Bowsa
-
Posts
61 -
Joined
-
Last visited
Everything posted by Bowsa
-
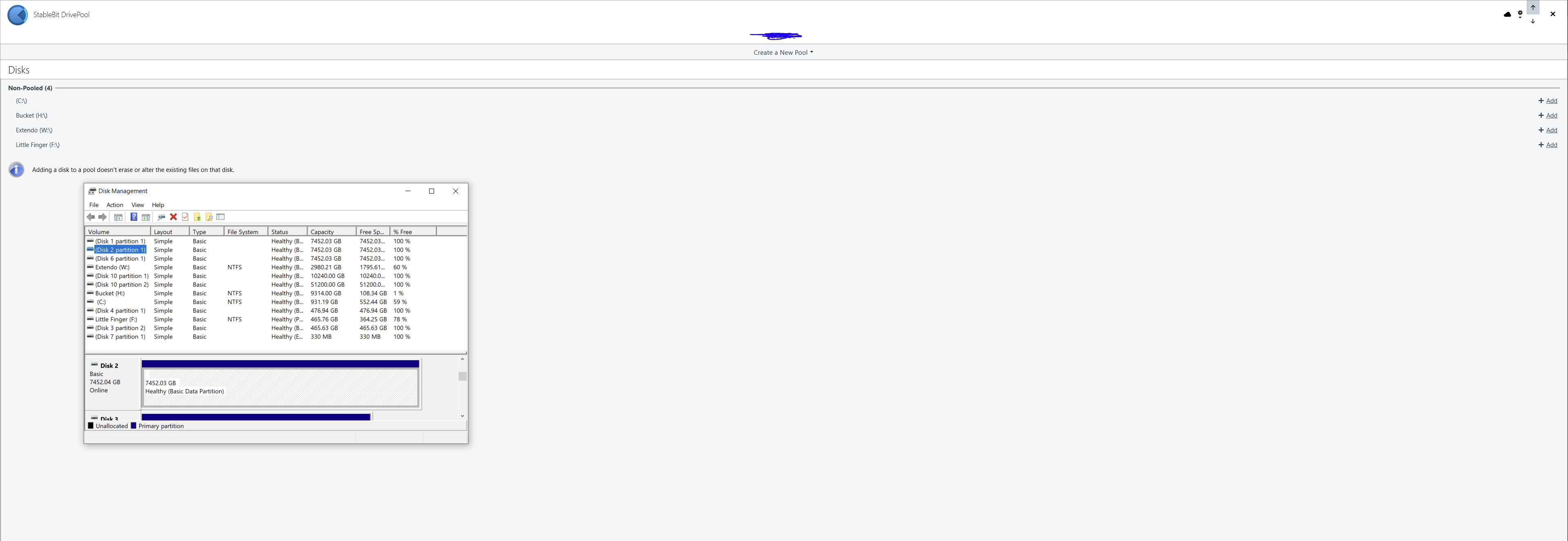
My disks are detected, and it seems to be detected on some level on the software. But it's not pooling, or showing up as the pools.
-
I use DrivePool for two pools Pool 1 - Physical HDDS * x3 8TB HDDS * x2 500 GB SSDs as Balancer Pool 2 - CloudDrives *x2 StableBit Cloud VHDDs that form a singular drive letter Now, I restarted a few times to install a new SSD. But my program seems to be detecting the pools, because it shows the "non-pooled" drives. But even then, my drives aren't present in the application or windows explorer.
-
Contacted them... is anyone else getting this error? Has occurred more than 20 times now, where the chunk is unavailable both in my local and duplicate drive. All that data lost...
-
Haven't submitted a ticket, I'm used to suffering data loss at least 2-5 time a year with StableBit cloud. Nothing I can do about it
-
It doesn't work. I've still suffered data loss multiple times with this enabled...
-
Is there an actual purpose to pinning? For all intents and purposes it should behave as responsive as any other file, until you need to access said file. But most of the time, accessing the drive or certain folders freezes Windows Explorer for a few seconds. Isn't pinning supposed to prevent this?
