zeroibis
-
Posts
61 -
Joined
-
Last visited
-
Days Won
3
Everything posted by zeroibis
-
Yea that makes sense, honestly I do not really care how it reports it on the higher pool. The more important thing is for the balancing to actually work correctly. The simplest solution would be to have the balance operation recheck and adjust the goal posts while underway so that it is not able to overshoot or infinite loop itself.
-
So currently you have: A pool with files A drive not in a pool with files You want: A pool with files also containing the drive that is currently not in the pool and its files also in the pool. How to: Add the existing drive that is not in a pool to the pool. This will create a hidden folder on that drive called pool part or something like that. The contents of that folder is what shows up in the pool. So in order to have your files on this drive show up in the pool just move the files to this folder. The will now be in the pool. If the folder names are different they will be in different folders.
-
I mean the data is already in the program and it is the same program. Nothing is really changing here with respect to file placement only how the program internally reports the data. As I have stated before I think it is logical that the files in the higher pool not be labeled "duplicated" because that may lead users to believe that duplication is turned on at that pools level. Instead it should label them something else like "duplicated by child pool". Also nowhere is anyone asking or wanting a higher pool to inherit any settings, it should not be doing that.
-
Oh you mean a mix of duplication levels within a pool. What is interesting is I am not even sure how they would achieve this or why. For example for that to actually happen the following would be needed. Pool A: Contains the pool part folder for Pool Z Pool B: Contains the pool part folder for Pool Z Pool A: Configures custom duplication settings to an individual file or group of files in the pool part folder for Pool Z Pool B: Configures custom