Tell
-
Posts
24 -
Joined
-
Last visited
Tell's Achievements
Member (2/3)
0
Reputation
-
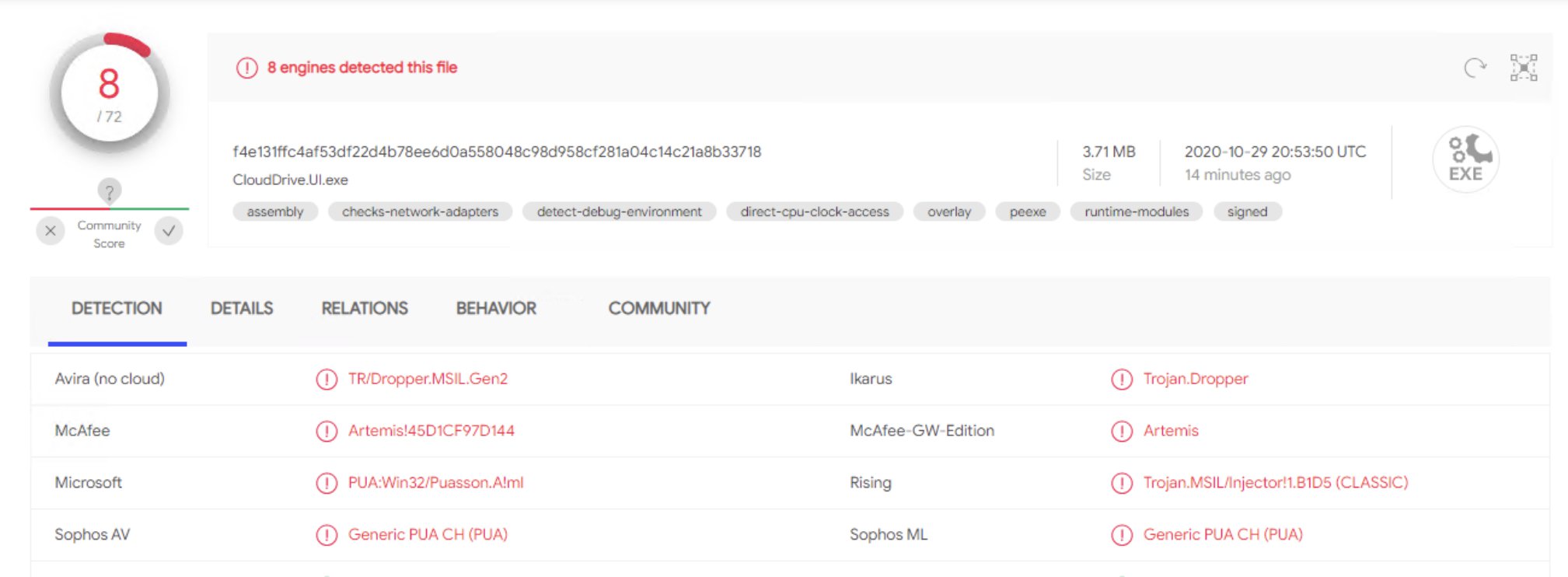
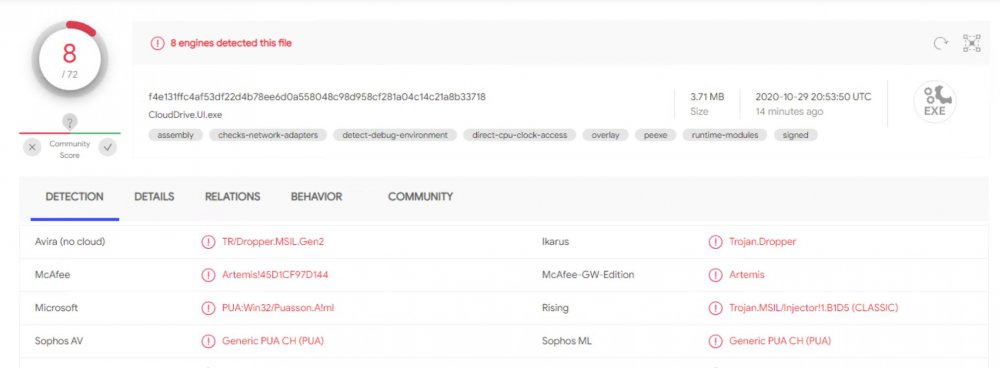
@Tetradi Your file is triggering with the same pattern as mine ("PUA:Win32/Puasson.A!ml"). Let's hope CoveCube can sort this out soon. Paging @Christopher (Drashna) and @Alex :-)
-
I just submitted a support request using the link you provided @srcrist, thanks. I can see that my version of the file is signed by the developers, so it seems highly likely that it’s a false positive, but it’s very worrying that you’re all getting different results with your versions of what should be the same file.
