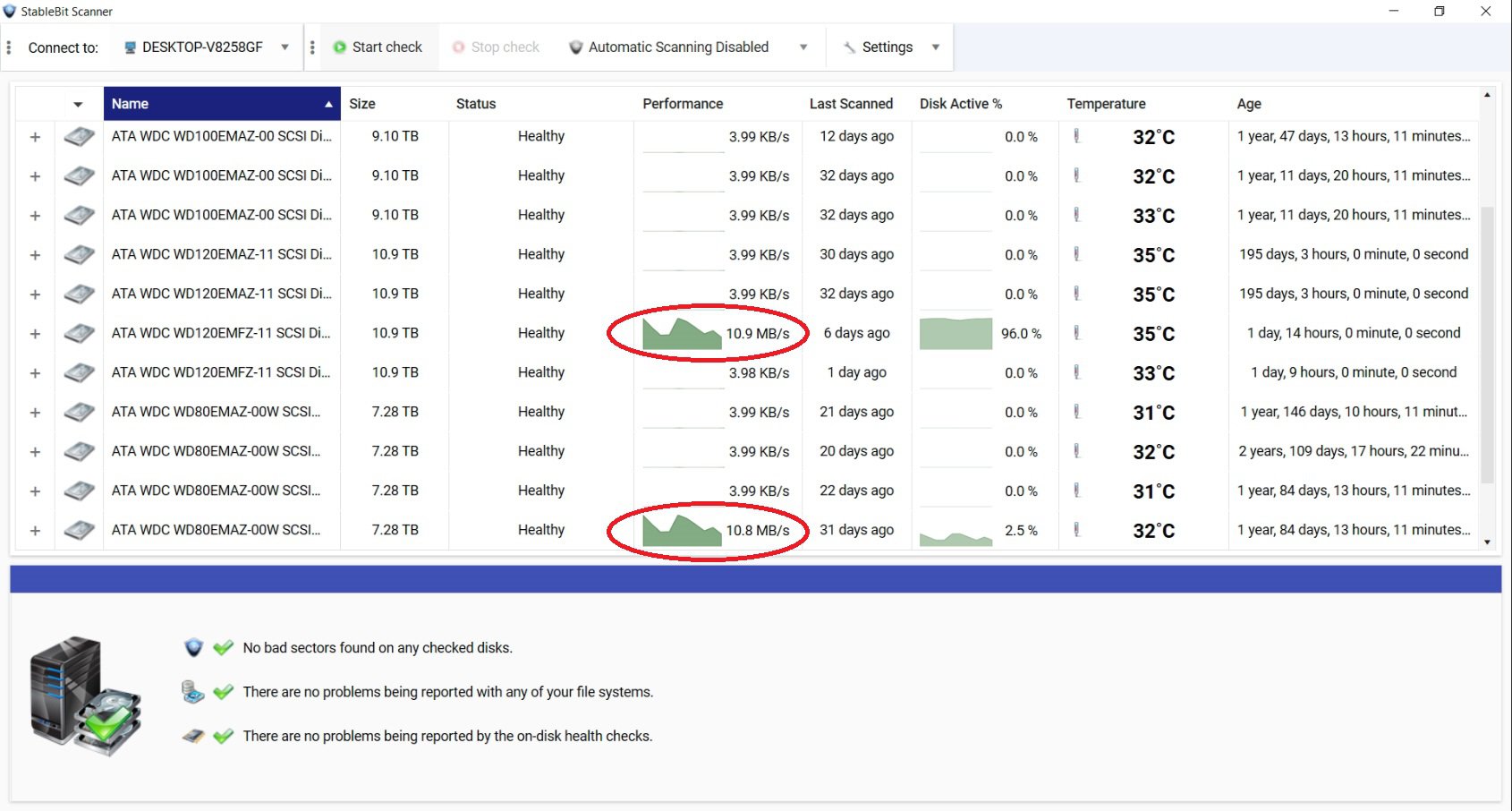
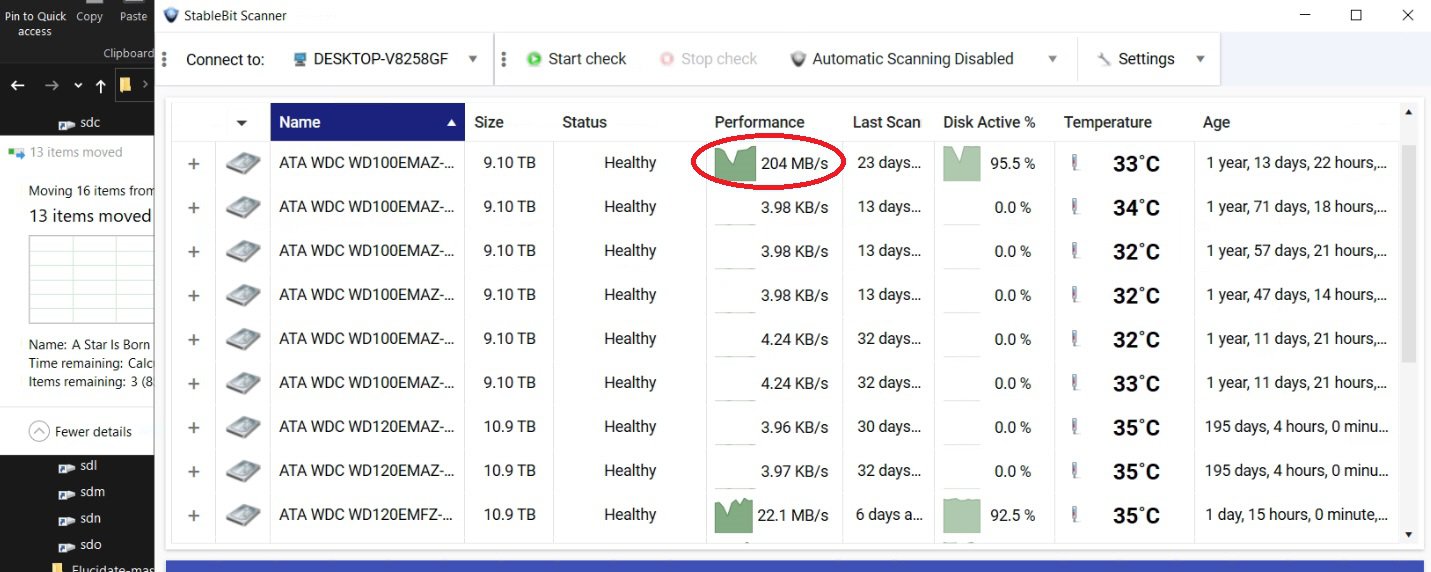
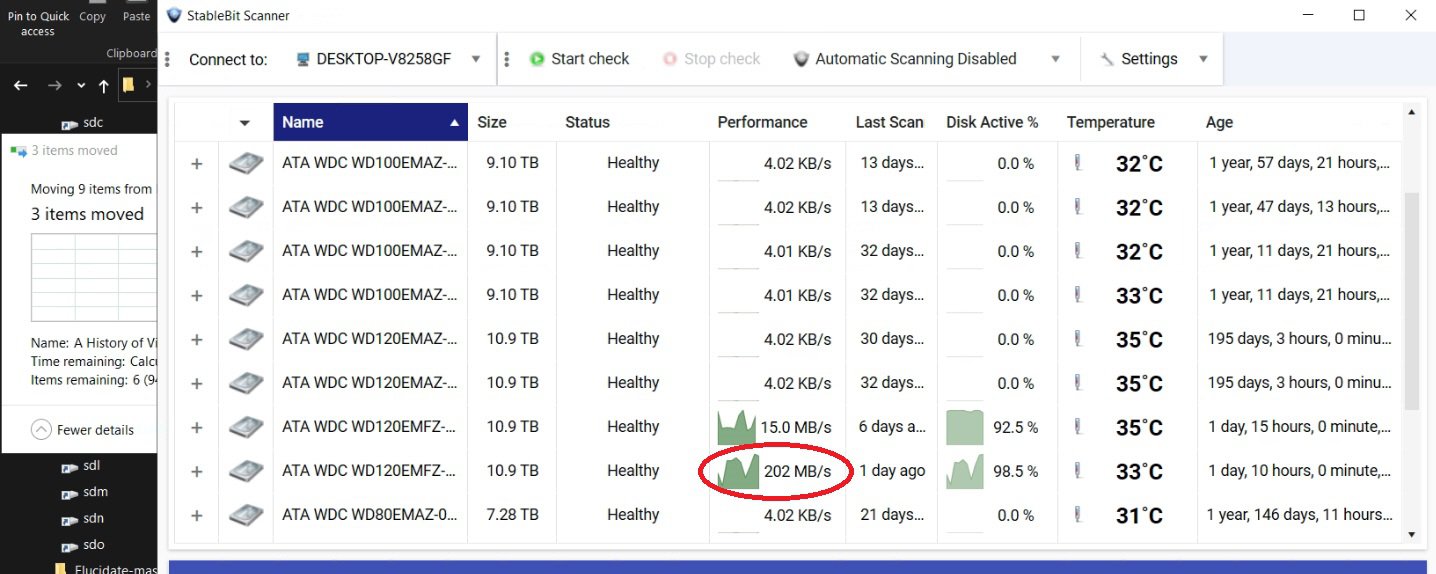
I added two new 12 TB drives to my pool yesterday and hit Re-Balance, and it is taking forever. As you can see in the pictures, it is currently moving data from one of my 8 TB drives to one of my new 12 TB drives. It has been doing so all night at about 10 to 20 MBps. At this rate (2% completed in one day) it will take about 50 days. Also shown in the pictures is me bypassing DrivePool by manually moving some files