Search the Community
Showing results for tags 'Performance'.
Found 10 results
-
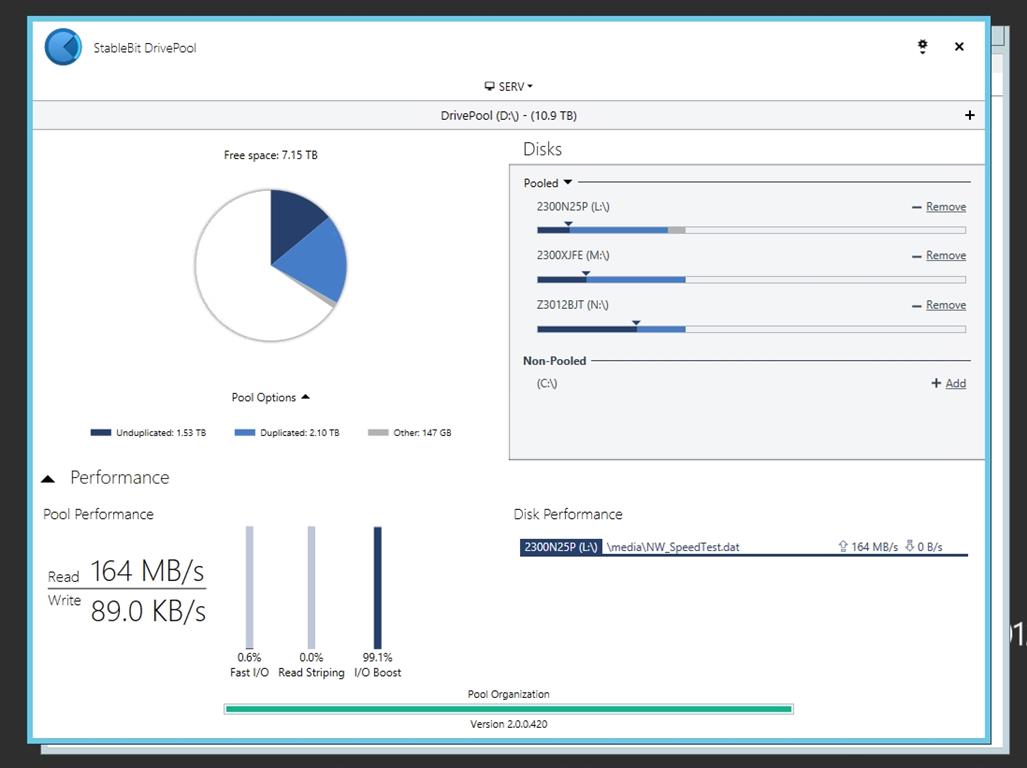
I'm 9 days into my DrivePool adventure. I saw my Read Striping vertical bar look like this tonight. It contains a color that isn't shown on the reference in the User Guide (reference link). The percentage also seems mysterious, as only all 3 colors combined would add up to 99.3% Anyone able to share some hard-earned knowledge with a curious mind? Thx in advance.
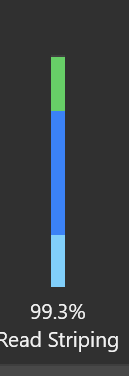

-
I use 2 disks in drive pool. When use one single drive, the sequence reading or writing speed is about 160-240MB/s. When I change No Duplicate to 2x Duplicate, duplication start automatically. However, the duplicate speed will drop down from 100MB/s to 20MB/s, and the physical disk usage will increase from 60% to 100%, if click "Increase Priority" button. By the way, files being duplicated is big big files. This is awful. Hope it will be fixed. By the way, why read striping doesn't improve any performance when reading one big 2x-duplicated file? Reading speed can never be over 250MB/s.
