


Mick Mickle
-
Posts
86 -
Joined
-
Last visited
-
Days Won
3
Everything posted by Mick Mickle
-
Norton Warning on StableBit Download Webpage
Mick Mickle replied to Mick Mickle's question in General
Yeah, I figured as much. Thought you'd like to know the latest challenge, though. 🙂 -
(Added from the Scanner General Forum, since the Norton flag is primarily on DrivePool.) FYI, Norton has the download website for either Scanner or DrivePool - I don't remember which - flagged as malicious. I did give a quick "Safe" review for it at the Norton "full report" website tonight. (Hopefully, it wasn't hacked.) You probably want to dispute the warning. Alao, some more "community reviews" besides my one review on Norton would be helpful for the software and website reputation. Also, I noticed that StableBit.DrivePool_2.3.2.1493_x64_Release was missing from my downloads folder, so I found that Norton 360 had quarantined it - probably just too new. No issues at all at VirusTotal (even from Symantec).
-
FYI, Norton has the download website for either Scanner or DrivePool - I don't remember which - flagged as malicious. I did give a quick "Safe" review for it at the Norton "full report" website tonight. (Hopefully, it wasn't hacked.) You probably want to dispute the warning. Also, I noticed that StableBit.DrivePool_2.3.2.1493_x64_Release was missing from my downloads folder, so I found that Norton 360 had quarantined it - probably just too new. No issues at all at VirusTotal (even from Symantec).
-
Some honorable mention for Scanner in the comments of this new article: https://lifehacker.com/how-to-check-if-your-hard-drive-is-failing-1835065626
-
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
It makes a lot of sense to point to 3216 as the sole cause, and the constant rewriting of the Diskid files may be partly to blame in this case, but this is why I think some other factor is involved here: 1. The manual settings backup I made before upgrading didn't restore the custom names for three disks under 3246. (Perhaps the frequent Diskid file writing resulted in corrupt data written to the backup file also?) 2. On the two machines that experienced lost settings after the 3246 upgrade, I uninstalled 3246 and reinstalled 3216 after my post above: Voila! All the settings were back just as before the upgrades. (If the Diskid files had been corrupted, I don't think the reinstallation of 3216 would've brought back correct settings.) (I don't mean to minimize the problem you identified earlier about 3216's frequent writing to Diskid files and the corrupt state they may be left in. That would seem to be a valid cause of lost settings sometimes.) -
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
I upgraded from 3216 to 3246 Beta on two machines. On my WS2012R2E VM, all the settings persisted through the upgrade on 3246, but on my laptop, Scanner lost the settings (disk names, last scanned date). I restored the settings from the last backup made on March 16, but the last scanned time is never -- I guess because March 16 is more than the 30 days I have set for scan interval. I think this is another example of why automatic periodic backups would be a good feature. Edit: I upgraded from 3216 to 3246 on a third machine, WS2012R2, with mixed settings experience. Seven disks kept their custom names and three disks lost all settings. However, for some of the seven disks that kept their names, "Last Scan" data was incorrect, e.g., 286 days when it was actually last scanned within 30 days. Restoring a settings backup made on April 19 didn't change anything. -
Stablebit Scanner loses all settings on unexpected shutdowns.
