


srcrist
-
Posts
466 -
Joined
-
Last visited
-
Days Won
36
Everything posted by srcrist
-
I thought it was relatively clear that this point had already been reached, frankly.
-
I am not going to sit here and have some argument with you about this. If you think your data is made safer by rclone, use rclone and let the issue be. I really don't care about your data, and this matters vastly more to you than it does to me. I'm sorry that you don't understand the actual point. Nobody is forcing you to either use CloudDrive or come here and ask for explanations that you don't actually want. You have a good day.
-
A lot of that is simply repeating what I wrote. But nothing that I wrote is nonsense, and you ignore the inherent volatility issues of cloud storage at your peril. It is obviously true that in this one particular case and for a specific use case rclone did not have the same issues. But hand-waving away data loss simply because it's in the form of stale but complete files reveals that you are a bit myopic about different use scenarios--which is weird, because it's something that you are also acknowledging when you say "Saying Rclone data is stagnant is nonsense too, it entirely depends on the usage." Which was effectively my point. The point you're actually making in your previous post is only that most users are NOT, in fact, using rclone for that purpose, and that is why they were less impacted by this particular (again, one time, several years ago) issue. If they WERE using it to store frequently updated data, they would also have lost data in the rollback--thus negating your point about volatility. I don't know about you, but if I make a lot of changes to a file and Google just throws them out and replaces it with a version I had last month, I'm not pleased. The ultimate distinction between rclone and clouddrive in this particular instance is that clouddrive was frequently updating data (because of the file system), and rclone was not. The actual file data could, in fact, ALSO be restored an a CloudDrive volume after the incident--it was just a lengthy and tedious process. In any case, my point to you is not that one solution is better than another at all. Again, I use both for different purposes. I find rclone to be better for longer-term cold storage, and CloudDrive to have superior performance for regular access. My point, rather, is to help you understand that all cloud storage is equally volatile, and to caution you from presuming that ANY of it is "safer," as you previously claimed. It is not. They are just equally volatile and vulnerable to that volatility in different ways.
-
Upload verification will not prevent provider-side data corruption of any form (absolutely nothing will), but that wasn't the concern you mentioned. It WILL prevent the write hole issue that you described, as CloudDrive will not regard the data as "written" until it can verify the integrity of the data on the provider by retrieving it. Either way, though, I would discourage you from looking at rClone as "safer" in any way. It is not. Any cloud storage is not a safe backup mechanism for data in general, and all cloud storage should be treated as inherently and equally volatile and only used for data that is redundant with more stable mechanisms, or that you can afford to lose. Google Drive has no SLA with respect to the corruption of uploaded data, for example. What you're really noting here is a use case dependent issue. CloudDrive's data (particularly the structural data) was updated more frequently than rClone's more stagnant data. If someone were using rClone to mirror frequently changing data, they also would have been impacted by the rollback--though in different ways. What IS true, is that any corruption on an rClone mirror would be essentially undetected for lengthy periods of time until that specific data is accessed. CloudDrive's corruption was only quickly apparent because the structural drive data is accessed and modified on a regular basis. This all was, it should be noted, a one-time issue several years ago that has not happened since, and CloudDrive has added pinned data (file system) redundancy in the meantime. So it is less likely to be an issue in the future regardless of all of the above discussion.
-
Nobody can really tell you what happened to prompt that cautionary warning about Google Drive other than Google themselves. What we know is that in March of 2019 Google had a major outage that affected multiple services including Drive and Gmail. After the service disruption was resolved, Drive started returning what appeared to be stale, outdated chunks rather than up-to-date data, and that corrupted CloudDrive volumes. I think the widest held presumption is that Google had to do a rollback to a previous backup of some form, and thus replaced some chunks with older versions of themselves--but we'll never really know for sure. Google is not exactly forthcoming with their operative decision making or the technical details of their services. Regardless, turning on upload verification would prevent the sort of write issue you're describing entirely, but you'll always be at the mercy of the stability of Google's services with respect to the data on their servers. So nobody can guarantee that it won't ever happen again. Hence the warning. For what it's worth, I've used both rClone and CloudDrive for large-scale data storage for years and I've never found either one to be particularly more volatile than the other--dating even back to CloudDrive's beta. It's always been perfectly stable for me, aside from the Google incident. Just make sure to enable the data integrity features like pinned data duplication and upload verification.