-
There is a couple of issues and questions about measuring. Why it is not optimized / cached / smarter? Case 1: If there is a pool of 2 or more drives and one is disconnected for whatever reason - once the drive is back entire pool is measured. If that is large, cloud based pool with a lot of small files - a short interruption in connectivity triggers hours of measuring. Would that be possible to cache results of previous measure run and measure only the drive that was reconnected? Case 2: Four cloud based drives CLD1, CLD2, CLD3 and CLD4 are coupled in two pools: CLD1+2 and CLD3+4. Those two are paired again as a pool CLD1+2&CLD3+4. And this pool is coupled with physical drive in the highest level pool: HDD1&CLD1+2&3+4. Apart from CLD1+2 and CLD3+4 - every other pool is set to duplicate all files. Now - when measure is running it is starting from the highest level, then is measuring middle tier and two on the lowest level. So files on the cloud based drives are actually measured three times. Would that be possible to start from the lowest level, then cache and re-use data it on higher levels? Why it is so sensitive? Case 3: Let's say there is more than one pool running measure. As far as I can see this is slightly misleading - as only one pool can be measure at a time - other pools are actually awaiting. If for whatever reason one drive in the pool that is NOT currently effectively being measured disconnected and reconnected - measure on the other drive is restarted. Why..? And is it possible by change in configuration to allow more than one measure thread to run? Would that be possible to set specific measure order for pools? Case 4 (feat. CloudDrive): As mentioned above - short interruption in internet connectivity can disconnect all cloud drives, enforce manual intervention (re-connect) and massive re-measure. Would that be possible to make CloudDrive drives a bit more offline-friendly and disconnection resistant ? In cases when there is no pool activity from users? And can we receive some feature that will automatically re-connect cloud drives, please? Thanks EDIT: typos, wording
-
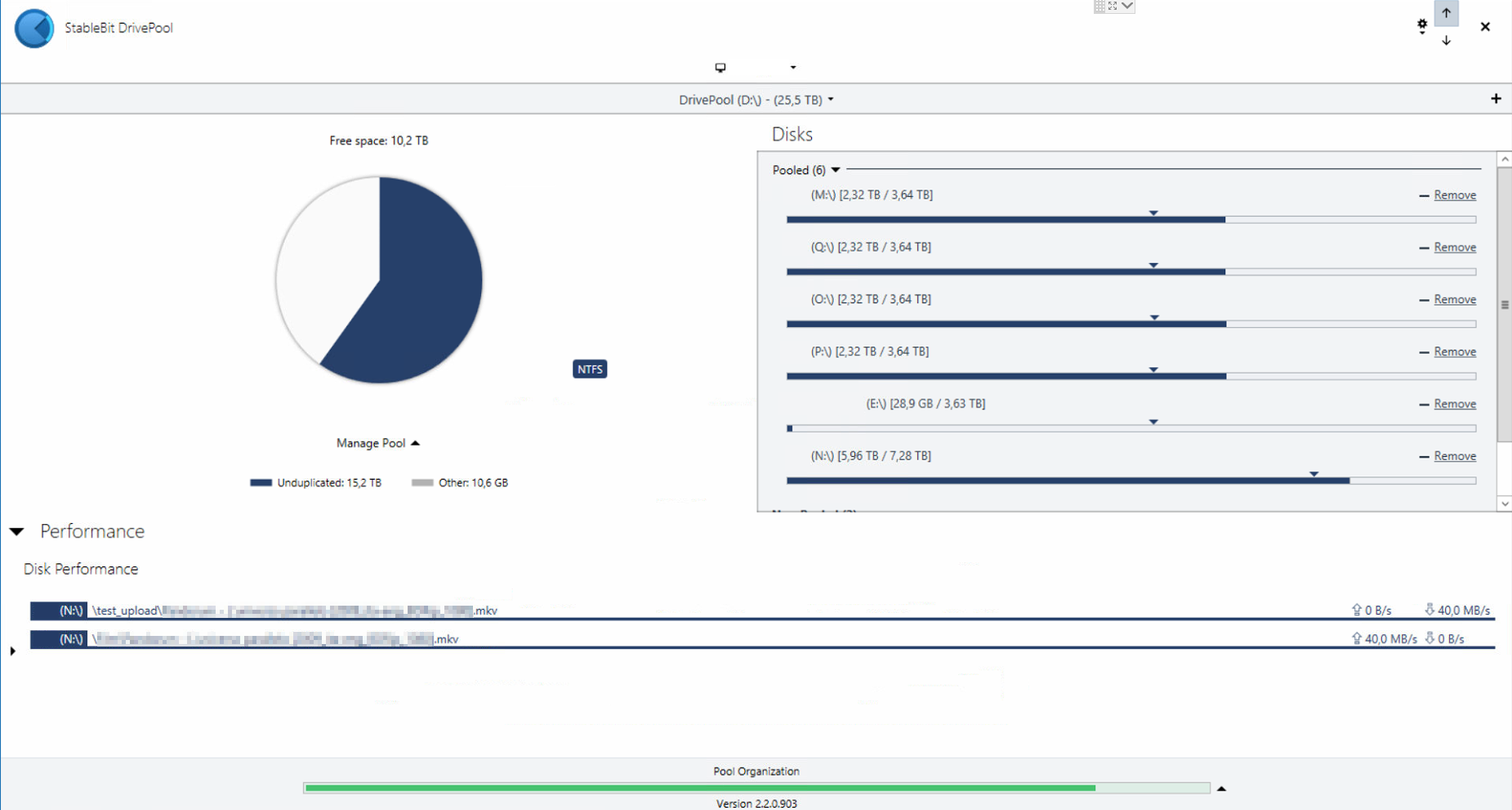
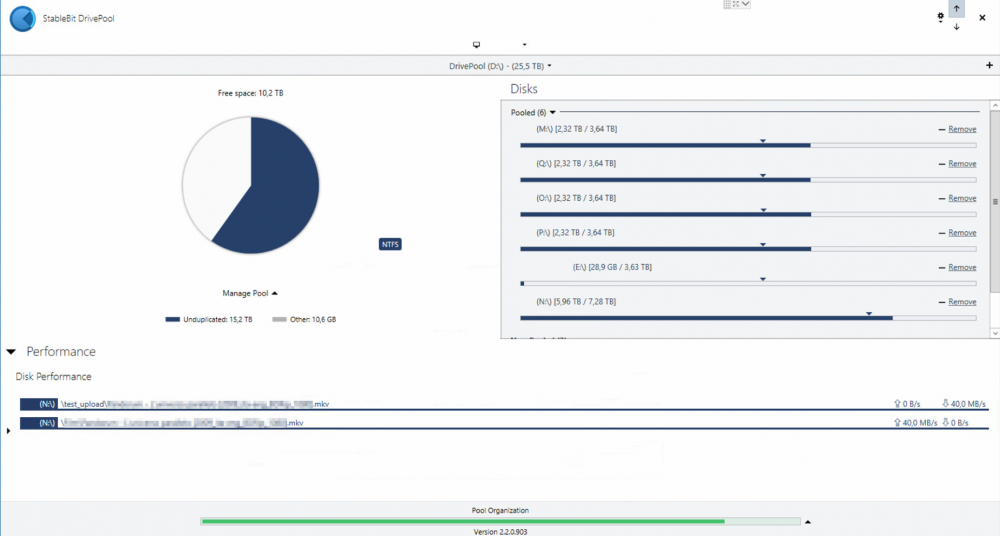
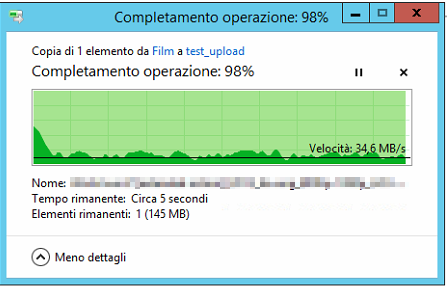
