Royce Daniel
-
Posts
26 -
Joined
-
Last visited
-
Days Won
1
Royce Daniel's Achievements
Member (2/3)
4
Reputation
-
 Christopher (Drashna) reacted to an answer to a question:
Plex Cloud and Stablebit
Christopher (Drashna) reacted to an answer to a question:
Plex Cloud and Stablebit
-
Make sure you turn off Automatic updates.
-
Nope. Just the same Reddit threads that Drash has already pointed out. Talk about popcorn eating entertainment...
-
Ah. I thought you were asking me if I found anything interesting in my search. Well, yeah that quote was interesting. Imagine if some marketing team at Amazon decided to search through everyone's Cloud Drive account to see what pictures are uploaded, music, movies what ever. They could index it all and build behavior profiles to make targeted marketing campaign ads. Imagine some user, like my grandmother, who doesn't know WTF encryption is thinks, "oh great, for 60 bucks a year I can store all my personal information here". *smacks head* I can imagine a lot of dreadful things people do unaware...
-
@Spider99 That quote is directly from Plex's TOS... it's in there. I wouldn't be uploading any *cough* questionable home movies. You might find yourself online in all your embarrassing glory. Wait... wut? I mean I know they have the ability to go in and look at your files but I was under the impression that the "chunks" that are uploaded are encrypted. Is that not the case? I did setup encryption. This is all they will see... chunk files which are encrypted.
-
Spider99 reacted to an answer to a question:
Plex Cloud and Stablebit
-
Christopher (Drashna) reacted to an answer to a question:
Plex Cloud and Stablebit
-
I'm sure at some point there might be some kind of a "crack down" because there will be users who will abuse the service. Let's face it, if a would be Pirate wants to store and run copy protected material unencrypted... they are going to get caught. From what I've read Plex Cloud doesn't encrypt the content you upload via Plex to Amazon Cloud Drive which means Amazon has the ability to see what you have stored and examine it. If it contains embedded metadata suggesting that it was obtained illegally... your toast. If I were a rogue user I wouldn't use it. People talk about Amazon Cloud Drive / Plex Cloud as a private Netflix. I don't see it. Netflix has a shared video library where multiple users can view the same file. If every movie nut in the world has a private collection of 10TB or more... holy data Armageddon batman! Amazon has some amazing search algorithms they use to manage their data in various ways. With Amazon's TOS they have the ability to use those algorithms on your "private" movie libraries. Who's to say they aren't DE-duping to some extent and linking metadata among users accounts? It's a multi-tenant environment. Could easily be done. Plex's TOS allows for it too. I'm adding this topic to my daily news search because I think at some point there are going to be some really interesting stories that come out from this...
-
After installing build 711 beta build for DrivePool I tried this again for kicks. Same error. However, I did some digging and the same issue pops up under FlexRaid with a running VM. The person reporting the issue solved it by shutting down the VM... thus releasing the drive. That got me thinking. The error I get when the backup fails basically translates into not being able to create a snapshot. This requires full write access or the ability to make modifications to the drives properties. I remembered when I attempted to unmount the DrivePool drive when I first created it and tried to reformat it from NTFS to ReFS. I learned later that it's not a real NTFS drive but its access is limited and you can't reformat it. Perhaps the API that's trying to create a snapshot or VSS copy doesn't have sufficient rights or access to write a bootfile (as the error message in the event log suggests)? Or some other underlying mechanic that is preventing the back up from creating a snapshot? I'll be honest, I know very little about how VSS works but from what I was able to read about it my assumption seems logical. If you recall from the older days of FAT and FAT32 you couldn't make any changes to the file allocation table when the drive was "in use". Even applications like Partition Magic freaked out if something was using the drive while it attempted to make changes to the drives partition table. Perhaps VSS is something along those lines... *shrug* Just a thought.
-
I can confirm that build 711 fixed my BSOD issues. Thanks!
-
VSS: OK OK I get it. Sucks... So what are you using to back up 50TB?!?!
