Search the Community
Showing results for tags 'bug'.
Found 13 results
-
I am using StableBit DrivePool and noticed that I am getting file corruption that is somewhat reproducible. I particularly noticed this with FLAC files as I was attempting to verify my library of music using flac -t which checks the MD5 signature of the decoded WAV file. My setup is DrivePool with Folder Duplication enabled on specific folders, "Bypass filesystem Filters" checked, "Read striping" checked and "Real-time duplication checked". Note that it appears to be "Read striping" that is the culprit for this but I am not 100% sure. Particularly concerning to me is that this happens even with "Verify after copy" checked. Steps for me to reproduce are to download a FLAC to a DrivePool location that matches the above parameters, verify it with flac -t (ensure that it verifies OK), copy the file to a different location (doesn't even have to be a DrivePool location), verify this copied file with flac -t and see that the file does not verify anymore. Checking with a hex editor, I can see it's not even just 1 byte difference, usually something like the first 32kb is fine, then I get random jumbled up data for a 128kb or so then the remainder of the file is correct (and the file size is correct). Here's something I would never expect to see in a working filesystem: PS F:\test\> flac -t .\test.flac flac 1.3.2 Copyright (C) 2000-2009 Josh Coalson, 2011-2016 Xiph.Org Foundation flac comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to redistribute it under certain conditions. Type `flac' for details. test.flac: ok PS F:\test\> copy .\test.flac test2.flac PS F:\test\> flac -t .\test2.flac flac 1.3.2 Copyright (C) 2000-2009 Josh Coalson, 2011-2016 Xiph.Org Foundation flac comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to redistribute it under certain conditions. Type `flac' for details. test2.flac: *** Got error code 2:FLAC__STREAM_DECODER_ERROR_STATUS_FRAME_CRC_MISMATCH test2.flac: ERROR while decoding data state = FLAC__STREAM_DECODER_ABORTED Edit: It seems I am not the only one running into this problem, see this recent Reddit thread:
-
 To start, while new to DrivePool I love its potential I own multiple licenses and their full suite. If you only use drivepool for basic file archiving of large files with simple applications accessing them for periodic reads it is probably uncommon you would hit these bugs. This assumes you don't use any file synchronization / backup solutions. Further, I don't know how many thousands (tens or hundreds?) of DrivePool users there are, but clearly many are not hitting these bugs or recognizing they are hitting these bugs, so this IT NOT some new destructive my files are 100% going to die issue. Some of the reports I have seen on the forums though may be actually issues due to these things without it being recognized as such. As far as I know previously CoveCube was not aware of these issues, so tickets may not have even considered this possibility. I started reporting these bugs to StableBit ~9 months ago, and informed I would be putting this post together ~1 month ago. Please see the disclaimer below as well, as some of this is based on observations over known facts. You are most likely to run into these bugs with applications that: *) Synchronize or backup files, including cloud mounted drives like onedrive or dropbox *) Applications that must handle large quantities of files or monitor them for changes like coding applications (Visual Studio/ VSCode) Still, these bugs can cause silent file corruption, file misplacement, deleted files, performance degradation, data leakage ( a file shared with someone externally could have its contents overwritten by any sensitive file on your computer), missed file changes, and potential other issues for a small portion of users (I have had nearly all these things occur). It may also trigger some BSOD crashes, I had one such crash that is likely related. Due to the subtle nature some of these bugs can present with, it may be hard to notice they are happening even if they are. In addition, these issues can occur even without file mirroring and files pinned to a specific drive. I do have some potential workarounds/suggestions at the bottom. More details are at the bottom but the important bug facts upfront: Windows has a native file changed notification API using overlapped IO calls. This allows an application to listen for changes on a folder, or a folder and sub folders, without having to constantly check every file to see if it changed. Stablebit triggers "file changed" notifications even when files are just accessed (read) in certain ways. Stablebit does NOT generate notification events on the parent folder when a file under it changes (Windows does). Stablebit does NOT generate a notification event only when a FileID changes (next bug talks about FileIDs). Windows, like linux, has a unique ID number for each file written on the hard drive. If there are hardlinks to the same file, it has the same unique ID (so one File ID may have multiple paths associated with it). In linux this is called the inode number, Windows calls it the FileID. Rather than accessing a file by its path, you can open a file by its FileID. In addition it is impossible for two files to share the same FileID, it is a 128 bit number persistent across reboots (128 bits means the number of unique numbers represented is 39 digits long, or has the uniqueness of something like the MD5 hash). A FileID does not change when a file moves or is modified. Stablebit, by default, supports FileIDs however they seem to be ephemeral, they do not seem to survive across reboots or file moves. Keep in mind FileIDs are used for directories as well, it is not just files. Further, if a directory is moved/renamed not only does its FileID change but every file under it changes. I am not sure if there are other situations in which they may change. In addition, if a descendant file/directory FileID changes due to something like a directory rename Stablebit does NOT generate a notification event that it has changed (the application gets the directory event notification but nothing on the children). There are some other things to consider as well, DrivePool does not implement the standard windows USN Journal (a system of tracking file changes on a drive). It specifically identifies itself as not supporting this so applications shouldn't be trying to use it with a drivepool drive. That does mean that applications that traditionally don't use the file change notification API or the FileIDs may fall back to a combination of those to accomplish what they would otherwise use the USN Journal for (and this can exacerbate the problem). The same is true of Volume Shadow Copy (VSS) where applications that might traditionally use this cannot (and drivepool identifies it cannot do VSS) so may resort to methods below that they do not traditionally use. Now the effects of the above bugs may not be completely apparent: For the overlapped IO / File change notification This means an application monitoring for changes on a DrivePool folder or sub-folder will get erroneous notifications files changed when anything even accesses them. Just opening something like file explorer on a folder, or even switching between applications can cause file accesses that trigger the notification. If an application takes actions on a notification and then checks the file at the end of the notification this in itself may cause another notification. Applications that rely on getting a folder changed notification when a child changes will not get these at all with DrivePool. If it isn't monitoring children at all just the folder, this means no notifications could be generated (vs just the child) so it could miss changes. For FileIDs It depends what the application uses the FileID for but it may assume the FileID should stay the same when a file moves, as it doesn't with DrivePool this might mean it reads or backs up, or syncs the entire file again if it is moved (perf issue). An application that uses the Windows API to open a File by its ID may not get the file it is expecting or the file that was simply moved will throw an error when opened by its old FileID as drivepool has changed the ID. For an example lets say an application caches that the FileID for ImportantDoc1.docx is 12345 but then 12345 refers to ImportantDoc2.docx due to a restart. If this application is a file sync application and ImportantDoc1.docx is changed remotely when it goes to write those remote changes to the local file if it uses the OpenFileById method to do so it will actually override ImportantDoc2.docx with those changes. I didn't spend the time to read Windows file system requirements to know when Windows expects a FileID to potentially change (or not change). It is important to note that even if theoretical changes/reuse are allowed if they are not common place (because windows uses essentially a number like an md5 hash in terms of repeats) applications may just assume it doesn't happen even if it is technically allowed to do so. A backup of file sync program might assume that a file with specific FileID is always the same file, if FileID 12345 is c:\MyDocuments\ImportantDoc1.docx one day and then c:\MyDocuments\ImportantDoc2.docx another it may mistake document 2 for document 1, overriding important data or restore data to the wrong place. If it is trying to create a whole drive backup it may assume it has already backed up c:\MyDocuments\ImportantDoc2.docx if it now has the same File ID as ImportantDoc1.docx by the time it reaches it (at which point DrivePool would have a different FileID for Document1). Why might applications use FileIDs or file change notifiers? It may not seem intuitive why applications would use these but a few major reasons are: *) Performance, file change notifiers are a event/push based system so the application is told when something changes, the common alternative is a poll based system where an application must scan all