


msq
-
Posts
18 -
Joined
-
Last visited
-
Days Won
1
Everything posted by msq
-
You and your fibre broadband bubble Fair enough, thank you for your response. We'll wait for a message from Alex.
-
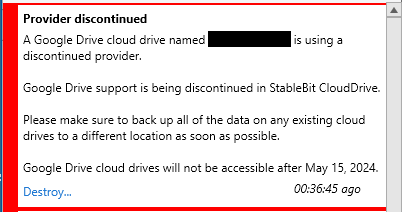
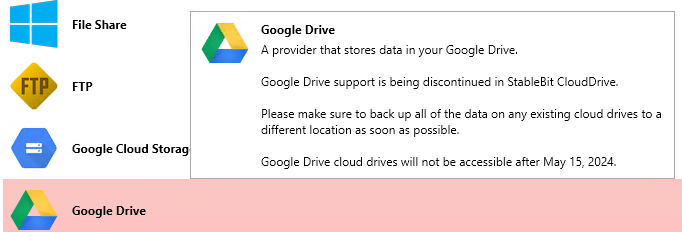
You're 100% right, this is a massive change and for me puts the whole CloudDrive & DrivePool setup in question This is how it looks like in 1.2.6.1710 beta, not really explaining anything:

-
@srcrist@RG9400@ksnell Thank you guys for bringing it up! One question - are those individual keys for all configured Google Drives? This entry in %PROGRAMDATA%\StableBit CloudDrive\ProviderSettings.json is a global entry, so what will happen if I will setup the keys for Google Account A while in CloudDrive I have configured Google Drive A, Google Account B and so on? Based on the fact it worked so far with StableBit keys - I would assume this should work, but does anybody tried that? Last thing I want to mess my CD setup.... :|
-
And that helped Thank you, need to add it to my KB, but it looks like dirty workaround rather than proper solution.
-
Nah - 'Repair' did not solve the issue. And I have a dejavu - I think I already experienced this issue but I can't find where... :|
-
Local service is not affecting GUI connected to remote host. It can be stopped, restarted etc - GUI & remote host combo will still work. My host machine was restarted a couple of times last few days and the problem persist. It could be IU will try to run installer once again and select 'Repair' option. Thank you for this suggestion! And CCleaner is not something I would recommend by the way https://en.wikipedia.org/wiki/CCleaner#Security_flaws
-
Hello, Scanner 2.5.4.3216 was used to control instance on remote machine. Now I would like to go back to local but... can't :| In the top left drop down 'Connect to' I can only see two remote servers, there is no local machine. I checked and service is running. Any hints how to switch back? Thank you!
-
No - I'm doing the quick format and - more or less - I understand the difference. Ok, thank you!
-
Hello, Let's say I have a cloud based drive - 500GB total size, 50GB of data on this drive - with 25GB already in the cloud and 25GB as 'to upload' and uploading. And at that stage for whatever reason I need to format such drive and start again - for the sake of this scenario let's say it was unrecoverable chkdisk error and format is the only solution. So I'm formatting the drive - the drive in system shows as empty - full 500GB of space is available. I'm copying 10GB of new data and now I have this: total size of drive - 500GB (new) data on the drive - 10GB already in the cloud - 25GB 'to upload' - 35GB 'Clean up' is not cleaning this up actually. So what is happening here? What is that 'empty' / old / pre format 25GB of data that still needs to be uploaded? How those 50GB will be utilized in the future - is that going be replaced with new data? Wat is the process here? Any explanation will be much appreciated, thank you!
-
With the amount of data I'm using that should not be an issue. So far it is still below $1.0 Apart from that I got daily cap warnings set up so I don't think that could come as surprise!
-
In the very latest beta 1.1.0.991 the B2 provided has been added Downloaded, installed, set up and using already. Thank you guys!