Mick Mickle replied to FirstAidPoetry's question in General
Thanks, @Wiidesire! Your discovery looks like it might solve the this CDIDW (constant Diskid write) root problem for a number of threads, including the ones I've enumerated below. A useful new Scanner feature, now that the program has effective settings backup and restore, would be automatic backups, for example, weekly. That way, a backup that would more accurately reflect the scanned state of drives might exist when needed. (Manual backups are less likely to have been made within the last scheduled scan window; thus, even though disk names and other settings can be restored, scan history may be older causing new scans of all disks.) https://community.covecube.com/index.php?/topic/3831-scanner-lost-all-data/ https://community.covecube.com/index.php?/topic/4099-stablebit-scanner-loses-all-settings-on-unexpected-shutdowns/ https://community.covecube.com/index.php?/topic/4265-scanner-2543216-upgrade-loses-my-setups/ https://community.covecube.com/index.php?/topic/3707-bug-prior-scan-data-and-settings-not-preserved-on-update/ -
Thanks, @Wiidesire! Your discovery looks like it might solve the root problem for a number of threads, including the ones I've enumerated below, where I've added a duplicate of this post to help close the loop. According to Christopher, Beta version 2.5.4.3246 addresses and fixed this CDIDW (constant Diskid write) issue by increasing the interval from once every second, allowing shutdowns and upgrades with low risk of corrupting the Diskid files and losing scanning history. A useful new Scanner feature, now that the program has effective settings backup and restore, would be automatic backups, for example, weekly. That way, a backup that would more accurately reflect the scanned state of drives might exist when needed. (Manual backups are less likely to have been made within the last scheduled scan window; thus, even though disk names and other settings can be restored, scan history may be older causing new scans of all disks.) https://community.covecube.com/index.php?/topic/3831-scanner-lost-all-data/ https://community.covecube.com/index.php?/topic/4099-stablebit-scanner-loses-all-settings-on-unexpected-shutdowns/ https://community.covecube.com/index.php?/topic/4265-scanner-2543216-upgrade-loses-my-setups/ https://community.covecube.com/index.php?/topic/3707-bug-prior-scan-data-and-settings-not-preserved-on-update/
-
Thanks, @Wiidesire! Your discovery looks like it might solve the root problem for a number of threads, including the ones I've enumerated below, where I've added a duplicate of this post to help close the loop. According to Christopher, Beta version 2.5.4.3246 addresses and fixed this CDIDW (constant Diskid write) issue by increasing the interval from once every second, allowing shutdowns and upgrades with low risk of corrupting the Diskid files and losing scanning history. A useful new Scanner feature, now that the program has effective settings backup and restore, would be automatic backups, for example, weekly. That way, a backup that would more accurately reflect the scanned state of drives might exist when needed. (Manual backups are less likely to have been made within the last scheduled scan window; thus, even though disk names and other settings can be restored, scan history may be older causing new scans of all disks.) https://community.covecube.com/index.php?/topic/3831-scanner-lost-all-data/ https://community.covecube.com/index.php?/topic/4099-stablebit-scanner-loses-all-settings-on-unexpected-shutdowns/ https://community.covecube.com/index.php?/topic/4265-scanner-2543216-upgrade-loses-my-setups/ https://community.covecube.com/index.php?/topic/3707-bug-prior-scan-data-and-settings-not-preserved-on-update/
-
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
Thanks, @Wiidesire! Your discovery looks like it might solve the root problem for a number of threads, including the ones I've enumerated below, where I've added a duplicate of this post to help close the loop. According to Christopher, Beta version 2.5.4.3246 addresses and fixed this CDIDW (constant Diskid write) issue by increasing the interval from once every second, allowing shutdowns and upgrades with low risk of corrupting the Diskid files and losing scanning history. A useful new Scanner feature, now that the program has effective settings backup and restore, would be automatic backups, for example, weekly. That way, a backup that would more accurately reflect the scanned state of drives might exist when needed. (Manual backups are less likely to have been made within the last scheduled scan window; thus, even though disk names and other settings can be restored, scan history may be older causing new scans of all disks.) https://community.covecube.com/index.php?/topic/3831-scanner-lost-all-data/ https://community.covecube.com/index.php?/topic/4099-stablebit-scanner-loses-all-settings-on-unexpected-shutdowns/ https://community.covecube.com/index.php?/topic/4265-scanner-2543216-upgrade-loses-my-setups/ https://community.covecube.com/index.php?/topic/3707-bug-prior-scan-data-and-settings-not-preserved-on-update/ -
Apparently, yes: Either a crash or planned shutdown could result in corrupted Diskid files because they were being constantly written.
-
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
Chris, I've been using 2.5.4.3216 for a long time now, and it's working well on multiple installations, with this exception: Almost any reboot of my WS2012R2E VM, planned or otherwise, results in Scanner losing all its data. I've been making backups in advanced settings, but not regularly, so even though I can get back to tailored names, the scanning history is usually too old and requires all the drives to be rescanned. Do you think the disk id's being updated too often, as summarized above, would also be the cause of my problem? And 2.5.4.3246 could be the remedy? -
Thanks, Christopher. I agree. Currently, I have a SMART warning just for LCC, so I did permanently ignore it.