the files looking for changes (and may try to rely on file timestamps or even hashing the entire file to determine this) this causes a good bit more overhead / slowdown. *) FileID's are nice because they already handle hardlink file de-duplication (Windows may have multiple copies of a file on a drive for various reasons, but if you backup based on FileID you backup that file once rather than multiple times. FileIDs are also great for handling renames. Lets say you are an application that syncs files and the user backs up c:\temp\mydir with 1000 files under it. If they rename c:\temp\mydir to c:\temp\mydir2 an application use FileIDS can say, wait that folder is the same it was just renamed. OK rename that folder in our remote version too. This is a very minimal operation on both ends. With DrivePool however the FileID changes for the directory and all sub-files. If the sync application uses this to determine changes it now uploads all these files to the system using a good bit more resources locally and remotely. If the application also uses versioning this may be far more likely to cause a conflict with two or more clients syncing, as mass amounts of files are seemingly being changed. Finally, even if an application is trying to monitor for FileIDs changing using the file change API, due to notification bugs above it may not get any notifications when child FileIDs change so it might assume it has not. Real Examples OneDrive This started with massive onedrive failures. I would find onedrive was re-uploading hundreds of gigabytes of images an videos multiple times a week. These were not changing or moving. I don't know if the issue is onedrive uses FileIDs to determine if a file is already uploaded, or if it is because when it scanned a directory it may have triggered a notification that all the files in that directory changed and based on that notification it reuploads. After this I noticed files were becoming deleted both locally and in the cloud. I don't know what caused this, it might have been because the old file it thought was deleted as the FileID was gone and while there was a new file (actually the same file) in its place there may have been some odd race condition. It is also possible that it queued the file for upload, the FileID changed and when it went to open it to upload it found it was 'deleted' as the FileID no longer pointed to a file and queued the delete operation. I also found that files that were uploaded into the cloud in one folder were sometimes downloading to an alternate folder locally. I am guessing this is because the folder FileID changed. It thought the 2023 folder was with ID XYZ but that now pointed to a different folder and so it put the file in the wrong place. The final form of corruption was finding the data from one photo or video actually in a file with a completely different name. This is almost guaranteed to be due to the FileID bugs. This is highly destructive as backups make this far harder to correct. With one files contents replaced with another you need to know when the good content existed and in what files were effected. Depending on retention policies the file contents that replaced it may override the good backups before you notice. I also had a BSOD with onedrive where it was trying to set attributes on a file and the CoveFS driver corrupted some memory. It is possible this was a race condition as onedrive may have been doing hundreds of files very rapidly due to the bugs. I have not captured a second BSOD due to it, but also stopped using onedrive on DrivePool due to the corruption. Another example of this is data leakage. Lets say you share your favorite article on kittens with a group of people. Onedrive, believing that file has changed, goes to open it using the FileID however that file ID could essentially now correspond to any file on your computer now the contents of some sensitive file are put in the place of that kitten file, and everyone you shared it with can access it. Visual Studio Failures Visual studio is a code editor/compiler. There are three distinct bugs that happen. First, when compiling if you touched one file in a folder it seemed to recompile the entire folder, this due likely to the notification bug. This is just a slow down, but an annoying one. Second, Visual Studio has compiler generated code support. This means the compiler will generate actual source code that lives next to your own source code. Normally once compiled it doesn't regenerate and compile this source unless it must change but due to the notification bugs it regenerates this code constantly and if there is an error in other code it causes an error there causing several other invalid errors. When debugging visual studio by default will only use symbols (debug location data) as the notifications from DrivePool happen on certain file accesses visual studio constantly thinks the source has changed since it was compiled and you will only be able to breakpoint inside source if you disable the exact symbol match default. If you have multiple projects in a solution with one dependent on another it will often rebuild other project deps even when they haven't changed, for large solutions that can be crippling (perf issue). Finally I often had intellisense errors showing up even though no errors during compiling, and worse intellisense would completely break at points. All due to DrivePool. Technical details / full background & disclaimer I have sample code and logs to document these issues in greater detail if anyone wants to replicate it themselves. It is important for me to state drivepool is closed source and I don't have the technical details of how it works. I also don't have the technical details on how applications like onedrive or visual studio work. So some of these things may be guesses as to why the applications fail/etc. The facts stated are true (to the best of my knowledge) Shortly before my trial expired in October of last year I discovered some odd behavior. I had a technical ticket filed within a week and within a month had traced down at least one of the bugs. The issue can be seen https://stablebit.com/Admin/IssueAnalysis/28720 , it does show priority 2/important which I would assume is the second highest (probably critical or similar above). It is great it has priority but as we are over 6 months since filed without updates I figured warning others about the potential corruption was important. The FileSystemWatcher API is implemented in windows using async overlapped IO the exact code can be seen: https://github.com/dotnet/runtime/blob/57bfe474518ab5b7cfe6bf7424a79ce3af9d6657/src/libraries/System.IO.FileSystem.Watcher/src/System/IO/FileSystemWatcher.Win32.cs#L32-L66 That corresponds to this kernel api: https://learn.microsoft.com/en-us/windows/win32/fileio/synchronous-and-asynchronous-i-o Newer api calls use GetFileInformationByHandleEx to get the FileID but with older stats calls represented by nFileIndexHigh/nFileIndexLow. In terms of the FileID bug I wouldn't normally have even thought about it but the advanced config (https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings) mentions this under CoveFs_OpenByFileId "When enabled, the pool will keep track of every file ID that it gives out in pageable memory (memory that is saved to disk and loaded as necessary).". Keeping track of files in memory is certainly very different from Windows so I thought this may be the source of issue. I also don't know if there are caps on the maximum number of files it will track as if it resets FileIDs in situations other than reboots that could be much worse. Turning this off will atleast break nfs servers as it mentions it right in the docs "required by the NFS server". Finally, the FileID numbers given out by DrivePool are incremental and very low. This means when they do reset you almost certainly will get collisions with former numbers. What is not clear is if there is the chance of potential FileID corruption issues. If when it is assigning these ids in a multi-threaded scenario with many different files at the same time could this system fail? I have seen no proof this happens, but when incremental ids are assigned like this for mass quantities of potential files it has a higher chance of occurring. Microsoft mentions this about deleting the USN Journal: "Deleting the change journal impacts the File Replication Service (FRS) and the Indexing Service, because it requires these services to perform a complete (and time-consuming) scan of the volume. This in turn negatively impacts FRS SYSVOL replication and replication between DFS link alternates while the volume is being rescanned.". Now DrivePool never has the USN journal supported so it isn't exactly the same thing, but it is clear that several core Windows services do use it for normal operations I do not know what backups they use when it is unavailable. Potential Fixes There are advanced settings for drivepool https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings beware these changes may break other things. CoveFs_OpenByFileId - Set to false, by default it is true. This will disable the OpenByFileID API. It is clear several applications use this API. In addition, while DrivePool may disable that function with this setting it doesn't disable FileID's themselves. Any application using FileIDs as static identifiers for files may still run into problems. I would avoid any file backup/synchronization tools and DrivePool drives (if possible). These likely have the highest chance of lost files, misplaced files, file content being mixed up, and excess resource usage. If not avoiding consider taking file hashes for the entire drivepool directory tree. Do this again at a later point and make sure files that shouldn't have changed still have the same hash. If you have files that rarely change after being created then hashing each file at some point after creation and alerting if that file disappears or hash changes would easily act as an early warning to a bug here being hit.
