


srcrist
-
Posts
466 -
Joined
-
Last visited
-
Days Won
36
Everything posted by srcrist
-
I actually think CloudDrive's strongest unique use case is the opposite of that. Because CloudDrive can uniquely support partial transfers and binary diffs, CloudDrive can create working drives that are hosted in the cloud that can be used to actively edit even large files without re-uploading the entire thing. The chunk-based nature of CloudDrive also makes it ideal for large amounts of smaller files, since it will upload uniform, obfuscated chunks regardless of the file sizes on the disk--thus reducing API load on the provider. If you're just doing archival storage, uploading an entire file and letting it sit with something like rClone or NetDrive works just fine. But if you need to store files that you'll actively edit on a regular basis, or if you need to store a large volume of smaller files that get modified regularly, CloudDrive works best. I think another good way to think of it is that rClone and NetDrive and ExpanDrive and all of their cousins basically *compliment* what the cloud provider already does, while CloudDrive aims to make your cloud provider operate more similarly to a local drive--and with a fast enough connection, can basically replace one.
-
Yeah, this is a fundamental confusion about how CloudDrive operates. CloudDrive is a block-based virtual drive solution, and not a convenient way to sync content with your cloud provider. ExpanDrive, NetDrive, rClone, and Google File Stream are all 1:1 file-based solutions, and all operate similarly to one another. CloudDrive is something else entirely, and will neither access nor make available native content on your provider. CloudDrive simply uses the cloud provider to store encrypted, obfuscated chunks of disk data.
-
I'm relatively certain that DrivePool can be configured in such a way that it only ever reads data off of your CloudDrive if your local storage is unavailable. You set it up by creating a pool with all of your local drives, adding your clouddrive, and enabling duplication only on the cloud drive. Good luck with whatever you decide!
-
I should also point out that Backblaze's personal storage option provides unlimited backup space as long as you can use their in-house tool. That might be cheaper than using B2 cloud storage with CloudDrive, if backup is your only desire.
-
I don't think there is necessarily an objective "best" to provide you with. It sort of depends on your needs. You might consider using CloudDrive in a pool with your local storage using DrivePool or another similar tool and then running redundancy with Backblaze. That would back up your content AND repair it as necessary. Or you could simply set up rsync or a similar tool to copy data to the cloud periodically. In any case, the theoretical maximum size of a CloudDrive drive is 1PB. You can make a drive larger than 10TB, simply type in the size you want. Your volume size will, of course, be limited by the cluster size that you format it with. If you use 64KB clusters, you can make a single 256TB volume, though I would suggest you keep individual volumes lower than 60TB with NTFS, otherwise chkdsk will not work and there is no way to repair file system errors. I would say that if you need to backup 46TB, you could make a single 50TB volume on CloudDrive with 16KB clusters and that should suit you fine.
-
Create a pool on the new drive, then stop the service and simply move all of the data from the pool folders on the old drives to the pool folder on the new drive. Done. That's all you've got to do. When you restart the service it will remeasure the pool from the new drive. You can also just copy the data to the drive if you want. No need to use a pool. The files in the poolpart folders on your pooled drives are able to simply be moved to the root of the new drives if you want. If you want to get really creative, you can even use DrivePool to simply duplicate the content from the old pool to the new one in a new nested pool.
-
Sure, no problem. To be clear, though: you can't use CloudDrive to interact with pools at all. You can use DrivePool to pool two different pools together, and you can use CloudDrive volumes in DrivePool pools, but DrivePool is the only software that interacts with pools in any way, and it requires direct access to the drives to form the pools. It can't use SMB. It *can*, however, use iSCSI.
-
I still think there might be some fundamental confusion about CloudDrive and how it operates here. What do you mean that you used CloudDrive to take a share and place it into a new virtual drive? I suspect that you might have created a CloudDrive volume on your network share, but that won't make any data that is *also* on your network share available to the CloudDrive volume. It simply stores the data for your volume on your network share. CloudDrive does not operate by accessing existing data from a location. It creates a drive image in a location and uses it to store the data that you copy or move to the CloudDrive volume. You could make a CloudDrive volume large enough to contain all of the data on your network share and then store the volume on your network share and move all of the data onto the CloudDrive and pool it together with other drives on "Horse" using DrivePool, but then that data will not be natively accessible on "Bear" anymore. Bear will simply contain the chunks of disk data for the CloudDrive. It sounds to me like you're looking for software to simply pool a network share together with your drives on the "Horse" machine, but neither CloudDrive nor DrivePool can accomplish this. You might be able to work some magic with something like iSCSI to make it work with DrivePool, but I'm not the one to help there. Maybe make a post asking over in the DrivePool forums and see if someone with more familiarity with those technologies can help you.
-
I'm not totally sure that I understand the question. CloudDrive is a virtual drive application that lets you create a drive and store the data on a cloud provider. It doesn't interact with a pool in any way, other than being a drive that can be added to a pool. Once a CloudDrive drive is added to a pool, you can use it in any way that you could use any physical drive in your PC. It will always be blank until you copy or move data onto the drive via whatever mechanism you'd like to use to do so.
-
It is a Google server-side limitation. Google will not allow you to upload more than 750GB/day, and will lock you out of the upload API for a day if you hit that threshold. CloudDrive cannot do anything to evade that limitation. You will either have to throttle your upload to 70-75mbps so that you don't need to worry about it, or you'll have to personally monitor your upload so that you upload less than 750GB/day of data. rClone has the same limitation, with the same solution. The --bwlimit flag in rclone is the same as setting the upload throttling in CloudDrive. To be clear, though, this post was not about an inability to reach over 70mbps upload. If that's your problem, you aren't talking about the same thing. CloudDrive can easily achieve over 70mpbs upload, but there isn't generally any reason to.
-
Unfortunately not, but you also don't necessarily need to. You can simply expand the drive size from the CloudDrive UI, add another partition on the same drive, and use DrivePool to pool them together, if you have a license for it. The limit on expanding the drive and a limit of the volume based on the cluster size are not the same thing. You can still expand the drive and create another volume on it. Otherwise you'll just have to copy the data from one drive to the other.
-
That would help. Glad you got it figured out!
-
How did you set up the drive? What is your chunk size?
-
EDIT: Disregard my previous post. I missed some context. I'm not sure why it's slower for you. Your settings are mostly fine, except you're probably using too many threads. Leave the download threads at 10, and drop the upload threads to 5. Turn off background i/o as well, and you can raise your minimum download to 20MB if that's your chunk size. Those will help a little bit, but I'm sure you're able to hit at least 300mbps even with the settings you're using. Here is my CloudDrive copying a 23GB file:
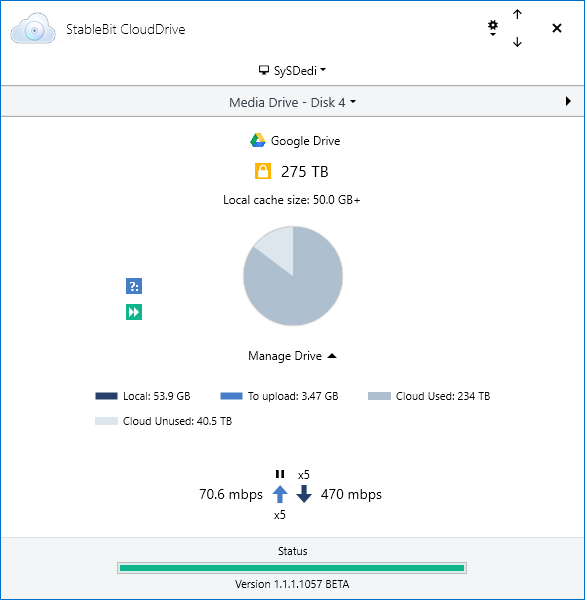
-
Covecube is, as far as I know, two people. And also as far as I know, the forums aren't an official support channel, though Christopher and Alex do respond here from time to time. If you have urgent questions you'd be better off submitting a support ticket, not complaining because other users aren't responding to you quickly enough in the discussion forum. You can find the contact form here: https://stablebit.com/Contact
-
Plex performs maintenance during downtime, and that maintenance can involve deep reads of entire files. Without looking at any more information, I would presume that is what is going on here. Check your plex settings. If you have options checked under "scheduled tasks" like "upgrade media analysis during maintenance" and "perform extensive media analysis during maintenance," those are the options that enable deep reads and analysis of media during scheduled tasks. The fact that it begins at 2am, which is the default start time for Plex's maintenance period, supports my assumption here. It may also be generating video preview and chapter thumbnails during that time as well, depending on your library settings. All in all, though, these things are not harmful unless you need to conserve your data usage. You're fine just letting Plex do its thing. It uses the media analysis to configure the streaming engine to be more efficient, and the thumbnail generation is used for aesthetic effects in the UI. If you do need to conserve your data, simply disable those options.
-
I wouldn't make your minimum download size any larger than a single chunk. There really isn't any point in this use-case, as we can use smart prefetching to grab larger chunks of data when needed. Your prefetcher probably need some adjustment too. A 1MB trigger in 10secs means that it will grab 300MB of data every time an application requests 1MB or more of data within 10 seconds...which is basically all the time, and already covered by a minimum download of 20MB with a 20MB chunk size. Instead, change the trigger to 20MB and leave the window at 10 seconds. That is about 16mbps, or the rate of a moderate quality 1080p encode MKV. This will engage the prefetcher for video streaming, but let it rest if you're just looking at smaller files like EPUB or PDF. We really only need to engage the prefetcher for higher quality streams here, since a 1gbps connection can grab smaller files in seconds regardless. A prefetch amount of 300MB is fine with a 1000mbps connection. You could drop it, if you wanted to be more efficient, but there probably isn't any need with a 1gbps connection.
-
Nope. None at all.
-
Nope. No need to change anything at all. Just use DrivePool to create a pool using your existing CloudDrive drive, expand your CloudDrive using the CloudDrive UI, format the new volume with Windows Disk Management, and add the new volume to the pool. You'll want to MOVE (not copy) all of the data that exists on your CloudDrive to the hidden directory that DrivePool creates ON THE SAME DRIVE, and that will make the content immediately available within the pool. You will also want to disable most if not all of DrivePool's balancers because a) they don't matter, and b) you don't want DrivePool wasting bandwidth downloading and moving data around between the drives. So let's say you have an existing CloudDrive volume at E:. First you'll use DrivePool to create a new pool, D:, and add E: Then you'll use the CloudDrive UI to expand the CloudDrive by 55TB. This will create 55TB of unmounted free space. Then you'll use Disk Management to create a new 55TB volume, F:, from the free space on your CloudDrive. Then you go back to DrivePool, add F: to your D: pool. The pool now contains both E: and F: Now you'll want to navigate to E:, find the hidden directory that DrivePool has created for the pool (ex: PoolPart.4a5d6340-XXXX-XXXX-XXXX-cf8aa3944dd6), and move ALL of the existing data on E: to that directory. This will place all of your existing data in the pool. Then just navigate to D: and all of your content will be there, as well as plenty of room for more. You can now point Plex and any other application at D: just like E: and it will work as normal. You could also replace the drive letter for the pool with whatever you used to use for your CloudDrive drive to make things easier. NOTE: Once your CloudDrive volumes are pooled, they do NOT need drive letters. You're free to remove them to clean things up, and you don't need to create volume labels for any future volumes you format either. My drive layout looks like this:
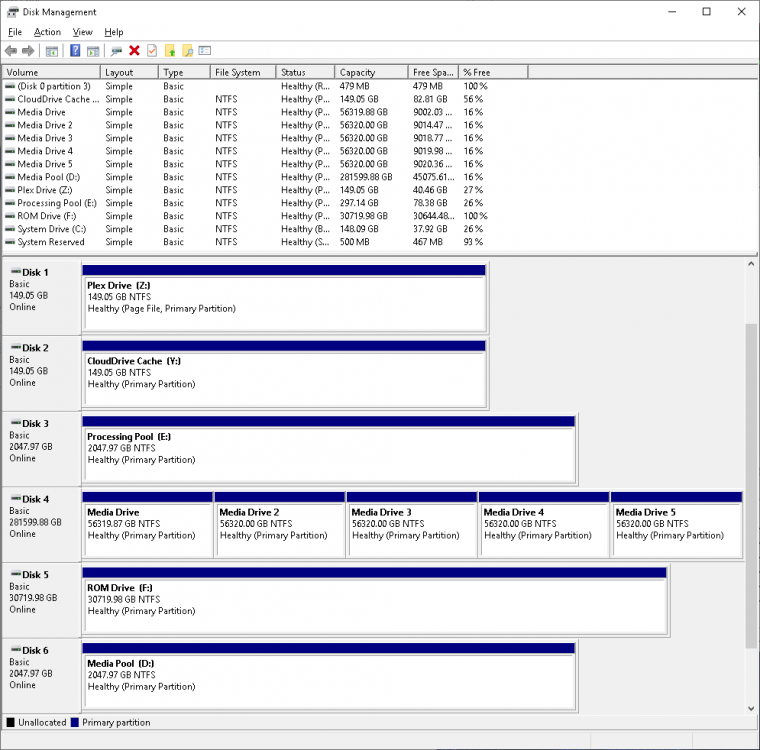
-
Are you using Windows Server by any chance? I think that's a Windows thing, if you are. I don't believe Windows Server initializes new drives automatically. You can do it in a matter of seconds from the Disk Management control panel. Once the disk is initialized it will show up as normal from that point on. I'm sure Christopher and Alex can get you sorted out via support, in any case.
-
Oh, the format of the cache drive is irrelevant. Doesn't matter. It can cache any format of cloud drive. An NTFS drive with 4KB clusters can cache a CloudDrive with 16KB clusters just fine. All of my physical drives use 4KB clusters.
-
No. You can't change cluster size after you've formatted the drive. But, again, I mentioned that disclaimer. It won't affect you. You want the optimal settings for plex, not the theoretical minimum and maximum for the drive. The only salient question for you is "will a larger cluster size negatively impact plex's ability to serve numerous large video files on the fly, or the ability of other applications to manage a media library?" And the answer is no. It may have some theoretical inefficiencies for some purposes, but you don't care about those. They won't affect your use case in the least.
-
For the record, your cache size and drive can be changed by simply detaching and reattaching the drive. It isn't set in stone. You are given the option to configure it every time you attach the drive. As far as the drive size goes, you don't need optimal performance. Remember that CloudDrive can be configured for many different purposes. For some, a smaller chunk size might be better, for some no prefetcher might be better, for some a longer delay before uploading modified data might be better. It just depends on use case. Your use case is going to be very large files with a priority on read speed over seek time and write performance. That being said, I just looked because I never remembered seeing any such disclaimer, and I don't see the section of the manual you're referring to. There is a disclaimer that clusters over 4KB can lead to certain application incompatibilities in Windows, and that Windows itself may be less efficient, but those are not important for you. Plex has no such issues, and, from experience, a larger cluster size is plenty efficient enough for this purpose. Remember that you're creating what is predominately an archival drive, where data will be accessed relatively infrequently and in long, contiguous chunks. I can tell you from two years in an active, production environment that larger clusters has caused no issues for me, and I haven't found a single application that hasn't worked perfectly with it. But it's ultimately your call.
-
You've got a lot packed in there so I'll bullet them out one at a time: I lost a ReFS drive. It wasn't because of CloudDrive, it was because of the infamous instability of ReFS in Windows 10 (which has now been completely removed as of the creators update). The filesytem was corrupted by a Windows update which tried to convert ReFS to a newer revision, and the drive became RAW. To mitigate this, simply do not use ReFS. It isn't necessary for a Plex setup, and there are ways to accomplish most of what it offers with NTFS and some skillful configuration. ReFS simply is not ready for prime time, and Microsoft, acknowledging as much, has removed support for the format from Windows 10 entirely. Is full drive encryption *necessary*? Probably not. But I suggest you use it anyway. It adds effectively no overhead, as modern processors have hardware support for AES encryption and decryption. The additional peace of mind is worth it, even if it isn't strictly necessary. I use it in my setup, in any case. It is entirely possible to store two caches for different CloudDrives on the same disk, but probably unnecessary to actually use two CloudDrives in the longer term. I use one drive divided up into multiple volumes. That is: one CloudDrive drive partitioned into multiple 55TB volumes that are then placed into a DrivePool pool to be used as one large file system. I suggest you use that. This way you can throttle your upload to comply with Google's 750GB/day limit (70-80mbps, I use 70 to leave myself some buffer if I need it), and manage your caching and overall throughput more easily. I actually had multiple drives and took about 6 months to migrate all the data to one large drive just because management was easier. If you just need a drive to place a cache to copy from one CloudDrive to another, temporarily, one drive will be just fine. You can also use a relatively small cache for the older, source drive too. You don't need a large cache to just read data and copy it to another drive. The destination drive will, of course, need plenty of space to buffer your upload.
-
The difference between fetching a single 10MB chunk and a single 20MB chunk on a 1gbps connection is a matter of fractions of a second. Not worth worrying about. CloudDrive is also capable of accessing partial chunks. It doesn't necessarily need to download the entire thing at a time. That is a separate setting. You can set your chunk cache size to as large as your system's memory can handle, and the cluster size is really only important with respect to the maximum size of the drive. You'll just need to do the math and decide what cluster size works for your intended purpose. 16KB clusters can create volumes of 60TB, which is the limit for chkdsk and shadow copy, so you want to keep each volume less than that. So I might go with that, if you're going to have an NTFS drive.