-
CrystalDiskInfo worked fine so far to reduce the timing on Seagate. At least it will ease my mind even if the LCC isn't critical. I posted results at the pinned thread:
-
Load Cycle Count on Seagate Backup Plus 5TB
Mick Mickle replied to matthew.austin's question in General
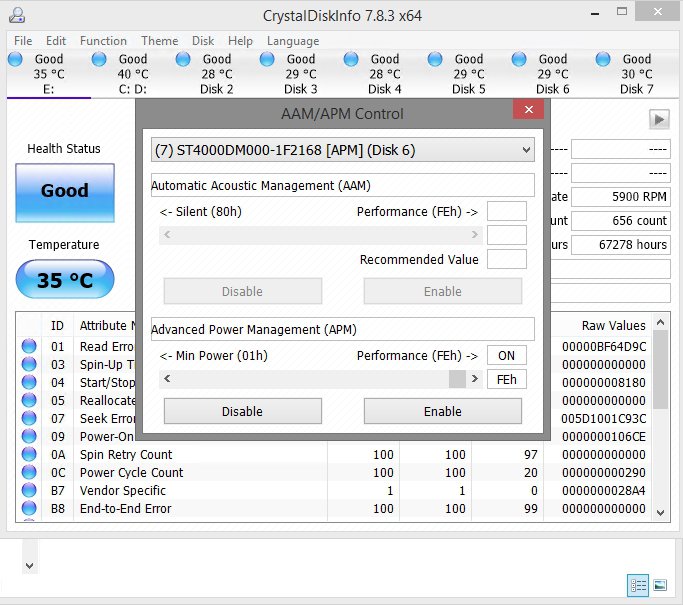
Thanks for this tip! CrystalDiskInfo 7.8.3 x64 worked better for my Seagates than WDidle3 for WD, and I didn't even have to remove them from the server. Over a 5-day period of testing, one ST4000DM000 drive that had a LCC of nearly 250,000 in 2 years dropped to a rough estimate of 1 head park per 8 minutes after I set the APM midway at 80h, and the other ST4000DM000 that was sitting at 369,149 LCC had the park timing reduced to about once every 20 minutes when set to highest performance FEh. The first setting should result in an annual LCC less than 70,000, and the second should be less than 30,000 a year. It might not be critical to lower the parking rate in aggressive parking drives, but it should minimize Scanner's red flag for high LCCs that would otherwise be thrown, and it can be one less thing to be concerned about.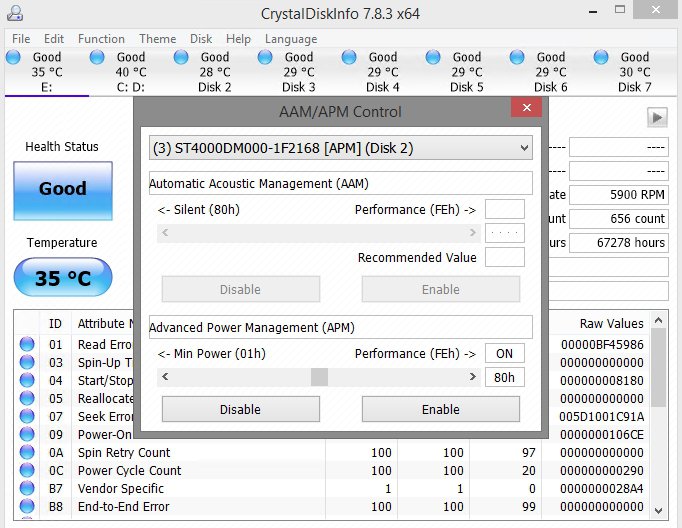
-
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
Related? -
I've been noticing this as well several times with V. 2.5.4.3216 in a VM when it restarts. I thought this was somewhat related to the thread for preserving data when upgrading, because I thought the json methodology would keep this problem from happening when a machine was turned off or crashed. (I referenced this thread over there as well.) Anyway, the backup/restore settings function works well, especially now that it uses one zip file. But...but...but... if you haven't backed up recently, your scanning history will be older than the 30-day rescan default, and all the disks will need to rescan.