To start, while new to DrivePool I love its potential I own multiple licenses and their full suite. If you only use drivepool for basic file archiving of large files with simple applications accessing them for periodic reads it is probably uncommon you would hit these bugs. This assumes you don't use any file synchronization / backup solutions. Further, I don't know how many thousands (tens or hundreds?) of DrivePool users there are, but clearly many are not hitting these bugs or recognizing they are hitting these bugs, so this IT NOT some new destructive my files are 100% going to die issue. Some of the reports I have seen on the forums though may be actually issues due to these things without it being recognized as such. As far as I know previously CoveCube was not aware of these issues, so tickets may not have even considered this possibility. I started reporting these bugs to StableBit ~9 months ago, and informed I would be putting this post together ~1 month ago. Please see the disclaimer below as well, as some of this is based on observations over known facts. You are most likely to run into these bugs with applications that: *) Synchronize or backup files, including cloud mounted drives like onedrive or dropbox *) Applications that must handle large quantities of files or monitor them for changes like coding applications (Visual Studio/ VSCode) Still, these bugs can cause silent file corruption, file misplacement, deleted files, performance degradation, data leakage ( a file shared with someone externally could have its contents overwritten by any sensitive file on your computer), missed file changes, and potential other issues for a small portion of users (I have had nearly all these things occur). It may also trigger some BSOD crashes, I had one such crash that is likely related. Due to the subtle nature some of these bugs can present with, it may be hard to notice they are happening even if they are. In addition, these issues can occur even without file mirroring and files pinned to a specific drive. I do have some potential workarounds/suggestions at the bottom. More details are at the bottom but the important bug facts upfront: Windows has a native file changed notification API using overlapped IO calls. This allows an application to listen for changes on a folder, or a folder and sub folders, without having to constantly check every file to see if it changed. Stablebit triggers "file changed" notifications even when files are just accessed (read) in certain ways. Stablebit does NOT generate notification events on the parent folder when a file under it changes (Windows does). Stablebit does NOT generate a notification event only when a FileID changes (next bug talks about FileIDs). Windows, like linux, has a unique ID number for each file written on the hard drive. If there are hardlinks to the same file, it has the same unique ID (so one File ID may have multiple paths associated with it). In linux this is called the inode number, Windows calls it the FileID. Rather than accessing a file by its path, you can open a file by its FileID. In addition it is impossible for two files to share the same FileID, it is a 128 bit number persistent across reboots (128 bits means the number of unique numbers represented is 39 digits long, or has the uniqueness of something like the MD5 hash). A FileID does not change when a file moves or is modified. Stablebit, by default, supports FileIDs however they seem to be ephemeral, they do not seem to survive across reboots or file moves. Keep in mind FileIDs are used for directories as well, it is not just files. Further, if a directory is moved/renamed not only does its FileID change but every file under it changes. I am not sure if there are other situations in which they may change. In addition, if a descendant file/directory FileID changes due to something like a directory rename Stablebit does NOT generate a notification event that it has changed (the application gets the directory event notification but nothing on the children). There are some other things to consider as well, DrivePool does not implement the standard windows USN Journal (a system of tracking file changes on a drive). It specifically identifies itself as not supporting this so applications shouldn't be trying to use it with a drivepool drive. That does mean that applications that traditionally don't use the file change notification API or the FileIDs may fall back to a combination of those to accomplish what they would otherwise use the USN Journal for (and this can exacerbate the problem). The same is true of Volume Shadow Copy (VSS) where applications that might traditionally use this cannot (and drivepool identifies it cannot do VSS) so may resort to methods below that they do not traditionally use. Now the effects of the above bugs may not be completely apparent: For the overlapped IO / File change notification This means an application monitoring for changes on a DrivePool folder or sub-folder will get erroneous notifications files changed when anything even accesses them. Just opening something like file explorer on a folder, or even switching between applications can cause file accesses that trigger the notification. If an application takes actions on a notification and then checks the file at the end of the notification this in itself may cause another notification. Applications that rely on getting a folder changed notification when a child changes will not get these at all with DrivePool. If it isn't monitoring children at all just the folder, this means no notifications could be generated (vs just the child) so it could miss changes. For FileIDs It depends what the application uses the FileID for but it may assume the FileID should stay the same when a file moves, as it doesn't with DrivePool this might mean it reads or backs up, or syncs the entire file again if it is moved (perf issue). An application that uses the Windows API to open a File by its ID may not get the file it is expecting or the file that was simply moved will throw an error when opened by its old FileID as drivepool has changed the ID. For an example lets say an application caches that the FileID for ImportantDoc1.docx is 12345 but then 12345 refers to ImportantDoc2.docx due to a restart. If this application is a file sync application and ImportantDoc1.docx is changed remotely when it goes to write those remote changes to the local file if it uses the OpenFileById method to do so it will actually override ImportantDoc2.docx with those changes. I didn't spend the time to read Windows file system requirements to know when Windows expects a FileID to potentially change (or not change). It is important to note that even if theoretical changes/reuse are allowed if they are not common place (because windows uses essentially a number like an md5 hash in terms of repeats) applications may just assume it doesn't happen even if it is technically allowed to do so. A backup of file sync program might assume that a file with specific FileID is always the same file, if FileID 12345 is c:\MyDocuments\ImportantDoc1.docx one day and then c:\MyDocuments\ImportantDoc2.docx another it may mistake document 2 for document 1, overriding important data or restore data to the wrong place. If it is trying to create a whole drive backup it may assume it has already backed up c:\MyDocuments\ImportantDoc2.docx if it now has the same File ID as ImportantDoc1.docx by the time it reaches it (at which point DrivePool would have a different FileID for Document1). Why might applications use FileIDs or file change notifiers? It may not seem intuitive why applications would use these but a few major reasons are: *) Performance, file change notifiers are a event/push based system so the application is told when something changes, the common alternative is a poll based system where an application must scan all the files looking for changes (and may try to rely on file timestamps or even hashing the entire file to determine this) this causes a good bit more overhead / slowdown. *) FileID's are nice because they already handle hardlink file de-duplication (Windows may have multiple copies of a file on a drive for various reasons, but if you backup based on FileID you backup that file once rather than multiple times. FileIDs are also great for handling renames. Lets say you are an application that syncs files and the user backs up c:\temp\mydir with 1000 files under it. If they rename c:\temp\mydir to c:\temp\mydir2 an application use FileIDS can say, wait that folder is the same it was just renamed. OK rename that folder in our remote version too. This is a very minimal operation on both ends. With DrivePool however the FileID changes for the directory and all sub-files. If the sync application uses this to determine changes it now uploads all these files to the system using a good bit more resources locally and remotely. If the application also uses versioning this may be far more likely to cause a conflict with two or more clients syncing, as mass amounts of files are seemingly being changed. Finally, even if an application is trying to monitor for FileIDs changing using the file change API, due to notification bugs above it may not get any notifications when child FileIDs change so it might assume it has not. Real Examples OneDrive This started with massive onedrive failures. I would find onedrive was re-uploading hundreds of gigabytes of images an videos multiple times a week. These were not changing or moving. I don't know if the