duplication settings to an individual file or group of files in the pool part folder for Pool Z Issue Files and folders within these pool parts can be moved at any time and then your duplication rules will not match. Solution: They should apply these rules at the Pool Z there is no logical reason to not do this unless they are not using balancing. It does not make sense to be for that type of duplication method to be supported or encouraged. It is one thing to have duplication applied to an entire pool and then make that pool part of another pool. I could also see making duplication enabled only on the entire pool part folder. However, if you are wanting to have duplication at the individual file and folder level within a pool part folder whos contents you then want to balance to another pool where you do not and logically could not have this identical configuration set is insane. You are right that a simple solution to the balancer is to have it adjust the goal posts as it goes. I would imagine the programing of that logic to be more copy pasta than trying to write a bunch of new math into it lol.
-
It is actually pretty easy. Right now due to a bug it is seeing half of the data on the underline pools as other. Once it no longer categorizes them as other it will then balance the correct amount of data. If it did matter in so far as the calculations are considered it just needs to divide the balance operation by the duplication setting of the underline pool. The actual file operations as they work now do not need to be changed. So the difference would be: Currently: 6TB = 3TB Movable Files, 3TB Unmovable Files 4TB = 2TB Movable Files, 2TB Unmovable Files So to balance it can only move the movable files and thus it tries to move 1TB becuase 6-1=4+1. However in this case the other data will also move every time it moves the movable data. So instead of moving 1TB likes it thinks it is doing it actually moves 2TB creating an infinite loop. ------------------------------------------------------ After the bug is fixed 6TB = 6TB of 2x duplicate files = 6/2 =3TB Unique files 4TB = 4TB of 2x duplicate files = 4/2 = 2TB Unique files 3-1=2+1 so move 1tb of files. Another example: 9TB = +TB of 3x duplicate files = 9/3 = 3TB Unique files 4TB = 4TB of 2x duplicate files = 4/2 = 2TB Unique files Obviously I am assuming the pools in these examples have the same total storage size but you can do the math and see that it works out pretty simply. The key is that all the program needs to do different than it does now as far as balancing pools with file duplication is to divide the balance action by the duplication setting on the pool it is modifying to take into account the multiplication effect of duplication. 40TB pool with 4 10TB drives with 4x duplication with 12TB of data in the pool. This pool is 30% full. a new 40TB pool with 2 20TB drives is created and 2x duplication is enabled. This pool is 0% full. The two above pools are added to a new pool and this pool now balances the data of the duplication pools. How much needs to be moved to balance. Members: Pool A: 40TB with 12TB used 30% full 4x duplication Pool B: 40TB with 0TB used 0% full 2x duplication We need to look at the real space in order to figure it out. How much free space is there for unique files on Pool A? 40/4 = 10TB How much free space is there for unique files on Pool B? 40/2 = 20TB So how much space is actually being used on Pool A 12TB/4=3TB -> 3/10 = 30% ok so far so good However, if we reduce files on pool A by 50% we only increase the usage on pool B by 25%. Thus we need to move twice as much as we expect to. So how do we know how much to move? We still have 3TB of unique data but we now have 10TB+20TB of total storage space for unique files. Our new total % of used storage space is thus 3/30 or 10%. So if each pool is 10% full their totals will add up to the 10% full that the new total is. Pool A 1TB = 10% full Pool B 2TB = 10% full So if we currently have 3tb of unique files on Pool A we need to remove 2tb worth and move them to pool B. This will result in: Pool A: Remove 2TB unique files = 2*4 -8TB of data so 12-8= 4TB or 10% full Pool B: Add 2TB unique files = 2*2 of data so 4TB or 10% full. Here is just the raw math: Pool A: 40TB with 12TB used 30% full 4x duplication Pool B: 40TB with 0TB used 0% full 2x duplication Balance Calculation: Space for unique files: Pool A: 40TB/4 = 10TB Pool B: 40TB/2 = 20TB Total Space for Unique Files = 30TB Space used by unique files: Pool A: 12TB/4 = 3 Pool B: 0TB/2 = 0 Total Space used by unique files = 3TB Current Space Used by Unique files as a % Pool A: 3TB/10TB = 30% Pool B: 0TB/20TB = 0% Total Current Space Used by Unique files as a % = 3TB/30TB = 10% Target % used for members to be balanced = 10% Pool A: 30% - X = 10% -> X = 20% Pool B: 0% - X = 10% -> X = 10% Convert from % to TB to move: Pool A: 10TB*20% = 2TB Pool B: 20TB*10% = 2TB 2TB = 2TB Conclusion: Move 2TB of unique files from Pool A to Pool B Pool A: Remove 2TB unique files = 2*4 = 8TB of data so 12-8= 4TB or 10% full Pool B: Add 2TB unique files = 2*2 of data so 4TB or 10% full. I think you also get the idea from the above math as to how a system with more than 2 pools would operate in so far as finding how much to remove and add to each one.
-
Nice, yea the balance issue is caused by this issue. Because the balance program can only logically move data other than "other" it does not count "other" data when making the calculation. So if I had 2 pools like in my case and one pool had 6tb total used and another had 4TB total used and it was seeing half the data as other the decision goes like this: 6TB = 3TB Movable Files, 3TB Unmovable Files 4TB = 2TB Movable Files, 2TB Unmovable Files So to balance it can only move the movable files and thus it tries to move 1TB becuase 6-1=4+1. However in this case the other data will also move every time it moves the movable data. So instead of moving 1TB likes it thinks it is doing it actually moves 2TB creating an infinite loop. So my expatiation is that once they fix the bug of the data showing up as other this will correct the balancing bug as well. In order to recreate the balance issue you need to use enough data to have it so out of balance that it can never get within the 10% or 10GB condition to stop.