-
Thanks, Christopher. That's what I thought from earlier comments you've made. How about this question concerning "Ignore S.M.A.R.T. Warning" in Scanner?
-
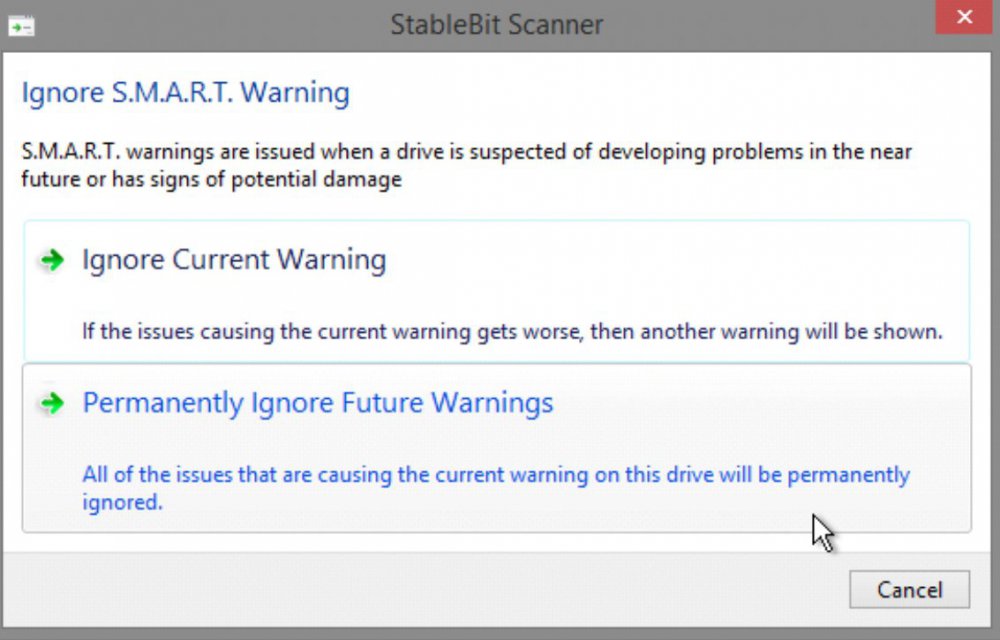
Well, I should have checked other posts here first. I see a lot of relevant conversation on the pinned thread here: So I'll try out some of what's discussed. And I see that the current (a few years ago, anyway) conventional wisdom seems to be not to worry about high LCC on aggressive-park designed HDDs unless other problem indicators develop. Still, it's disconcerting to see the out-of-tolerance measurements in SMART reported by Scanner. Note that the referenced thread above doesn't address the newer Seagate drives such as Iron wolf which use EPC. According to Seagate, most of the drives made since 2016 use that power management feature, and the new SeaChest program accesses the feature, even in 64-bit Windows. There's some discussion about it over here: https://forum.synology.com/enu/viewtopic.php?t=125401&start=45 On a slightly different topic, if I don't ignore the LCC warning, I don't get more warnings from Scanner that the LCCs are getting worse (Good!). If I ignore the current warning, I'll get another warning almost immediately as the count goes up. The permanently ignore option is clear if there is only one SMART condition (like LCC) to deal with. But it's not clear to me how that works if there are two or more flagged SMART conditions, such as both LCC and Reallocated Sectors Count. It looks like I would never get another warning about either if I chose Permanently. However, while I wouldn't want to be bothered with LCC warnings, I would want to know if the Reallocated Sectors continued to increase. Clarification?
-
I've got a couple of ST4000DM000 4TB drives that I'm using in my server (removed from original external USB enclosures). One is now over the 300,000 Load Cycle Count limit, and another is close to it. So, basically, they have the green WDC drive problem that WDidle3 fixes by changing the timing from 8 to 300 seconds. Seagate now has a SeaChest program that will change timing of newer drives that use EPC (Extended Power Conditions), but ST4000DM000 apparently predates EPC. Any ideas on how to minimize the load cycle count on these drives to prolong their lives?