issue is onedrive uses FileIDs to determine if a file is already uploaded, or if it is because when it scanned a directory it may have triggered a notification that all the files in that directory changed and based on that notification it reuploads. After this I noticed files were becoming deleted both locally and in the cloud. I don't know what caused this, it might have been because the old file it thought was deleted as the FileID was gone and while there was a new file (actually the same file) in its place there may have been some odd race condition. It is also possible that it queued the file for upload, the FileID changed and when it went to open it to upload it found it was 'deleted' as the FileID no longer pointed to a file and queued the delete operation. I also found that files that were uploaded into the cloud in one folder were sometimes downloading to an alternate folder locally. I am guessing this is because the folder FileID changed. It thought the 2023 folder was with ID XYZ but that now pointed to a different folder and so it put the file in the wrong place. The final form of corruption was finding the data from one photo or video actually in a file with a completely different name. This is almost guaranteed to be due to the FileID bugs. This is highly destructive as backups make this far harder to correct. With one files contents replaced with another you need to know when the good content existed and in what files were effected. Depending on retention policies the file contents that replaced it may override the good backups before you notice. I also had a BSOD with onedrive where it was trying to set attributes on a file and the CoveFS driver corrupted some memory. It is possible this was a race condition as onedrive may have been doing hundreds of files very rapidly due to the bugs. I have not captured a second BSOD due to it, but also stopped using onedrive on DrivePool due to the corruption. Another example of this is data leakage. Lets say you share your favorite article on kittens with a group of people. Onedrive, believing that file has changed, goes to open it using the FileID however that file ID could essentially now correspond to any file on your computer now the contents of some sensitive file are put in the place of that kitten file, and everyone you shared it with can access it. Visual Studio Failures Visual studio is a code editor/compiler. There are three distinct bugs that happen. First, when compiling if you touched one file in a folder it seemed to recompile the entire folder, this due likely to the notification bug. This is just a slow down, but an annoying one. Second, Visual Studio has compiler generated code support. This means the compiler will generate actual source code that lives next to your own source code. Normally once compiled it doesn't regenerate and compile this source unless it must change but due to the notification bugs it regenerates this code constantly and if there is an error in other code it causes an error there causing several other invalid errors. When debugging visual studio by default will only use symbols (debug location data) as the notifications from DrivePool happen on certain file accesses visual studio constantly thinks the source has changed since it was compiled and you will only be able to breakpoint inside source if you disable the exact symbol match default. If you have multiple projects in a solution with one dependent on another it will often rebuild other project deps even when they haven't changed, for large solutions that can be crippling (perf issue). Finally I often had intellisense errors showing up even though no errors during compiling, and worse intellisense would completely break at points. All due to DrivePool. Technical details / full background & disclaimer I have sample code and logs to document these issues in greater detail if anyone wants to replicate it themselves. It is important for me to state drivepool is closed source and I don't have the technical details of how it works. I also don't have the technical details on how applications like onedrive or visual studio work. So some of these things may be guesses as to why the applications fail/etc. The facts stated are true (to the best of my knowledge) Shortly before my trial expired in October of last year I discovered some odd behavior. I had a technical ticket filed within a week and within a month had traced down at least one of the bugs. The issue can be seen https://stablebit.com/Admin/IssueAnalysis/28720 , it does show priority 2/important which I would assume is the second highest (probably critical or similar above). It is great it has priority but as we are over 6 months since filed without updates I figured warning others about the potential corruption was important. The FileSystemWatcher API is implemented in windows using async overlapped IO the exact code can be seen: https://github.com/dotnet/runtime/blob/57bfe474518ab5b7cfe6bf7424a79ce3af9d6657/src/libraries/System.IO.FileSystem.Watcher/src/System/IO/FileSystemWatcher.Win32.cs#L32-L66 That corresponds to this kernel api: https://learn.microsoft.com/en-us/windows/win32/fileio/synchronous-and-asynchronous-i-o Newer api calls use GetFileInformationByHandleEx to get the FileID but with older stats calls represented by nFileIndexHigh/nFileIndexLow. In terms of the FileID bug I wouldn't normally have even thought about it but the advanced config (https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings) mentions this under CoveFs_OpenByFileId "When enabled, the pool will keep track of every file ID that it gives out in pageable memory (memory that is saved to disk and loaded as necessary).". Keeping track of files in memory is certainly very different from Windows so I thought this may be the source of issue. I also don't know if there are caps on the maximum number of files it will track as if it resets FileIDs in situations other than reboots that could be much worse. Turning this off will atleast break nfs servers as it mentions it right in the docs "required by the NFS server". Finally, the FileID numbers given out by DrivePool are incremental and very low. This means when they do reset you almost certainly will get collisions with former numbers. What is not clear is if there is the chance of potential FileID corruption issues. If when it is assigning these ids in a multi-threaded scenario with many different files at the same time could this system fail? I have seen no proof this happens, but when incremental ids are assigned like this for mass quantities of potential files it has a higher chance of occurring. Microsoft mentions this about deleting the USN Journal: "Deleting the change journal impacts the File Replication Service (FRS) and the Indexing Service, because it requires these services to perform a complete (and time-consuming) scan of the volume. This in turn negatively impacts FRS SYSVOL replication and replication between DFS link alternates while the volume is being rescanned.". Now DrivePool never has the USN journal supported so it isn't exactly the same thing, but it is clear that several core Windows services do use it for normal operations I do not know what backups they use when it is unavailable. Potential Fixes There are advanced settings for drivepool https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings beware these changes may break other things. CoveFs_OpenByFileId - Set to false, by default it is true. This will disable the OpenByFileID API. It is clear several applications use this API. In addition, while DrivePool may disable that function with this setting it doesn't disable FileID's themselves. Any application using FileIDs as static identifiers for files may still run into problems. I would avoid any file backup/synchronization tools and DrivePool drives (if possible). These likely have the highest chance of lost files, misplaced files, file content being mixed up, and excess resource usage. If not avoiding consider taking file hashes for the entire drivepool directory tree. Do this again at a later point and make sure files that shouldn't have changed still have the same hash. If you have files that rarely change after being created then hashing each file at some point after creation and alerting if that file disappears or hash changes would easily act as an early warning to a bug here being hit. -
 New user here, I have a drivepool configured with 6 SSD's. I have duplication turned on. If I try to build a Rust (programming language) application, when build process fails, with windows error 5. This is a very weird issue, and I've been debugging this for hours now, before I realized that drivepool is most likely the problem, since the application builds correctly on any other drives which are not part of the DrivePool. It even works on the drives which are part of the pool, if I use them directly, circumventing the DrivePool layer. After some more debugging it turns out that the issue is connected to Read Striping. Having it on is what leads to the aforementioned errors. However I'd like to continue using Read Striping, because disabling it leads to quite a big performance loss. What can I do in this situation? Can I turn off Read Striping on a folder to folder basis? Maybe turn off duplication on this folder only so that DrivePool is forced to read from one drive? What could be the root issue here? Maybe the compiler is using memory mapped files which do not play along with DrivePool? What can I do to help you debug the root issue?