Hi, referring to this post and how DrivePool acts with different size drives, I found myself copy/pasting a file and DrivePool used the same drive for the entire operation (as the source and the destination). This resulted in a really poor performance (see attachments; just ignore drive "E:", there are some rules that exclude it from the general operations). Same thing extracting some .rar files. Is there a way to make DP privilege performance over "available space" rules? I mean, if there is available space on the other drives it can use the other drives instead of the "source" one. Thanks
-
My original plans for a new disk layout involved using tiered storage spaces to get both read and write acceleration out of a pair of SSDs against a larger rust-based store (a la my ZFS fileserver). This plan was scuppered when I discovered that Win8 Does Not Do tiered storage and I'd need to run a pair of Server 2012R2 instances on my dual-boot development and gaming machine instead. I'm currently using DrivePool with the SSD Optimiser plugin to great effect and enjoying the 500MB/sec burst write speeds to a 3TB mirrored pool... but although read striping on rust is nice it doesn't yield the same benefits it would against silicon. Would it be possible to extend the SSD Optimiser plugin to move frequently- or recently-accessed files to the SSDs? It would in fact be sufficient to merely copy them, treating that copy as 'disposable' and not counting towards the duplication requirements. Possibly an easier approach might be to partition the SSDs as write cache and read cache, retaining mirroring for the write cache 'landing pad' and treating the read cache as a sort of RAID0? Based on my understanding of how DP works, this might mean that the read cache needs to be opaque to NTFS, but that's certainly a reasonable tradeoff in my use case (I was expecting to sacrifice the entire storage capacity of the SSDs). I know it's possible to select files to keep on certain disks, which is a very nice feature and one I wish eg. ZFS presented (in a 'yes, I really do know what I want to actually keep in the L2ARC, TYVM' sort of way) but an auto system for reads would be good too. Bonus points for allowing different systems on a multiboot machine to maintain independent persistent read caches, although I suspect checking and invalidating the cache at boot time might be a little expensive... Looking at the plugin API docs, implementing a non-file-duplicate-related read cache does not appear to be currently possible. It seems to be a task entirely outside the balancer's remit, in fact. Is this something considered for the future?