within the PoolParts using Windows Explorer from a 10 TB drive to the other new 12 TB drive. Stablebit Scanner shows that these speeds are normal, around 200 MBps. They are all on the same HBA, so the problem can only be caused by DrivePool. I know the obvious solution would be to manually move all the files to the new drives myself like I demonstrated in the pictures, but that would still be several days of me babysitting the process. I paid for DrivePool, and would like to be able to use it so I can just hit the Balance button and walk away. I tried checking and unchecking the Bypass File System Filters and Network I/O Boost settings but that had no effect, and I am not using file duplication. Is there anything else I can try?
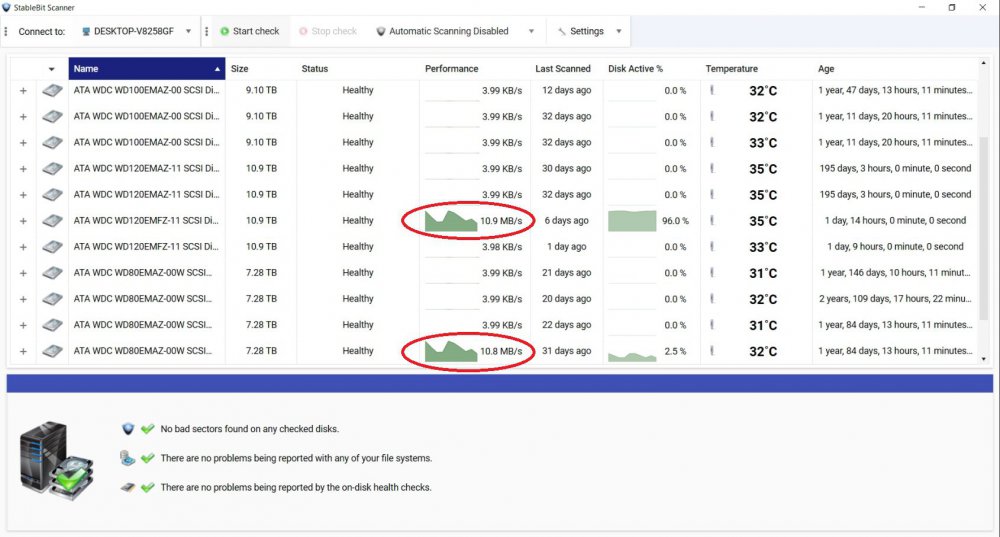
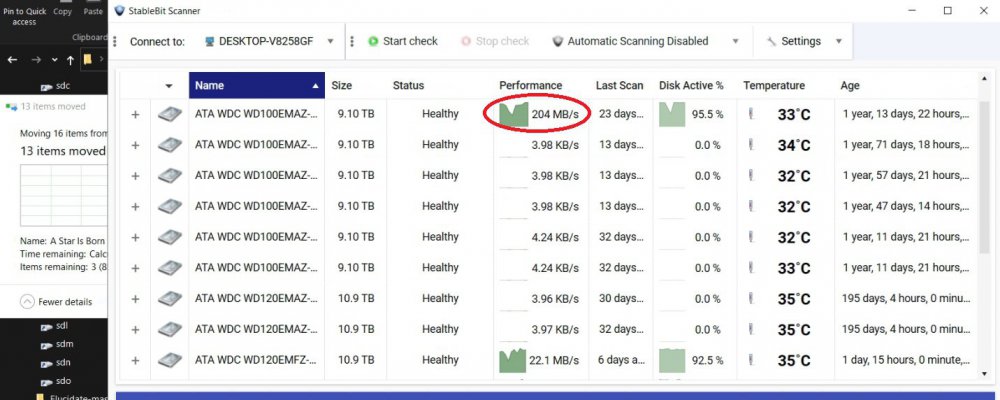
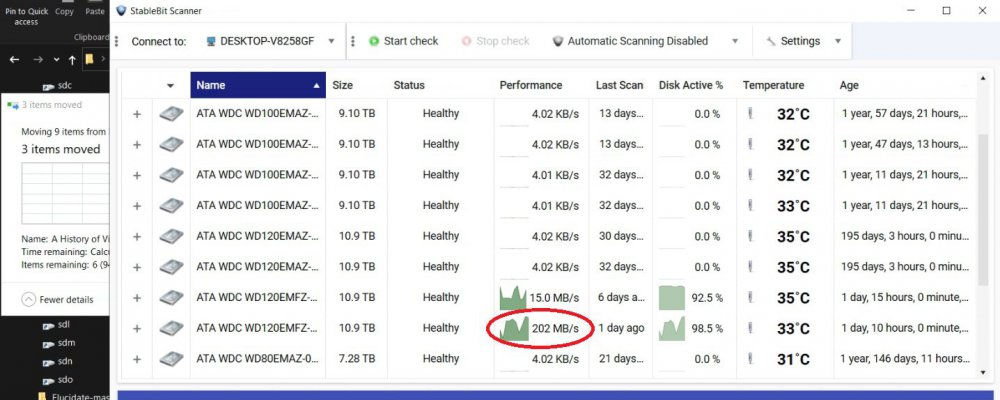
-
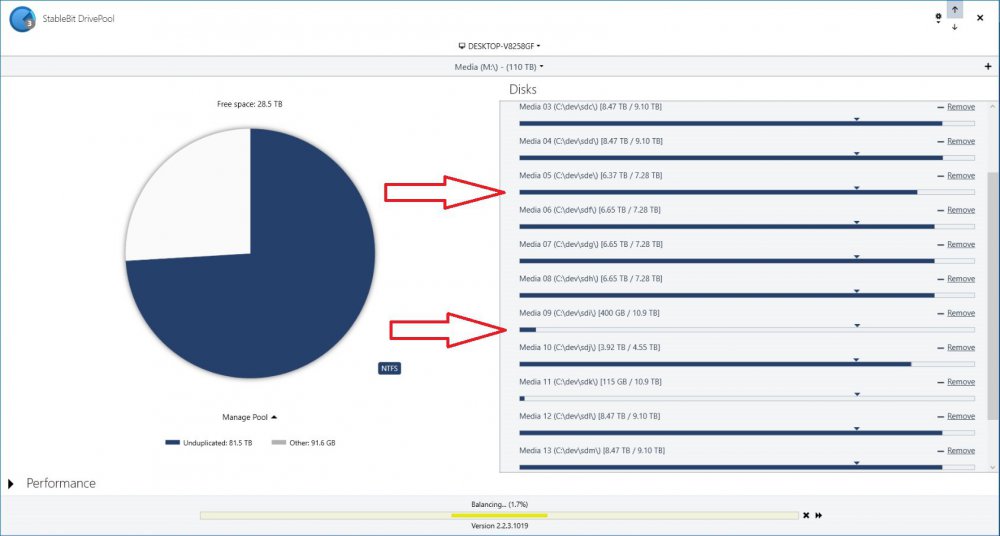
During balancing, I notice only two drives being used out of 10 total. All 10 drives have a new balancing target. Is there a way to use all disks simultaneously to speed up the balancing?
