


Jonibhoni
-
Posts
50 -
Joined
-
Last visited
-
Days Won
4
Everything posted by Jonibhoni
-
Sorry, I didn't mention: Upload verification was disabled. I opened a ticket.
-
Hi, isn't there some priorization taking place under the hood when deciding about which chunk to upload first? I just did few experiments with Google Cloud Storage and 100 MB chunk size, cache size 1 GB (initially empty except pinned metadata and folders), no prefetch, latest public CloudDrive: a) pause upload b) copy a 280 MB file to the cloud drive c) resume upload With this sequence, the whole plan of actions seems to be well defined before the actual transfer starts. So lot's of opportunity for CloudDrive for batching, queueing in order etc. Observing the "Technical Details" window for the latest try, the actual provider I/O (in this order) was: Chunk 3x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 72 MB Chunk 3x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 72 MB Chunk 4x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 80 MB Chunk 10x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 4 kb, + 3 "WholeChunkIoPartialSharedWaitForRead" with few kb (4 kb, 4 kb, 8 kb) Chunk 10x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 4 kb, + 3 "WholeChunkIoPartialSharedWaitForCompletion" with few kb (4 kb, 4 kb, 8 kb) Chunk 0x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 4 kb Chunk 0x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 4 kb Chunk 4x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 23 MB Chunk 4x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 23 MB Chunk 5x1 Write 100MB, length 100 MB Chunk 6x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 11 MB Chunk 10x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 16 kb, + 4 "WholeChunkIoPartialSharedWaitForRead" with few kb (4 kb, 4 kb, 4 kb, 12 kb) Chunk 10x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 16 kb, + 4 "WholeChunkIoPartialSharedWaitForCompletion" with few kb (4 kb, 4 kb, 4 kb, 12 kb) So my questions / suggestions / hints to things that shouldn't happen (?) in my opinion: The chunk 10x1 is obviously just for filesystem metadata or something; it's few kb, for which a chunk of 100 MB has to be downloaded and uploaded - so far so unavoidable (as described in here). Now the elephant in the room: Why is it downloaded and uploaded TWICE? The whole copy operation and all changes were clear from the beginning of the transmission (that's what I paused the upload for until copying completely finished). Ok, may be Windows thought to write some desktop.ini or stuff while CloudDrive was doing the work. But then why did it have to be read again and wasn't in the cache on the second read? Caching was enabled with enough space, also metadata pinning was enabled, so shouldn't it then be one of the first chunks to cache?. Why is chunk 4x1 uploaded TWICE (2 x 100MB) with 80 MB productive data the first time and 20 MB the second?! Isn't this an obviuous candidate for batching? If chunk 5x1 is known to be fully new data (100 MB actual WORTH of upload), why does it come after 3x1, 4x1 and 10x1, which were all only "partial" writes that needed the full chunk to be downloaded first, only to write the full chunk back with only a fraction of it actually being new data. Wouldn't it be more efficient to upload completely new chunks first? Especially the filessystem chunks (10x1 and 0x1 I'm looking at you) are very likely to change *very* often; so prioritizing them (with 2x99 MB wasted transfered bytes) over 100 MB of actual new data (e.g. in chunk 5x1) seems a bad decision for finishing the job fast, doesn't it? Also, each upload triggers a new file version of 100 MB at e.g. Google Cloud Storage, which get's billed (storage, early deletion charges, ops...) without any actual benefit for me. So regarding network use (which is billed by cloud providers!): Naive point of view: I want to upload 280 MB of productive data Justified because of chunking etc.: 300 MB download (partial chunks 0x1, 3x1, 10x1) + 600 MB upload (4x1, 5x1, 6x1, 0x1, 3x1, 10x1) Actually transfered in the end: 500 MB download + 800 MB upload. That's 66% resp. 33% more than needed?
-
Wouldn't it be more efficient to just load the parts of the chunk that were not modified by the user, instead of the whole chunk? One could on average save half the downloaded volume, if I'm correct. Egress is expensive with cloud providers. 😅 Think: I modify the first 50 MB of a 100 MB chunk. Why is the whole 100 MB chunk downloaded just to overwrite (= throw away) the first 50 MB after downloading?