New user here, I have a drivepool configured with 6 SSD's. I have duplication turned on. If I try to build a Rust (programming language) application, when build process fails, with windows error 5. This is a very weird issue, and I've been debugging this for hours now, before I realized that drivepool is most likely the problem, since the application builds correctly on any other drives which are not part of the DrivePool. It even works on the drives which are part of the pool, if I use them directly, circumventing the DrivePool layer. After some more debugging it turns out that the issue is connected to Read Striping. Having it on is what leads to the aforementioned errors. However I'd like to continue using Read Striping, because disabling it leads to quite a big performance loss. What can I do in this situation? Can I turn off Read Striping on a folder to folder basis? Maybe turn off duplication on this folder only so that DrivePool is forced to read from one drive? What could be the root issue here? Maybe the compiler is using memory mapped files which do not play along with DrivePool? What can I do to help you debug the root issue? -
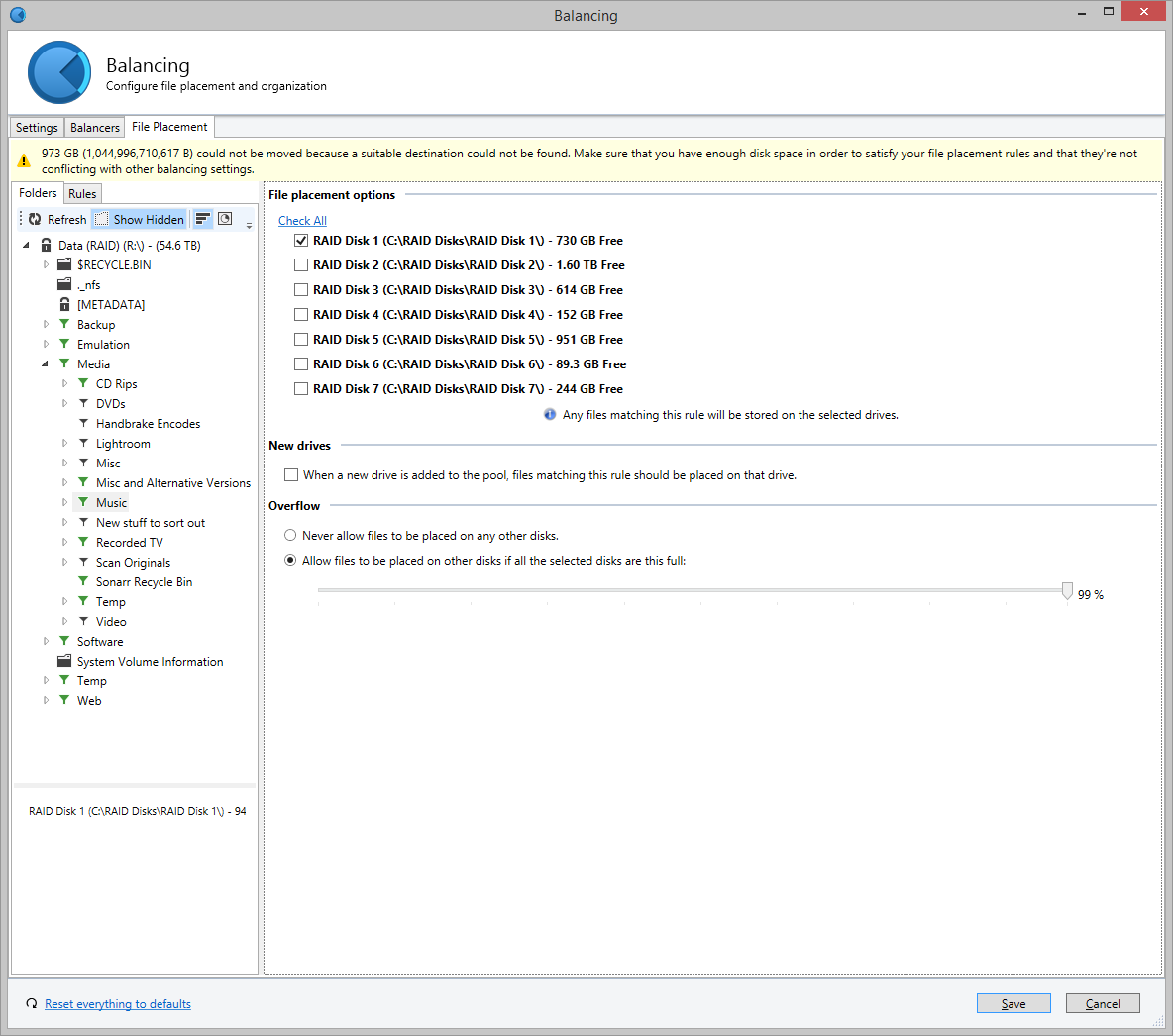
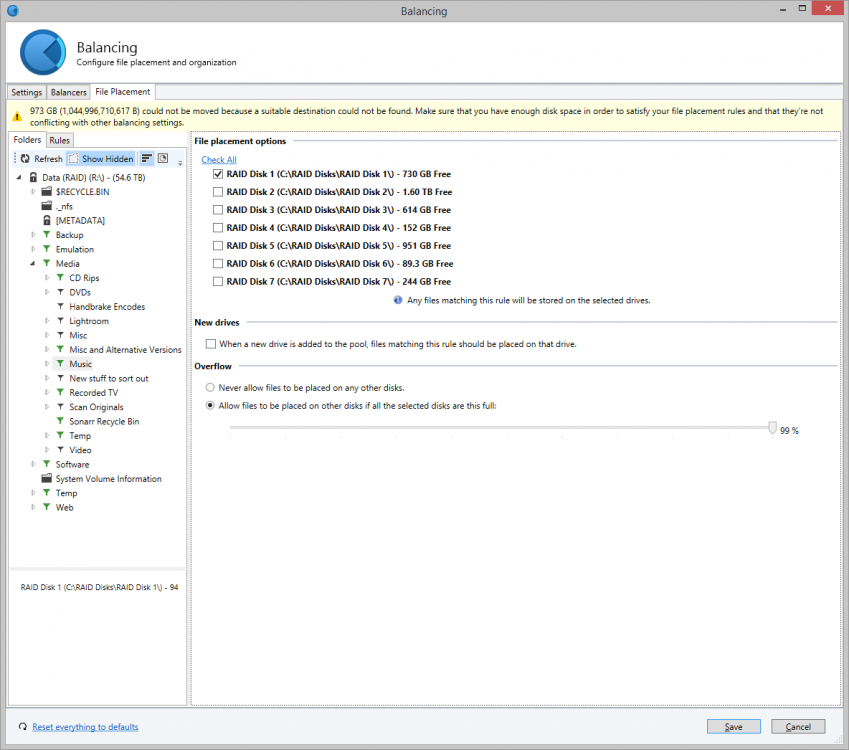
Hi there I've been using Drivepool for a couple of years now and it's been really stable and has generally great. However, I have noticed an issue over the past few months in relation to file watches. Specifically, in relation to Subsonic server that is running on my machine. The scenario is as follows: I have 7 data disks in my pool and most of my music collection is placed only on disk 1, as per a file-placement rule (see attached screenshot). Subsonic (which is a Java application) has code that keeps a watch on the filesystem so that when new music files are added into my music folder, it will automatically detect it, scan the files and add to my music libary. This was working fine, but I noticed that sometimes the files were never detected, even after I forced a scan. Long story short - because disk 1 was getting full, some music files were being placed onto disks 2 and 3 when I copied them to my pool drive. Subsonic a) didn't notice the new files and b) would not recognise the files as new even when I forced a scan. Now, my assumption was that the software used NTFS file watches to detect new files, but that doesn't explain why files are not detected on a forced scan, which I believe from looking at the code is based on file/folder last modified timestamps. If I manually move the music files from disks 2 or 3 on to disk 1, or clear up space so that the file placement rules move the files when I re-balance, then Subsonic detects the files. My hypothesis is that Drivepool isn't properly reporting timestamps or filewatch system events when files are placed on