


APoolTodayKeepsTheNasAway
-
Posts
18 -
Joined
-
Last visited
APoolTodayKeepsTheNasAway's Achievements
Member (2/3)
0
Reputation
-
Would it be possible to maybe speed up the process by removing things in batches rather than doing everything at once resulting in what I assume is thrashing? Of course doing that is probably complex, and I assume its not just one hidden setting, but I assume it does things like checking whether or not files copied correctly, status etc, and perhaps transferring a few then doing all the secondary things would greatly improve the speed. Sort of like: 5 Copy > 5 Checks > Repeat instead of 1 Copy + 1 Check > Repeat Where copying separately allows the drive to transfer at nearer to its full speed of ~200MBS vs ~30MBs
-
In this case where you want it done asap, my bet for the fastest way is this: Steps: Add the new drives to your pool without doing any balancing. Label all your old drives, maybe A-Old B-Old C-Old etc and the new drives A-New B-New etc (A spreadsheet can help keep this organized) Stop the drive pool service, make sure you arent using any of the files. Copy everything from the respective drive to the new drive (so for example, copy everything in the hidden folder PoolPart.[bunch of numbers and characters] in A-Old to PoolPart.[bunch of numbers and characters] in A-New). Once each drive has been copied over to the respective new drive, you can then recycle bin/delete the old drive data for poolpart (This is just copy, then delete instead of move), restart your computer and with it the Drivepool service will also restart and remeasure. At this point, you may remove the old drives using the in built removal action, and as the old drives will be basically empty, it should take no time. The whole process vs the remove button should, from my experience, be much faster though much more hands on (as the remove button involves no spreadsheet or service stopping). Just so you know how I've come up with this, its based on this line of reasoning I've seen a few times in responses: There was a better post about this including the bit about stopping the service just to be on the safe side, so I recommend searching for something along those lines, but thats the best way I can think of without having to wait for the slower removal process. That being said, of course this isn't the way its designed to work and if you're really worried about that data, apart from suggesting you make a backup just in case, I also might recommend you wait till @Christopher (Drashna) responds here as obviously he knows better than anyone responding most likely. Another method I just thought up is simply cloning the drives over since you have 4 new ones and 4 old ones. Each drive would just get cloned to a newer drive. No data loss, no speed issues. The reason I suggested the above is because Ive myself just moved things into the poolpart folder before whereas Im not sure of the behaviour of drivepool with cloned drives (Whether or not itll pick them up as being the same drive or if youll need to add the new drives into the same pool for instance). I should think all youd do is after cloning without drive pool, remove the old drives from the computer, insert the new ones and have drivepool see the new pool, but like I said, Im unsure of that method so its why in order of most recommended to least, id suggest: Waiting for the response of the person Ive referenced Trying the first thing I suggested (after making sure backups you have are up to date preferably) Simply using the remove action built in Trying the third option listed that Im unsure about. I'm sorry I have no 100% confidence replies but hopefully I gave you some info that helps in at least finding the best solution for you.
-
How many data streams are involved in balancing/removal?
APoolTodayKeepsTheNasAway posted a question in General
I ask because I noticed that with the remove action, transfer speeds are slow while active time is high. This is weird to me as transfering regularly to the drive is multiple times faster with less usage often. Is there something else at play apart from simply transferring the files in the background? Are multiple files being transferred at once? If so, is there a way to change this? I have been previously advised to try setting the background IO priorities to false, and this is with that in place so I can only imagine this is the only way transfers could remain at this speed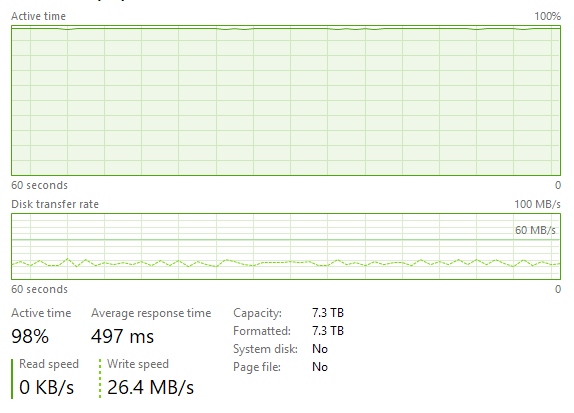


-
Like the post below, it seems that when removing a drive from a pool, transfering is a lot slower than expected. In tests the drive thats having data transferred to it performs as expected with sequential writes (180MBs+) yet here looking at task manager, Im only seeing speeds of up to 50MBS but usually 30MBs with the empty, new, faster drive having the higher utilization percentage. I cant figure out why exactly. Does the remove perhaps try to write multiple files at a time thrashing the drive and causing the low speeds with high usage? I cant imagine thats the case as the drive doesn't sound like its thrashing, yet "remove" always seem this slow, the same speed as balances (even after trying the tweak suggested in the thread below). Id really love to get to the bottom of this as it feels like Im just wasting my time waiting for remove to complete where I could have copied in windows beforehand for a better result. I just cant figure out why this would be slower than that.
