gj80
-
Posts
42 -
Joined
-
Last visited
-
Days Won
4
Everything posted by gj80
-
I do. The speeds are amazing. I ran CrystalDiskMark, and I got the speeds they advertised on the product page (http://www.mydigitaldiscount.com/mydigitalssd-480gb-bpx-80mm-2280-m.2-pcie-gen3-x4-nvme-ssd-mdnvme80-bpx-0512/) - ~2700MB/s read and ~1400MB/s write. The price is very competitive too. As far as what Christopher mentioned - yes, it does get very hot when under load. VERY hot. It thermally throttles itself, but not as aggressively as I would like - I've seen its temperature climb above 90C. I did some research and it appears that basically all the nvme drives out there get similarly hot without airflow. This was in an open test bench setup with no airflow. After I set up a quiet 120mm fan aimed in its general direction the temperatures under heavy load became more reasonable (70C or so) and it stopped thermal throttling. The airflow from a norco case with its fan wall should be more than sufficient.
-
It reads SMART data fine since it's just a JBOD controller. I'm not sure about drive spin-down - I keep all my drives on.
-
It picks right back up. I'd attach all the disks first, make sure they're all being seen, and then install DrivePool. The point of doing the disks first just being that it's easier to troubleshoot disks not showing up while DrivePool isn't busy trying to examine the attached disks, in my opinion. If you already installed it, you can just disable the service and then later reenable it.
-
I'm using DrivePool and Stablebit on my new 2016 server with no issues, Jason. I am using the beta versions of both, however. I've also run DP+Stablebit on several Win10 systems.
-
My understanding was that Green drives park regardless of any power management settings set via software. That is, that their controllers do so independent of all the other power management stuff that's OS-controlled... I did check just now, though, and all my drives were either set to "APM -> Max Perf (no standby)" or the APM section was entirely grayed out (which seemed to be the case for a significant number of them).
-
For those who aren't already aware of the issue - some drives (particularly WD "Green" drives) aggressively park their heads (every 8 seconds) to save power. This has caused serious longevity issues with those drives. I was switching disks over to a new server I built, and I noticed the load cycle count was quite high for a lot of drives. For some, I had already used the WDIDLE3 utility in the past, but not for all of them. Since using that tool is such a pain to do, I decided to just write a little script/service to keep the disks alive instead. Posting it here in case anyone else would like to use it. Edit the "KeepDisksAlive.ps1" file for notes, how to install, how to customize if desired, etc. Once installed, it runs as a system service. It writes to "volume paths", so there's no need to have your disks mounted to letters/folders. I don't think it will lead to any appreciable difference in power consumption or wear & tear as opposed to just having disks that don't park themselves in general. I monitored my UPS power consumption and didn't see a difference. Also, I monitored the sum of all my drive's load cycle counts before and after to confirm it's working. I included what I used to do that in a subfolder. (Not a DrivePool issue, but I figured many running DrivePool could take advantage of this) Edit 12/10/2018: Re-uploaded attachment upon request since the old one was reporting not being available. Edit 12/10/2018 Part2: It appears that the forum gives a message about the attachment having been removed. Actually though, you just need to be logged in to download it. If anyone else gets that message, just create an account and try again and you should be good. KeepDisksAlive-v1.0.zip
-
1) Yes, 2016 is supported 2) Yes, that's not a problem. DP works at a file-level, so it isn't concerned with interfaces, block sizes, disk signatures, etc. 3) 42
-
Unsafe Direct/IO didn't work, and none of the "specific methods" did either.
-
Thanks! Sounds like everything should work fine, regardless of duplication settings then.