to disks that are not the one(s) chosen in file placement rules. It's taken months to work this out and I spent ages on the Subsonic forums (and talking to its developer) because I assumed that it was a problem with Subsonic. I've now conclusively (and repeatably) shown this is a Drivepool issue. Thanks, Steve. PS: I'm running Windows Server 2012R2 with all the latest updates. I have no AV installed at the moment (I got rid of it while testing this, just in case). I also use Snapraid for parity across my Drivepool disks, not that I expect that makes any difference!
-
I have been troubleshooting an issue with erratic timestamps when attempting to backup my pool using Bvckup2. Due to timestamps being different between the backup source and backup destination, files are needlessly copied, even though they are actually the same. Only a small percentage of files in my pool are affected, but some are huge (>50 GB) so this eats up backup disk space quickly. For some of these files, timestamps are incorrect but consistent. For other files, the timestamps change almost every time the file is accessed/queried. The Bvckup2 thread below contains all of my troubleshooting information so far, and a potentially related DrivePool bug thread is listed below. Bvckup2 Form Thread: https://bvckup2.com/support/forum/topic/1274 File Watch/Timestamps Unavailable:
-
I have two machines, both running clouddrive and drivepool. They're both configured in a similar way. One CloudDrive is split into multiple partitions formatted in NTFS, those partitions are joined by DrivePool, and the resulting pool is nested in yet another pool. Only this final pool is mounted via drive letter. One machine is running Windows Server 2012, the other is running Windows 10 (latest). I save a large video file (30GB+) onto the drive in the windows server machine. That drive is shared over the network and opened on the windows 10 machine. I then initiate a transfer on the Windows 10 machine of that video file from the network shared drive on the windows server machine to the drive mounted on the windows 10 machine. The transfer runs slower than expected for a while. Eventually, I get connection errors in clouddrive on the windows server machine, and soon after that the entire clouddrive becomes unallocated. This has happened twice now. I have a gigabit fiber connection, as well as gigabit networking throughout my LAN. I'm also using my own API keys for google drive (though I wasn't the first time around so it's happened both ways). Upload verification was on the first time, off the second time. Everything else about the drive configuration was the same. Edit: to be clear, this only affects the drive I'm trying to copy from, not the drive on the windows 10 machine I'm writing to (thank god because that's about 40TB of data).