-
On your H: and your V: you will have a poolpart folder, if they have been added to the pool. Put everything ELSE on those drives, like the CloudDrive folder, if that's where your content is, into the poolpart folder. Then remeasure and it will be accessible from your G:.
-
All of the content, on each drive, that you want to access from the pool, should be moved to the hidden pool folder on that respective drive.
-
This is backwards. You don't want to move the hidden directory, you want to move everything else TO the hidden directory. The contents of the hidden directory is what is in your pool.
-
Make sure that you both submit tickets to support here: https://stablebit.com/Contact
-
Great. Glad you got it worked out.
-
Just including a quote in case you have email notification set up. Forgot to quote you in the previous post.
-
Hmm...not sure. The good news is that if drive corruption were the issue, you should see the chksum errors in the log and the notification drop-down. I don't see any pending notifications in your UI, unless you cleared them. So it's probably not corruption. What does the cache look like for this drive? What sort of drive is it on, how large, and what type of cache? And, to be clear: You are showing the "default i/o settings" in your screenshot. Those apply when you create a new drive. Is your existing, mounted drive actually using those settings as well? Verify within the "Manage Drive" menu. It is possible to have different default settings than the mounted drive is actually using. If the drive is actually using the settings in your screenshot, those settings should be sufficient for solid throughput.
-
Not to my knowledge, no. CloudDrive is just a tool to store a psuedo-native file system on another sort of storage protocol. CloudDrive takes non-native file storage like FTP, SMB, or a cloud storage host, and provides a native (NTFS or ReFS) file system for Windows. It's a middle man for the a storage API/protocol so that windows can access that storage as if it were a local drive. But the side effect is that the data must be accessed via the CloudDrive application. It is not intended to be a front-end for the non-native API. Tools like rClone or Netdrive are. Unless some future version of the application makes pretty dramatic changes to the entire functionality, its data will never be accessible in the way that it sounds like you want it to be--encrypted or not. Any file system that can be added to DrivePool directly can have its duplication managed by DrivePool itself, and file systems that cannot (like, for example, SMB shares or dynamic volumes) can simply be mirrored using a simple sync tool (of which there are many). Microsoft's own SyncToy is one, though I believe it takes some finagling to make it work on Windows 10. You likely can't add the NAS to the DrivePool (assuming it is an SMB share--I believe iSCSI CAN be added, but I'm not familiar with the process) but you can use many other options to just mirror/sync directories from the pool to the NAS. Note that while you you CAN use CloudDrive to create a volume on the NAS and add THAT to the DrivePool, and configure the duplication that way, the data on the NAS that CloudDrive creates will not be accessible to any system that isn't the one hosting the DrivePool and CloudDrive clients that are connected to the drive--nor is there really any way to modify CloudDrive to accomplish this goal without completely changing the way it works now. So, some options, then: You could try adding the NAS to DrivePool via iSCSI as mentioned above. I've never done this, but I believe there is some discussion elsewhere on the forum that you should be able to find to help you do this. The iSCSI volume can then be added to your DrivePool and your duplication adjusted accordingly. You could create a directory/volume WITHIN the pool, at the cost of pool space, which you can duplicate the data to, and then set up another tool like SyncToy to mirror THAT directory to your NAS. You could just use a tool like SyncToy to duplicate all of your media folders to the NAS. Or, to save space, you might be able to script up something simple that copies media to the NAS as required. Ultimately, though, note that none of these solutions use CloudDrive, and that there isn't any way to make CloudDrive do what you want it to do. And that isn't a factor of encryption. It's just a byproduct of the fundamental mechanism by which CloudDrive operates. Its data just isn't accessible outside of the application any more than a VHD is accessible to a host system outside of the VM--and for the same reasons. CloudDrive's data contains structural information about the drive, as well as relevant file system information, in addition to the actual files that it stores. CloudDrive certainly CAN be used to extend your pool, or to provide an off-site duplication resource to supplement your pool, but it is only capable of enhancing the pool in this manner for the system that hosts the pool itself. That system would then have to share the data with other systems via other, more traditional means. As far as this goes, I'm not sure what it means. It SHOULDN'T take days to recover from a simple network or power failure. I have around 300TB stored in a single cloud-based CloudDrive drive and it takes maybe 15-20 minutes to recover from a power failure or other hardware reboot. A temporary network failure simply dismounts the drive and remounts the drive once connectivity has been restored. No additional recovery time is necessary for that. The only time that either the stable or most recent beta version of CloudDrive should have to actually rebuild the database for a large drive (which does take awhile, though not days even for my drive) is when the local storage information/cache is actually corrupt and CloudDrive needs to audit the entire drive structure in order to determine what actually exists and what doesn't. It MIGHT be the case that the code for the NAS provider is less efficient. I've never used the NAS provider with CloudDrive, so I can't say. But you'd have to just reach out to Covecube via the contact form and ask.
