Jonibhoni
-
Posts
50 -
Joined
-
Last visited
-
Days Won
4
Everything posted by Jonibhoni
-
I think the FAQ answers this, actually. The folder structure would probably look like you described. Your Dropbox would be populated with multiple cloud drive folders, distinguishable by ID. I don't use Dropbox myself, but with multiple "local disk" CloudDrives in the same location it looks like this:

-
You also cannot change the virtual sector size. It's a thing I regretted when I discovered that MyDefrag cannot handle disks with 4096 bytes per sector.
-
Hello again klepp, check the https://stablebit.com/Support/CloudDrive/Faq
-
Yep. Also with having automatic balancing enabled, your pool will become unbalanced from time to time. For example if you've setup the "Balance Immediately -> No more often than ..." rule, or if you've setup a trigger like "If the balance ratio falls below...". As soon as there is 1 byte to move, the arrow should appear. But automatic balancing will not start until all the requirements you've setup for automatic balancing are fulfilled. Then you can force an early start of balancing with the arrow.
-
Your balancing pass would have nothing to do. That's why there is no arrow. A green filled bar means your pool is perfectly balanced according to the balancing (and file placement) rules you've setup.
-
Well, it's not just due to encryption. Also that CloudDrive stores data on a virtual drive block level and not file level. Means, that you couldn't just download your Macrium image file even without encryption, because it's spread over a lot of files. So, for your use case, you can create a CloudDrive at your Dropbox with any local drive as local cache drive (e.g. your spinners) - that will work. You can also access your images from another computer in case your kids burn down your house. BUT, as you said, you will need to install CloudDrive on another computer in order to download, decrypt and assemble your data. CloudDrive is NOT made to have a shared drive in the cloud that's simultaneously used from many computers, in fact, this will corrupt your data. But if you know for sure, that you will never access that drive from your old computer again (because it burned down), you can force attach it from another computer. https://stablebit.com/Support/CloudDrive/Manual?Section=Reattaching your Drive#Force Attaching As always, make sure your decryption key is not on a post-it in your burned down house, in case. Btw.: Other services like Google Drive or OwnCloud based ones offer to setup multiple synchronization folders per machine (not just one "D:\Dropbox" like Dropbox), that would also solve your problem.
-
I don't think so. SSD Optimizer is no RAM disk or alike. It just makes files written to the designated SSDs in your pool first. But with those SSDs being a "proper" part of your pool already. So as soon as your data is written to the pool SSDs, it's already a regular part of your pool and duplicated etc. like any other file in your pool, regardless if it currently sits on the SSDs or later on the HDDs. But there are some differences in handling, e.g. that you have to supply two SSD for SSD optimizer, if you want duplication, or different behaviour when running full. I wrote something about it here:
-
I always thought the straightforward way was to let PrimoCache cache the virtual pool drive itself (preventing it also from caching duplicates twice). But I guess it only lets you choose physical drives, judging from your question?
-
Hey Ben, good you found it! Yeah, that balancer plugin was exactly what I was referring to! @Christopher (Drashna) , the balancing plugins manual page seems to be outdated here. It says "File Placement Limiter" while this balancer is now actually renamed to "Drive Usage Limiter".
