


steffenmand
-
Posts
418 -
Joined
-
Last visited
-
Days Won
20
Posts posted by steffenmand
-
-
On 11/10/2020 at 3:08 AM, Shane said:
20 is the global limit default for the CoveFs_AsyncNormalThreads setting. You may find the information at https://wiki.covecube.com/StableBit_DrivePool_2.x_Advanced_Settings useful, if you're willing to proceed at your own risk.
Are you sure this is also an option when using CloudDrive alone?
Wanted to try and edit my settings, but for some reason its empty now :D - Did they change something in recent versions casusing the Settings.json to be empty (0 bytes)?
-
5 hours ago, ilikemonkeys said:
I get the errors: Checksum mismatch: data from the provider has been corrupted
I'm trying to run a "chkdsk H: /r" to see if it can be repaired, but after several attempts, it just hangs forever with no additional progress.
Any suggestions?
If you have a lot of content then expect it to take days...
Alternatively use recuva to recover files
-
Hi,
Im currently using a 32 core system (64 threads) but i simply cant see Stablebit using more than 20 threads maximum at any given time, eventhough i have 10 drives split over 5 different users.
Are the limits for a drive (20 threads) also the global max ? - If so is it possible to get it changed to 20 threads PER USER as each user has its own API limits?
If its not limited globally, what could the issue be when threads start to be few if multiple drives are in use at the same time ? - i use NVMe drives and they are not reaching their peaks at all.
In the end i would love to see 16 threads on one drive and 14 on another.
Instead im seeing 3-4 threads on 1 drive, 2 on another and then maybe 4 on a third. (read + write combined)
-
On 12/21/2017 at 9:48 PM, Christopher (Drashna) said:
It may be. OneDrive for Business is backed by sharepoint, which is known for performance issues.
It's been requested in th the past, aind it's a feature request.
As for an ETA, I can't even begin to comment on that.
I actually like this feature request - being able to cache headers of your files up to X GB. It would for certain improve a lot of stuff in various usecases
-
On 7/7/2020 at 10:04 PM, Chase said:
All of my drives are working and I have no errors...EXCEPT the last beta that changed the GoogleDrive_ConcurrentRequestCount to "2" appears to be causing issues. My drives tend to do a lot of reading and writing...it's for a plex server. And 2 concurrent causes CloudDrive to tell me I don't have enough bandwidth. I have tried to change the setting in the "settings.json" but it isn't accepting the change.
The newest beta works great for me - i still have a great speeds and the drives are upgrading fine (25% per day)!
Only annoying bug i have atm is that if i try to attach a new drive, then it will fail and give me a folder i cant delete. After a reboot the drive will mount (although it said it failed, but due to the folder being there) but not upgrade as it is supposed to.
So since im moving my drives to a new server im only able to move and upgrade 1 drive at a time (although my drives are split over 5 google accounts and in theory have api limits on each account).
So my wish would be a new version which supports mounting new drives, while an existing is upgrading
") - and fixing so that a drive which fails at being mounted doesnt get undeleteable due to being in use
- and fixing so that a drive which fails at being mounted doesnt get undeleteable due to being in use
-
1 hour ago, srcrist said:
OK. My mistake, then. I haven't started this process, I just thought I remembered this fact from some rClone work I've done previously. I'll remove that comment.
1306 doesnt show any files being moved though like 1305... so dont know if it works or not :-P
-
5 minutes ago, Burrskie said:
Mine is the same as this!! It's frustrating, and I have tried every version including the latest one just released. It still shows no progress bar at all. I have no clue and it's been running (supposedly) for roughly 4 days with a few reboots in between...
I can see chunks being moved on my drive, so i know its running! We just have to give it time :-)
-
Mine is still going... complaining about Userlimitexceeded.
Going on Google i can see it has not moved files since the night to sunday... so for me atleast it will take a looooooong time if we dont get a higher API rate limit! And this is the first drive i have out of 12

-
4 minutes ago, josefilion said:
So after about 20 hours, It remounted,
I recommend using the beta like chase said and just be patient. Just writing this for people who are looking for similar answers.