-
Just noticed I have missing data again... and I’ve been on the duplication beta for weeks
-
This happened this month, not in march
-
I can't even fix my drive with CHKDSK, because I get an error no one seems to know how to solve. 12 TB of Data.....
-
How does a Virtual Volume even get damaged? It makes no sense to me. I had the drive running normally, no power outages, and upload verification was on. So why does StableBit connecting 200 times (user-rate limit exceeded) cause a drive to even become RAW in the first place, what's the point of Upload Verification? In some software it can still detect the drive as NTFS, but it still makes no sense. It's a virtual drive reliant on Chunks (that should be safe due to upload verification). I detached the drive, and mounted it again, and the Drive was still RAW. How do chunks even become RAW in the first place, it's like mounting the drive on another computer and it being raw too.
-
Nope. Chkdsk totally scrambled all my files into video142.mkv, so recovering 12TB is as good as useless. CHKDSK did more harm than good
-
Bump
-
I think it's just a matter of Recovering the Partition Table. I ran TestDisk, and it reports the drive as "NTFS", and more additional information, but it gets stuck on the "analyze" part. I'm sure that if I can find reliable software to recover the table, I should be back in business.
-
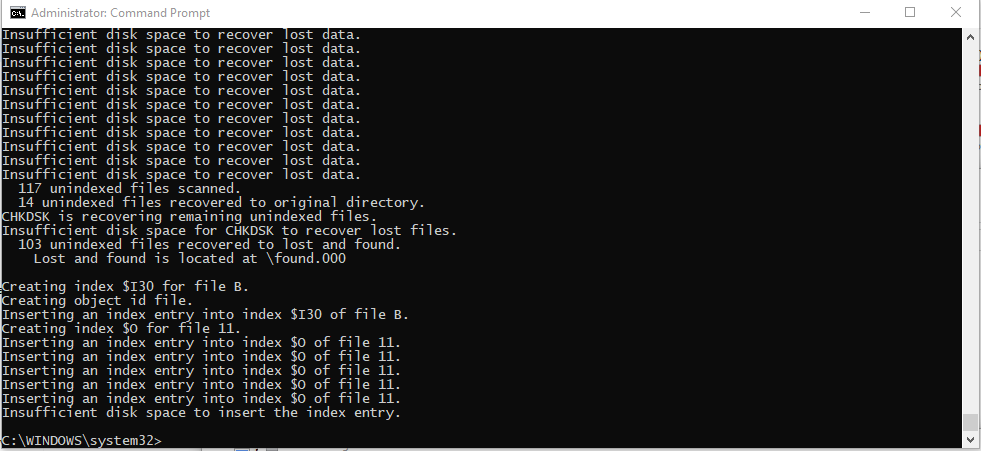
Pertinent Information: I had a major data loss weeks ago when Google had their downtime and made sure not to repeat the same mistake by enabling upload verification. I noticed the other day that Google was having issues, and the CloudUI reported the error more than 250 times. Today I checked and saw that a huge chunk of my are missing. I saw that my Cloud "Pool" was still working and there were a number of files, but then I had the intuition that this wasn't normal data loss like last time; it was isolated to one of the disks in the pool. Pool Setup: Initially I had a 10TB Drive that had filled up, and to enlarge it, I went through the steps in the UI and it created another partition instead of enlarging the existing one. I pooled these two together to have them under the same Name and Drive Letter for organization purposes. In addition, I removed drive letters for the "pool drives" to prevent clutter. Keeping the above in mind, I checked DrivePool, and it confirmed that the first Drive was "missing" and checking in Disk Management, the Drive is marked as "RAW". The first thing I did was follow these steps: It doesn't seem to have done anything, as the drive is still RAW. I also assigned a Drive Letter to the problem disk, and ran "CHKDSK /f". It deleted index entries, and didn't complete due to "insufficient disk space to insert the index entry" it also placed unindexed files in "lost and found". I need some advice on how to go forward with this, I don't want to lose 10 TBs of Data again. What can I do to recover my data? Should I detach the disk, and reattach it?