-
Hi Ben! Check out the File Placement Limiter plugin: https://stablebit.com/Support/DrivePool/2.X/Manual?Section=Balancing Plug-ins
-
Replaced my HBA card, now some drives are marked missing
Jonibhoni replied to PredatorAlpha's question in General
Well "grey" means "Other" files, so the pool definitely doesn't recognize the files as part of the pool. So probably a random portion of your files are now apparently missing from your pool when you browse for them via the pool drive letter, while physically they still should be there on the disks (in a hidden "PoolPart" folder). Because you manually "removed" the missing disks from the pool (via GUI), I guess you cannot just make DrivePool recognize them again in an easy way. But as all your files should still be there, you may be fine by just seeding (moving) them from the old "PoolPart" folder to the new "PoolPart" folder, on each of the "grey" drives. Like if you were migrating files from some other folder on those disks to the pool without copying them. The procedure is described here: https://wiki.covecube.com/StableBit_DrivePool_Q4142489 Anyway, if you want to be on the safe side, maybe open a support ticket or wait til Chris or someone who was experiencing that problem answers here. Edit: It also doesn't explain why the disks artifically went missing from the pool in first place. -
So, first a small hint regarding the 120 GB partition on the 1 TB M.2: From meer technical side you wouldn't have to create a separate partition. DrivePool doesn't mind if you assign it a fresh and clean or old and used partition. It will "live" in just some hidden, ordinary folders in the root of the volume, without harming existing data in any way. Regarding the optimal SSD size, well... You have to understand that SSD Optimizer isn't a transparent cache like PrimoCache is (some users here on the forum are using that one). Instead it's kind of tiered storage with automatic rebalancing from time to time. Comparing flushing: PrimoCache: A fixed time delay (or immediately, if you run out of cache) after you wrote a file, the content of the cache will be written to the HDDs. SSD Optimizer: Placing files on the pool will put them onto the SSD, which will reduce the "balance ratio" of your whole pool. The "balance ratio" is a measure of how much your pool is balanced. Once the balance ratio of the pool falls below a certain threshold, which is configured as part of your general balancing settings, an automatic balancing pass is triggered for the whole pool. The files from the SSD will be moved as part of the rebalancing like any other file placement rules or balancing plugins. Means if you set your balancing settings to not balance more often than every 12 hours, your SSD will not get flushed at all before the next scheduled time. This can lead to a known problem: Comparing what happens when running out of cache: PrimoCache: If you run out of PrimoCache, your writes will be slower because PrimoCache is flushing your cache while you write. That's it. Kind of transparent to the user. SSD Optimizer: If you run low on SSD space with the SSD optimizer plugin, DrivePool may write new files that are small enough directly to your archive drives. But if the free space on your SSD is below a certain (configurable) threshold while your file to be written is larger than the remaing space on the SSD, you will get an error message telling you your disks are full. Your transfer will abort. You can read those topics if you want to know more: https://community.covecube.com/index.php?/topic/1881-ssd-optimizer-problem/ https://community.covecube.com/index.php?/topic/6060-using-ssd-cache-and-keeping-some-files-on-ssd https://community.covecube.com/index.php?/topic/6277-2x-250gb-nvme-drives-ssd-optimization-or-primocache/ https://community.covecube.com/index.php?/topic/5776-ssd-optimizer-as-cache https://community.covecube.com/index.php?/topic/6627-q-how-to-copy-if-a-file-is-too-large-for-the-ssd-optimiser/ So, regarding size, well.. it depends. If you want to realize something like a cache that will never bother you, you will need SSDs which are somewhat larger than the combined size of all the files you transfer during your desired rebalancing interval (like 12 hours, or 2, or whatever). You can choose that interval yourself, but the lower that interval is, which means the more often your pool is rebalancing, the more files will be moved around in general. And if your 120 GB SSD is 100 GB full with to-be-balanced data and you try to copy a 21 GB file onto your pool, transfer may fail. Correct me if I am wrong, anyone, because actually I'm not using SSD optimizer myself.
-
Hi CptKirk1! Yep, that's exactly the case. The whole reason of file protection in DrivePool is to protect about failure of a disk, with emphasis on "disk". So it's "smart" enough to not treat two volumes on the same disk as different disks: https://stablebit.com/Support/DrivePool/2.X/Manual?Section=File Protection There was some recent post where someone used a single SSD as cache for otherwise duplicated files by deactivating real-time duplication, but I have no experience with that; and it also means your files are not protected at all until (delayed) duplication: https://community.covecube.com/index.php?/topic/6890-ssd-not-being-used-for-new-files/#comment-37104
-
Yes, I guess it should work. Keep in mind, that DrivePool cannot split single files into chunks, so your physical drives that make up the pool must be large enough to host those 4 TB files (DrivePool works on file level, not on sector level!). But if you have for example two 10 TB drives, I guess it should work well. The performance characteristics will differ from RAID or dynamic discs, storage spaces and whatever, but if in doubt, maybe just give it a try. DrivePool doesn't need formatted drives, any existing partitions will do fine and creating a pool on them will not harm the existing data. For completeness, I can maybe add that there is even another possibility to have encrypted data stored on a DrivePool for redundancy: Instead of VeraCrypt, you *could* also use StableBit CloudDrive to create a "Local Disk" cloud drive inside your pool, which will act as if your local DrivePool drive was a cloud provider. As CloudDrive (as opposed to DrivePool) creates an encrypted virtual drive that is based on chunk files, you will have both Encryption (CloudDrive) and Redundancy (underlying DrivePool) in a nicely clean virtual NTFS drive with just software from the StableBit bundle. But honestly, I'm using that solution because I thought it was clever (it is more friendly to file-based backup than having 4 TB files), but - despite it works conceptually well - perceived performance is unfortunately an order of magnitude slower than just using a VeryCrypt container. I'm hoping for some optimization by the devs there... but I guess, as CloudDrive was made for, well: the cloud, it will never be as fast.