-
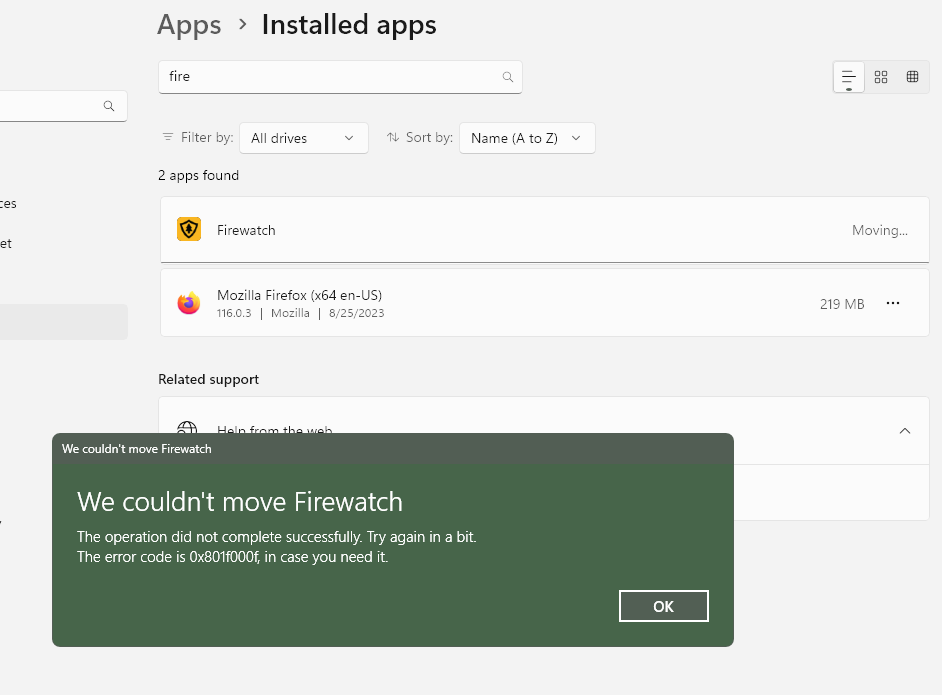
Hello Community, Just encountered an unusual situation with the Stablebit DrivePool, and I'm hoping for some advice or insights. Here's the short version: Originally, my goal was simple: move installed games from my C : (system drive) to my F: (DrivePool drive). Unfortunately, things haven't gone to plan. Both the Xbox app and Windows 'Installed Apps' function present error codes when I attempt to make the move—0x80070002 and 0x801f00f, respectively. To my surprise, these error codes remain consistent regardless of the game I'm trying to move. In an effort to solve this issue, I attempted to create another DrivePool drive. This, too, resulted in the same error codes. A ray of light in this scenario came when I used StableBit CloudDrive to create a new drive (X:), with the F: (DrivePool drive) chosen as the local drive. This approach worked! I was able to transfer games to the X: drive without any errors, which effectively moved them to the F: drive. Based on these experiences, I suspect that this could be related to a DrivePool driver issue. I would appreciate any feedback—has anyone else faced this issue? Does my hypothesis about a DrivePool issue seem plausible? If you have encountered this problem, do you have any recommendations on resolving it? Looking forward to your insights
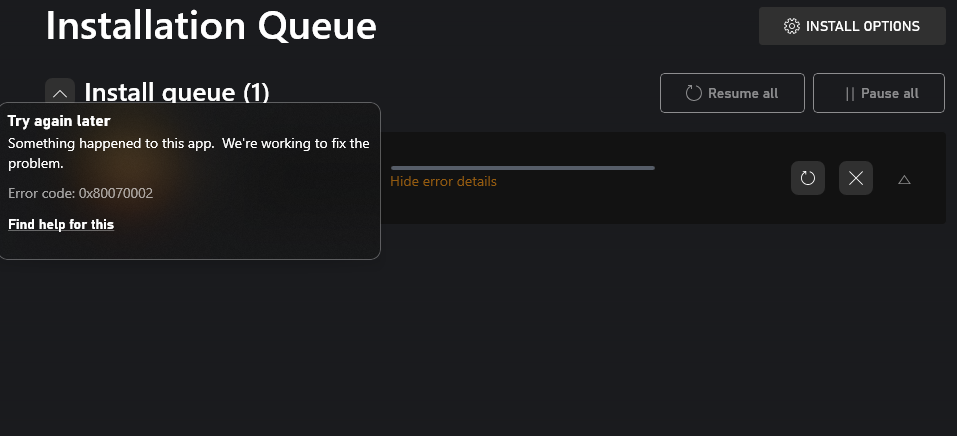
-
Hi Is it still safe to use the All in One plug-in with the latest beta 2.3.4.1519_X64? The GitHub page shows that it was last updated 3 years ago. https://github.com/cjmanca/AllInOne
-

New to StableBit Drivepool Quesiton regarding copy or move?
bigbirdtrucker posted a question in General
My pool size is 54tb with freespace of 18tb (all drives contain data) I'm going to enable duplication for one copy of each drive once I add enough new drives to cover the space needed for that (in my case an additional 36TB, correct?) I read on the forum of someone who moved their data from the original location to the hidden Poolpart folder (on that same drive) (called seeding) in order to see the files already in the pool. Do you recommend doing this? Should I be copying or moving my files into the pooled drive? If I do move my files to the hidden Poolpart directory from the same drive... are there risks if I then remove the drive later? Such as would the files then be erased form disk if I move the files to the poolpart folder on the same drive - for each drive with the intention of seeing the files in the pool? When I add drives to the pool that contain data I rad that stablebit drivepool doesnt modify those files. Am I correct to assume that even without moving the files to the poolpart folder from the same drive that the files that are on the drive at the time of creating the pool are indeed already in the pool (yet not visible)? Is it true that when duplication is enabled that drivepool will place my files across several of my drives which have ample space? While I understand the benefits of leaving my files in place on the origin drive....those files are automatically part of the pool when added right? Even though it took literally zero time to add them to the pool with over 30tb on the drives combined? How will I know which files are on which drive when it comes time to recover from a lost disk for instance? Is there a reason that the pooled drive appears empty when drives with data are added to it? Do I need to have my files visible on the pool (i.e. moving the files to the poolpart dir on the same drive for each drive in order to let snapraid see my pool and protect it with parity? -
I was wondering if there was any documentation or information on how the .covefs folder within the pool folder of an attached drive works? I am running into an issue that I'm troubleshooting and would like to know more about the function of this folder so that I can avoid making an changes that could corrupt the pool data. In particular, can I delete the files in the folder without issue?
