


Alex
-
Posts
254 -
Joined
-
Last visited
-
Days Won
50
Posts posted by Alex
-
-
I've received 3 more dumps and will review them to see if they correlate with everything that I've seen so far.
I'll try to get a new build out today that, at the very least, will turn off Fast I/O cached reads on the Win 8 kernel (which are causing srv2.sys to run the code that is crashing the system).
-
There is one other thing I would really like to see added to DP, as you talk about folders tagging Alex.
This is folder based balancing.
For now you balance on a per file basis, distributing them across the HDDs.
You already have a plugin to group files depending on the moment they are created.
What would be really great is to tag a folder so that its entire content is always kept on one HDD (no matter which one); when rebalancing the entire folder is considered as one unit to balance; when new files are created on that folder, they are created on that HDD.
This is a pretty interesting feature request. I've considered this, and actually it would be super simple to implement a per-folder name placement limit in the kernel.
We can control file placement by file name (including wildcard patterns) or file size.
For example, you might be able to say something like:
- I want all files that match this pattern \ServerFolders\ImportantDocuments\* to be placed on Drives 1, 3 and 4 only.
This is all very easy to do, given our existing infrastructure.
The problem with implementing something like this is that the non-real time balancer is not designed to deal with this. In other words, the module that reshuffled your existing files into their designated locations, doesn't understand folder names, and it would be non-trivial to implement this (because of performance considerations).
If we were only interested in controlling new file placement, we could have this feature next week.
But this is really something that I would like to do eventually.
-
Regarding parity, we touch here to something else that is a major advantage of DP to me: the ability to access my data by plugging a previously pooled HDD in any computer, without any specific install.
I am ready to pay the cost of full duplication instead of parity for this advantage.
My thoughts on parity agree with your. I have some terabytes of personal data, and do not feel that I'm missing anything because I don't use parity.
In fact, I feel even more secure.
I know that all of my files are stored as standard NTFS files, which can be accessed and recovered by countless software developed over the past few decades.
-
Per-pool-only would require getting rid of the current DP limitation of one pool per volume, otherwise we're simply replacing "disk juggling" with "volume juggling".
Per-pool-only also means multiple UNC shares, which raises the specter of move-via-copy shenanigans (unless we mount the pools as virtual folders instead of virtual drives, which is inelegant, etc).
That's very accurate.
Those 2 points are right on target and make perfect sense, in terms of the technology.
I guess I'm always looking to simplify things, but this simplification might come at the expense of sacrificing too much functionality.
-
The reason why NFS support is not enabled on 2.0 by default is because it has not been tested thoroughly yet on all of the supported operating systems. I don't want to enable it unless I'm sure that it works on every supported OS.
From what I understand right now, it does not work with the Microsoft's NFS service on Windows Server 2012.
However, I've had great success with haneWIN NFS in the past (which is super fast), so you might want to give that 3rd party solution a try.
-
Yep, that's the idea.
If you want duplication, why not just simply duplicate the entire pool? It would make balancing a whole lot simpler.
If you want to store non-duplicated files, then just create a new non-duplicated pool.
-
And another dev question.
When you say that "The crash occurs at the point when the function tries to access the MdlFlags member of mdl1", are you talking about the access in the if test or the do...while loop?
In other terms, is the first mdl causing the crash, or one in the linked list?
Here is the decompiled code from srv2.sys that is crashing.
if ( mdl1 && mdl1 != mdl2 && !(mdl1->MdlFlags & MDL_SOURCE_IS_NONPAGED_POOL) ) { do { mdlCurrent = mdl1; mdlFlags = mdl1->MdlFlags; mdl1 = mdl1->Next; if ( mdlFlags & (MDL_PARTIAL_HAS_BEEN_MAPPED | MDL_PAGES_LOCKED) ) { MmUnlockPages(mdlCurrent); } IoFreeMdl(mdlCurrent); } while ( mdl1 ); *(_DWORD *)(Length + 4) = 0; }So right in the if statement, srv2 is trying to test whether mdl1->MdlFlags contains the MDL_SOURCE_IS_NONPAGED_POOL value.
mdl1->MdlFlags is an invalid statement. mdl1 is already freed at this point, it has no flags (it doesn't exist).