-
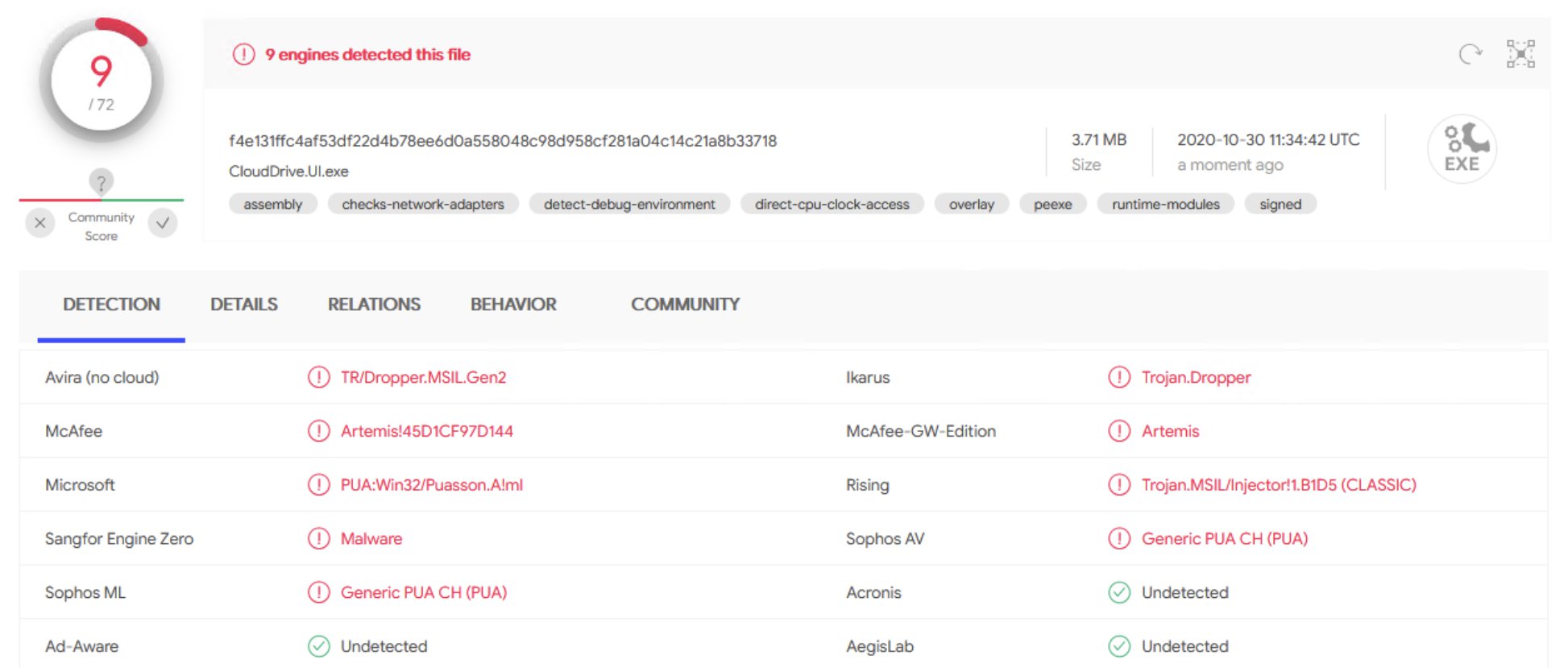
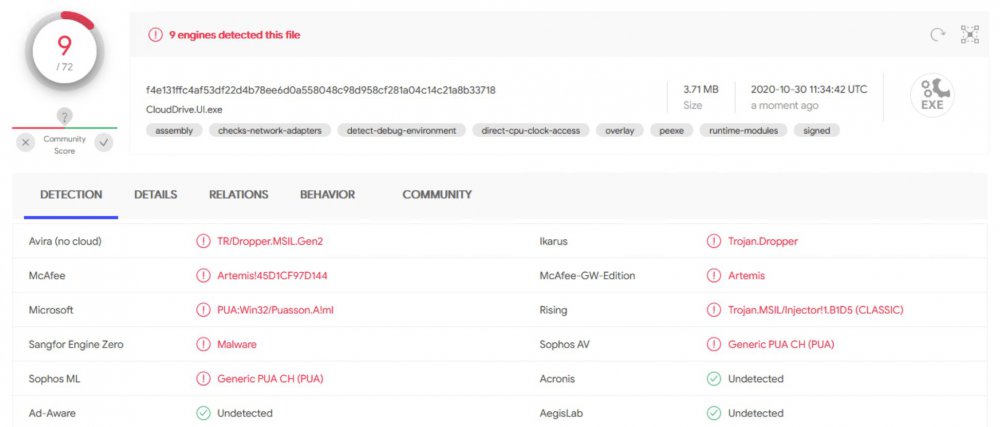
One more engine on VirusTotal is now detecting this as malware, bringing the total to 9 engines. I’ll reach out to CoveCube to bring this to their attention (or do we have @Christopher (Drashna) here now?)