-
To be clear: encryption is (and has always been) optional even on CloudDrive volumes hosted on cloud providers. You do not have to enable encryption for volumes stored on cloud storage or local storage. But what I suspect that you are actually talking about is that you want the data to be accessible in whatever native, unobfuscated file format your applications are accessing when encryption is disabled, but that simply isn't possible with CloudDrive. It just isn't how this particular software works. As mentioned in the above post from June, there ARE tools you can use to basically access cloud storage with a front-end that mounts it as a local drive, this just isn't that tool. Even if you could use a multi-terabyte chunk size, your drive would still just be one giant obfuscated chunk because what CloudDrive actually stores is a drive image. It's effectively the same thing as a VHD or VMDK--and that is by design. Even an unencrypted volume is still stored as an unencrypted drive image, not the native files that you're probably looking to access. If I'm understanding your needs correctly, though, it actually sounds like your needs are much simpler than CloudDrive. It sounds like you actually just need a SMB share and a sync tool like SyncToy to mirror certain content from the server to a NAS? Is that correct?
-
 If you have the thread organized by votes, that post from Christopher is actually from Oct 12th. It's not the first post from the thread chronologically, which was made back in June. You just have your thread sorted by votes. This is correct though, and something I had not noticed before. Also the ReFS fix from beta .1373 and the ReFS fix listed in the stable changelog for stable .1318 are for different issues (28436 vs 28469). No versions between 1.1.2.X and 1.2.0.X are represented in the betas at all, but, for example, the Google Drive API keys which were added in BETA .1248 are represented in the stable changelog for .1249. I was presuming that the build numbers from the stable versions subsequent to the builds for the beta were implementing all of the changes up until that point and simply not listing them in the changelog, but you might be correct, here. They may simply be merging some limited number of beta changes back to the stable branch and using the version suffix to represent a rough build equivalency. If that is the case: then the stable branch is *significantly* behind the beta and, yes, Christopher and I may both have been referring to the same changes and I was just confused. If the stable version has only implemented the changes listed in the stable changlog, then the stable release will not mitigate the folder-limit issue. You would have to use a beta. This is my fault for not keeping up with the stable changelog since switching to the beta. So, yeah, the bottom line is that people need to either switch to the beta, if they're seeing this issue, or wait for a stable release. But you'd have to reach out to Alex and Chrisopher about when that might be. I can, however, vouch for the stability of at least beta .1316, which is what I am still using on my server. I'll go back and edit the inaccuracies in previous posts. Pursuant to the above, if you are not running the beta, then it would appear that these changes are not available to you. So nothing that anyone has suggested here would work. You'll have to switch or wait.
If you have the thread organized by votes, that post from Christopher is actually from Oct 12th. It's not the first post from the thread chronologically, which was made back in June. You just have your thread sorted by votes. This is correct though, and something I had not noticed before. Also the ReFS fix from beta .1373 and the ReFS fix listed in the stable changelog for stable .1318 are for different issues (28436 vs 28469). No versions between 1.1.2.X and 1.2.0.X are represented in the betas at all, but, for example, the Google Drive API keys which were added in BETA .1248 are represented in the stable changelog for .1249. I was presuming that the build numbers from the stable versions subsequent to the builds for the beta were implementing all of the changes up until that point and simply not listing them in the changelog, but you might be correct, here. They may simply be merging some limited number of beta changes back to the stable branch and using the version suffix to represent a rough build equivalency. If that is the case: then the stable branch is *significantly* behind the beta and, yes, Christopher and I may both have been referring to the same changes and I was just confused. If the stable version has only implemented the changes listed in the stable changlog, then the stable release will not mitigate the folder-limit issue. You would have to use a beta. This is my fault for not keeping up with the stable changelog since switching to the beta. So, yeah, the bottom line is that people need to either switch to the beta, if they're seeing this issue, or wait for a stable release. But you'd have to reach out to Alex and Chrisopher about when that might be. I can, however, vouch for the stability of at least beta .1316, which is what I am still using on my server. I'll go back and edit the inaccuracies in previous posts. Pursuant to the above, if you are not running the beta, then it would appear that these changes are not available to you. So nothing that anyone has suggested here would work. You'll have to switch or wait. -
EDIT: THIS POST APPEARS TO BE INCORRECT. Both. We were both talking about different things. I was referring to the fix for the per-folder limitations, Christopher is talking about the fix for whatever issue was causing drives not to update, I believe. Though it is a little ambiguous. The fixes for the per-folder limitation issue were, in any case, in the .1314 build, as noted in the changelog: http://dl.covecube.com/CloudDriveWindows/beta/download/changes.txt EDIT: Christopher might also have been talking about the ReFS issue, which looks like it was fixed in .1373. I'm not sure, though. People have used this thread for a larger number of issues, at this point, than is probably helpful. If a moderator agrees, we might want to lock it to encourage people to post new threads.