Thank you @Chase @steffenmand
The reindexing you saw was normal since waaaay back. Its to avoid corruption, then it rebuilds the chunk database by going through them 1 by 1
The numbers you saw were chunk id's
-
33 minutes ago, Chase said:
That is where I put it.
Now upon closer look the log is still giving me the same error but it is no longer telling me it cant mount the drive and the percentage is going up still where it wasn't before.
Seems to make no difference here...
Same error and still no % counter. My guess is that you guys got to a certain point before the limit was reached, where mine didnt get started. Anyway i hope they will have a fix for this soon - just sucks that stuff like this always have to happen in weekends
-
1 hour ago, Chase said:
I was on the stablebit API key and it locked me out for the limits. So I created my own API key, saved it in the provider settings json, and reset my machine. The race is back on now.
it started the percent over again the same as it did when i restarted my PC earlier. And it's not climbing any faster as if the new percent level is "of what was left"...its more like it completely started over the full process.
What field does the key go in? And is it in ProviderSettings.json?
-
Your drive is reindexing - it can take a while.
Most likely due to og being closed wrong
-
Just now, steffenmand said:
Thats the one i got :-)
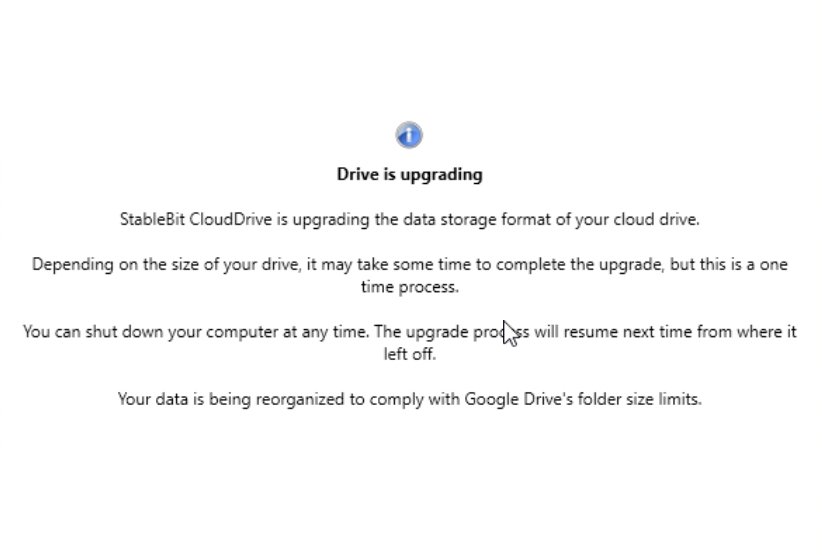
-
23 minutes ago, Paco said:
Try to install the latest version 1305
Thats the one i got :-)
-
so weird all of you see a %! i see nothing
-
1 hour ago, Chase said:
I know you are responding to "josefilion" however i'm learning here so i'm going to step in too.
is the log you are referring to the "service log" under Technical Details?
If so, Mine has all lines that say "[ApiHttp:18] Server is temporarily unavailable due to either high load or maintenance. HTTP protocol exception (Code=ServiceUnavailable)." My percentage is going up though very slowly.
Yea in there!
Try going up to the log levels and set ApiGoogleDrive to verbose - do you get Userlimitexceeded?
-
12 minutes ago, josefilion said:
So I deactivated the Stablebite Clouddrive and remounted it after installing windows 10 again, I have about 20 TB - It's been mounting for 20 hours now, just wondering if it stuck or because of the size that's why it's taking so long.
Thank you.
What does the log write ? Maybe you ære hit with Userlimitexceeded like me. Then it will never finish untill limits are fine again
-
Just now, Chase said:
What user limit are you referring to? It doesn't appear that it is downloading or uploading anything so it shouldn't effect the daily upload cap.