-
CloudDrive not releasing Reserved clusters after upload
Royce Daniel replied to tomm1ed's question in General
Not sure if this is relevant to this particular thread but I was having a similar issue with my "cache" drive filling up. I specifically had a Local cache size set to 1.00 GB and left the Cache type setting at it's default; Expandable (recommended). I wanted my local cache to stay at or around 1.00 GB because the only other drive I have in my server is the main OS drive which is a 160GB SSD and it's the only drive that was available for me to select as a cache drive in the UI when I created the Cloud Drive volume. I only use the Cloud Drive to store backup's so to have a large local cache for storing frequently accessed files didn't apply to me and it's not needed. When I started my backup it blew through that 1 GB very quickly and continued to grow well beyond the 1 GB setting. My "chunks" are set to 100 MB and since my upload bandwidth couldn't keep up with how fast the backup was making chunks, naturally it pilled up but I wanted the Cloud Drive to throttle the backup, not the other way around where disappearing drive space and ultimately low drive space causes the CloudDrive to throttle itself. Something that was never suggested in this thread or others I came upon with a similar issue did either... my fix was to set the Cache type to Fixed. Now my local cache hovers around 1 - 1.2 GB. Once the chunks are uploaded the cache is flushed and the Local cache size stays capped at where I set it. /cheers -
Oh... yeah duh! It's practically plain text. I'm just so used to everything already being compressed.
-
I'm using the Windows Server 2012 R2 Essentials server back up option. It does rely on VSS. Using the info contained in your link I was able to start the backup without error but, like I said, I have to select all the PoolPart folders manually rather than just simply selecting the folders in the DrivePool that I want. Which means I'm backing up all the data with the duplicated files. Raw data plus all the duplicated files is roughly 30TB of data vs just raw data without the duplicated files would only be about 12TB of data. Some of the folders I have set to x3 but most are x2. It would be nice if DrivePool was VSS friendly. I meant Amazon Cloud Drive's upload caps specifically. The CloudDrive app is really awesome compared to all the others I've tried. All your stuff is really awesome. It's why I bought the whole package. I LOVE your approach to DrivePool in how you can control the amount of redundancy on a per-folder basis. Well turns out that I WAS saturating my upload pipe. LOL! I haven't looked at my Internet account in a couple years. It's never been an issue until now. I just remember getting the fastest I could get my hands on. 150 / 5 mbps. I did some checking that that is their "advertised" speed not what the line is provisioned for. It's actually provisioned for 50 (up to 200 burst) mbps / 12 mbps. This makes total sense since that is what I'm seeing as an average upload speed... 12.6 on average. So I upgraded my account, after I swap the modem out tomorrow, and I'll have a provisioned speed of 300 / 30 mbps. But still, 30TB will take roughly 97 days to complete @ 30 mbps. If I can solve the issue of only backing up RAW data and upload only 12 TB that would only take roughly 39 days @ 30 mbps. But I did some digging and apparently, in the state that it's in now, the CloudDrive app is capped at 20 mbps.
-