-
Thanks, but while I do see the speed occasionally go up to 50 and 60 so at least its an improvement), its still a far cry from what I've seen the same drives do in tests.
-
 APoolTodayKeepsTheNasAway reacted to an answer to a question:
Balancing has drives transfering far slower than what they are capable of doing.
APoolTodayKeepsTheNasAway reacted to an answer to a question:
Balancing has drives transfering far slower than what they are capable of doing.
-
Ive noticed that while balancing, or removing from pool, transfers seem to only occur at about 40MBs whereas a normal manual transfer or test on the drive can see upwards of 150MBs. Is there a way around that? Is it a purposeful restriction?
-
That sounds mostly like what Im looking for actually, well sort of but also totally even though I dont have Excel. I assume other spreadsheet programs such as Google sheets or Libre Office would work. I say sort of because I've realized I asked the wrong question as sync/backup software would cover just missing files, and hopefully be smart enough for name changes, but instead I was looking for how to figure out what files weren't backed up. Luckily I think your question answers that too as I imagine I could just compare the files after recovering from the backup and find out which ones still arent there. Thanks
-
Drivepool Backup solutions? (looking for suggestions)
APoolTodayKeepsTheNasAway replied to APoolTodayKeepsTheNasAway's question in General
Ah, alright, Il see what I can find then. Also I think perhaps my edit was missed so forgive me for asking again, but what about the second question of a drive pools longevity? I basically just want to know Il never end up being unable to recover from the offline/disconnected drive pool as that'd kinda eliminate the whole point of having it. -
Drivepool Backup solutions? (looking for suggestions)
APoolTodayKeepsTheNasAway replied to APoolTodayKeepsTheNasAway's question in General
Thats kind of what I was asking for really, suggestions of backup/sync software that people who use drivepool have tried and works for them (preferably with deduplication (smart acknowledgement of folder filename changes) to avoid multiples), and now that I think of it, also for detecting lost files that weren't in the backup without having to manually sort through a list. Goodsync seems to do most of this except the last part for example. Also what about the second question of a drive pools longevity? I basically just want to know Il never end up being unable to recover from the offline/disconnected drive pool as that'd kinda eliminate the whole point of having it. -
Drivepool Backup solutions? (looking for suggestions)
APoolTodayKeepsTheNasAway posted a question in General
Im currently planning to have 2 pools with a few drives each and no duplication on either. Im wondering how backup and recovery can be accomplished with this setup. Specifically, id like to answer 2 questions: 1. How can I recover only missing files (with the correct folder structure) from a backup in the event of drive failure. (programs, suggestions and/or anecdotes welcome, Im trying to find the optimal solution) 2. How long can a secondary pool made for offline backup stay without being updated/connected? WIll future updates make older pools unreadable and if so how much warning could I expect for such a change? -
Is there anyway this could be used to restore only the missing files in the event of a drive failure?
-
Drive pool backups/Keeping files in folders together
APoolTodayKeepsTheNasAway replied to APoolTodayKeepsTheNasAway's question in General
Yea, I was really hoping @Christopher (Drashna) could confirm this would work for the long term, because while Im grateful for the replies of other users, only developers/associates really will be able to give a firm/definitive answer. What Im kind of afraid of is Il start using this for backups, then an update will come which makes the inactive pool unable to be read or used correctly in Drivepool which would severely hurt its usefulness as a backup given a key focus of the backup would be retaining organization. -
Drive pool backups/Keeping files in folders together
APoolTodayKeepsTheNasAway replied to APoolTodayKeepsTheNasAway's question in General
That would work too I think, That requires a lot more micromanagement though than if #offolders>#offiles;keep together however. What I mean is 2 separate pools. The plan is to have one pool offline most of the time as a backup for the other pool so pool 1 would have 4 drives, and occasionally I would connect pool 2 drives to sync pool 1 contents. Im just wondering if there are any inherent problems with that (mainly to do with taking a pool offline. -
I was using the latest Stable version from the website. Using this version, from the start, smart data is readable without the rest of the steps.
-
Drive pool backups/Keeping files in folders together
APoolTodayKeepsTheNasAway replied to APoolTodayKeepsTheNasAway's question in General
Thanks for the response. I have no idea how big a change it would be but, something similar to file placement rules, like folder placement rules would mostly accomplish what Im looking for with 2 pieces of information. Like for example a rule that goes if number of files (direct child(not counting files in sub folders)) > number of folders (direct child(not counting folders in sub-folders)) ; keep together. This would allow far less micromanagement but keep most folders recognizable. Also, about the backup part, would an offline backup using drivepool be possible (safe), as in can I take a pool of say 4 drives, create a pool on them, to backup another pool, and take them offline to update them periodically. Short of that would you happen to know any backup software that could keep daily backups of filenames/folder structure to restore missing files?