-
Hi I' use the MS deduplication and DrivePool both since the beginning. I never had any major problem with them, aside some calculation glitches with older DP releases. Now I'm in troubles. The deduplication of Windows has changed a bit since the build 16299 or so. A disk previously deduplicated with Win10 or Win server 2016, after being touched by a recent W10/Server 1803/1809/Server 2019, will be silently upgraded and the deduped files become inaccessible by older incarnations. So downgrade/dual boot is not an option. DrivePool (I tested even the latest beta) will fight with the dedup filter and while DP itself still works, the deduplication does not. Before you ask, yes the option to skip the FS filter is correctly set, as usual, in my case This is what I get from powershell with a simple Get-dedupstatus (after DP installation and a reboot) This Is what I see in the deduplication section of event log Sorry messages are in Italian but I think are still pretty clear. So please fix DP asap to not ruin the good reputation of your product (and also to make my life easier ) P.S. FYI Drive Bender 2800 has the exact same behavior
-
 Hello. I ihink that I might have encountered a bug in DrivePool behavior when using torrent. Here shown on 5x1TB pool. When on disk (that is a part of Pool) is created a new file that reserve X amount of space in MFT but does not preallocate it, DrivePool adds that X amount of space to total space avaliable on this disk. DrivePool is reporting correct HDD capacity (931GB) but wrong volume (larger than possible on particular HDD). To be clear, that file is not created "outside" of pool and then moved onto it, it is created on virtual disk (in my case E:\Torrent\... ) on that HDD where DrivePool decide to put it. Reported capacity goes back to normal after deleting that file:
Hello. I ihink that I might have encountered a bug in DrivePool behavior when using torrent. Here shown on 5x1TB pool. When on disk (that is a part of Pool) is created a new file that reserve X amount of space in MFT but does not preallocate it, DrivePool adds that X amount of space to total space avaliable on this disk. DrivePool is reporting correct HDD capacity (931GB) but wrong volume (larger than possible on particular HDD). To be clear, that file is not created "outside" of pool and then moved onto it, it is created on virtual disk (in my case E:\Torrent\... ) on that HDD where DrivePool decide to put it. Reported capacity goes back to normal after deleting that file: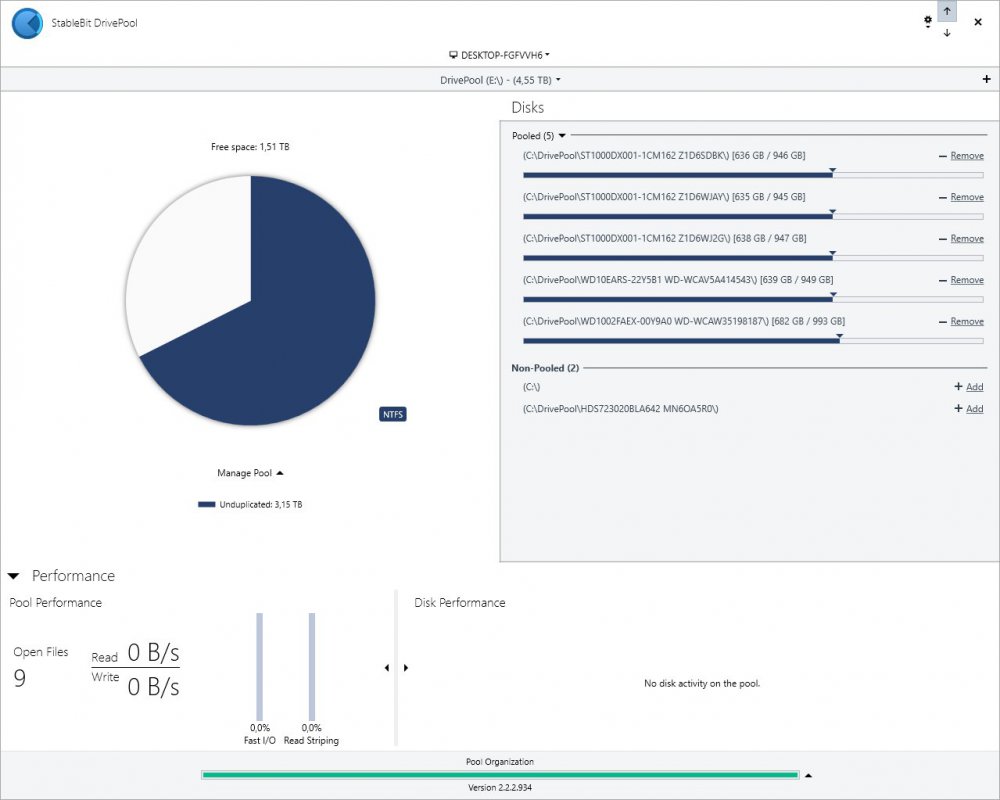



-
Hey Guys - For the past couple of months, I've had an issue which I found out today only occurs with network file shares that are on my drive pool. I am able to connect to these file shares just fine as well as read from them, however; if i try to write to them or edit a file within one, the workstation (system that hosts the share) immediately bluescreens, bugchecks, dumps, then restarts. I run both DrivePool 2.2.0.906 as well as Scanner which scans as needed at night. I have all performance options enabled except for "Bypass file system filters" plus use the SSD plugin. Balancing is not occurring when the issue happens. Other than that, everything is pretty much default as I don't even duplicate anything. The pool is 43.5tb comprised of 12 platters and a single SSD. It works great other than this issue. I'm happy to submit and logs or whatnot from the app, but wanted to post first to see if this was a known issue with workaround. DrivePool aside, below is the evidence that I've collected from the OS which is Windows 10 1803 x64. Event Logs The computer has rebooted from a bugcheck. The bugcheck was: 0x00000019 (0x0000000000000020, 0xffffe6871f9fd310 XML View - <Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event"> - <System> <Provider Name="Microsoft-Windows-WER-SystemErrorReporting" Guid="{ABCE23E7-DE45-4366-8631-84FA6C525952}" EventSourceName="BugCheck" /> <EventID Qualifiers="16384">1001</EventID> <Version>0</Version> <Level>2</Level> <Task>0</Task> <Opcode>0</Opcode> <Keywords>0x80000000000000</Keywords> <TimeCreated SystemTime="2018-10-16T14:00:03.312566800Z" /> <EventRecordID>2223702</EventRecordID> <Correlation /> <Execution ProcessID="0" ThreadID="0" /> <Channel>System</Channel> <Computer>KelNetSVR</Computer> <Security /> </System> - <EventData> <Data Name="param1">0x00000019 (0x0000000000000020, 0xffffe6871f9fd310, 0xffffe6871f9fd380, 0x000000000407000c)</Data> <Data Name="param2">C:\WINDOWS\MEMORY.DMP</Data> <Data Name="param3">df4e3200-9e5b-48ca-a497-62ed9c91ce3e</Data> </EventData> </Event> Dump Files I loaded the dumps it created in WinDbg. It contains lots of data, but below is a summary - the 5th line from the bottom is what caught my eye. Microsoft (R) Windows Debugger Version 10.0.18239.1000 AMD64 Copyright (c) Microsoft Corporation. All rights reserved. Loading Dump File [D:\101618-45984-01.dmp] Mini Kernel Dump File: Only registers and stack trace are available ************* Path validation summary ************** Response Time (ms) Location Deferred srv* Symbol search path is: srv* Executable search path is: Windows 10 Kernel Version 17134 MP (8 procs) Free x64 Product: WinNt, suite: TerminalServer SingleUserTS Built by: 17134.1.amd64fre.rs4_release.180410-1804 Machine Name: Kernel base = 0xfffff800`f6293000 PsLoadedModuleList = 0xfffff800`f6641170 Debug session time: Tue Oct 16 08:55:13.232 2018 (UTC - 5:00) System Uptime: 0 days 20:22:06.699 Loading Kernel Symbols ............................................................... ................................................................ ................................................................ ................................................................ ................ Loading User Symbols Loading unloaded module list ................ ERROR: FindPlugIns 8007007b ERROR: Some plugins may not be available [8007007b] ******************************************************************************* * * * Bugcheck Analysis * * * ******************************************************************************* Use !analyze -v to get detailed debugging information. BugCheck 19, {20, ffffe6871f9fd310, ffffe6871f9fd380, 407000c} *** WARNING: Unable to verify timestamp for covefs.sys *** ERROR: Module load completed but symbols could not be loaded for covefs.sys *** WARNING: Unable to verify checksum for win32k.sys Probably caused by : covefs.sys ( covefs+2eae1 ) Followup: MachineOwner --------- nt!KeBugCheckEx: fffff800`f643bca0 48894c2408 mov qword ptr [rsp+8],rcx ss:ffff850c`0c184b00=0000000000000019 Any thoughts or suggestions? Thanks!