-
When realtime duplication is disabled, and an already-duplicated file is updated, presumably this file is written to only one drive (out of, say, 2 it was duplicated onto) ... how does DrivePool later know which of the 2 now-different versions of the file to duplicate? I ask this because I'm writing a file auditing / change indexing / integrity-verifying program that utilizes a custom alternate data stream which is added to each file with miscellaneous tracking information. When that happens, the main data stream ($DATA) doesn't change, and I'm using special overrides to disable updating the DateModified values. My guess is that DP probably looks at whichever file has the newest date, and chooses that as the new "master" file and overwrites the other one...maybe taking into account the filesize as well? Since I'm not changing DateModified and I'm writing to an alternate stream (so the primary "file size" would be the same I think), would this end up randomly writing to 1 file only out of a duplicated pair and not getting duplicated? If the answer to that is yes, then - if I have realtime duplication *enabled* and all of the above is true, would my new data stream get duplicated to both duplicates of a file, in spite of the primary file size not changing and the datemodified not changing? I'm not only writing this program for use with DrivePool, but since I obviously use it, I want to make sure it works, and how I need to have it set for it to work properly. Thanks!
-
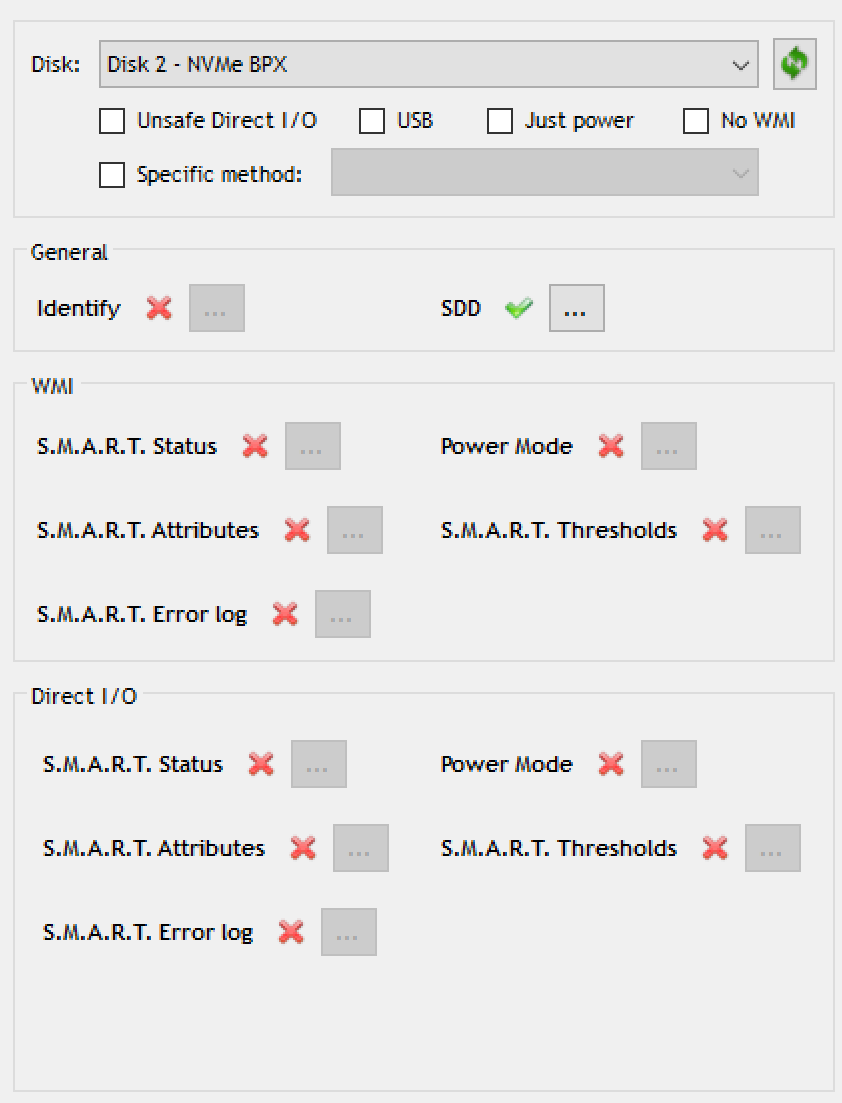
I've switched my desktop over to Windows 10 on one of these: http://www.mydigitaldiscount.com/mydigitalssd-480gb-bpx-80mm-2280-m.2-pcie-gen3-x4-nvme-ssd-mdnvme80-bpx-0512/ CrystalDiskInfo shows the SMART status for the drive, but StableBit.Scanner_2.5.2.3103_BETA says "The on-disk SMART check is not accessible" The DirectIOTest results are attached. Thanks
-
There's no need to have the disks mounted at all for DrivePool's purposes, so you can just go to diskmgmt.msc and remove the letters as far as it's concerned. For snapraid, though, maybe you could mount the disks as folders? http://wiki.covecube.com/StableBit_DrivePool_Q4822624
-
Ah, gotcha. Backups are different than RAID. If you accidentally deleted everything with a stray command, or got hit with a ransomware virus, for instance, all your data would instantly be lost with RAID. RAID's purpose is only to keep systems up in the event of hardware failure. If a copy of your data is not sitting in another system, with versioning handled, then your data is supremely vulnerable. Also, "parity" is just something people say for short when referring to one type of RAID - RAID5 or RAID6 levels (or, in ZFS notation, "RAIDZ" or "RAIDZ2"). If you use DrivePool with 1 file duplication across the entire pool, then it's basically functioning as a RAID1 at that point. If you used no duplication, it would be equivalent to a RAID0 array (striping). Of course, you can customize it further at the folder level, which isn't typical with RAID, so "duplication" is probably the best way to refer to what DP does. You wouldn't need to do anything. The disk would show up in the DrivePool UI, you'd click "add" and you would immediately have that much more space available in the pool. DrivePool takes care of balancing out the distribution of files across the disks automatically on its own. Because it's all file-based, there's no fixed filesystem that needs to be adjusted.