-
Yeah, I mean, I still wouldn't worry too much until you talk with Christopher and Alex via the contact form. The truth is that CloudDrive would be relatively scary looking software for an engine that is looking for spoopy behavior and isn't familiar with its specific signature. It has kernel-mode components, interacts with services, hooks network adapters, accesses the cpu clock, and does things to Windows' I/O subsystem based on network input. Take a second and think about how that must look to an algorithm looking for things that are harming your PC via the internet. By all means, exercise some level of caution until you get some confirmation from Covecube, but I wouldn't be terribly concerned just yet. CloudDrive just looks shady to any engine that doesn't know what its actually doing--and there aren't many tools that do what it does.
-
You'd have to ask via the contact form to get some sort of confirmation: https://stablebit.com/Contact Though this is almost certainly just a false positive. They're not uncommon. I only see two detections on my version, in any case (https://www.virustotal.com/gui/file/1c12d59c11f5d362ed34d16a170646b1a5315d431634235da0a32befa5c5ec5c/detection). So Tell's rising number of detections may be indicative of another (scarier) problem. Or just overzealous engines throwing alarms about kernel-mode software.
-
Open a ticket. You should be able to force the migration process, but they also need to know when it isn't working to troubleshoot a longer-term fix.
-
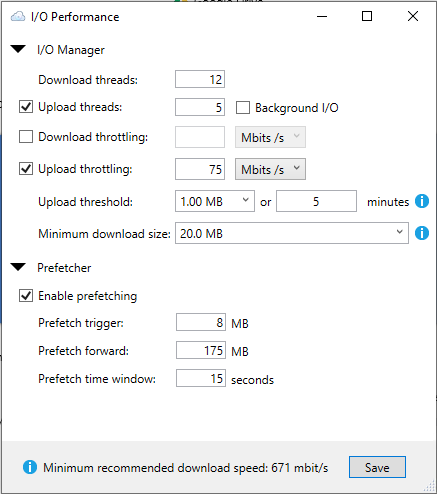
I actually see multiple problems here, related to prompt uploads and data rate. The first is that, yes, I'm not sure that your prefetcher settings make much sense for what you've described your use case to be--and the second is that you've actually configured a delay here on uploads--contrary to your actual objective to upload data as fast as possible. But, maybe most importantly, you've also disabled the minimum download, which is the most important setting that increases throughput. So let's tackle that delay first. Your "upload threshold" setting should be lower. That setting says "start uploading when you have X amount of modified data, or it has been Y minutes since the last upload." You've actually raised the values here from their lower defaults of 1MB or 5 minutes. So your drive will actually be more delayed relative to drives created with the default settings. Your minimum download should be some reasonable amount of data that roughly corresponds to the amount of data you expect the system to need in short order whenever any amount of data is requested. So, for example, if you're dealing with files of 10-20MB, and you need the data asap, you'd probably want a minimum download of around 15MB so that any time the system makes a request of the drive, it pulls all of the data that might be quickly needed to the cache immediately. Note that if you let it ClouddDrive will only pull the amount of data that your system requests of it for a particular file read. That means, say, a few hundred KB at a time of a music file, a few dozen megabits of a high quality video file, or the data for a first few pages of a document. Just like a hard drive. But, unlike a hard drive, CloudDrive has to renegotiate an API connection and request data every time you system requests any amount. You absolutely cannot let it do that. That is tremendous overhead and very slow. You need to figure out what your actual data needs are, and force CloudDrive to pull that data asap when a request is made. I would suggest (and this is based on the still somewhat cryptic use case you've described thus far) 10 or 20MB for your minimum download. You'll notice that your current minimum download recommended speed is presently only 14mbps. Compare that to the estimated data rate for these settings: With respect to your prefetcher, I'd probably need to know a bit more about both your intended purpose for the drive and your actual drive settings to give you better advice. For now, suffice it to say that I actually think that, based on your intention to load 10-20MB files as quickly as possible, the prefetcher probably doesn't need to be enabled at all. As long as your drive is structured correctly and the other settings are correct. If you want some more help here, you're going to have to provide a more detailed account of what you're actually doing with the drive, and preferably all of the structural information about the drive such as this information here: I'd also note that if you want to prioritize writes to the drive over read speed, you'd probably want to enable background I/O as well. Turning it off makes it easier for drive reads to slow the write process. And, relatedly, another thing that isn't clear to me: since data is available from the CloudDrive drive as soon as its added to the drive, what is the need for the rapid upload to the provider? That is, the data is already accessible, and the speed with which the data is uploaded to the provider has no bearing on that. So why the need for many MB/s to move what effectively amounts to duplicate data to your host? Just trying to understand your actual objective here. And upload verification is not a relevant setting with respect to drive throughput, but, if data integrity is something you care about, I do suggest turning it on. It should effectively eliminate the potential for Google issues to ever cause data loss again, since every byte uploaded is verified to exist on Google's storage before CloudDrive will move on to new data and remove the uploaded data from the cache.