-
I have two questions for you:
- what is the performance impact of this option? (speed up net accesses? consume CPU?)
- what would be the impact of turning of Fast IO as you suggest?
For my personal take on Fast I/O see: http://blog.covecube.com/2013/05/stablebit-drivepool-2-0-0-256-beta-performance-ui
(scroll down to the Fast I/O section)
I believe that I've described it rather well in that post. In short, it's not important but good to have.
We are due for a new version today, but I've delayed making a release because of this issue. I am seriously considering disabling Fast I/O read requests on Windows 8 in future builds due to this issue.
-
Continuing the thread from the old forum: http://forum.covecube.com/discussion/1129/critical-bsod-when-accessing-dp-over-a-network-share
Just to recap, I've received a number of memory dumps over the past month or so showing a system crash in srv2.sys. Srv2.sys is Microsoft's file sharing driver that translates network file I/O requests into local file I/O requests on the server, but the implication is of course that StableBit DrivePool may somehow be the cause of these crashes. The crashes only occur on Windows 8 / Windows Server 2012 (including Essentials).
Paris has submitted the best dump to date on this issue and I've analyzed it in detail.
I'm going to post a technical description of the crash for anyone who can read this sort of thing.
What we have
- A full memory dump of the crash.
- Verifier enabled on all drivers at the time of the crash (giving us additional data about the crash).
- ETW logging enabled on CoveFS / CoveFSDisk, giving us everything that CoveFS did right before the crash.
The system
3: kd> vertarget Windows 8 Kernel Version 9200 MP (4 procs) Free x64 Product: Server, suite: TerminalServer DataCenter SingleUserTS Built by: 9200.16581.amd64fre.win8_gdr.130410-1505 Kernel base = 0xfffff800`65214000 PsLoadedModuleList = 0xfffff800`654e0a20 Debug session time: Fri May 31 04:45:08.610 2013 (UTC - 4:00) System Uptime: 0 days 0:21:01.550 3: kd> !sysinfo cpuinfo [CPU Information] ~MHz = REG_DWORD 3100 Component Information = REG_BINARY 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 Configuration Data = REG_FULL_RESOURCE_DESCRIPTOR ff,ff,ff,ff,ff,ff,ff,ff,0,0,0,0,0,0,0,0 Identifier = REG_SZ Intel64 Family 6 Model 58 Stepping 9 ProcessorNameString = REG_SZ Intel(R) Core(TM) i7-3770S CPU @ 3.10GHz Update Status = REG_DWORD 2 VendorIdentifier = REG_SZ GenuineIntel MSR8B = REG_QWORD ffffffff00000000
The crash
3: kd> !Analyze -v ******************************************************************************* * * * Bugcheck Analysis * * * ******************************************************************************* PAGE_FAULT_IN_NONPAGED_AREA (50) Invalid system memory was referenced. This cannot be protected by try-except, it must be protected by a Probe. Typically the address is just plain bad or it is pointing at freed memory. Arguments: Arg1: fffffa8303aa41ea, memory referenced. Arg2: 0000000000000000, value 0 = read operation, 1 = write operation. Arg3: fffff8800556e328, If