-
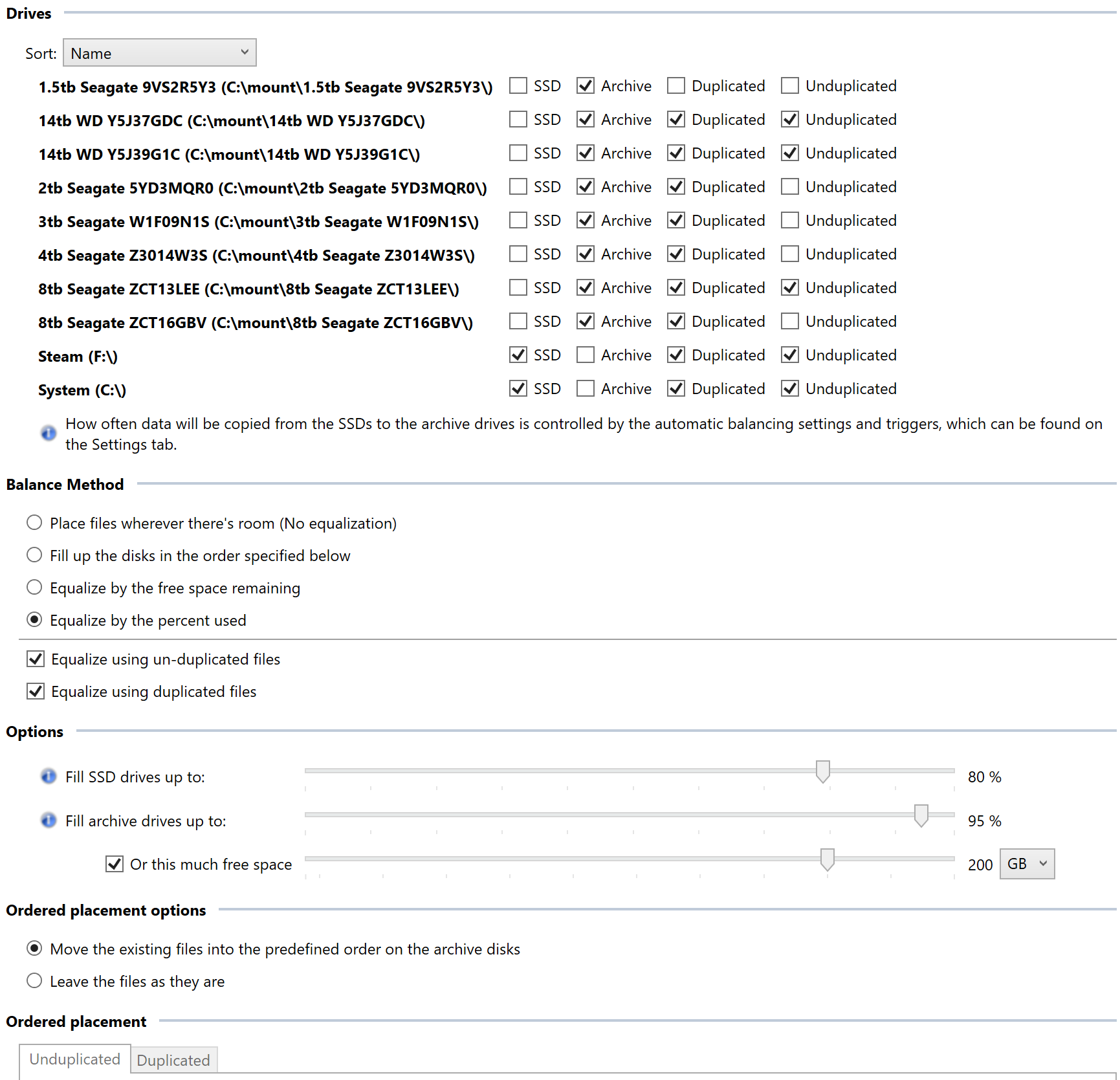
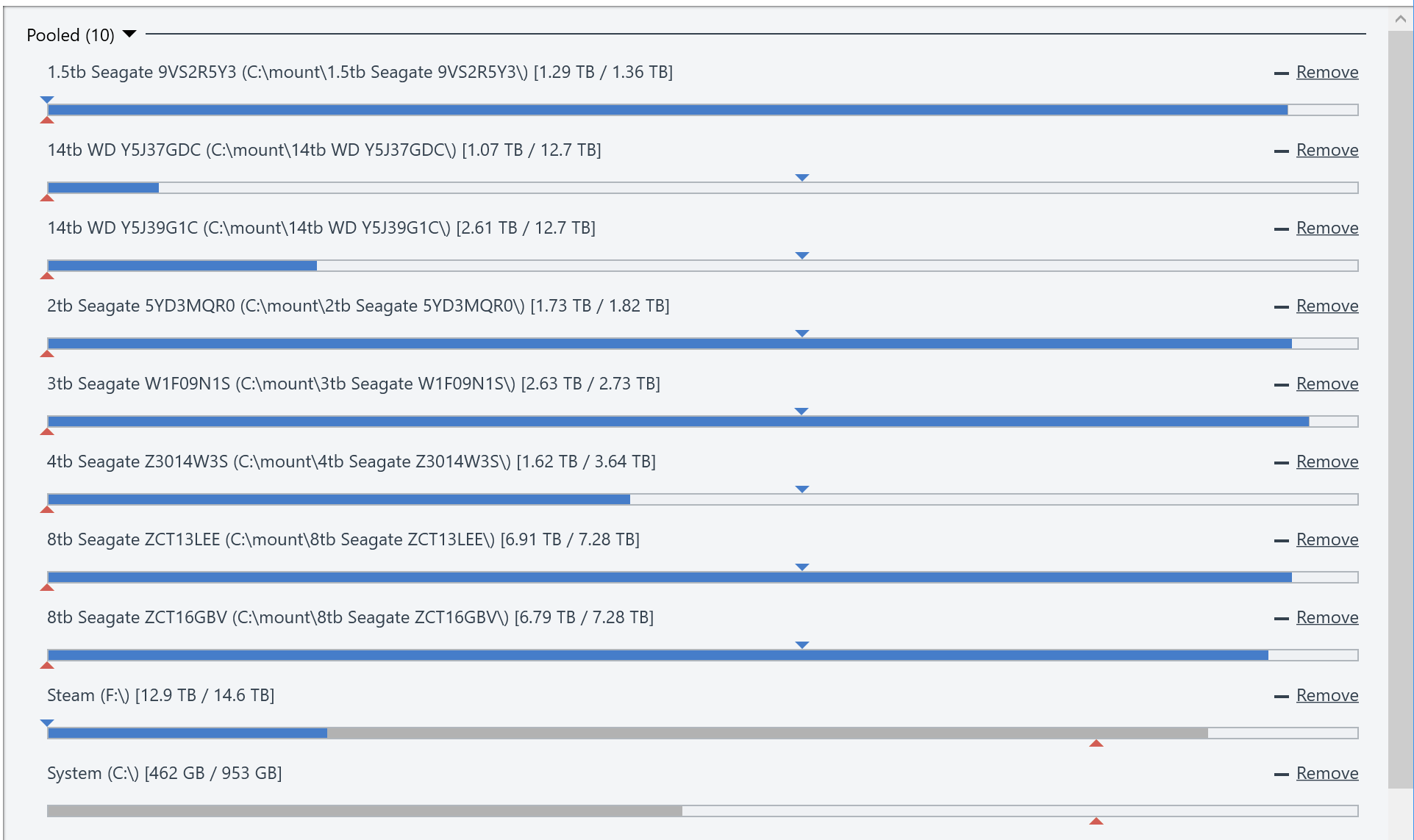
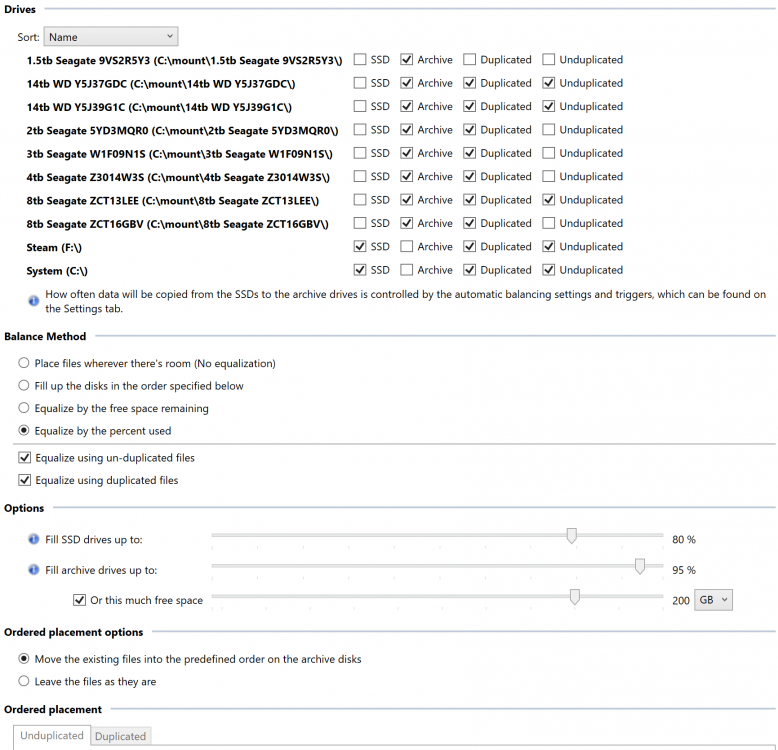
In an attempt to learn the plugin API, I created a plugin which replicates the functionality of many of the official plugins, but combined into a single plugin. The benefit of this is that you can use functionality from several plugins without them "fighting" each other. I'm releasing this open source for others to use or learn from here: https://github.com/cjmanca/AllInOne Or you can download a precompiled version at: https://github.com/cjmanca/AllInOne/releases Here's an example of the settings panel. Notice the 1.5 tb drive is set to not contain duplicated or unduplicated: Balance result with those settings. Again note the 1.5tb is scheduled to move everything off the disk due to the settings above.
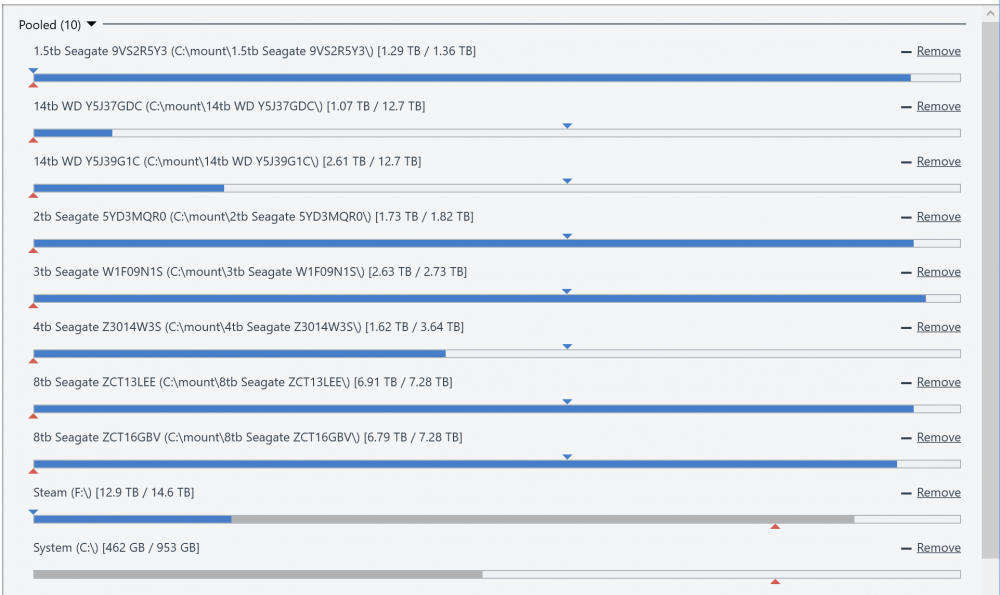
-
Is there any way to see exactly which files Drivepool thinks are open? And perhaps, by which process? If I check the windows Resource Monitor, the only files that show disk activity are on the OS drive and not part of the pool. I've been turning off services, terminating running programs and uninstalling apps in an attempt to figure out which one is holding access to these 42 files. I have also scanned for malware and couldn't find anything. Another strange symptom: If I force disk activity on the pool by opening a bunch of files, Resource Monitor shows these files being accessed. However, the 42 Open Files as reported by Drivepool remains unchanged. This was never an issue until I recently rebuilt my server and reinstalled Windows. Are newer installs of Windows behaving oddly?
-
I'm having significant problems with the DrivePool hanging for minutes on basic things like showing the contents of a folder in Explorer. So far I cannot figure out how to locate the source. For instance today I opened a command prompt and simply tried to switch to the DrivePool's drive (i.e. I typed X: into the command prompt.) That caused the command prompt to freeze for several minutes. While it was frozen in that command prompt I opened up a second command prompt and switched to each of the underlying drives, and even listed out a hundred thousand or so files and folders on each of the source drives. So, it feels like the DrivePool drive is hanging for something independent of the source drives. On the other hand I don't know what that something else could be as in my quest to troubleshoot this I have setup a brand new computer with a clean fresh install of everything including DrivePool. The only thing I transferred was the source drives. Yet the problem followed the drives to the new computer. StableBit Scanner reports that all the underlying drives are in great shape, and so far I can't find any logs that report problems. How can I root out the source of this problem? Oh and I did also try the StableBit Troubleshooter. However, it hung infinitely at collecting system information (Infinity defined as well over 80 hours of trying). Also the hanging seems to be intermittent. I might go a day or so without or it might happen every few minutes. I have utterly failed to identify triggers so far.