-
File duplication from local to cloud possible?
Mick Mickle replied to Stuart_75's question in General
Ha! Got it. Just had to put my mind in 3D mode. If I'd ever experimented with hierarchical pooling (or even thought about it deeper -- no pun intended, truly), I would have realized we weren't talking about parallel level folders. -
File duplication from local to cloud possible?
Mick Mickle replied to Stuart_75's question in General
If you've already moved them, there's probably no need to do it again. Umfriend was describing in "Wrt step 4" how to move the location address of the files within each individual drive (E: then F: then G:) rather than physically copying and deleting the files themselves. As you probably know, if you move a file, no matter how big it is, from one folder to another using Windows/File Explorer, the action is almost instantaneous since Windows simply points to the new location -- like changing the page number in the table of contents or index. You can do the same thing by moving files between the PoolPart.* folder (that represents the DrivePool pool) and another folder outside of the PoolPart.* folder on the same drive (e.g., E:). So if folder PoolPart.xxxxx represents Pool A on Drive E: and folder PoolPart.yyyyy represents Pool B also on Drive E:, you can move the files between those two folders quickly, since the operation would just change the address of the files. The long alternative would be physically moving the files into the drive letter that represents Pool B. Again, if you can confirm that the files are now in Pool B, you completed the race but didn't take the shortcut. I guess "upper" and "lower" PoolPart folders is how they are sorted in Windows Explorer, and PoolPart for Pool A is named closer to "A" in the alpha sort, maybe because it was created first? -
File duplication from local to cloud possible?
Mick Mickle replied to Stuart_75's question in General
If I understand the Drive Usage Limiter Balancer correctly, the way you've got it set up, the local drives, E: - G:, will have no duplicated files; only unduplicated. Since you only have one drive, the Google Drive (J:), checked to hold duplicated files, I'm not sure what the effect is. I think you need to have at least two drives for duplicated files, otherwise you have no protection or reason to duplicate if one of the drives fails. Perhaps if you also check one of the local drives (the one with the photo folder that you want to duplicate) for duplicated as well as unduplicated, DrivePool will keep a copy on both the Google Drive and that local drive. (However, I'm shooting from the hip and haven't played with multiple pools, which it sounds like you're describing in the first post. Your screenshot makes it looks like the Google Drive is just another drive in the same pool.) -
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
I'll not convinced that the json file scheme is a panacea, yet. (I had a power outage crash while using json structure, and lost the settings - one of my posts above. Previous file/folder versions in properties didn't help either, although I did have previous versions.) Best bet, so far, is the new backup/restore in advance settings. And, "Yes", an upgrade warming is in order. -
[Bug?] Prior scan data and settings not preserved on update
Mick Mickle replied to Jaga's question in General
You didn't say which version you upgraded from, but it sounds like it was 3062 or earlier (pre-json files); otherwise, you'd probably have already encountered this issue. Jaga gave you good methods above, but you will have had to have a backup from which to restore the folders where the prior version Scanner settings are. If so, uninstall the new version, make sure the Scanner service is stopped, restore the old data folders from your backup (any old backup date is good, assuming you haven't done major physical HDD changes in a while), reinstall your previously well working Scanner version, and you should be back where you were. I've reinstalled the older version many times as described here: Lost All Configurations under Disk Settings after Upgrade. Here's the kicker: If you are able to successfully get back to your tailored settings, locations, etc., I recommend you take a screen shot of the GUI and print it out after pasting in Paint, so you can manually enter all that info when you do upgrade. Sure, it'll be a PITA, but at least you can move forward into the newer versions. Also, the individual disk scan status and history will be reset on upgrade, but new scanning will take care of itself, so it's not really a big deal. Once you have the newest version, manual backup and restore of settings, including scan status, is built in. And it works, so subsequent upgrades can have settings manually restored (staying on the latest version) even if the upgrade process happens to give Scanner amnesia.