-
I remember there to be some message category in the Gear Icon -> Troubleshooting -> Service Log... for which you have to set the Tracing level to something lower ("Information" or "Verbose"). Then a text log item will pop up for each file touched during balancing (which is a lot). Unfortunately I don't remember the exact category and tracing level needed. :/
-
Well it also worked fine for me with either Bitdefender or read striping running, but not with both in combination, so you cannot really say that either of them causes it alone. It seemed to be the combination of read striping reading files in stripes and antivirus checking them on-the-fly. Specifically the curruption that was taking place was a duplication of exactly the first 128 MB of the file, which seems very coincidental and un-random. I would suspect that either Bitdefender scans files in chunks of 128 MB or DrivePool stripes them in 128 MB chunks. And somewhere on the clash of on-access-scanning of Bitdefender (and Windows Defender?) and read striping in the CoveFS driver (and maybe Windows file caching playing along, too), something unexpected happens.
-
Good to hear, for your case. When I measured it, read striping didn't give me any practical performance increase anyway, so it's not so much a problem to turn it off. But that the file corruption problem for you appears with Windows Antivirus, too, is actually a new level of that problem! I think you should file a bug report to the support, mentioning this! I mean, silent file corruption is somewhat a nightmare for people using what not technology to have their files stored savely. I had extensively documented the kind of corruption (what conditions, which files, even the kind of corruption in the file format) that happened for me back then, but the StableBit guys somewhat refused to do anything because they saw it as a problem on Bitdefender side. Which is partly disappointing but also partly understandable, because Bitdefender probably really does some borderline stuff. But if now it happens with the regular Windows Antivirus ... they should take it serious! I mean DrivePool + Read Striping + Windows Defender is not really an exotic combination, it's pretty much the most ordinary one. It's bits here at stake, StableBit! @Christopher (Drashna)
-
Does the problem still appear if you disable Read Striping (Manage Pool -> Performance -> Read striping)? And do you have an anti virus software active that checks files on access? I have an issue with random file corruption when using the combination of both (Bitdefender + Read Striping), which is why I disabled read striping.
-
There is some confusion around the forum whether DrivePool is the culprit or not.. It's a longtime open issue. If you search the forum you will find some older topics which report the same issue, with no straightforward solution, afaik. https://community.covecube.com/index.php?/topic/4734-drive-sleep/ https://community.covecube.com/index.php?/topic/48-questions-regarding-hard-drive-spindownstandby/ https://community.covecube.com/index.php?/topic/5788-hard-drives-wont-sleep-always-running-hot/ https://community.covecube.com/index.php?/topic/7157-i-have-to-ask-what-is-the-deal-with-drives-and-sleep-or-lackthereof/ If you solve your case, maybe be so kind and tell me your solution.
-
Just out of curiousity: Does the problem still appear if you disable Read Striping (Manage Pool -> Performance -> Read striping)? And do you have an anti virus software active that checks files on access? I once had an issue with the combination of both.
-
I won't judge about your procedure. Seeding usually involves shutting the service down, it may work without, or it may produce errors; I cannot say. I would stick closely to the seeding tutorial on the knowledge base (linked in my first post). You're probably right in that there is no (easy) method of listing non-duplicated data. Though I remember people on the forum somewhere had something with PowerShell and the official command-line tool that offered something similar like that, locating files and so on... Anyway, the functionality that you describe here is actually (sorry ^^) in the very official easy clickable GUI solution I pointed out before. If you simply remove a drive in the GUI, DrivePool will offer an option... ...which will exactly force the fast moving of unduplicated files from the to-be-removed drive, and then recreating the duplicated files from their existing copies in the pool later after the removal.
-
I don't think you can do it that way. I guess DrivePool would not recognize the moved PoolPart folder because of its naming scheme. But I'm not sure. The so called seeding procedure usually works by moving the contents (!) of existing (!) PoolPart folders (with DrivePool service shut down before), but it's also an advanced procedure with potential data loss if things go wrong. Honestly, why don't you just add the new drive to the pool and then remove the existing one with the GUI? It would migrate the data as you wish and probably not be much less efficient than doing it manually.
-
DrivePool doesn't have the concept of a "primary" and a "secondary" pool. So there is no "only duplicates" in the meaning of "the copy of the original" because there is no "original" - all two copies of a 2x-duplicated file are valid and equal. DrivePool fetches any of them when you access it and just makes sure that there are always 2x the file stored physically within your pool, without any of them being superior. So much for the theory. In practice, what you want to do ... ... is perfectly doable. You create a third, "parent" pool that contains pool 1 and pool 2 (and nothing else). In this parent pool, you set duplication for the whole pool to 2x. (In the lower pools 1 and 2, you disable duplication). Then you move all your files to the parent pool and DrivePool will distribute one copy of each file on pool 1 and one copy on pool 2. If you simply move the files from your original pool (now "pool 1") to the parent pool, you will be fine, you just have to wait for all the 20 TB being moved. If you are more adventurous, you can also go through a procedure referred to as "seeding" (https://wiki.covecube.com/StableBit_DrivePool_Q4142489) which will skip half of the disk writing work (but is more difficult and risky).