-
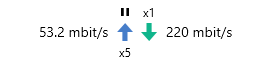
10MB chunks may also impact your maximum throughput as well. The more chunks your data is stored in, if you accessing more than that amount of data, the more overhead those chunks will add to the data speed. The API limits are for your account, not the API key. So they will all share your allotment of API calls per user. It does not matter that they use different API keys to access your account. That may be, but note that Google Drive is not, regardless of whether or not it's a business account, an enterprise grade cloud storage service. Google does offer such a service (Google Cloud Storage), but at a much higher price. This remains true regardless of what you consider their service to be. CloudDrive also supports GCS APIs as well, if you actually need that level of service. Google Drive, even on a business account, is intended to provide consumer grade storage for individual users--not enterprise grade storage for high data volume, high data rate, or high availability purposes. See Google's own statement on the matter here: https://cloud.google.com/products/storage I think I understood what you were saying, actually. I don't really understand the use case that would necessitate what you're looking for, and I'm not entirely sure how you're testing the maximum throughput, but I do understand what you are seeing and what you are thinking is a problem. 110mbps is pretty low relative to my experience, assuming your system is actually requesting the amounts of data from the drive that would lead CloudDrive to max out the throughput. I am, for example, presently seeing these speeds: And that is with a largely idle workload. I believe upload verification is the only load on the drive at the moment. I don't, unfortunately, really know how to help you solve it, though. If your system is trying to pull a lot of data, and your I/O settings and your prefetcher settings are configured reasonably, speeds to Google should certainly be faster than what you are experiencing. Maybe not 100MB/s, but better than 110mbps. Have you considered a peering issue between your system and Google itself? To be clear: have you actually tested the performance in a real-world way? Trying to read large amounts of data off of the drive, as opposed to looking at the network metrics in the UI? What speed does Windows report, for example, if you try to copy a large file off of the drive that isn't stored in the cache? And, on a related note, have you tested to see if your data is being pulled from the cache? 40GB every 12 hours is not a ton of data. If your cache is larger than that, it's probably all being cached locally. If that is the case, CloudDrive won't need to actually download the data from your provider in order to provide it to your system.
-
Is this a legacy drive created on the beta? I believe support for chunk sizes larger than 20MB was removed from the Google Drive provider in .450, unless that change was reverted and I am unaware. 20MB should be the maximum for any Google Drive drive created since. 50mbps might be a little slow if you are, in fact, using 100MB chunks--but you should double-check that. Gotcha. Yeah, if you set additional limitations on the API key on Google's end, then you'd have to create a key without those restrictions. And CloudDrive is the only application accessing that Google Drive space? Nothing else is using the API or accessing the data on your Google Drive? Those yellow arrows indicate that Google is throttling you--and that is handled on a user by user basis--so that's the angle to explore. I think you might just be running into a difference in expectation. I'm not sure how many users would consider 50mbps * X threads to be slow. I think that if most users hit 500mbps they would probably consider that to be relatively fast. So the only people who are saying, "yeah, my drive is slow," are the people whose drives are bottlenecked by I/O, rather than network throughput. It really sounds like you were looking for CloudDrive to provide effectively enterprise grade throughput on a consumer data storage service, and I don't think that was necessarily a design goal. You might be able to get the sorts of data speeds you're looking for, somewhere in the 100s of MB/s, from rClone if you configure it to operate on the data in parallel--so maybe look into that. Sure thing. Good luck finding something that works for you!