-
When you add a drive to a pool, all that happens to the drive is that a folder named "PoolPart-<IDString>" is added to the root of the drive. You can then cut and paste content from the disk (or not) into that folder. What you put into that folder appears in the overall merged pool. If two matching files on different disks collide, they will both be added and the second/third/etc copy will just be utilized as duplicate copies. Yes, everything is still a plain file. All your DrivePool data on each disk just reside inside of the PoolPart folder on the disk. You should back up the pool drive which presents the merged view of all the individual disks. You could back up each individual disk's contents, but that gets messy imo. You can use any file-based backup tool. VSS is not supported, though. Parity isn't supported - only duplication levels. You can set duplication levels either globally across the entire pool, or at a folder level instead. So, you could choose to not duplicate temporary/unimportant data, and then set 2x on others, and 3-4x on critical document folders/etc. A popular choice is for people to use DrivePool with no replication along with "snapraid" to implement parity. That's a good choice for pools where data is rarely/never deleted/changed, but it's a bad choice for setups where data is being deleted/reworked/etc frequently, since it's file-based RAID which isn't real-time and there's risk of data loss in the event of a rebuild if parity hasn't been recalculated following significant data changes/deletions (additions are fine). I would like parity too, but I much prefer the simplicity and sense of assurance I get from not having to worry about how much I change my data around or how frequently I do it. There really isn't a product which exists today in which there is no compromise whatsoever to running parity - normally the compromise is performance or complexity + lack of flexibility. ZFS is the best parity option imo, but you don't have raw files on the disks in the event of a catastrophe, and the logistics of disk acquisition to do expansion can be tricky. Personally, I prefer being able to just throw a single drive in as I need space, being able to easily just remove a single disk, never having to worry about drive sizes matching, etc. For me, sacrificing space efficiency to get those things is worth it. I understand if other people have different priorities, though.
-
UPSs help, but power supplies still fail, and UPS units go bad as well. In a home lab/etc situation that's one thing, but domain controllers are rarely in that setting. I think it's an understandable decision to force write caching off for the disk holding AD schema. A corrupt domain can be a nightmare.