-
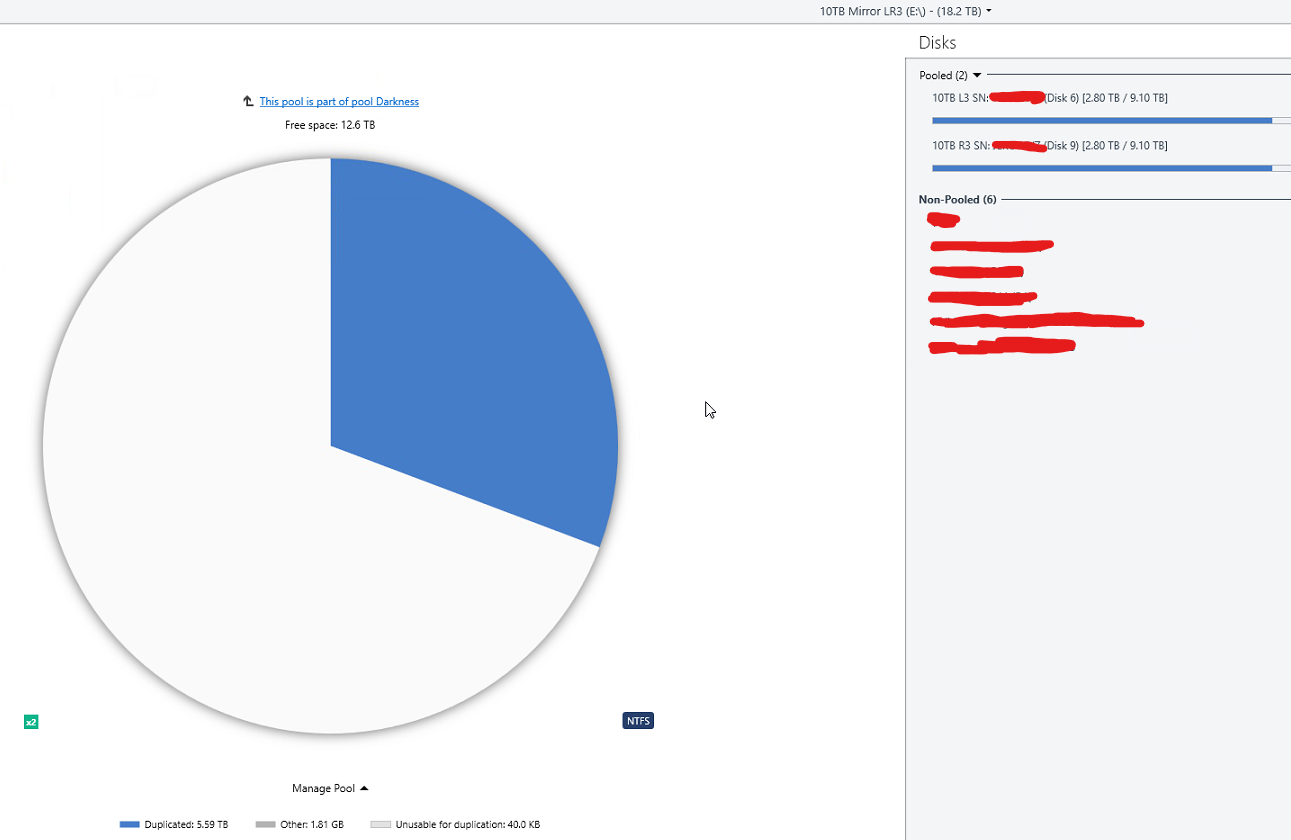
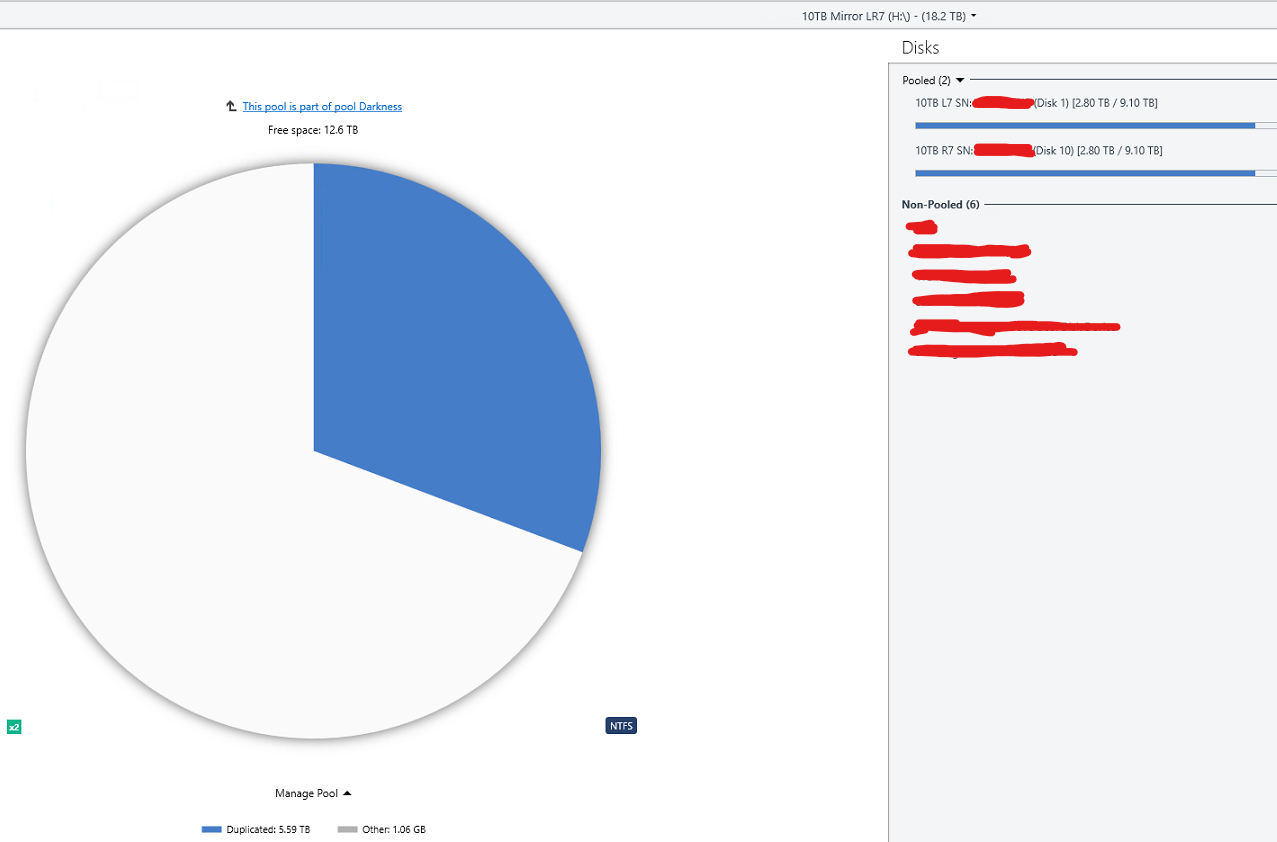
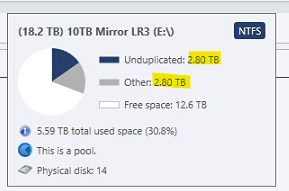
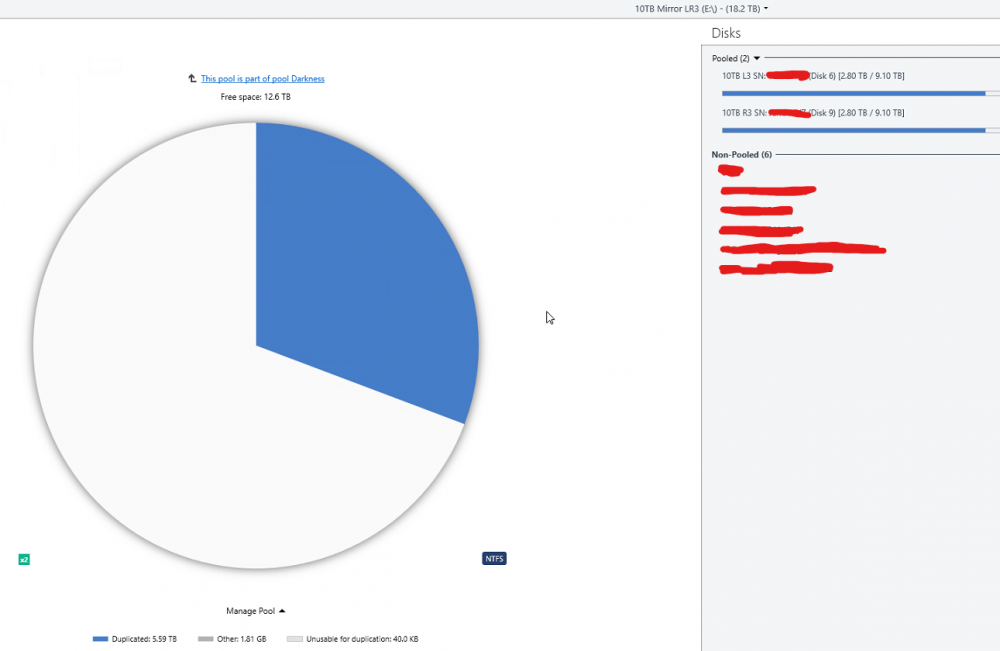
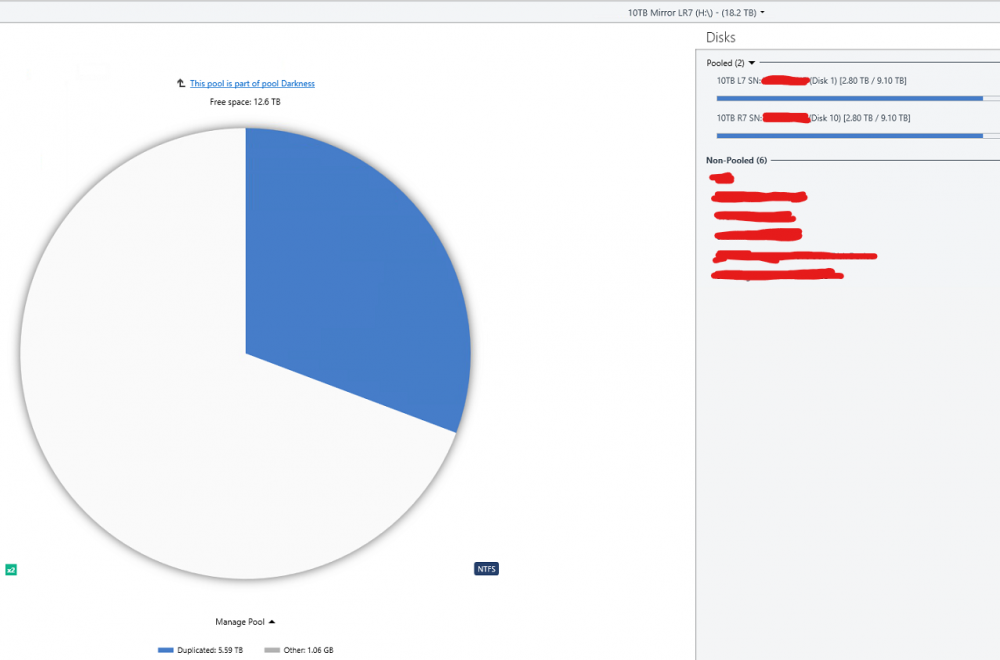
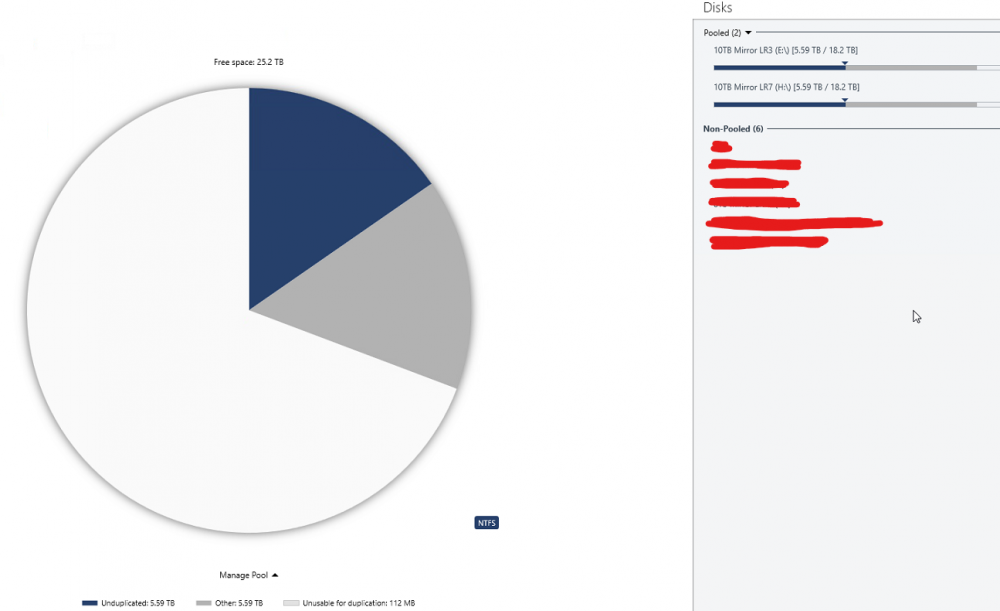
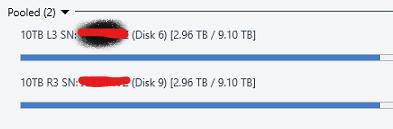
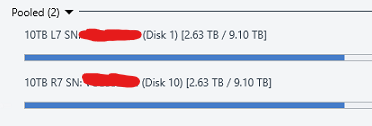
Here is what is going on mathematically in the images you see above. Disk 6 (L3): 2.96TB Disk 9 (R3): 2.96TB There pool reports 5.92TB total storage used. Note that their pool reports this full 5.92 as "duplicated" which is correct as the data of disk 6 and 9 are identical. Disk 1 (L7): 2.63TB Disk 10 (R7):2.63TB Their pool reports 5.26TB total storage used. Note that their pool reports this full 5.26TB as "duplicated" which is correct as the data of disk 1 and 10 are identical. Then you have the pool z which contains Disk 6,9,1,10 for a total space used of 11.18TB however this pool does not properly report the type of data so what it instead reports now is: 10TB Mirror LR3 5.92TB exactly 50% of the data is "other" 10TB Mirror LR7 5.26TB exactly 50% of the data is "other" The pie charts you can also see this but the numbers are different becuase I manually balanced by then. So what is going on is that the Pool Z is not recognizing the duplicated files from the pools E and H and is listing them as other. You can recreate this by the following steps: Create a pool of two drives and enable 2x file duplication Create a second pool of two drives and enable 2x file duplication Create a third pool of the first two pools. Place some files into the third pool. Half of the space will be reported as "unduplicated" and half as "other" If the above steps does not recreate the issue then something is just wrong for me. Note the numbers in this image are after I balanced and will not match the math preformed at the beginning of this post.