-
Hi, check the "Notes" on the SSD optimizer plugin on: https://stablebit.com/DrivePool/Plugins It says... That's probably your case, isn't it? I'm not using SSD optimizer myself, but I think in reality it isn't even just "one or more" but "all" of the file parts. Means: Nothing is stored on SSD until you have at least as many SSDs as you want file duplicates (2x duplication = 1 original + 1 copy = 2 SSDs needed). I think there were also some topics on the forum where this behaviour was discussed; feel free to search if you are curious for more.
-
Drives cannot be detected by DrivePool, how to get them to be detected?
Jonibhoni replied to DrivePoolfan's question in General
Any hint in the gear icon in upper right -> Troubleshooting -> Service Log? Check right after system restart and scroll to the very top, to see the part where DrivePool detects existing pools. (Maybe temporarily deactivate Service tracing / auto-scroll right after opening the log, to prevent the interesting lines to move out of view.) And, just out of curiosity, are there any other pools shown in the UI? (click your pool's name in the top center in the main window) And - also just another wild guess - are the two missing drives shown if you start your computer without the working drive plugged in? (Disclaimer: Do at your own risk. I'm just an ordinary user!) -
Is there any hint to a reason why it's not balancing? E.g: On the tooltip (upon hovering) of the pool organization bar on the main screen On the tooltip of the blue file icons in your screenshot As a warning in the balancing window as seen in https://stablebit.com/Support/DrivePool/2.X/Manual?Section=File Placement in the "File Placement Warnings" section On the top left of the main screen in the "Feedback" section that appears when you click the icon Any signs of "error" or "warning" or "exception" in the Log (gear icon in the upper right -> Troubleshooting -> Service Log)
-
Ok, all of this actually reminds me a lot to an issue that I already reported few months ago (5570628). Sorry, Christopher, I don't want to be a troublemaker but I think it's a severe issue and it seems that it is totally related to the one I reported, so I have to repeat this here. All the symptoms that are here mentioned are shared with my issue: Wrong hash, regardless of which hash algorithm Only happens with read-striping enabled "it's not consistent and it's somewhat difficult to reproduce" "It seems to happen more often with large files" Checking files again after they had erroneous hashes makes them actually appear fine, on second try I'm using a custom-written Python script for applying the hash algorithms, so I already did a lot of research on the details of when this occurs. When does it occur? It only occurs when all of the following comes together, though in this case I am reliably able to recreate it: It only occurs when read-striping is enabled. It never occurs when read-striping is disabled. It only occurs when reading data via the drive pool letter. Directly accessing the data on the underlying disks is always fine. It only occurs when my Antivirus software's on-access file scanning is enabled on the pool drive letter. All other options of the software (Bitdefender) seem unrelated. Also on-access scanning of the raw disks' letters/mount paths will not lead to the problem. It only happens if the file is not in Windows read cache (so the first read after cache flush or after a reboot, that is). It only happens to larger files (my guess: >128 MiB?). Which exact file is affected appears to be somewhat random. What is it doing to the data? The error is not affecting the actual data on disk, but "just" delivering wrong data on (first, uncached) read. The abnormal hash value (would be "412453bf" in WingNut's example) is always the same; that means: if a file is affected, it is always changed in the same way. I also tried to capture the corrupted data during hashing to see how it is actually changing and found out the following: The read file content is correct until offset 0x8000000 into the file; at this offset of the read data, the file content starts again from the beginning, like if the read pointer in the actual file was reset to 0 at that time and then the file was read "again" from start until eof. This means that the wrongly read data is exactly 0x8000000 = 128 MiB larger than it should be, with the excess part being a duplicate of the beginning (128 MiB) of the file itself. Though I only did this check once, so I cannot tell if this is always the same; anyway, the 128 MiB seems quite suspicious. So, in conclusion, for me it seems that the combination of large file + read-striping + on access virus scanner is sometimes delivering wrong data on first read. And this makes the hash function deliver a wrong value. What's so scary about this issue, is that it's actually a totally silent data corruption that could happen on any read of a file, not just by the hashing software (in fact, I used the normal Python library functions for reading files, same that every other Python program uses; ..which uses OS functions that probably every other software in any programming language uses). This even could mean that in theory the corruption could be made "permanent" if you move a file from the pool to somewhere else and the issue occurs on that read process. For me, this was reason enough to completely disable read-striping until this issue is fixed. Please, kuba4you and HTWingNut, feel free to double check for similarities with your issues! And may you kindly tell if and which antivirus software are you using? I hope by putting information together, we will find a solution for this. If it's not the same issue, then I'm sorry for bloating this thread. Edit: I just realized that the original question by WingNut was posted last year. Anyway, as the issue is still present and kuba4you revived that thread, I guess having the information here is still a good idea.