-
Probably the internal DrivePool metadata ("[METADATA]"). It's locked to 3x-duplication by default.
-
Afaik, yes. To my understanding, SSD optimizer cache functionality works with "real-time file placement limits", which kind of says where files are allowed to be put on *creation* / first write. The regular file placement rules kick in on (subsequent) balancing passes. So I would remove the SSD from file placement rules, if you don't want files to be archived there. (but I'm not using SSD optimizer myself) Also, you could just try to temporarily deactivate SSD optimizer, to see if a subsequent re-balancing pass fixes the thing. Then we at least know who is the culprit. (The log time is relative time since service start. So all fine here. )
-
Strange, hmm... How is your SSD Optimizer set-up? Do you have at least 2 drives marked as SSD and the rest as archive? And if you open *gear icon* -> *Troubleshooting* -> *Service log* after you have done a "re-balance" attempt, is there anything with error or warning or critical level?
-
There might be a rule active for a subfolder of "Plex". Could you check on the "Rules" tab if there might be another rule that overrides the general "Plex" one? On the "Settings" tab, have you checked "Balancing plug-ins respect file placement rules."?
-
There is nothing wrong with your new drive. A combination of 2x8 TB + 1x16 TB is fine, DrivePool just has to shuffle the files around a bit in the background, so that the first copy of all files are on the 16 TB and the other copy on the 8 TB drives. Or, in case of unduplicated files, that they are equally spread amongst those two. This will take a while. Make sure that the Duplication Space Optimizer is enabled (low priority is fine). It will take care of that during the next balancing runs. You can also force remeasuring and rebalancing via the menu / arrow if you want it to start immediately.
-
Well, from my personal history: When I switched from 2xSSD in a Windows Storage Space to the same SSDs in a DrivePool I actually perceived a *really* noticable degradation in some edge cases. I had my development folder on that pool and suddenly some disk-intensive self-written Python programs took multiple times longer than before to initially read their data (hundreds of files with some GB total) from the disk. Unfortunately I don't have any numbers on that specific thing. But I just did some new checks for you (conclusion/tldr at the bottom): Test 1: Everything is done with In theory, if DrivePool had no performance impact, there should be no difference between all test cases. Test 1a: Drive R: = 10 GB test partition on a ADATA SX900 SSD Test 1b: Drive G: = DrivePool consisting of just the partition R. Test 1c: Drive G: = DrivePool consisting of the partition R AND an empty 300 GB partition on a much faster Kingston SKC1000 NVM SSD, but with the latter being disabled for use in pool by the drive usage limiter balancer. (Why test 1c? - To see if the managment overhead of having two SSDs in the same pool has an impact, with the data actually still written on the same drive as in test 1b.) While there is a degradation noticable in random access reads and writes when switching from the bare SSD to a pool with that SSD (and optionally other SSDs), the performance drop is almost non-existent. I was a bit puzzled how I experienced the performance drop on my development folder when I originally switched to DrivePool. So I did another test with an additional HDD in my test pool, but again, which was disabled via balancing settings. Just to see if it makes an impact when having SSD and HDD mixed in a pool. The results were about the same. I then discovered that CrystalDiskMark does all the benchmarking via a single large file, so the overhead of managing files over various disks might not really be tested there. So I decided to just do another real-world test with data I know. Test 2: CRC32 calculation via 7zip of 12231 files in 1701 folders with an overall size of 6.38 GB, with Windows read cache flushed before each test. Test 2a: Drive R: = 10 GB test partition on a ADATA SX900 SSD: Total time: 25 seconds Test 2b: DrivePool consisting of just the partition R: Total time: 42 seconds Test 2c: DrivePool consisting of the partition R AND an empty 300 GB partition on a much faster Kingston SKC1000 NVM SSD, but with the latter being disabled for use in pool by the drive usage limiter balancer: Total time: 42 seconds Test 2d: DrivePool consisting of the partition R AND an empty 300 GB partition on a much faster Kingston SKC1000 NVM SSD AND an empty 5 GB partition of a Seagate ST2000DM005 HDD, but with the latter two being disabled for use in pool by the drive usage limiter balancer: Total time: 43 seconds Test 2e: DrivePool consisting of the partition R AND my 80% filled Samsung SSD 850 Pro 500 GB software partition , but with the latter being disabled for use in pool by the drive usage limiter balancer: Total time: 43 seconds Test 2f: The same files on another partition on the same disk (ADATA SX900) as part of my real in-use DrivePool consisting of 2 SSDs and few HDDs with a total of ~2 TB of mixed size data: Total time: 46 seconds --------------------------------------------------- Conclusion: With my little test setup, the time to process (read) many small files is roughly doubled if they are accessed via a drive pool (Test 2). For larger files the performance was roughly comparable with and without drive pool, regardless if sequential or random access (Test 1).