-
The only source of files in the Pools E and H above are from the combined pool Z. You can see attached images for exact contents of E and H. The only data outside the pool is a folder containing not even 1MB of data used by backblaze. The issue I am having is occurring becuase the pool Z is seeing half the data on pools E and H as "other" instead of as duplicate data because the data is being duplicated on pools E and H instead of on pool Z directly. I do understand that it would be confusing to users to label this "other" data as duplicated as they might assume that it is being duplicated by the current pool and not an underline pool but the data should be labeled something other than "other" and the balance functions should take the existence of duplicate data within underline pools into account.


-
All settings are default. I no longer have an issue after manually balancing to 50% and stopping the balance run and then disabling the auto re balance. What is going on is I have 2 pools and they show all the data as being duplicated as you would expect as they are duplication pools. You then add those two pools to a poll and the resultant pool now shows 50% of the data as other. Now I guess the root issue issue is that the higher level pool should not show this data as other but I can also see how if it was labled duplicated data like the other pools it could confuse users as to what pool the duplication is occurring on. So there would need to be some sort of other label like duplicate data in sub pool or something like that so it is clear where the duplication is occurring to users. See these images: if this is not how it is supposed to work let me know and I will open a ticket to get this issue resolved.
-
Yea the goal is to not need to pull a 20TB recovery when you could have just done a 10TB recovery it would literally take twice as long. Also you have a higher probability of failure. In my case: A+B = Duplication Pool 1 C+D = Duplication Pool 2 E+F = Duplication Pool 3 Duplication Pool 1+2+3 = Pool of Pools In the above example you can sustain more than 2 drive failures before you lose data depending on what drives fail. In the event of a failure where data loss occurred you will need to restore 1 drives worth of data. Next example: A+B+C+D+E+F = One large pool with 2x duplication. In the above case you will have data loss whenever 2 drives die; however, you will need to pull two drives worth of data from your backups in order to restore. Even if you skip files that you did not lose you still need to actually generate the remote pull action to get the data to then restore from your remote backup server/service. Next example: A+B = Pool 1 C+D = Pool 2 E+F = Pool 3 G+H = Pool 4 Pool 1+2+3+4 = Pool of Pools with duplication applied here. Once again like above if any 2 drives die you will need to restore data and the restore operation will be at least the size of two drives. The other issue is how you are presenting data for backup. If you are just backing up your entire large pool then in order to run a restore operation you need to pull the entire backup because you do not know what files you lost. By having your data sorted in such a way as that you know exactly what backup goes to what drive set you can reduce the scale of the restore operation. For those trying to use this at home things like this may not really matter for for business usage the way that your structuring your backups and your time to restore are major factors in how your going to deploy. Anyway none of this really matters to the actual issue at hand here which appears to be a bug in the software. From what I can tell the software is unable to correctly balance a pool of pools when the underline pools have file duplication enabled on them. Given that the ability to pool pools together is a key feature of Drive Pool along with the ability to then balance data across these pools this is a bug. As stated in my previous post a simple fix would be to recode the balance operation to check after no more than 50% completion if balance is still needed. Until then the only work around is to disable automatic drive balancing and only run the operation manually and then stop it at exactly 50% and your good. From there you should not need to run it if you have file placement balance turned on.
-
Actually the reason for the config I have is to aid in recovery and due to limits in mountable drives. You can mount drives A-Z so this gives you a maximum of 26 mountable drives. My system supports 24 drives so this would appear to be ok until you add in external drives. Then there is the issue of backup. By taking a pair of drives and using duplication on them I need both drives in that pair to be lost to trigger me needing to restore from backup. This is becuase content of both drives is known to be identical. If instead I just had all the drives in a pool and duplication turned on and I lost 2 drives I do not know exactly what content was actually lost as only some of the files were actually present on both of the lost drives. Thus in order to safely restore data I would need to restore twice the amount of data. This also dramatically complicates backups becuase now you are also backing up duplicate data as well. There is no data that is not within the pool. All data is within the pool or within a poll that is part of this pool. You can see this indicated in the images below. See attached images: As you can also see in the last image the balance creates a condition where it can never actually obtain balance. Likely the easiest way to correct this would be to simply alter the way that the balance operation functions rather than worry about making new ways to report data etc. Currently the balencer will make a decision and then it will execute the plan and nothing will change its mind. It needs to take some time to stop and recheck rather than move everything in one go. If the system was configured so that maybe after every X % of balance it rechecks to see how its changes actually effected the balance. If it never tired to balance more than 50% of the required balance change it estimates before rechecking it would never have a problem.