-
Hi Christopher. Tonight I did some operation on the pool and it was pretty slow, so I went to have a look at the logs (found lots of "Incomplete file found" repeatedly, for the same file; not sure why it dumped the warning 20 times in the log) and had a look at the console too (it was "checking" when I looked, I forget the exact wording). Anyway, once DrivePool was finished "Checking" and "Balancing" everything went back to normal. I think something happened, but I can't say what, it's the first time it's ever gone "slow" on me. Anyway, what I DID notice is that the timestamps inside the logfiles all started at around 10pm. This is when I logoff from 1 user and switch to the Administrator user to do maintenance, install new software, etc. DrivePool is not appending to the log, it is overwritting it. I would definitively call that a bug; we need logs to persist (in fact it keeps daily logs for some days, so the intention *is* to persist). Can you raise a bug report? Thanks! Best Regards,
-
Hi, today I tried to update from 2.2.0.906 to 2.2.1.907 (so I could extend my beta license for another 30days) and it seems the installer may be broken. 2 (maybe related) Problems: First the update to .907 didn't stick (also later with trying to update from .896, it also didn't work). When installing .907 after deinstalling and deleting folders in `Program Files`, it can't start the service (error: couldn't find CoveFS). Second, when uninstalling .906 it doesn't actually delete files in `Program Files`, after an restart DP just opens again, just like I didn't uninstall it. The entry in "Program and Feature" is gone though. So to really uninstall I have to remove the files in `Program Files` manually I could upgrade from .896 to .906 though. Thx
-
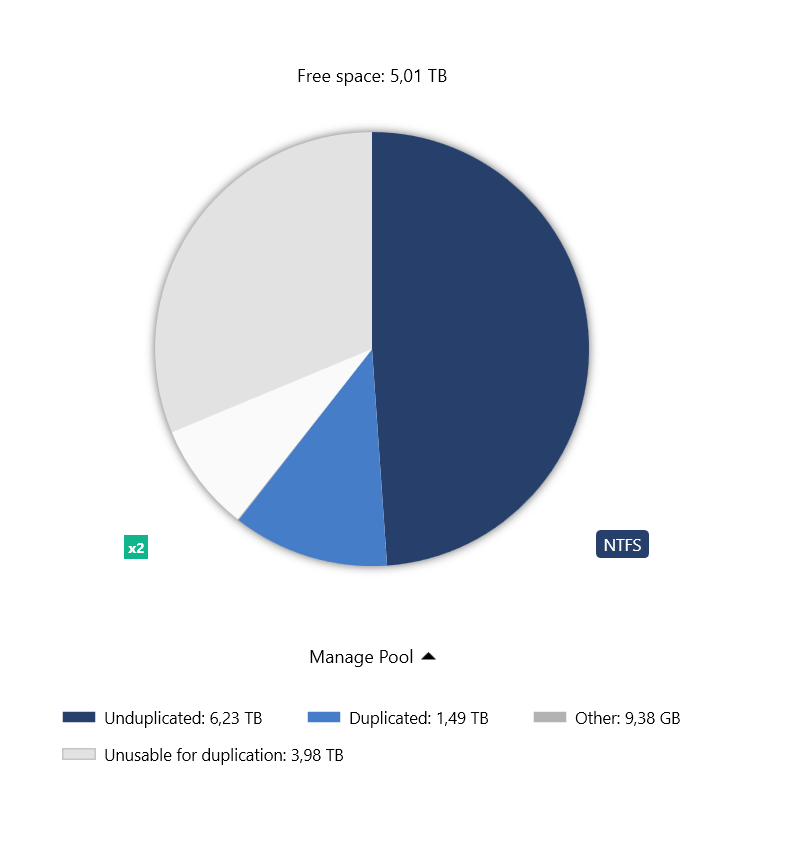
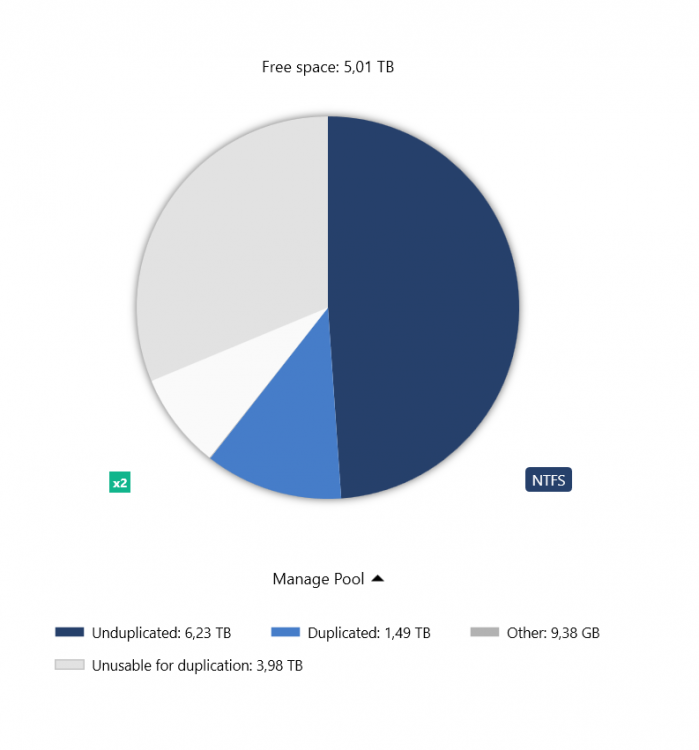
Hi, today I installed a new 6TB to my 8TB pool. While balancing I looked at the pie chart and it seems it's ratios are wrong. Unusuable for duplication (~4TB/gray) should be smaller than free space (5TB/white). Also actually there are no other files on this hard disk than DP, so unusable for duplication is simply wrong. Later after balancing it corrected that accordingly. But measuring was already done at that point when I took this screenshot, so it still should not be wrong Thx
-
Hey, I have the Stablebit Scanner for over a year and I really like it . Last week I changed my backup HDD to a bigger size when I noticed a strange bug. The HDD is a Samsung Spinpoint M8 1TB and it has a standby time of a few seconds (when I check "automatic stanby" in the disk control menu). The normal standy timer seams to have no effect. Although I checked "Do not query if the disk has spun down", I heard the starting of the HDD motor every minute! The Power option only changes between "Standby" and "Active" when I enable "Query power mode directly from disk", but then there is an access every 10 seconds from the scanner and so the HDD starts every 10 seconds.... .Also enabling the option "do not query SMART" for the HDD does not prevent the HDD from starting. I can now thottle the SMART queries to 60 minutes and/or make the HDD 24/7 without standby, but because it is just a backup HDD which makes a backup every day for 30min, both things don't seam right. Is there an option I have overseen? Thanks in advance! Regards, Wonderwhy