-
I'm using Everything with DrivePool actually. Basically you have 3 choices: 1) You either can go the slow way and add your pool drive letter as a generic "folder" to the DB, which will work as expected but be very slow on indexing. 2) You can directly index ALL of the base drives of your pool, which will index very fast because NTFS-Journal can be used, but it will lead to duplicate entries for all your duplicated files with different (base drive) paths. Also, you shouldn't fiddle around with the files at the base drive paths because it will circumvent drive pool from working properly (DrivePool is the only one meant to handle the files directly on the pool's base drives). 3) Or you can use a technique mentioned here in order to make Everything scan the base drives but output the file with the pool's path. You will also get duplicate entries for duplicate files, but they will both have the expected pool drive letter path and you can also actually work with them (e.g. delete them from context menu) right in Everything. I use method 2 and 3 in conjunction, which makes each duplicated file appear 4 times in Everything (), but this way I can see which file is duplicated onto which base drive, and I can also work with the files on the pool drive letter (V: in my case) right from within Everything: Here I searched for one specific file "testprojekt" on a pool with 2x duplication, which is shown on the pool's path (V:) via method 3 as well as on the two base drives path where the duplicated files physically lie around via method 2. I did this with Everything 1.4. There may even be new possibilities for more easily achieving method 3 with Everything 1.5, without having to deal with cryptic semicolon-separated config files: Community member klepp has had some discussion here with David from voidtools. Anyway, I didn't read through it since my solution works well at the moment.

-
Ah, ok, I guess you must have cloud enabled/connected for it to appear. Here is how it looks for me: v2.3.0.1385
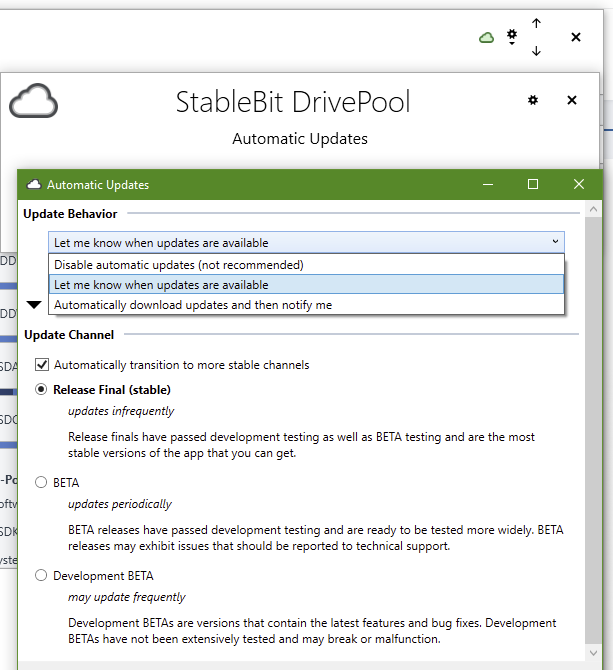
-
In the main window, in the upper right, click the gear icon -> Updates... -> gear icon. The settings there are quite detailed and have descriptive names. I guess this will answer your question.