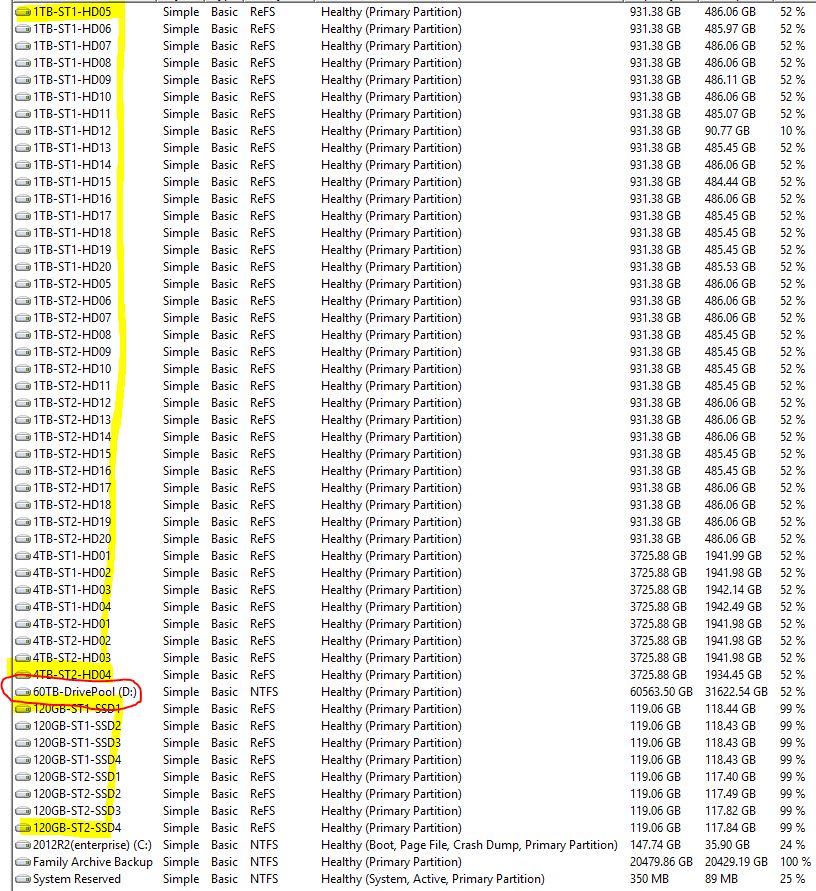
Sorry to resurrect an old discussion - I got this in a forum post from 2 years ago where Christopher was answering a question about why Server 2012 R2 Essentials fails during a back up: http://stablebit.com/Support/DrivePool/1.X/Manual?Section=Using%20Server%20Backup%20to%20Backup%20the%20Pool So this fix worked for me but I have a HUGE problem with backing duplicated files. Why? Because I have over 60TB of raw storage. Using Amazon Cloud Drive @ 1.5 MB/s it would take me roughly 2 years to do a complete backup - incremental will be faster sure but damn! That first one is a doozy. I considered only backing up the most critical data but even still that's at least 1 year. I've done some comparison with other providers; sure there are other cloud storage solutions that don't throttle that severely but you're either limited to a few hundred gigs or beyond a couple terabytes it gets Enterprise level expensive. The only other reliable service I could find was Crash Plan but there is a huge Reddit thread where people are saying that they are only getting about 1.5 MB/s too and they claim that their service packages are "unlimited". We haven't even officially arrived at the 4K video era yet so folks buying movies in 4K and archiving them in digital media servers... do you see my point yet? If we're stuck doing huge backups at 1.5 MB/s and it takes 1-2 years to do a complete back up, oh god. I've gone through all my files and the best I can do is 13.5 TB of un-duplicated data that I NEED to backup. Is it possible to engineer DrivePool to put files tagged as "duplicated" in separate folders outside the PoolPart* folder so we can at least manually select only un-duplicated data? Please don't make me go back to Storage Spaces.
-
My DrivePool isn't comprised of a mismatched file system. All the drives were formatted ReFS then joined to the DrivePool. I only mentioned that the resulting DrivePool seemed to show up as a Sudo NTFS volume. I'm not sure the fix you proposed would work in my case?

-
MEMORY.DMP - uploading C:\Users\Administrator>fltmc Filter Name Num Instances Altitude Frame ------------------------------ ------------- ------------ ----- DfsDriver 1 405000 0 msnfsflt 0 364000 0 Cbafilt 3 261150 0 DfsrRo 0 261100 0 Datascrn 0 261000 0 Dedup 5 180450 0 luafv 1 135000 0 Quota 0 125000 0 npsvctrig 1 46000 0 Windows 2012 R2 Essentials upgraded to Standard (build 9600) StableBit DrivePool version 2.2.0.692 BETA BSOD Message: KMODE_EXCEPTION_NOT_HANDLED (covefs.sys)
-
Yes. I moved all the files from the root of the logical volume into the DrivePoolPart folder and it showed up in my mounted DrivePool drive. Hence my reference to it only taking a few seconds lending credence that it was just a simple file move on the same drive. Of course I had to move blocks of files from the individual drive roots outside the DrivePool mount point into the DrivePoolPart folder. I fully understand that ReFS isn't supported yet and the NTFS volume that's referenced in Disk Manager is only a sudo reference. It's not a true NTFS volume. I'm wondering... when I Right Click on the DrivePool volume and try to enter Properties, it causes my server to BSOD. I have to use the Shared Folders Snap-In to create network file shares. Is this what you're referring to in regards to the API not being fully linked or the fact that it "looks" like an NTFS volume so Windows is being stupid and trying to execute NTFS API's on an ReFS volume?