-
Hi there, Is it possible to use a DrivePool made up an SSD (1TB) and an HDD (10TB) as the cache drive for a CloudDrive? I would love to use the SSD Optimizer plugin with DrivePool to create a fast and large cache drive. This would give the best of both worlds, newer and more frequently used files would be stored on the SSD, older files would slowly be moved to the HDD, you would only need to download from the CloudDrive if you are accessing an older file that is not in the cache... Is this possible?
-
Looking for a little guidance so as to avoid making any errors that could cause damage. Avira Antivirus updated and for some reason the settings are different so it flagged all of my Stablebit Drivepool (and Stablebit Scanner) files on my WHS2011 system. I suspected this was a heuristic error on Avira's part, but did some searching in the forum to confirm that was true. My issue is that for whatever reason Avira is unable to restore the program files back into the correct spots, so instead it just dumped them into a folder on the desktop called "RESTORED". Clearly that is not very helpful as I don't know how to put them back with the right location structure for both Drivepool and Scanner within their original program folders. When I load the dashboard I find both Drivepool and Scanner are missing as they are disabled in safemode. What is the ideal method to fix this? I thought I saw some people mention to just uninstall Drivepool and Scanner, then reinstall them. I'm not overly concerned with Scanner, but will an uninstall/reinstall mess up my existing pool? And am I uninstalling at the OS level if that is the method to use? And then when I reinstall will they'll get picked up on the dashboard again and enabled? Thanks
-
Maybe due to an update with Win 10 Pro. Drivepool no longer can find my drives unless they are assigned a drive letter. Although this is not a problem with system with a little number of drives but at one time I had made partitions 1 for the solid data and 1 for the backup on the same drive. I changed my program but this may need to be looked into. My scheme was this. I made 27 partitions 1 for the letters of the alphabet and 1 for Numbers. My system worked great for many years using Win 7 Pro and I only moved to Win 10 Pro several months back.
-
Hi and hope everyone had a good weekend (and thanksgiving in the US). I have had stablebit drivepool and scanner for the past 3 plus years. It has worked great. I have a mirrored setup of two 4TB drives in my pool. This is housed in a windows server (essentials 2016) that backs my home client PCs nightly and also has server folders for the family. The server is also backed up into an external 8TB drive every day. I am planning on replacing the internal 2 4TB with 2 8TB drives as I am almost out of space. I do not however have an available spot inside the computer to add one or two more drives during the upgrade. So I was wondering what my best (fastest or safest if they differ) options for migration were? 1. Remove one of the two HDDs probably via the DP UI ( i presume i would need to force it to cancel duplication when that happens?) and which of the two should I start first with, given that I believe that one of them tends to have slightly less space maybe from the VSS. Then I pop the first new 8TB drive in its spot, add it via DP, and wait for the over 3TB data to be copied over. Then repeat with the second drive? Or would this be too many writes. A to B and then back to A 2. Switch of the PC, pull one drive out and clone it to the 8TB drive and then do the same for the other. When i put the two new 8TB cloned drives back will DP recognize that these are the same content as the previous pool except for the size? Or does it use serial numbers of the old drives and would that be an issue. 3. Connect one or both of the new 8TB drives to the PC via an external USB enclosure such as the one I have: Unitek 2 drive unitek enclosure Then ask DP to add them to the same pool and do its magic and move the files to the two new drives? This may take a while given in my experience the external enclosures are slow even if they claim to be USB 3.0. For options 1 and 2, I presume I should stop all actions in the server like client back up and server backup before I start I presume? Thank you for your time. Best AK
-
Hello all, I have a Windows 2012R2 server with a 4TB RAID1 mirror (2 x 4TB HDD, using basic Windows software RAID, not storage spaces - can't boot from storage spaces pool) and some other non-mirrored data disks (1x 8TB, 2 x 3TB etc.) This is configured with the OS and "Important Data" on the 4TB mirror, and "Less Important Data" on the other non-redundant disks. The 4TB mirror is now nearly full, so I intend to either replace this mirror with a larger mirror, or replace this mirror with two larger non-mirrored drives, and use DrivePool to duplicate some data across them. I'm evaluating whether the greater flexibility of using DrivePool is worth moving to that, instead of using a basic mirror as I am currently. Current config is this: C: - redundant bootable partition mirrored on Disk 1 and Disk 2 D: - redundant "Important Data" partition mirrored on Disk 1 and Disk 2, and backed up by CrashPlan E:, F:, etc. - non-redundant data partitions for "Less Important Data" on Disks 3, 4, etc. If I moved to DrivePool I guess the configuration would be this: C: - non-redundant bootable partition on Disk1 D: - drivepool "Important Data" pool duplicated on Disk1 and Disk2, and backed up by CrashPlan E: - drivepool "Less Important Data" pool spread across Disks 3, 4 etc. - or - C: - non-redundant bootable partition on Disk1 D: - drivepool pool spread across all disks, with "Important Data" folders set to only be stored and also duplicated on Disk1 and Disk2, and backed up by CrashPlan (or something similar using hierarchical pools) I have a few questions about this: Does it make sense to use DrivePool in this scenario, or should I just stick to using a normal RAID mirror? Will DrivePool handle real-time duplication of large in-use files such as 127GB VM VHD's, and if so, is there a write-performance decrease, compared to a software mirror? All volumes use Windows' data-deduplication. Will this continue to work with DrivePool? I understand the pool drive itself cannot have deduplication enabled, but will the drive/s storing the pool continue to deduplicate the pool data correctly? Related to this, can DrivePool be configured in such a way that if I downloaded a file, then copied that file to multiple different folders, it would most likely store those all on one physical disk so that it can be deduplicated by the OS? CrashPlan is used to backup some data. Can this be used to backup the pool drive itself (it needs to receive update notifications from the filesystem)? I believe it also uses VSS to backup in-use files, but I as this is mostly static data storage I think files should not be in use so I may be able to live without that. Alternatively, I could backup the data on the underlying disks themselves? Are there any issues or caveats I haven't thought of here? How does DrivePool handle long-path issues? Server 2012R2 doesn't have long-path support and I do occasionally run into path-length issues. I can only assume this is even worse when pooled data is stored in a folder, effectively increasing the path-length of every file? Thanks!