-
I use Crashplan, and I'm just finishing off my first full backup pass with Syncovery to Amazon Cloud Drive (ACD). I just built out a new Norco 4224 server, which I have sitting beside my current one. Once the Syncovery pass finishes, I'm going to swap the drives into that and then put my current Norco 4220 offsite and run Syncovery sync against that as well. As Christopher said, I'm skittish about only relying on cloud backup. Besides, it gave me an excuse to upgrade my server! lol
-
http://www.newegg.com/Product/Product.aspx?Item=N82E16816101792&cm_re=AOC-SAS2LP-MV8-_-16-101-792-_-Product I've bought and used many of those on several builds of mine with Windows 10 (and also Server 2016) with no issues. It is an HBA with no RAID mode at all, so there's no need to flash it, and it's dirt cheap. I've also been using these in very heavily stressed systems that process upwards of 20TB reads per week and 5-10TB writes over a long period, so I'm quite happy with their stability. If you were to try to use it with an expander, it might get hairy and I wouldn't suggest it (I just don't know what it would or would not work with), but if you're directly connecting it disks/backplanes then it should be fine. The Windows 10/2016 drivers are available on Supermicro's website. It doesn't *say* it supports 10/2016 last I checked, but if you download the driver, the readme specifically states that the latest update is Microsoft WHQL certified for 10 + 2016, and it has worked for me on several systems running both. They come with a full and low profile PCI bracket. Oh, and they're 8-lane PCI-E 2.0 cards.
-
It would be nice if there was a context option in DrivePool for a particular drive to "open in Scanner". I often find myself hovering over a disk in DP to note the model and disk serial number, and then trying to find that drive in Scanner. If there was a way to directly jump from one to the other it would be a nice convenience. Another UI-integration thing that would be useful would be if DrivePool reflected any 'custom names' I set for a disk in Scanner. In Scanner, I will change disk names to stuff like "DAMAGED. Not in Pool. Ready for removal." (because I often evacuate disks remotely, and I'm lazy and don't always get around to physically pulling the disks for some time). In Drivepool, I don't see those custom names when I hover over disks, and it would be helpful if I could. Finally, along the line of being lazy, it would be nice if there was an option in Scanner to "never warn for this disk again". Ie, to instruct Scanner that I know that a drive is wrecked, and to mark it as such, and not warn me about it again. There are options to "not scan" a disk, but in the popup Scanner smart status warnings, the only option seems to be to "never warn me about disks with unreadable data". I do want to be warned, though - just not about that particular disk.
-
There is, but I did some testing of that at work with a client who was all on Windows 10 and had issues with long paths... what Microsoft apparently did was that they added the flag, but they didn't bother to do anything whatsoever beyond that with core applications. What that means is that things which had been recently-compiled did "just work" with long paths, but Explorer actually has explicit coding to disallow saving files in long paths (it throws up error messages, as I'm sure you've seen). Microsoft didn't bother to remove that......which is beyond moronic, but there you go. So, I made a very long series of directories with powershell and had no problems there, but the moment I tried to do things in there with Explorer I started running into weird issues. I could go down past the 260 character limit, but not all the way to the bottom of the series of folders, and Explorer would intermittently throw up its "path too long - I'm not allowing this!" message when I tried to create/modify files. And of course, Explorer not working causes problems with many other things since it's relied upon for open/save dialogs, etc. Thanks Microsoft.
-
I'm not sure what rsync is doing during those "spikes", but I agree with Tim... I'd copy with Robocopy from the windows side (use the multithread flag - /mt) to pull things down. If you put the copy thread count high enough, you'll get drastically faster copy performance than you would with rsync (without chunking rsync out with multiple batches simultaneously). I could see a motivation for using rsync if you were running it against an rsyncd daemon on the other end, because in that case it could do its own CRC validation from one side to the other (default behavior) for extra data validation on top of standard tcpip, but when you're running rsync against a plain file share, that doesn't occur. A heads-up, though - be sure you check your ZFS pool for any file paths (a restriction linux doesn't have, but Windows does) that might extend past (or even come close to) 260 characters (the windows max path limit). Rsync against a Drivepool share will copy the long paths, but you will then be unable to access them using explorer, powershell, etc. I made this mistake, and had a hell of a time dealing with it retroactively - do yourself a favor and shorten them beforehand.