non-zero, the instruction address which referenced the bad memory address. Arg4: 0000000000000000, (reserved) Debugging Details: ------------------ READ_ADDRESS: fffffa8303aa41ea Nonpaged pool FAULTING_IP: srv2!Smb2ContinueUncachedRead+26c28 fffff880`0556e328 410fb644240a movzx eax,byte ptr [r12+0Ah] MM_INTERNAL_CODE: 0 IMAGE_NAME: srv2.sys DEBUG_FLR_IMAGE_TIMESTAMP: 51637dde MODULE_NAME: srv2 FAULTING_MODULE: fffff880054ff000 srv2 DEFAULT_BUCKET_ID: WIN8_DRIVER_FAULT BUGCHECK_STR: AV PROCESS_NAME: System CURRENT_IRQL: 0 TRAP_FRAME: fffff88004d3fb60 -- (.trap 0xfffff88004d3fb60) NOTE: The trap frame does not contain all registers. Some register values may be zeroed or incorrect. rax=fffffa830396c150 rbx=0000000000000000 rcx=0000000000000000 rdx=0000000000000000 rsi=0000000000000000 rdi=0000000000000000 rip=fffff8800556e328 rsp=fffff88004d3fcf0 rbp=fffff9801e9e0af0 r8=00000000000006e5 r9=fffff88005544680 r10=fffffa83035a6c40 r11=0000000000000001 r12=0000000000000000 r13=0000000000000000 r14=0000000000000000 r15=0000000000000000 iopl=0 nv up ei ng nz na po cy srv2!Smb2ContinueUncachedRead+0x26c28: fffff880`0556e328 410fb644240a movzx eax,byte ptr [r12+0Ah] ds:00000000`0000000a=?? Resetting default scope LAST_CONTROL_TRANSFER: from fffff8006532f3f1 to fffff8006526e440 STACK_TEXT: fffff880`04d3f978 fffff800`6532f3f1 : 00000000`00000050 fffffa83`03aa41ea 00000000`00000000 fffff880`04d3fb60 : nt!KeBugCheckEx fffff880`04d3f980 fffff800`652a8acb : 00000000`00000000 fffffa83`03aa41ea fffffa83`035be040 fffff880`03cc4419 : nt! ?? ::FNODOBFM::`string'+0x33c2b fffff880`04d3fa20 fffff800`6526beee : 00000000`00000000 fffff980`254b6950 fffff980`1e9e0b00 fffff880`04d3fb60 : nt!MmAccessFault+0x55b fffff880`04d3fb60 fffff880`0556e328 : 00000000`00000000 fffff880`00000000 ffff2f2d`390b1a54 fffff980`01dc8f20 : nt!KiPageFault+0x16e fffff880`04d3fcf0 fffff880`055470de : fffffa83`03c3d1e0 fffff980`01dc8f20 fffff980`254b6950 fffffa83`01f99040 : srv2!Smb2ContinueUncachedRead+0x26c28 fffff880`04d3fd50 fffff880`055455bd : 00000000`00000002 fffffa83`01f99040 fffff980`254b6c60 fffff800`6524acbe : srv2!Smb2ExecuteRead+0x6ce fffff880`04d3fde0 fffff880`05545a64 : fffffa83`0084cd18 fffff980`254b6950 fffff980`1b44efd0 fffff980`254b6950 : srv2!Smb2ExecuteProviderCallback+0x6d fffff880`04d3fe50 fffff880`05543180 : fffff980`1b54cd80 fffff980`1b54cd80 00000000`00000001 fffff980`254b6950 : srv2!SrvProcessPacket+0xed fffff880`04d3ff10 fffff800`65268b27 : fffff880`04d3ff01 00000000`00000000 fffff980`254b6960 fffff880`05546000 : srv2!SrvProcpWorkerThreadProcessWorkItems+0x171 fffff880`04d3ff80 fffff800`65268aed : fffff980`1b54cd01 00000000`0000c000 00000000`00000003 fffff800`652c3ab8 : nt!KxSwitchKernelStackCallout+0x27 fffff880`07f9c9e0 fffff800`652c3ab8 : fffffa83`00000012 fffff980`1b54cd01 00000000`00000006 fffff880`07f97000 : nt!KiSwitchKernelStackContinue fffff880`07f9ca00 fffff800`652c63f5 : fffff880`05543010 fffff980`1b54cd80 fffff980`1b54cd00 fffff980`00000000 : nt!KeExpandKernelStackAndCalloutInternal+0x218 fffff880`07f9cb00 fffff880`05500da5 : fffff980`1b54cd80 