-
Hi, Sorry if this is not in a suitable location, but I couldn't find a suggestions option. Would it be possible to implement a auto-tiering option in some way? E.g. automatically use fast storage as primary and slow storage for secondary duplicates? That way something should always come off say NVMe first, followed by SSD, SSHD and traditional HDDs. I only ask, because by default my duplication goes across HDDs and the performance is... as you would expect! Alternatively, some way of using the faster disks as "caching" drives - perhaps based on frequency of file access or just by file access timestamps? Just some thoughts I had today whilst trying to make best usage of my varied storage devices.
-

Visual Studio Projects on Drivepool drive breaking Visual Studio features?
Cerlancism posted a question in General
I have a Drivepool with 2x folder duplication for my projects. I was initially blaming VS 2019 for possible bugs. However, after I moved the project to my SSD C Drive not using Drivepool, everything works again. Things which I found broken are: - Slow to no detection of syntax errors - Quick actions for code refactoring are doing nothing. System Infomation Microsoft Windows 10 Pro Version 2004 10.0.19041 Build 19041 Drivepool 2.2.3.1019 Microsoft Visual Studio Community 2019 Version 16.7.1 VisualStudio.16.Release/16.7.1+30406.217 Microsoft .NET Framework Version 4.8.04084 Update I have found a walkaround to share the drive on the network and work from the network share. -
I am a complete noob and forgetful on top of everything. I've had one pool for a long time and last week I tried to add a new pool using clouddrive. I added my six 1TB onedrive accounts in cloudpool and I may or may not have set them up in drivepool (that's my memory for you). But whatever I did was not use drivepool to combine all six clouddrives into a single 6TB drive and I ran out of space something was duplicating data from one specific folder in my pool to the clouddrive. So I removed the clouddrive accounts, added them back, and did use drivepool to combine the six accounts into one drive. And without doing anything else, data from the one folder I had and want duplicated to the clouddrive started duplicating again - but I don't know how and I'd like to know how I did that. I've read nested pools, hierarchy duplication topics but I'm sure that's not something I set-up because it would have been too complicated for me. Is there another, simpler way that I might have made this happen? I know this isn't much information to go on and I don't expect anyone to dedicate a lot of time to this, but I've spent yesterday and today trying to figure out what I did and I just can't. I've checked folder duplication under the original pool, and the folder is 1x because I don't want it duplicated on the same pool so I assume that's not what I did.
-
Hi, I got a question: Ok, Here's what I am starting with: Local Machine D: 2 GB E: 5 GB F: 3 GB Local Network Server Windows Fire Share Lots of space. Network: 10 gbit network. Now, what I want to do: (already tried, actually) 1st pool: Local Pool D: E: F: No duplication, just 1 big 10 GB pool. "Local Pool Drive" is the name. 2nd pool: Cloud Drive, Windows File Share Provider, 10 GB disk, no encryption. "File Share Drive" is the name. 3rd Final Pool +"Local Pool Drive" +"Fire Share Drive" Some folders like my Steam Games I don't want to duplicate because Steam is my 'backup' I set this up, but something went backwards as it seems to be trying to put the un-duplicated files on File Share Drive, which is not what I want. I am currently taking my files back off to be able to rebuild this. I think I've set some stuff up wrong. I understand the basics, but I am missing something in the details. Now, my thinking was to allow me to have a local 10 GB drive, and a 10 GB mirror on my file server. So, I get the best of both worlds. it seems it can "Technically" do this. What I would like to know is, when reading files, will I get local copy reads, or is everything going to grind to a halt with Server Reads? Is there a way to force local reads? I expect a cache would hide the uploads unless I went crazy on it. (hint, I copied all my files on it, it went crazy.) but, I was hoping for a Quazi live backup. So, I get full use of my local disk sizes and have a live backup if a drive ever failed or I wanted to upgrade a disk. Is this one of those "yea, it can, but it doesn't work like you think" or "yea, your just doing it wrong" things. What are the best options for Could Drive (pinning, network IO settings, cache size, drive setup settings) What are the best Local Disk options, D: E: F: and the Local Disk oh, and as a nutty side note, I tend to play games that like SSDs, I have a C: SSD but it's limited in size, (yea, I know, buy a new one, ... eventually I will) so, I would like to setup those games along side my others and add C: to D: E: and F: and tell it no files go on C: cept for the ones I say and EVERYTHING just looks like a D: drive because the actual drive letters will be hidden in disk manager. so, If I want to move a game into or off of my C:, Drive pool SHOULD make it as easy as clicking a couple of boxes right? That's a lot so summary: Can I force local reads when using a pool of Local Pool and Could Drive Pool together? Can I force certain files into specific drives only? (seems I can, just want to confirm) Can specific folders not be duplicated? (again, I think I know how, but there's a larger context here.) Can I do the above 3 at once? Thanks!
-
Hey, I've set up a small test with 3x physical drives in DrivePool, 1 SSD drive and 2 regular 4TB drives. I'd like to make a set up where these three drives can be filled up to their brim and any contents are duplicated only on a fourth drive: a CloudDrive. No regular writes nor reads should be done from the CloudDrive, it should only function as parity for the 3 drives. Am I better off making a separate CloudDrive and scheduling an rsync to mirror the DrivePool contents to CloudDrive, or can this be done with DrivePool (or DrivePools) + CloudDrive combo? I'm running latest beta for both. What I tried so far didn't work too well, immediately some files I were moving were being actually written on the parity drive even though I set it to only contain duplicated content. I got that to stop by going into File Placement and unticking parity drive from every folder (but this is an annoying thing to have to maintain whenever new folders are added). 1) 2)