-
Good evening everyone. I found this very interesting, fascinating even: I had just set up a Windows 2012-R2 Storage Server, with ~20 TiB of drives to function primarily as a media server running Emby and file-server endpoint for various backups of machine images etc. CPU: Intel Core i7-4790K RAM: 32 GiB DDR3 2666MHz. OS is hosted on an M.2 PCIe 3.0 x4 SSD (128 GiB) *screaming fast*. 5 x 4 TiB HGST DeathStar NAS (0S003664) 7200 RPM/64 MB cache SATA-III Initially, the machine was set up with one large mirrored storage pool (no hot spares) composed from 5 primordial 4 TiB HGST sata-III disks all connected to sata-III ports on the motherboard (Z97 based). The graph below was taken during the process of copying ~199 files in multiple directories of various sizes (15K - 780 GiB) for a total of ~225 GiB. Fig 1: Copy To Storage Spaces 2012-R2 mirrored pool What isn't apparent from the graph above are the *numerous* stalls where the transfer rate would dwindle down to 0 for 2-5 seconds at a time. The peaks are ~50 MB/s. Took *forever* to copy that batch over. Compare the above graph with the one below, which is another screenshot of the *exact* same batch of files from the exact same client machine as the above, at almost exactly the same point in the process. The client machine was similarly tasked under both conditions. The target was the exact same server as described above, only I had destroyed the Storage Spaces pool and the associated virtual disk and created a new pool, created from the exact same drives as above, using StableBit DrivePool (2.1.1.561), transferring across the exact same NIC, switches and cabling as above also. More succinctly: Everything from the hardware, OS, network infrastructure, originating client (Windows 10 x64) is exactly the same. The only difference is that the pooled drives are managed by DrivePool instead of Storage Spaces: Fig 2: Massive file transfer to DrivePool (2.1.1.561) managed pool. What a huge difference in