-
Scanner can't detect drives in Storage Spaces
gj80 replied to gameiam2008@hotmail.com's question in General
At home, I love drivepool, and while I'd love to have some kind of checksumming functionality and very much hope it is implement/integrated into drivepool at some point, I prefer the advantages of files being easily recoverable from individual disks, extreme ease of expansion, ability to mix different sized disks, etc. I have a script that generates PARs for large files I throw on my home server anyway, so that takes care of most of my concerns about bitrot. I'd very much like it if Stablebit supported reporting SMART data of Storage Space member drives, however, because at work we have many servers running Storage Spaces (high column count mirrored spaces - the performance is quite good), and it bothers me not having an easy way of monitoring the drive smart statuses. In that setting, I don't really care about the block scanning so much, since Windows is already doing volume scrubs - I just want to get alerts regarding SMART status issues. Imo, it'd be well-worth $30 for that. -
@Spider - If you're interested in writing a DB frontend, and if drivepool already has a database to keep track of the files, then the frontend could just access that database with all the metadata info and then there would be no need to do an "import" at all. If there isn't a database-like functionality to access, however, then direct access to the API probably wouldn't provide much benefit. The two 500mb files the script generates don't really matter, since the only thing that's retained from run to run are the 12mb zip files, which isn't anything of note in terms of space requirements. Once the script is out of testing, I can always just uncomment the lines I've got at the bottom to delete the csv + log after the zip happens, so 1GB is only needed while it's running temporarily, if it matters. If you get a frontend set up, I can always change the PS script to write out to an sqlite file. @Christopher - How does drivepool store the metadata so it knows what file is on what disk, etc? Is it a sqlite file somewhere? I haven't poked around too much into the way drivepool actually operates.
-
Just a million? That's surprising. And unfortunate... Hrmmm. Maybe it would be better if a list of files was just dumped out per disk. I guess I could have it make a folder structure corresponding to all the drives, and have a text file inside with the disk information and a csv with the full list of files. I could split out to a second csv if it exceeds 1 million files on a single disk (not likely, but with an 8TB drive and some file types, maybe....). Having the separate text file with the disk info would reduce the size of the CSV data, as a nice side benefit. ...this is starting to reduce the appeal, though, since it's starting to get more fiddly, and less easy to play "what if" with a master list of all your files. I guess it would still accomplish the overall goal of "a simple list of all the files that were on a particular drive" though. Writing it out to an SQLite database would make the most sense. Powershell can export to SQLite.. the only issue would be writing a front-end. A front-end isn't something I want to tackle for this though. I guess the per-disk thing would probably make the most sense. Realistically, we're not going to be using this for anything other than figuring out what was on a drive in an emergency... thoughts? How big is the uncompressed .csv and how big is the .log? When you zip the csv (try doing it manually if 1.51 doesn't work still), what is the file size of the compressed csv? Thanks Christopher. The dpcmd's output works fine, though, and since I already wrote the regex stuff to parse it, and I'm lazy, I'm fine just sticking with that
-
I uploaded a new "V1.51" In 1.5 I switched the CSV to be unicode (so that it matches drivepool's unicode format in the log format and doesn't fail to work for everyone with non-english language files). Incidentally, the (zipped) size of the CSV only increased ~35% from being unicode. Also, in testing, I noticed that I ended up with one of the 1kb zip files myself. Running it a second time, it worked...so I think there's some timing issue going on. I added a bunch of long sleep timers in the zip function to rule that out, and uploaded a new "V1.51". See if that works for you?