-
Hmm. You might still check the log (gear icon -> Troubleshooting -> Service log...) for error messages to appear when you manually start a rebalance operation via the GUI, or rather the moment it fails. Apart that, I don't know if there is any use, but if you haven't tried, you can also let DrivePool do the available cleanup operations like * Manage Pool -> Re-measure... * gear icon -> Troubleshooting -> Recheck duplication...
-
As far as I know this could also be an issue with the file placement settings themselves. I can see from your screenshot that you have all your files duplicated = files are stored by DrivePool on 2 different disks. That means, that in each of the file placement rules for a certain folder/pattern always at least 2 checkboxes have to be ticked. Otherwise you're telling DrivePool to store 2 copies of folder/pattern X but you only allow a single disk, which is impossible for DrivePool to fulfill. Also check all of the other possible reasons for this message in the section on "File Placement Warnings" in the manual: https://stablebit.com/Support/DrivePool/2.X/Manual?Section=File Placement
-
I'm not Drashna, but I assume the idea was to create a CloudDrive that doesn't use an actual cloud provider (Dropbox, AWS, etc..) but a "Local Disk" provider. That means, that instead of uploading the chunk files (a large collection of small block files which the cloud drive is made of from a technical point of view) into the actual cloud, they are simply stored in a regular folder on a local disk; or - if you want redundancy and pooled space - on a local pool. If you mount the CloudDrive to a drive letter, it will look as a regular drive to the system, and so, according to the comments above, it should be possible to make this virtual drive the default storage for Windows Apps. While _technically_ the drive is actually stored (cut into small file chunks) on the local pool. I'm actually using a "local disk" cloud drive for having a "detachable" encrypted storage that is still duplicated and compatible with file based incremental backup. Whereas I never faced any "hard" problems with this approach, it unfortunately is a lot slower / less reactive than the large TrueCrypt container that I used before. I also tried folder and metadata pinning, but while it made it faster in terms of "usable", it's still not comparable to a TrueCrypt container. So .. if you want to use it for performance critical Windows Apps, it might still not be the best choice.
-
Remove subfolder from duplication with wildcard
Jonibhoni replied to Glauco's question in Nuts & Bolts
Actually, I just tried it and I find the command-line documentation quite comprehensive. If you have DrivePool 2.X installed, just open a command prompt with admin rights and type dpcmd set-duplication-recursive A help will be shown with examples etc. Seems like indeed this tool can help you with your task. -
All pools gone and became "COVECUBECoveFs" after WIndows 11 upgrade
Jonibhoni replied to DrivePoolfan's question in General
To calm you down: If the PoolPart.XXXX... folders are still there, your data should be save in there, too. Not each file in every folder, but scattered amongst all the drives that made up the pools. You can browse them and even read the data, best done by temporarily copying the file of interest to somewhere else to make sure the originals remain unchanged. Be careful to not write to them, as this may produce version conflicts once your pool goes properly online again. Regarding the resuscitation of your pool(s), I would wait until there is a proper fix or statement about Windows 11 compatibility or your particular problem. If you reset all settings now, chances are that it won't help but you just have to set them up again from scratch later. -
Hi, thanks for the answer. Still happening with latest 1244, I will open a ticket.