-
Thank you - good point. I had it set to something non-default already but most likely during some re-installation this has been lost. But hey - I just noticed something in change log Thank you once again and will test that next few days! .988 * Added an option to automatically retry mounting drives. See "Automatically retry mounting" under Options. - Drives that were unmounted due to an incorrect or missing encryption key, an unknown storage provider, or damaged metadata will not retry mounting automatically.
-
No. You wouldn't want this. This can cause issues, it could cause serious performance/reliability issues? Like would you use a drive long term that would randomly and frequently disconnect from the USB hub? No, I wouldn't. But what I meant by "feature that will automatically re-connect cloud drives" is some functionality that will perform exactly the same action as user from the front end by clicking 'Retry' - that's all. Every x minutes if drive gets disconnected. If there will be no connectivity - nothing will happen. But if the connectivity will be back - drive will be just reconnected. I'm on a rather crappy internet here and sometimes cloud drives get disconnected. All I have to do is click 'Retry' and it is connected again. I'm asking to get this 'Retry' action automated. IUt could be turned off by default and hidden deep into advanced json setup - that's fine. If that is gui action someone will finally write a script that will mimic such click
-
There is a couple of issues and questions about measuring. Why it is not optimized / cached / smarter? Case 1: If there is a pool of 2 or more drives and one is disconnected for whatever reason - once the drive is back entire pool is measured. If that is large, cloud based pool with a lot of small files - a short interruption in connectivity triggers hours of measuring. Would that be possible to cache results of previous measure run and measure only the drive that was reconnected? Case 2: Four cloud based drives CLD1, CLD2, CLD3 and CLD4 are coupled in two pools: CLD1+2 and CLD3+4. Those two are paired again as a pool CLD1+2&CLD3+4. And this pool is coupled with physical drive in the highest level pool: HDD1&CLD1+2&3+4. Apart from CLD1+2 and CLD3+4 - every other pool is set to duplicate all files. Now - when measure is running it is starting from the highest level, then is measuring middle tier and two on the lowest level. So files on the cloud based drives are actually measured three times. Would that be possible to start from the lowest level, then cache and re-use data it on higher levels? Why it is so sensitive? Case 3: Let's say there is more than one pool running measure. As far as I can see this is slightly misleading - as only one pool can be measure at a time - other pools are actually awaiting. If for whatever reason one drive in the pool that is NOT currently effectively being measured disconnected and reconnected - measure on the other drive is restarted. Why..? And is it possible by change in configuration to allow more than one measure thread to run? Would that be possible to set specific measure order for pools? Case 4 (feat. CloudDrive): As mentioned above - short interruption in internet connectivity can disconnect all cloud drives, enforce manual intervention (re-connect) and massive re-measure. Would that be possible to make CloudDrive drives a bit more offline-friendly and disconnection resistant ? In cases when there is no pool activity from users? And can we receive some feature that will automatically re-connect cloud drives, please? Thanks EDIT: typos, wording
-
Constant "Name of drive" is not authorized with Google Drive
msq replied to irepressed's question in General
I experienced that on 976 as well, but not that often as before. One thing I noticed - this 'Reauthorize' requests can be ignored and will disappear after a while - sometimes after 3 minutes sometimes after 6 hours. I never yet experienced drive to be disconnected after this 'Reauthorize' message. -
Thank you
-
Hello, Is there a way to move CloudPart.xxxxxxxx folder, where metadata and cache is stored from one location to another within the same machine without destroing and recreating entire drive? In my case - from P:\CloudPart.xxxxx to Q:\CloudPart.xxxxx ..?
-
Experienced this strange behaviours already as well. The funny thing is that after the crash some drives that were fully uploaded after recovery were just fine - while others were re-uploadiung everything..... So it sounds like a poor design. Can't imagine any database doing this after unclean shut down. Apart from that - if I will loose the drive where local cache was stored - assuming everything was completely uploaded - doest that mean I will loose my data stored in DriveCloud? With this or you';ll "force" the app to trust what is uploaded or ... loose your data.