-
So, the latest release of CloudDrive.UI.exe is being detected by multiple AV engines as various forms of malware or potentially unwanted application. Anybody else seeing this? Have a look at the VirusTotal report of CloudDrive.UI.exe. I was alerted by Windows Defender. I’d welcome other members of the community to submit their own CloudDrive.UI.exe to VirusTotal to see if I’m the only one getting this.
-
Any thoughts on this, @Christopher (Drashna)? What about https://docs.jottacloud.com/en/collections/178055-jottacloud-command-line-tool ?
-
Well, they reserve the right to do so, but they haven't capped me – and I'm well in excess of 10 TB! :-)
-
Well, sort of, but not really. rclone did it using the jottaCLI. Any possibility that there might be something here for CloudDrive?
-
I’d like to suggest that Covecube revisits Jottacloud as a possible provider for StableBit CloudDrive. Jottacloud is a Norwegian cloud sync/cloud backup provider with an unlimited storage plan for individuals and a very strong focus on privacy and data protection. The provider has been evaluated before, but I’m not sure what came of it (other than that support wasn’t added). Jottacloud has no officially documented API, but they have stated officially that they don’t oppose direct API access by end users or applications, as long as the user is aware that it isn’t supported. There is also a fairly successful implementation in jottalib, which I believe also has FUSE support.
-
I’d like to chip in that this is no longer the case. JottaCloud now limits their storage and bandwith usage to “normal individual usageâ€. Specifically:
-
Thank you for your input! Unfortunately, the ACD software is not related to the issue being discussed in this thread. This thread details a problem that appears when an amount of data greater than the size of the drive the cache resides on is written (copied) to the CloudDrive drive.
-
After some testing, I can confirm that the .777 build does NOT resolve this issue. I understand that the issue is caused by how NTFS handles sparse files. Why is this issue so "rare"? Is it only a small subset of users that experience this bug? Does not everybody see this happen when they copy more data to cloud drive than the size of the cache? For me, this makes CloudDrive incredibly difficult to use – I'm trying to upload about 8 TB of data, and given a 480 GB SSD as a cache drive, you can do the math on how many reboots I have to do, how many times I have to re-start the copy and how often I need to check the entire CloudDrive for data consistency (as CloudDrive crashes when the cache drive is full). The reserved space is released when the CloudDrive service is restarted. This indicates that the deallocated blocks are freed when the file handles are closed from CloudDrive. To me, it seems like a piece of cake to just make CloudDrive release and re-attach cache file handles on a regular basis – for example, for every 25% of cache size writes and/or when the cache drive nears full or writes are beginning to get throttled.
-
Actually, there isn't. Their unlimited plan is limited at 10 TB. See https://www.jottacloud.com/terms-and-conditions/ section 15, second paragraph.
-
I'm currently testing to see if the .777 build har resolved this issue.
-
Turns out running… net stop CloudDriveService net start CloudDriveService … does actually resolve the issue and release the reserved space on the drive (which in effect was the same as a reboot accomplished), allowing me to continue adding data. It is clear to me that the issue is resolved when CloudDrive then releases/flushes these sparse files. The issue does not re-appear until after I have added data again. While the problem might be NTFS-related, I would claim that this would be relatively simple to mitigate by having CloudDrive release these file handles from time to time so that the file system can catch up on how much space is occupied by the sparse files. It makes sense to me that Windows, to improve performance, might not compute new free space from sparse files until after the file handles are released – after all, free disk space is not a metric that mostly needs be accurate to prevent overfill and not the other direction. TL;DR: The problem is solved by restarting CloudDriveService, which flushes something to disk. CloudDrive should do this on its own.
-
Drashna and friends, I'm still experiencing the issues, which is preventing me from uploading more than the size of my cache drive (480GB) before I have to reboot the computer. Hosting nothing but the CloudDrive cache, fsutil gives: C:\Windows\system32>fsutil fsinfo ntfsinfo s: NTFS Volume Serial Number : 0x________________ NTFS Version : 3.1 LFS Version : 2.0 Number Sectors : 0x0000000037e027ff Total Clusters : 0x0000000006fc04ff Free Clusters : 0x0000000006fb70c3 Total Reserved : 0x0000000006e6d810 Bytes Per Sector : 512 Bytes Per Physical Sector : 512 Bytes Per Cluster : 4096 Bytes Per FileRecord Segment : 1024 Clusters Per FileRecord Segment : 0 Mft Valid Data Length : 0x0000000000240000 Mft Start Lcn : 0x00000000000c0000 Mft2 Start Lcn : 0x0000000000000002 Mft Zone Start : 0x00000000000c00c0 Mft Zone End : 0x00000000000cc8c0 Since a reboot solves the issue, could it be that CloudDrive needs to release the write handles on the (sparse) files so that the drive manager will let go of the reservation? Did https://stablebit.com/Admin/IssueAnalysis/27122uncover anything? Best, Tell