-
Sometimes the threads-in-use lags behind the actual total. As long as you aren't getting throttled anymore, you're fine. Netdrive and rClone are not appropriate comparisons. They are uploading/downloading several gigbytes of contiguous data at a time. The throughput of that sort of data stream will always be measured as larger. CloudDrive pulls smaller chunks of data as needed and also no data at all if it's using data that is stored in the local cache. You're not going to get a measured 50MB/s per thread with CloudDrive from Google. It just isn't going to happen. 50mbps for a single thread with a 20MB chunk size is about what I would expect, accounting for network and API overhead. That's about 500mbps with 10 download threads--or roughly 62MB/s in the aggregate. A larger chunk size could raise that throughput, but Google's chunk size is limited because it creates other problems. You are hitting the expected and typical performance threshold already. Your aggregate thread count would already exceed the 50MB/s that you get from the applications making larger contiguous data reads. You just have to understand how the two applications differ in functionality. CloudDrive is not accessing a 10GB file. It is accessing X number of 20MB files simultaneously. That has performance implications for a single API thread. The aggregate performance should be similar. I am not 100% sure what this means. But, if I am interpreting correctly, I think you are confusing the API key's functionality. The API key has nothing to do with the account that you access with said key. That is: an API key created with any google account can (at least in theory) be used to access any other account's data, as long as a user with the appropriate credentials authorizes said access. So much to say that you can use the API key you create to authorize CloudDrive to access any Google account to which you have access, as long as you sign in with the appropriate credentials when you authorize the drive. Note that Google does place limits on the number of accounts that the API key can access without submitting it to an approval process, but those limits are much higher than anyone using a key for genuine personal use would ever need to worry about. It's something like 100 accounts. Note that, by default, you were already using an API key created on Stablebit's Google account to access YOUR data. Sure. Ultimately, CloudDrive isn't really designed to provide the fastest possible throughput with respect to storing data on Google or any other provider. If your needs are genuinely to have multiple 50MB/s simultaneous downloads at once, on a regular basis, this probably just isn't the tool for you. The most efficient performance configuration for CloudDrive is to have one large drive per Google account, and give that one drive the maximum number of threads as discussed above, leaving you with that 60ish MB/s aggregate performance. Your present configuration is sort of self-defeating with respect to speed to begin with. You've got multiple drives all pulling chunks from the same provider account, and they all have to compete for API access and data throughput.
-
I mean, the short answer is probably not using your API key. But using your own key also isn't the solution to your real problem, so I'm just sorta setting it aside. It's likely an issue with the way you've configured the key. If you don't see whatever custom name you created in the Google API dashboard when you go to authorize your drive, then you're still using the default Stablebit keys. But figuring out exactly where the mistake is might require you to open a ticket with support. Again, though, the standard API keys really do not need to be changed. They are not, in any case, causing the performance and API issues that you're seeing.
-
Any setting that is only available by editing the JSON is considered "advanced." See: https://wiki.covecube.com/StableBit_CloudDrive_Advanced_Settings That is more, in one drive, than Google's entire API limits will allow per account. You'll have to make adjustments. I'm not 100% sure the exact number, but the limit is somewhere around 10-15 simultaneous API connections at any given time. If you exceed that, Google will start requesting exponential back-off and CloudDrive will comply. This will significantly impact performance, and you will see those throttling errors that you are seeing. Note that Google's limits are across the entire google user, so, if your drives are all stored on the same account, your total number of upload and download threads across all of the drives on that account cannot exceed the 15 or so that Google will permit you to have. I use 10 down and 5 up, with the presumption that all 15 will rarely be used at once, and rarely run into throttling issues. It should not be. My server is only on a 1gbps connection, not 10gbps like yours, and I can still *easily* hit over 500mbps with 10 download threads. 20 upload threads is pointless, since Google will only allow you to upload 750GB per day, which averages out to around 70mbps or so, a rate that even two upload threads can easily saturate. Ultimately, though, your numbers are simply excessive. You're quite a bit over the recommended values. Drop it so that you're at less than 15 threads per Google account and you'll stop getting those errors. Then we can take a look at your throughput issues.