fffff980`1b54cd00 fffff980`1b54cd80 fffff800`65277cc4 : nt!KeExpandKernelStackAndCalloutEx+0x25 fffff880`07f9cb40 fffff800`652ac2b1 : fffffa83`035be040 fffff880`05546000 fffff980`1b54cde0 fffff900`00000000 : srv2!SrvProcWorkerThreadCommon+0x75 fffff880`07f9cb80 fffff800`65241045 : fffffa83`03058660 00000000`00000080 fffff800`652ac170 fffffa83`035be040 : nt!ExpWorkerThread+0x142 fffff880`07f9cc10 fffff800`652f5766 : fffff800`6550c180 fffffa83`035be040 fffff800`65566880 fffffa83`0088d980 : nt!PspSystemThreadStartup+0x59 fffff880`07f9cc60 00000000`00000000 : fffff880`07f9d000 fffff880`07f97000 00000000`00000000 00000000`00000000 : nt!KiStartSystemThread+0x16 STACK_COMMAND: kb FOLLOWUP_IP: srv2!Smb2ContinueUncachedRead+26c28 fffff880`0556e328 410fb644240a movzx eax,byte ptr [r12+0Ah] SYMBOL_STACK_INDEX: 4 SYMBOL_NAME: srv2!Smb2ContinueUncachedRead+26c28 FOLLOWUP_NAME: MachineOwner BUCKET_ID_FUNC_OFFSET: 26c28 FAILURE_BUCKET_ID: AV_VRF_srv2!Smb2ContinueUncachedRead BUCKET_ID: AV_VRF_srv2!Smb2ContinueUncachedRead Followup: MachineOwner ---------
From the auto analysis we can see that the memory address 0xfffffa8303aa41ea was being accessed from some code at address 0xfffff8800556e328.
We can also see that the function that crashed the system is srv2!Smb2ContinueUncachedRead.
We can check that memory address and it is indeed invalid:
3: kd> dd 0xfffffa8303aa41ea fffffa83`03aa41ea ???????? ???????? ???????? ???????? fffffa83`03aa41fa ???????? ???????? ???????? ???????? fffffa83`03aa420a ???????? ???????? ???????? ???????? fffffa83`03aa421a ???????? ???????? ???????? ???????? fffffa83`03aa422a ???????? ???????? ???????? ???????? fffffa83`03aa423a ???????? ???????? ???????? ???????? fffffa83`03aa424a ???????? ???????? ???????? ???????? fffffa83`03aa425a ???????? ???????? ???????? ????????
What was srv2 trying to do?
So the next question to ask is what was srv2 trying to do and why did it fail?
I've gone ahead and decompiled the portion of srv2 that is causing the crash, and here it is:
if ( mdl1 && mdl1 != mdl2 && !(mdl1->MdlFlags & MDL_SOURCE_IS_NONPAGED_POOL) ) { do { mdlCurrent = mdl1; mdlFlags = mdl1->MdlFlags; mdl1 = mdl1->Next; if ( mdlFlags & (MDL_PARTIAL_HAS_BEEN_MAPPED | MDL_PAGES_LOCKED) ) { MmUnlockPages(mdlCurrent); } IoFreeMdl(mdlCurrent); } while ( mdl1 ); *(_DWORD *)(Length + 4) = 0; }A MDL is a kernel structure that simply describes some memory (http://msdn.microsoft.com/en-us/library/windows/hardware/ff554414(v=vs.85).aspx).
The MDL variables:
- mdl1: 0xfffffa83`03aa41e0 (invalid memory pointer)
- mdl2: 0xfffffa83`03c3d1e0
3: kd> dt nt!_MDL fffffa83`03c3d1e0 +0x000 Next : (null) +0x008 Size : 0n568 +0x00a MdlFlags : 0n4 +0x00c AllocationProcessorNumber : 0xf980 +0x00e Reserved : 0xffff +0x010 Process : (null) +0x018 MappedSystemVa : 0xfffffa83`03bfd000 Void +0x020 StartVa : 0xfffffa83`03bfd000 Void +0x028 ByteCount : 0x40150 +0x02c ByteOffset : 0
The crash occurs at the point when the function tries to access the MdlFlags member of mdl1 (mdl1->MdlFlags). Since mdl1 points to an invalid memory address, we can't read the flags in.