performance! I didn't believe it the first time. So, of course, I repeated it, with the same results. Has anyone else noticed this enormous performance delta between Storage Spaces and DrivePool? I think the problem is with the writes to the mirrored storage pool, I had no problems with stalls or inconsistent transfer rates when reading large batches of files from the pool managed by Storage Spaces. The write performance is utterly horrid and unacceptable! Bottom Line: The combination of drastically improved performance with DrivePool over Storage Spaces, plus the *greatly* enhanced optics into the health of the drives provided with Scanner: DrivePool + Scanner >>>> Storage Spaces. Hands Down, no contest for my purposes. The fact that you can mount a DrivePool managed drive on *any* host that can read NTFS is another major bonus. You cannot do the same with StorageSpace managed drives, unless you move all of them en-bloc. Kudos to you guys! <tips hat>
-
I'd like to pool 1 SSD and 1 HDD and with pool duplication [a] and have the files written & read from the SSD and then balanced to the HDD with the files remaining on the SSD (for the purpose of [a] and ). The SDD Optimizer balancing plug-in seems to require the files be removed from the SSD, which seems to prevent [a] and (given only 1 HDD). Can the above be accomplished using DrivePool? (without 3rd party tools) Thanks, Tom
-
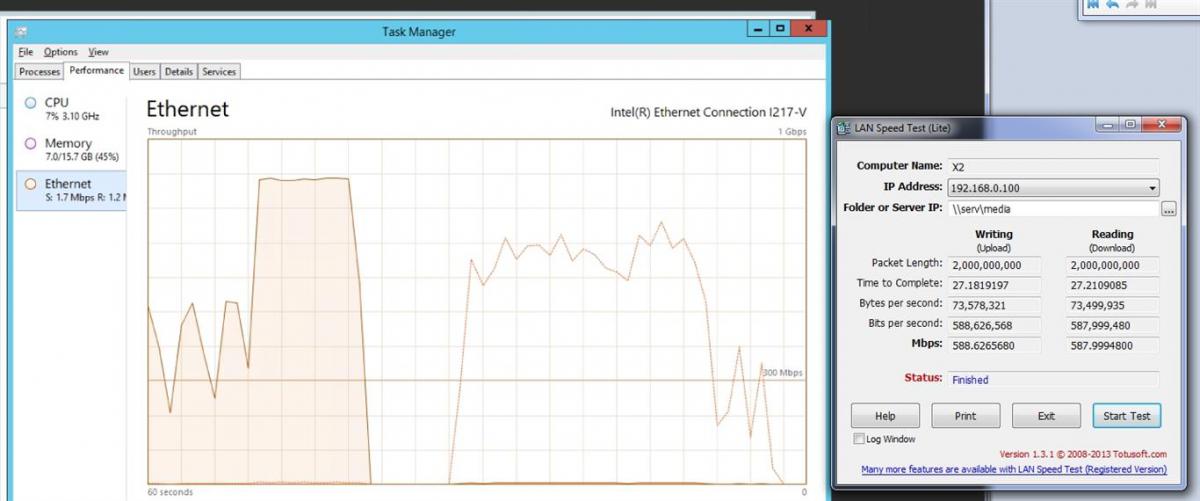
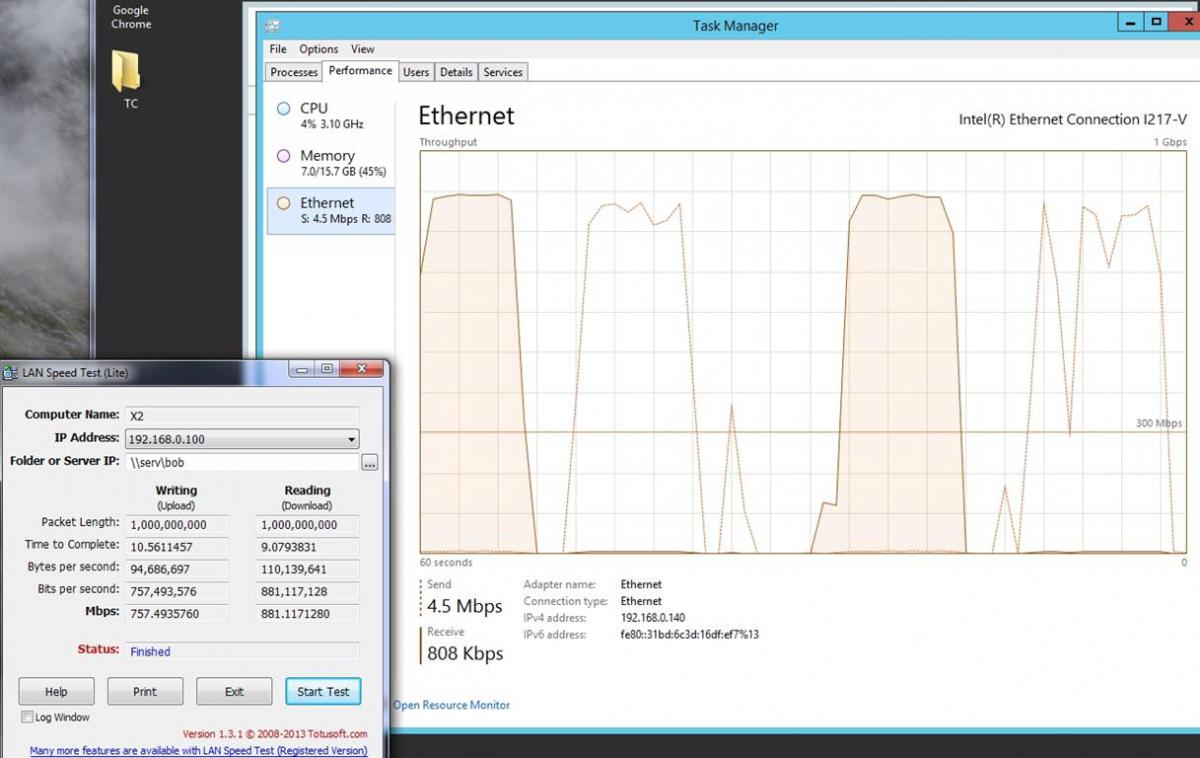
I'm running drivepool on Windows 2012 R2. I noticed slower than usual performance on a share stored on the drivepool. I' utilized LAN speed test to test out some of my suspicions. I consistently get 800+Mbps/~100MBps on a share that is on the raw hard drive that is part of a drivepool. However when I do the same test on a folder in the drivepool (actually on the virtual drivepool drive), performance consistently lags down to 600Mbps/~70MBps. I've enabled all the Diskpool I/O performance options (network, etc...) Looking at the performance monitor on Drivepool UI, it shows its reading the file at what should be quicker performance, e.g. 150+MB/s. Any input? I've attached pictures showing performance tests, etc...
- 10 replies
-
- 1
-

-
- performance
- share
- (and 1 more)
-