-
Ok, but how do you convert the disk from RAW back to NTFS...?
-
No I have 2 accounts, with its respective drive. Everything is uploaded now, but I have no idea what could've caused this to happen in the first place. Maybe it was my upload/download threads that caused it?
-
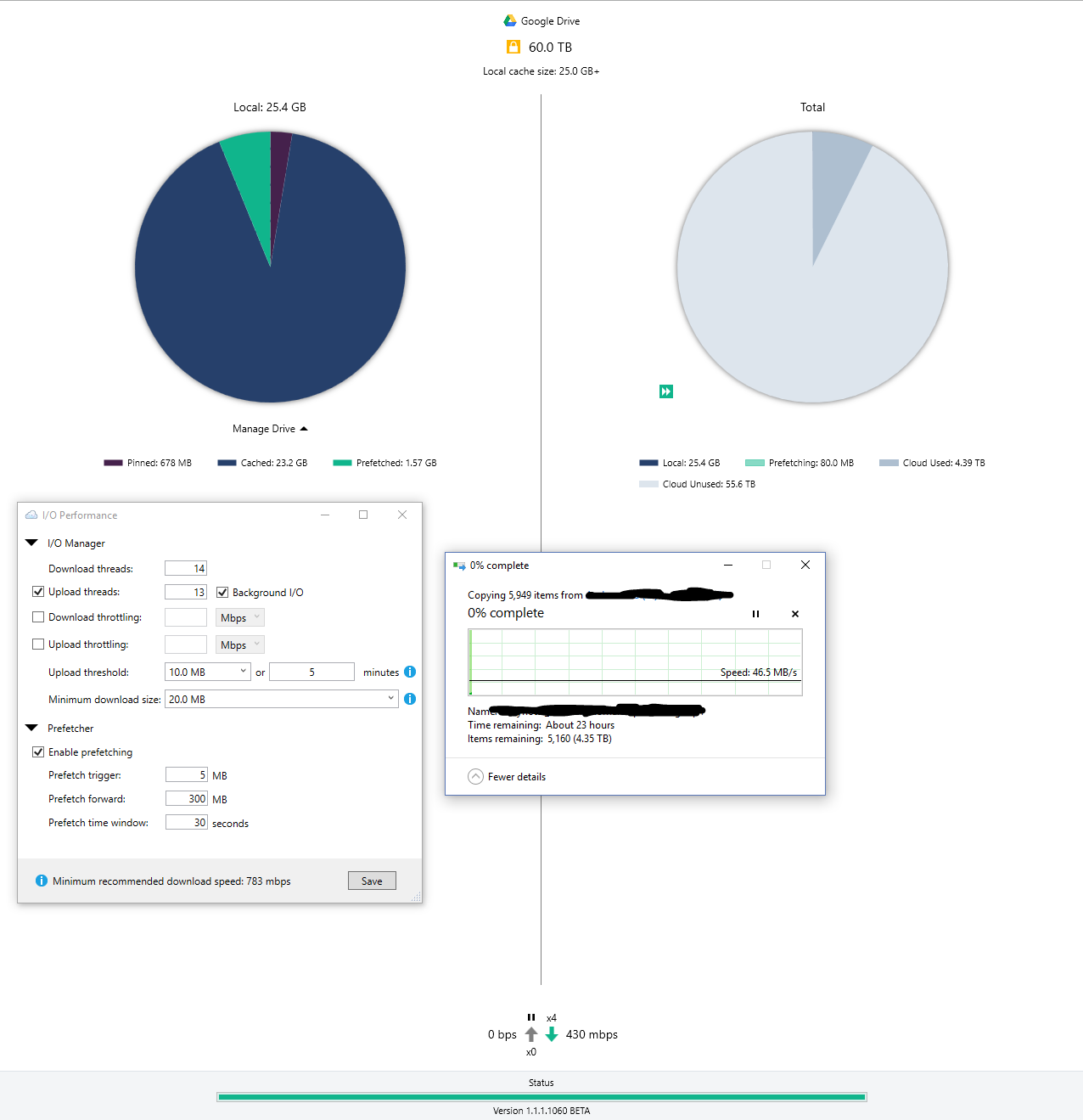
I have automations set-up for the management of my media, and noticed in Plex that a few media articles were showing up "blank". Upon investigating CloudDrive, I noticed that it was being throttled and that it triggered the User-rate limit 252 times! I inspected my download history, and I've only downloaded 100GB this entire month, so I know for a fact it's not throttled due to the daily upload limit. Does anyone know what might have caused this? Is it possible Data got unpinned, and that Plex accessing it again messed things up due to the API calls?
-
It does make a difference, CloudDrive doesn't start uploading at full speed until a certain amount of data is copied/cached, so having to go through the process for every 400GB isn't ideal.
-
https://community.covecube.com/index.php?/topic/1225-why-isnt-xyz-provider-available/
-
Fortunately, I'm not subject to this upload max of 750 GB a day...so the point still stands
-
Thing is, if I set the Minimum DL to like 40 MB, enable 18 threads, and 3000 MB of pre-fetch, I get 600-700 Mbps
-
I sorta have that enabled, my SSD drive is my "intermediary" folder, but when it extracts, it extracts to the Pool. How do you limit it to completed files only>
-
I have 1000/1000, and regularly get download speeds of 950-970 mbps. There's a hard drive I backed up in its entirety, and now I want to transfer it to another external drive. The problem is that copying the entire folder to my new external is delivering less than stellar results. Usenet maxes out my connecting at 80-90 MBps, but it seems that through GDrive it's so much slower and very sporadic as there is no "real" transfer rate due to the pre-fetching mechanism. I was wondering if there where any other ways to optimize this?
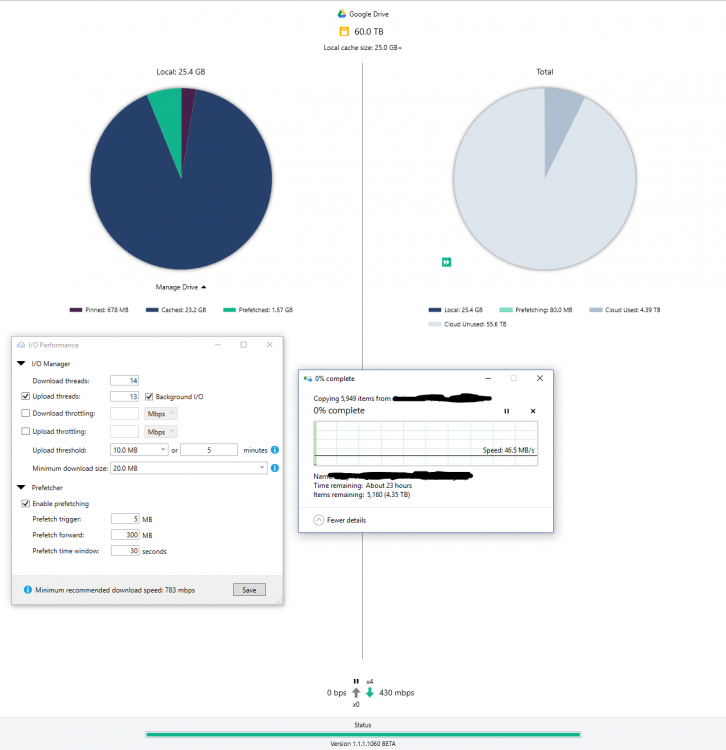
-
What would be the fastest/best option of backing up a physical DrivePool? As I understand, going the route of Hierarchical pooling is automatic and serves as a mirror which helps repopulate data in the event of a drive failure. But is an ACTUAL backup a better solution, and is it faster? If so, what software do you recommend for it
-
No, but won't that be problematic in the following scenarios? 1) Purpose of "Physical" DrivePool is the organization, structure, and distribution of files between the pool of drives. Backing up the underlying drive would be out of order? 2) Pointing it towards my "CloudDrive" doesn't do anything either, it doesn't backup my CloudDrive.