-
Hi klepp So my thoughts on this: This will only affect balancers which do trigger immediate balancing. The most prominent being "StableBit Sanner" balancer, which allows immediate evacuation of damaged drives once a defect/smart error is found. Otherwise, the evacuation would have to wait until the next scheduled balancing pass, so, eternally, in your case. If you plan to use StableBit scanner in conjunction with DrivePool eventually, you should check it. -> Only relevant if you actually use "File Placement" rules (rules per folder). "real-time file placement limits" are constraints on where to place NEW files, at the moment of creating/moving them to the pool. If you check this, all balancers which use "real-time file placement limits", e.g. StableBit Scanner, SSD optimizer, Drive Usage Limiter, will take precedence over per-folder file placement rules. Otherwise, per-folder file placement rules will override those limits, allowing files to be placed e.g. on defective drives (Scanner plugin), or drives other than the SSD cache drive (SSD optimizer) if you have respective rules set up. I guess you want to check this one, if you want no files to be placed on drives flagged as defective by scanner. Btw., you can see the kind of balancing rules active in the disk view. For example, "real time file placement limiters" (restrictions for placing NEW files) are shown as red markers: (in this example, new files will not be placed on F) While normal balacing targets (targeted disk usage for moving EXISTING files around) are shown in blue: (in this example, triggering a balancing pass will move files away from F until target is reached) https://stablebit.com/Support/DrivePool/2.X/Manual?Section=Disks List#Balancing Markers -> Only relevant if you actually use "File Placement" rules (rules per folder). Same as "2 - File placement rules respect real-time file placement...", but for existing files rather than new ones. You basically decide if you have set a file placement rule for folder X to reside on drive X, but some balancer plugin says X should go on drive Y, which one takes precedence. But I'm unsure here (@Christopher (Drashna) ?), if this option a) only becomes important once there is no other solution to solve a balancing conflict, in the meaning of that balancers will care for file placement rules "if possible" even if this box is unchecked, or if they will b) completely ignore file placement rules if this box is unchecked, even if there were solutions that satisfy both parties. I would have it checked. If you have manual per-folder file placement rules, you probably have them for a reason, so you want balancers stick to them, too. (especially blunt, sweeping ones like "Disk Space Equalizer" or "Volume Equalization"). -> Only relevant if you actually use "File Placement" rules (rules per folder). A subcase of "Balancing plug-ins respect file placement..."). You should have this one checked. If you're emptying your drive because of ... Removing it via the GUI Evacuating a drive because of scanner alert ...you problably don't want any files to be left on it, even if it goes against your per-folder file placement rules. You want the scanner plugin to be first. Otherwise, files will be placed on defective drives because Scanner plugin rules are overriden by other balancers. (the top one has the last word)
-
restoring a backup image seems to blow cloud drives to pieces
Jonibhoni replied to klepp0906's topic in Nuts & Bolts
Hmm. I'm curious: What kind of IO errors? Was it a problem with reading the data from the cache drive? Or was it a problem retrieving the data from the cloud? Did you take a screenshot or something of those messages? I guess both shouldn't happen. In the Manage Drive menu there is an option Data integrity -> Upload verification. If you enable this, then each data uploaded will be immediately downloaded again to check whether it was stored correctly at your cloud provider. Of course this eats twice the bandwith, but at least you will immediately be aware of corruption with your cloud data, the connection or something, right at upload time. Think about enabling it for testing purposes. -
@Christopher (Drashna) Correct me if I am wrong, but wouldn't that break the drive? As far as I understood it, klepp meant to move the chunk/data files from the old cache drive and/or from the cloud drive's Dropbox folder (StableBit CloudDrive Data (xxx-xxx-xxx-xxx)) to the new one. But the data/chunk files are not compatible with a new chunk/sector size, of course, so this would break the drive. The described procedure works for DrivePools, because they store files natively, but not for CloudDrives. For changing the technical guts of your cloud drive you have to create a new drive, and then just regularly move/sync your files from the mounted old cloud drive to the new one (afaik). Mind by the way, that you can easily expand the drive's volume size just via the GUI. You wouldn't need to fiddle with the chunk size nor copy your data anywhere just to increase the drive's overall size. Chunk size and sector size are technical parameters how the data is stored behind the scenes, but independent of your cloud drive's volume size.
-
Yes, you can access it and force attach it in case the other computer will not access it anymore. I think the license doesn't matter in this case. Your license is just about how many computer you can run CloudDrive on; it's independent from the number of providers or cloud drives at a certain provider or logins or whatever. If you connect to any provider that has cloud drives on it (from any computer, from any license), you will see what StableBit cloud drives exactly are at that location. And then it's up to you which one to attach to, detach from, or force attach, in case of disaster. Read this section of the manual and especially take a look at the screenshots, I think they will give you the impression you need: https://stablebit.com/Support/CloudDrive/Manual?Section=Reattaching your Drive