-
To put this another way the balancer will try to move 1tb of files for example instead of 500GB because it is ignoring the fact that for every mb of "unduplicated" files it moves it will always move the same mb of "other" files. If the reason for this is that file duplication is not enabled in the top level pool maybe there needs to be another category of file types besides Unduplicated, Duplicated, Other and Unusable for duplication. If duplicated only refers to the current pool and not underline pools there should be another category for something like Duplicated in another pool.
-
I have run into what appears to be a glitch or am I just doing something wrong. I have 4 10TB drives. I have 2 10TB drives in a pool with file duplication on. I have another 2 10TB drives in a pool with file duplication on. I then have a pool of these two pools. In this pool my data shows 50% as unduplicated and 50% as "other". The result of this appears to drive the balancer crazy so it is in a loop of moving files around and always overshooting. I know the files are duplicated on the lower pools but I feel that the higher level pool should be handling and reporting this status better. Am I doing something wrong, is my install bugged?
-
I wonder what running the scanner on a cloud drive actually does... as it is not as though it would be able to access anything on the physical layer anyways...
-
Wow, very interesting. I have had a problem like this long ago but not in DrivePool. Same thing, some ancient files from the 90s with a permissions bug. Will definitely take note of LockHunter if I ever run into that problem again. Thanks for sharing what fixed it!
-
Did not know that you guys even considered looking at raid controllers I can only imagine the mess that would be. Yea my main focus was just asking for support of HBA drives used in soft raid configurations as I know that you already have access their their data. The other part of my request was actually more of a suggestion which deals with your first response about displaying the info. I was hoping to provide in those photos a suggestion of how you could add support for this information without turning the UI upside and inside out to add support. As for dynamic disks yea I get how that can be a mess because a single physical disk could belong to multiple different virtual disks. Still though you could just have that same physical disk listed for multiple virtual disks because what the user really cares about is looking at their virtual disk what physical disks make it up and if they are healthy or not. Either way, looking forward to seeing this implemented at some point in the future. It is really the only major feature that is keeping the scanner from being 100% perfect lol. (at least for my use case rofl) Also a big thanks for all the work that has gone into this, I can no longer imagine running a server without the scanner!
-
Examples of Media Server/Setup using Drivepool
zeroibis replied to waltwhitman6969's question in General
Not really backup without some sort of versioning (at minimum turning on file history). It is basically a short term backup from the last X hours but you lose files that you delete once the process runs. I would call what your doing 8TB main drive where you have 2x 5tb pooled redundant drives. Thus at that point you would likely benefit from just making it real time or at minimum putting the entire process under drive pool. Create a simple pool with the two 5TB drives. Then create a second pool that contains the first pool and the 8TB drive. Now you can enable pool duplication. If you want the drives to only backup every so often configure drive pool to always place files first on the 8TB drive and then every so often preform a balancing operation to duplicate the files over to the pool of 5TB drives. For my case I use duplication on everything (48TB of drives for 24TB of usable space) and I backup via Backblaze. About 60% of my storage is in RAID 0 arrays (via storage spaces) which are then placed in duplication pools. I use the performance boost from RAID 0 for editing working loads. If I just had 100% static content I would not be using RAID 0 at all. I also use primocache as a write cache but plan to expand it to a read cache as to assist when browsing large image galleries or RAW images to improve responsiveness. (Using 2x 250GB 970 EVOs (two are required to overcome the 2x write performance penalty as a result of real time duplication)) -
Basically you have file corruption. If you have not had any system crashes that would have caused a write error and your HDDs were fine the causes is one of the following. Bit rot, the sector on one of the drives had not been accessed in a long time resulting in file corruption (very unlikley) Memory error, (if your not running ECC ram this is very likely) I would recommend doing some tests on your memory subsystem to ensure it is not causing file corruption.
-
Well you would only have them on different disks if you ran out of space while moving the file over so while it could occur it would not occur very often.