Is it normal for the Windows Server 2012 Essentials Dashboard to become extremely slow and in some cases unresponsive when Scanner is scanning drives? Currently Scanner is checking the health of two drives simultaneously that are connected to separate SAS controllers. I am running the latest stable release of Scanner.
-
Environment: Windows 8, 64 Bit - StableBit Drivepool 2.00.355. Four drives pooled into one pool. Shared over my G-bit network. Currently testing the latest release 2.00.355 I have following issue with data throughput. Copying large files (e.g. over 40GB) over my G-BIT network I have a no constant data throughput by writing the file on the pooled and shared device. Throughput falls and raises again in betreen of 70 to 115MB/sec. By watching the new perf. monitor I see the measurement of the file written into my pool for 2 to 3 seconds (with 115 MB/sec). After that time Drivepool shows no activities (but my file is still copying to the shared drive). Then again perf. monitor shows the file activity of the pool. After 2-3 seconds again shows no activities. This symptom continous until the copy process ends. First I thought that the buffer cache of Windows could be the root cause, but trying to copy with windows explorer shows the same symptom that the data throughput raises and falls in a cycled manner. To test other unknown issues I have tried the following: a) activated and deactivated the given performance options in DriveBender GUI (network boost, real time ....) without any change in performance. 1) Tested with an other pooling software "Drive Bender". Migrated my 4 drives to a pooled and shared volume in my network. Copying the same file delivered a constant throughput of around 110 MB/sec. 2) Tested with an other pooling software "FlexRaid". The same as with Drive Bender, a constant throughput of around 112 to 114 MB/sec. Therefore I have to assume that only in combination with DrivePool I have this symptom with and steady performance drop and raise by copying large files on the generated pooled drive by using drivepool. Any Idea how to figure out the root cause with my performance issue in combination with DrivePool? Are there any other users who had the same issue and found a workaround / fix for this issue? thank you Rainer (greeting from vienna, austria)