Thanks in advance.
I get a userlimitexceeded error. So API calls are not processed
-
3 minutes ago, Chase said:
I just restarted my computer...the percentage started over. Not sure if the whole process is starting again or if this is the percentage of what is left. FML
My guess it is the % of the remaining. = it will increase faster than initially from every reboot.
Mine is stuck however with the user limit
-
Is anyone having issues creating drives on .1305 ?
It seems to create the drives, but are unable to display it in the application!
I also notice that all of you get a % counter on your "Drive is upgrading"... mine doesnt show that - is there something up with my installation?
EDIT: A reboot made the new drive appear, but i can't unlock it. Service logs is spammed with:0:02:04.0: Warning: 0 : [ApiHttp:64] Server is temporarily unavailable due to either high load or maintenance. HTTP protocol exception (Code=ServiceUnavailable).
EDIT 2:
After ouputting verbose i can see:
0:04:42.8: Information: 0 : [ApiGoogleDrive:69] Google Drive returned error (userRateLimitExceeded): User Rate Limit Exceeded. Rate of requests for user exceed configured project quota. You may consider re-evaluating expected per-user traffic to the API and adjust project quota limits accordingly. You may monitor aggregate quota usage and adjust limits in the API Console: https://console.developers.google.com/apis/api/drive.googleapis.com/quotas?project=962388314550
As im not using my own API keys, the issue must be with Stablebit's
Did the drive updates make Stablebit's API keys go crazy? -
4 hours ago, Firerouge said:
I'm guessing this latest beta changelog is referencing the solution to this
.1305 * Added a progress indicator when performing drive upgrades. * [Issue #28394] Implemented a migration process for Google Drive cloud drives to hierarchical chunk organization: - Large drives with > 490,000 chunks will be automatically migrated. - Can be disabled by setting GoogleDrive_UpgradeChunkOrganizationForLargeDrives to false. - Any drive can be migrated by setting GoogleDrive_ForceUpgradeChunkOrganization to true. - The number of concurrent requests to use when migrating can be set with GoogleDrive_ConcurrentRequestCount (defaults to 10). - Migration can be interrupted (e.g. system shutdown) and will resume from where it left off on the next mount. - Once a drive is migrated (or in progress), an older version of StableBit CloudDrive cannot be used to access it. * [Issue #28394] All new Google Drive cloud drives will use hierarchical chunk organization with a limit of no more than 100,000 children per folder.Some questions, seeing as the limit appears to be around 500,000, is there an option to set the new hierarchical chunk organization folder limit to something higher than 100,000?
Has anyone performed the migration yet, what is the approximate time it takes to transfer a 500,000 chunk drive to the new format? Seeing as there are concurrency limit options, does the process also entail a large amount of upload or download bandwidth?
After migrating, is there any performance difference compared to the prior non hierarchical chunk organization?
Note, I haven't actually experienced this issue and I have a few large drives under my own api key, so it may be a very slow rollout or an A/B test.
i would guess chunks just gets moved and not actually downloaded/reuploaded! only upload is to update chunk db i suspect
-
Going to https://console.developers.google.com/apis/library/drive.googleapis.com and pressing "Enable" and afterwards disabling it again seems to make the issue go away.
Google must have done some not so smart changes
-
So weird, this seems to make it work on my end also!
Just go to
https://console.developers.google.com/apis/library/drive.googleapis.com
Press "Enable" and afterwards go disable it again - voila it works. -
2 minutes ago, CDEvans said:
Neither do I mate. From what I can tell that shuts does all access to Google drive and then gives access again. If you have the same error give it a shot.
Will give it a try and report back - would be weird if that fixes it

Is the 20 threads a global lock or per drive?
in General
Posted
Yea i know those settings and none of those changes the global limit
So i think the global thread settings are either hidden or hardcoded into the code - although i dont get the reason as the limit should be per account and not across all your drives