-
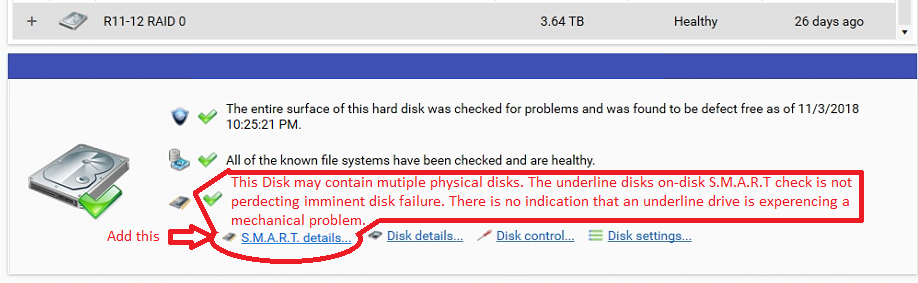
I remembered from a previous conversation that the issue with implementing support to get SMART data from a soft raid set is more of an implementation issue than a technical one. I wanted to put forward a suggestion on how this could be implemented in what would hopefully be a way that would not require a ton of work. First a why this is important. Currently if you have drives in a Soft RAID set lets say in a Storage Spaces array for example StableBit Scanner will pick up the RAID set and can perform a surface scan and file system check on it. This is fantastic and you want this sort of action being preformed on the array itself and not on the individual underline drives. However, no smart data is available for the drives in the underline RAID. Now it is possible to pull this data using other software if you want o manually read it but the larger issue is that you will not get a alert from Stable Bit Scanner that the SMART data on one of the underline drives is indicating trouble like you usually would. This leads us to the first request/suggestion. 1) Make it so that at minimum we at least can get an alert that a drive has a SMART warning. Even if we can not view the smart data within the program and even if lets say we do not know what raid set the drive belongs to at minimum just knowing drive with SN: XYZ is having a problem with the automated email function would be a massive improvement. The next logical question becomes hey lets say we do know what drives are in the RAID set but how do we present this info to users in a meaningful way that does not require massive GUI changes. This leads to the second suggestion. 2) Allow the SMART data of underline drives to be viable to the user so that a user can select a soft raid disk and be able to view the status of drives that make it up. See the images below for a suggestion on how this could be implemented.

-
Good to know about the backup and restore option. I am getting tired of needing to constantly re rename all my drives every time it gets upset becuase I crashed windows testing something.
-
Cool, just saw this. It appears that writes that use sector by sector write verification like to trigger this. For example I only see this error generated when I am using acronis to copy to a drivepool volume. (even if done via network). Would be neat if drivepool was somehow able to automatically suppress this error message but it is something that I suspect is tied heavily in the os.
-
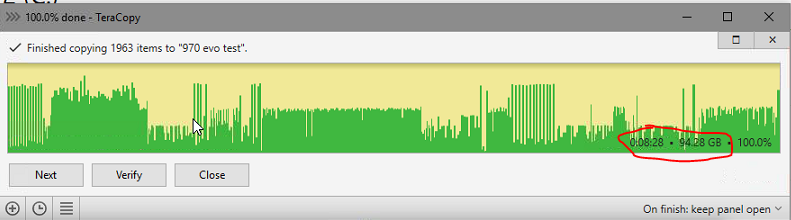
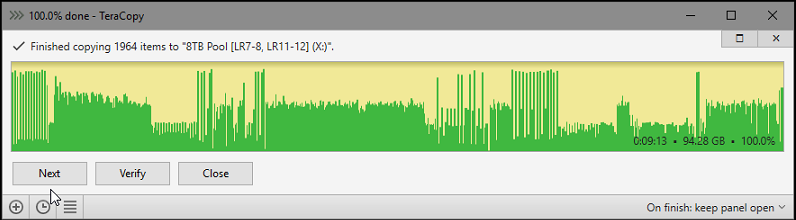
Oh BAM I found what was off. I knew based on the CPU usage and SSD usage that they were not being loaded heavy and figured it was something with the network. Changed the nic to enable jumbo frames and bam dropped the transfer down to ~9min. I do not remember turning them on before but maybe they were enabled when the ati card was connected. I do know that for some reason the ati gpu drives would screw around with the network connections in general (for example with the ati gpu it would take an extra 45 seconds to establish a network connection and this issue never occurs when an nvidia card is connected instead). Very strange behavior but at least now I am back to 9min to transfer 94GB which is what I am looking for. Especially given previous best case test SSD to SSD was getting 8.5min.
-
No that was just the transfer time from the 960 EVO (1tb) to a 970 evo (250gb). The transfer directly to an nvme SSD represents the fastest possible transfer time. Actually recreating that test on my current system it takes over 10min now and I am not sure why that is. Only setting changed since then was enabling sata hot plug in bios and swapping a PCIe x16 ATI card (running pcie2.0 x4) for a x1 (3.0) nvidia card. Oh it could be that the NVME has now settled to its true performance because I wrote over 11TB to it earlier this week. (that shit is warn in now)
-
I realized that I never posted the SSD to SSD result here it is: