


B00ze
-
Posts
81 -
Joined
-
Last visited
-
Days Won
5
Everything posted by B00ze
-
Well, since Drashna seems to be MIA, I investigated further. Turns out these reparse files are files that Drivepool uses to keep track of symlinks, and all the ones it was complaining about were DELETED symlinks. The "parts" that those deleted symlinks pointed to are still there, on two disks, and they are identical, but the symlink itself should not have remained in the CoveFS reparse directory since it had been deleted. I just zapped the reparse files, all resolved.
-
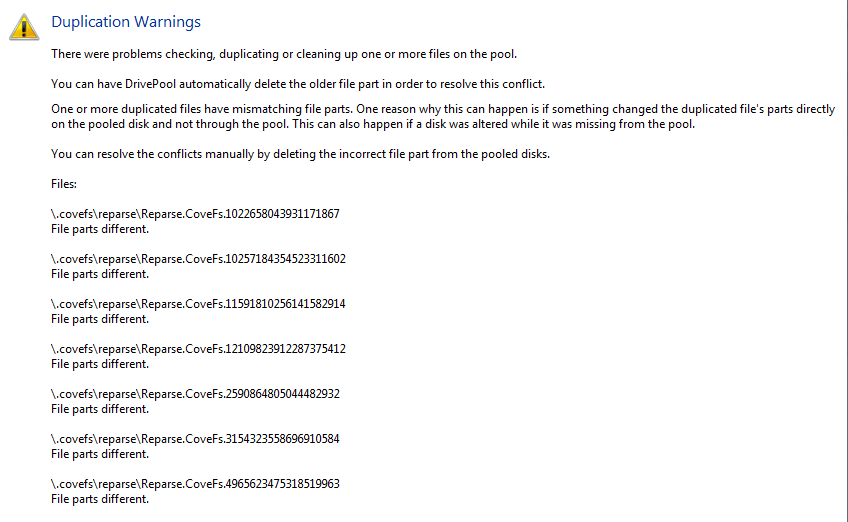
Good day. I have some "fileparts are different" errors right now, but the error details only show some numbers, there is no filename, so what do I do with this? How do I know which files these errors are about? I looked at the logs (attached) and it seems I've had these for some time now (at least 7 days). file '\\?\GLOBALROOT\Device\HarddiskVolume14\.covefs\reparse\Reparse.CoveFs.1022658043931171867' (file part contents is different). Incidentally if you look at the attached log you'll see I got a few other errors today (e.g. Error getting info on pack, whatever that means). On a different note, I've noticed the filesystem freezes-up sometimes when I do an operation in Explorer, specifically rename or move a file; it will freeze for 5-7 seconds, and sometimes Explorer just never finishes the move and I have to Cancel and move again. Strangely enough this happens consistently in some folders, so I can easily reproduce. This happens to me only on the pool, so far nowhere else. I've enabled the filesystem log and reproduced, but where's that log? Do I need to reboot after enabling it, or can I enable it, reproduce and then disable it? Thanks. DrivePool.Service-2021-06-21.log
-
Good day Jaga. Arg, so IOZone produces complicated CSV files? Darn, it looked perfect, all the website said it does is call standard disk stuff, not trying to measure position on disk or bypass cache. Sandra also looked promising. It's so difficult to find a benchmark for disks that doesn't try to get the disk's raw performance. Well who knows, maybe it is 4 times faster with PrimoCache enabled! When I go to their forums (it's on the todo list) to ask some questions, I'll ask if they know of a benchmark we can use. Thanks!
-
Hey! Thanks for discussing this. You have me interested. When I have time I will go to their forums/feedback and ask about a dynamic-size cache. They will probably tell me it cannot be done, lol, but if they did manage it for their RAMDisk then why not with the cache? Even with a fixed-size, it /could/ be good to have a smallish PrimoCache sitting underneath the Windows cache, especially with write-back (you are correct, Windows' write-cache sucks.) I see you can group disks and create separate caches, that's good - I probably would not want to cache my fast-enough SSD, but the DrivePool is something else! It took an HOUR to 7-zip unpack 1.2 million small files the other day, Gods it was slow! About CacheSet: Oh I have this already, but here are the Win7 defaults: Current minimum working set size: 1048576 Current maximum working set size: 1099511627776. That is, 1TB maximum size by default, so no need to touch it ;-) For disk benchmarks, we need something like AnandTech's Storage Bench. I checked AIDA but I don't see what I want in there. Maybe you can try IOZone or Sandra ? Best Regards,
-
Good day. For what it's worth, I tried just now on my own pool and the folder datetime is updated correctly (Win7, single pool 3 drives). How are the files created? i.e. which software creates them? For my test I just did New->TextFile and that worked OK... Regards,
-
No issues with Kaspersky and the pool on my machine...
-

Can I set up a pool on multiple external drives to use as offsite backup?
B00ze replied to Bryan Wall's question in General
Good day. I'm not sure about this, but you /could/ disable the DrivePool service and reboot, THEN disconnect the USB drives, and finally restart the service. I say I'm not sure, because even when I disable the service and reboot, the pool's drive is still there in Windows (the CoveFS device stays enabled) so I'm not sure if that would free-up the locks or not; you could try it... Regards, -
Hi Jaga. Comparing speeds with PrimoCache and then without ANY cache is not very useful, especially if you tell CrystalDisk to use a tiny 500MB file. I replied because I wish you would post numbers that compare the Windows cache VS PrimoCache, as I have been interested in PrimoCache. I used to run PowerCache (I think it was called) on Amiga, and could set the number of sets and the number of lines for the cache for each disk, so I was able to optimize depending on what kind of data was on the disks, and it was quite efficient. It was, like FancyCache, a sector-based cache, and I think it is a bit better than what Microsoft does, which is a FILE cache. BUT, since absolutely everything in NTFS is a file, using a file cache should not be all that bad; plus, if Windows does like BeOS, it can run programs directly from cache without first having to copy them somewhere else in RAM. Also, as far as I know, you can't "set Windows' system cache to allow it to expand well past normal limits" - In Win7 at least, it will used-up ALL available RAM by default (at least it does on my 32GB system, and I haven't touched any cache parameters.) I'd use PrimoCache almost immediately if I could tell it to do like Windows does - Grow to use all available RAM, then shrink when something needs the RAM. I'm not too keen having to specify in advance how big the cache will be. What happens if we use BOTH PrimoCache and Windows Cache? I might be interested in a small PrimoCache, below the native cache (but really, what I want is a cache that grows and shrinks, and that does write-back...) Regards,
-
Good day. I think CrystalDiskMark bypasses the Windows cache when it runs its tests, but cannot bypass PrimoCache. So while PrimoCache looks impressive, you should really compare with something that doesn't bypass the windows cache, if you want to know how much faster PrimoCache is compared to native caching... Regards,
-
Good day. Of course, this is kinda the whole point. Do you have Excel? You can load a CSV from before the loss of a drive, and a CSV from after the loss, and compare them. There is this function in Excel called VLOOKUP. You load both files into the same workbook as sheets, add a column to one of them and VLOOKUP the file paths in this one to the paths in the other; whatever's missing is what you've lost. You could setup conditional highlighting to do the same thing (I think.) Once you got a list in Excel, you can sort then copy/paste in a text file. You can then automate the process of recovery by writing a small batch script that reads the text file and copies the missing files from backup back onto the pool. If you do not use duplication at all, then it's even easier, just sort by disk and whatever's on the lost drive is what you need to recover. Regards,
-
Drive pool backups/Keeping files in folders together
B00ze replied to APoolTodayKeepsTheNasAway's question in General
Hi. If you just mount the missing pool now and again, and use copy/robocopy/syncToy/whatever to synchronize the 2 pools, then I don't see any issues. Just remember that you always have to reConnect ALL the drives from Pool 2, or the pool will be read-only. I wish someone else who'd tried that before would jump in; DrivePool is not supposed to have any issues with the scenario you describe, so that's what I'm saying, but it's always better if someone answers that has actually done it before (taking drives offline/online repeatedly.) I've done something similar, and DrivePool detected my pool just fine, but I've only done it a couple times, I've not tried this on a regular basis. Regards, -
That ticket is private, i.e. I cannot see the details. But I think 1 MB is a good chunk size; I'm not sure increasing it would make a difference (not knowing how read-stripping works, I cannot say.) So long as you remember you have a Nuts-n-Bolts to do on this, I'm good; we can discuss once it's published. Of course you could push and push and push for better performance, lol, but I'm okay waiting until someone @ StableBit decides now is the time to tackle this. Thanks again for being here! Regards,
-
Micro-management Of Drivepool - Solved by using junctions.
B00ze replied to Dave Hobson's question in General
What's fantastic is that DrivePool supports them! -
Drive pool backups/Keeping files in folders together
B00ze replied to APoolTodayKeepsTheNasAway's question in General
Hi A Pool A Day Keeps The Doctor Away. There was a big discussion about this, see here: File Placement Based On Folder (towards the end I added a few replies on the problems I'd run into if I was to code this myself...) As for backup, just so you know, if 1 drive is missing from a pool, you can no longer write to that pool until you re-balance (i.e. remove the drive from the UI and see what happens.) So at least you'd have to make sure you always reconnect all the USB drives. Christopher can say for sure about what would happen when 2 pools are related by duplication and then 1 pool goes offline, I've never tried that before. Regards, -
Hi Christopher. I agree that DrivePool cannot be as fast as a stripped array, but unless Alex explains where the difficulty lies (and it's quite possible there *is* a big difficulty,) I am for now convinced it can do better than 10% improvement reading the same file on 2 drives. I'm pretty sure we can cook-up a simple test program that sends a read for a MB off to drive 1 and then immediately sends a read for the next MB off to drive 2 (using ASync I/O so both reads go off and then the program sleeps,) and so on, and achieve respectable results. I don't know, maybe the driver cannot do ASync I/O? There is a difficulty somewhere, because DrivePool isn't really using more than 1 drive at a time... Wouldn't it be great if DrivePool could be used for cases like Matt's, where someone bought the program JUST to improve performance while also being able to read the drives like plain old NTFS volumes? That's why I said it's a legitimate use-case - i.e. unless there is some big difficulty making it impossible to do any better than now, then better performance should be something you should think about; it would improve the uses for DrivePool. PS: Been using DP for some time now; no problems to report except a little hiccup the other day. Works great!
-
Trigger a scheduled task or script after balance?
B00ze replied to fattipants2016's question in General
Hi Christopher. Lol, you know what that means: my BitLocker_PoolPartUnlockDetect.Override setting had not been working since the get-go! I don't really hear the drives spin-up or down, so it's hard for me to see if they spin-down as they should, I'd have to leave the computer idle on purpose and I haven't really had time to test this. I /think/ they don't spin-down, but it could be something else than DrivePool, like the Intel RAID driver that's still running the drives (I had to disable spin-down in Windows when this was a Intel RAID otherwise the Intel driver was fighting the sleep and re-spinning the drives up immediately. I have since re-enabled sleep in Windows, but not tested.) PS: The lock file works fine now that I don't have an error in the config. Regards, -
SSD Optimizer / File Placement Interoperability Issues
B00ze replied to fattipants2016's question in General
Hmmm, interesting issue, looks like the SSD-Optimizer is used even during balancing passes, which is kinda unexpected. Thanks for the tip that SnapRAID keeps growing (until you do a re-initialize or whatever the command is.) I plan to use a disk bigger than the biggest disk in my Pool for SnapRAID, but was not planning to try to minimize changes to files; maybe I should... -
Trigger a scheduled task or script after balance?
B00ze replied to fattipants2016's question in General
Lol, once again, my mistake. Tried a TON of things, loaded-up Process Monitor, made sure DrivePool was loading the settings file; monitored for my "lock" file -> Nowhere to be found. After like 40 minutes I had a look at the DrivePool logs and found this: DrivePool.Service.exe Warning 0 [JsonSettings] Error parsing JSON settings file. Using application defaults. Unexpected character encountered while parsing value: F. Path 'BitLocker_PoolPartUnlockDetect.Override', line 4, position 16. 2018-04-12 22:57:55Z 15061268610 DrivePool.Service.exe Warning 0 [JsonSettings] Error parsing JSON settings file. Using application defaults. Unexpected character encountered while parsing value: F. Path 'BitLocker_PoolPartUnlockDetect.Override', line 4, position 16. 2018-04-12 22:58:05Z 15098892007 Looks like TRUE and FALSE are CASE-SENSITIVE. Maybe now I will see if my drives spin-down? lol. Thanks. -
Ah! My bad! TIMEZONE! Sorry, 9pm is when I get home (in GMT0 I guess). Aaarg, I look like a fool lol. I had checked that too, before posting; guess I did the math wrong. Closing.
-
@Matt173 600 MB/s is very good for 4 drives, especially since you say your drives do 170MB/s on their own; you are very close to RAID0 performance (I'm not really familiar with FreeNAS, I just quickly Googled it, but I did see it can do RAID0 or Mirrors like RAID1.) So you run a VM on the same machine, and read the disks through a virtual network adapter? Amazing, I would've tried something like FlexRAID first, I wouldn't ever have thought of running a NAS in a VM lol. As for your use case, I don't find it unorthodox. You needed stripping and duplication and obviously did not want or could not use a RAID or that's what you'd be using. I guess most people use DrivePool to do JBOD, but since it's supposed to do stripping, using it for performance is legitimate I think. Alright, I'm going to bed ;-) Regards,
-
Hi Christopher. Tonight I did some operation on the pool and it was pretty slow, so I went to have a look at the logs (found lots of "Incomplete file found" repeatedly, for the same file; not sure why it dumped the warning 20 times in the log) and had a look at the console too (it was "checking" when I looked, I forget the exact wording). Anyway, once DrivePool was finished "Checking" and "Balancing" everything went back to normal. I think something happened, but I can't say what, it's the first time it's ever gone "slow" on me. Anyway, what I DID notice is that the timestamps inside the logfiles all started at around 10pm. This is when I logoff from 1 user and switch to the Administrator user to do maintenance, install new software, etc. DrivePool is not appending to the log, it is overwritting it. I would definitively call that a bug; we need logs to persist (in fact it keeps daily logs for some days, so the intention *is* to persist). Can you raise a bug report? Thanks! Best Regards,
-
Hi @Matt173. You know, I haven't really tried to send concurrent requests for multiple files, to see if it would spread the load to multiple disks; it's a good question (I'll take your answer that it does a good job of it.) I do think that something's not quite right with the stripping. Like you say, it tries to be intelligent about it - it has no choice, it lets you add network shares to the pool (kinda nuts if you ask me, but very popular, Christopher uses that (I think)) EDIT: It does not let you add network shares - so it has to have all kinds of logic to try and be intelligent. I can't tell exactly where the bug is. I think also that the driver is single threaded, so there may be limitations in that. I discussed this with Christopher in private, and Alex is supposed to write a Nuts & Bolts article about how stripping works. I am hoping we can reply and discuss (certainly with Christopher, but maybe Alex can chime in too.) You have to remember that he is the sole programmer, and that they have embarked on another project (CloudDrive) which will require constant development as cloud provider API change and as providers come and go. We just have to be patient. What other product are you trying? Regards,
-
Trigger a scheduled task or script after balance?
B00ze replied to fattipants2016's question in General
This isn't working for me. I've got this: "DrivePool_RunningFile": { "Default": "", "Override": "D:\\StableBit DrivePool\\Service\\CurrentlyBalancing.txt" }, Then I pick an un-duplicated folder and make it duplicate - no file is created while the duplication is running... I restarted the DP service, which should be sufficient for it to re-read the json file. I'll try rebooting but I shouldn't need to... Regards, -
Good day, been away a little. @Matt173 Yeah, something's not quite right with Read-Stripping, i.e. It hardly ever strips. But don't use the DrivePool UI, load-up Resource Monitor and switch to the disks, then start a large file copy to the SSD. You will see that it mostly ever reads from a single disk (I get a 12.5% speed increase with stripping enabled, I was expecting at least 50% (not 100% like a RAID.)) Look at the bar graphs too, you can see easily that it works 1 disk at a time. I wish you'd replied to the thread I started about this; I did ask everyone about their read-stripping performance there. Have a look at the thread, I explain how I think it should work, roughly, and why I think something's wrong. I talk about stripping performance in the Placement Rules thread as well. What Performance do you get from stripping Placement Rules (and initial remarks on stripping performance) What Matt did is copy several large files (so 1 file at a time) to a much faster disk. The fact that he got the transfer speed of 1 drive clearly means stripping does not work. Selecting a real hard disk over a duplicate copy on a USB drive is not read-stripping, it is simply being intelligent about selecting a source. Requesting read I/O on BOTH of these drives at the same time is read-stripping. And DrivePool is supposed to be really smart about this too, it will send most of the I/O to the real disk when the copy is on USB. The problem we see is that when both copies are on real disks, is STILL sends most of the I/O to a single disk, this is not exactly optimal. Regards,
-
Good day. Yup, the "Balance on the fly" would be slow, since you'd have to check ALL drives for the folder. For large folders, you do NOT keep it together; what you do is place any new file into the volume where the folder already has the most data (comparing all the volumes where the folder exists) AND where there is space (and not limited by some rule.) So not only do you have to check all drives, you have to calculate the amount of space the folder takes on every drive, so you can tell which drive to pick, and that means scanning all the files inside. It would make everything slow. One way around this is to just place the file anywhere where there is space, and just balance later. As far as depth, it does not matter : You treat all folders as singles - i.e. Subfolders NEVER count, they are just another folder to keep together; you just try to keep the FILES together, not the Subfolders. All of these problems are with nothing else running. What happens when you throw in Placement Rules, duplication and other balancers? Gets crazy pretty fast. It's probably do'able, and you can cut corners (place any new file anywhere and balance later). But there sure is a lot to think about. Regards,