-
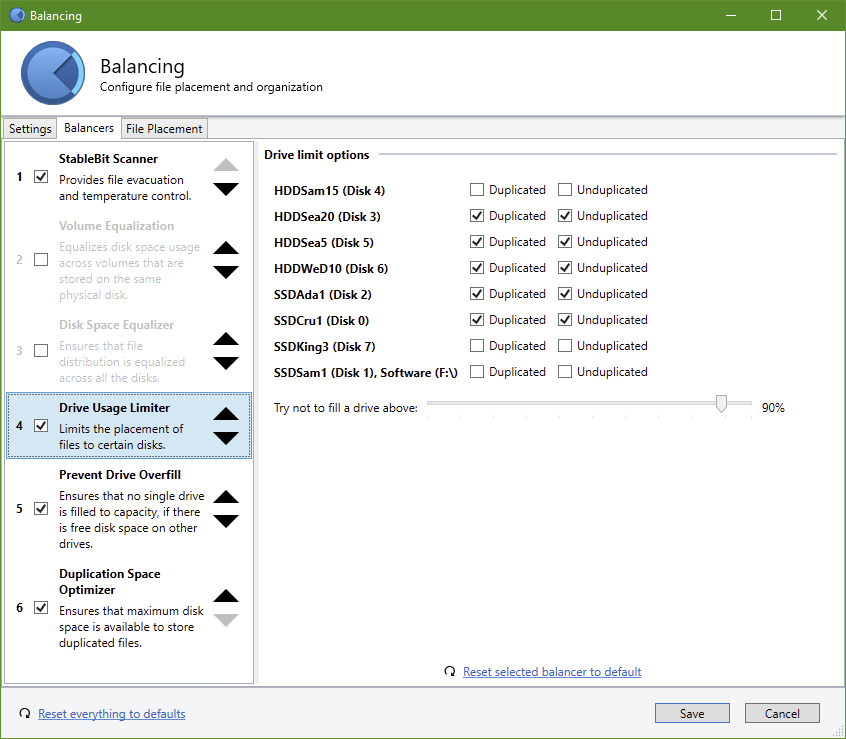
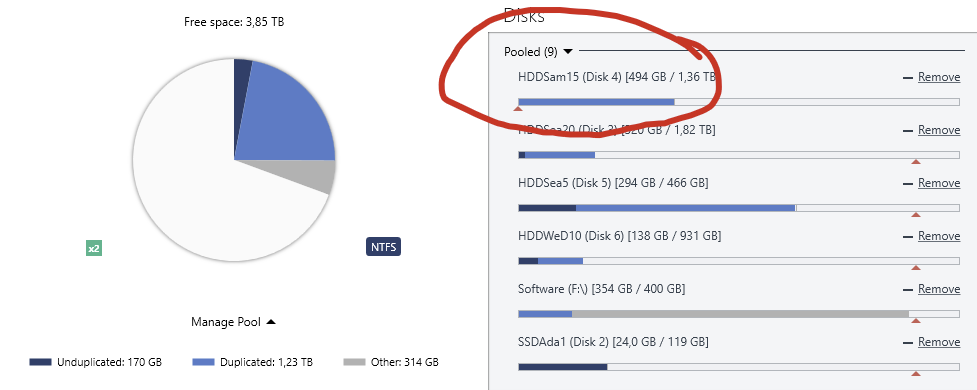
Hi there, glad to be part of the Covecube community now! I've just yesterday set up a new pool with all my (scanner checked) spare drives, moved all my data to it and configured some balancing and file placement rules. Nothing too awkward, though, I guess. Now I wanted to eventually empty some drives that were just in there temporarily, though not yet remove them from the pool. So I used the options on the "Drive Usage Limiter" plugin to set some of my drives to neither contain (new nor existing?) duplicated nor unduplicated data: The settings worked in that a "real time file placement limit" (I think that's what it is called?) was set for the drive: But unfortunately, no action whatsovever made the pool actually fulfill that limit! The "Pool Organization" shows up as a long green bar, when I hover it, it says: Whenever I click on "Manage Pool" -> "Re-measure..." or click the pool organization arrow -> "Re-balance" or even "Troubleshooting" -> "Recheck duplication" ... all ends up with some processing and stopping in that condition. So I took a look into the error log and found that all those operations are stopped by something like this: (Colored highlights by me.) I guess that's a bug? Cheers, Jonas