The assembly instructions look like this:
srv2!Smb2ContinueUncachedRead+0x26c28: fffff880`0556e328 410fb644240a movzx eax,byte ptr [r12+0Ah] fffff880`0556e32e a804 test al,4 fffff880`0556e330 0f853294fdff jne srv2!Smb2ContinueUncachedRead+0x68 (fffff880`05547768)
r12 is mdl1, and we crash when trying to read in the flags.
The connection to Fast I/O
In every single crash dump that I've seen, the crash always occurs after a successful (non-waiting) Fast I/O read. In fact, the function that calls the crashing function (srv2!Smb2ExecuteRead+0x6ce) has an explicit condition to test for this.
Where did mdl1 go?
So the question is, why is mdl1 invalid? Did it exist before and was freed, or was there some kind of memory corruption?
Here are my observations on this:
- In every dump that I've seen, the addresses look right. What I mean by that is that the seemingly invalid mdl1 address falls roughly into the same address range as mdl2. It always starts correctly and always ends with 1e0.
If this crash was due to faulty RAM, then I would expect to see this address fluctuate wildly.
- The crash always occurs in the same place (plus or minus a few lines of code).
To me, this indicates that there is a bug somewhere.
Based on these observations I'm assuming that the mdl1 address in indeed valid, and so it must have been previously freed.
But who freed it?
We can answer that with a simple verifier query:
3: kd> !verifier 0x80 fffffa8303aa41e0 Log of recent kernel pool Allocate and Free operations: There are up to 0x10000 entries in the log. Parsing 0x0000000000010000 log entries, searching for address 0xfffffa8303aa41e0. ====================================================================== Pool block fffffa83`03aa3000, Size 00000000000018e0, Thread fffff80065566880 fffff80065864a32 nt!VfFreePoolNotification+0x4a fffff80065486992 nt!ExFreePool+0x8a0 fffff80065855597 nt!VerifierExFreePoolWithTag+0x47 fffff880013b32bf vmbkmcl!VmbChannelPacketComplete+0x1df fffff88003f91997 netvsc63!NvscMicroportCompleteMessage+0x67 fffff88003f916a3 netvsc63!ReceivePacketMessage+0x1e3 fffff88003f913ff netvsc63!NvscKmclProcessPacket+0x23f fffff880013b2844 vmbkmcl!InpProcessQueue+0x164 fffff880013b402f vmbkmcl!InpFillAndProcessQueue+0x6f fffff880013b7cb6 vmbkmcl! ?? ::FNODOBFM::`string'+0xb16 fffff880014790d7 vmbus!ChildInterruptDpc+0xc7 fffff80065296ca1 nt!KiExecuteAllDpcs+0x191 fffff800652968e0 nt!KiRetireDpcList+0xd0 ====================================================================== Pool block fffffa8303aa3000, Size 00000000000018d0, Thread fffff80065566880 fffff80065855a5d nt!VeAllocatePoolWithTagPriority+0x2d1 fffff88001058665 VerifierExt!ExAllocatePoolWithTagPriority_internal_wrapper+0x49 fffff80065855f02 nt!VerifierExAllocatePoolEx+0x2a fffff880013b2681 vmbkmcl!InpFillQueue+0x641 fffff880013b4004 vmbkmcl!InpFillAndProcessQueue+0x44 fffff880013b7cb6 vmbkmcl! ?? ::FNODOBFM::`string'+0xb16 fffff880014790d7 vmbus!ChildInterruptDpc+0xc7 fffff80065296ca1 nt!KiExecuteAllDpcs+0x191 fffff800652968e0 nt!KiRetireDpcList+0xd0 fffff800652979ba nt!KiIdleLoop+0x5a ======================================================================
The memory has been originally allocated by vmbkmcl.sys, and has already been freed at the point of the crash.
Googling, I found that vmbkmcl.sys is a "Hyper-V VMBus KMCL", and netvsc63.sys is the "Virtual NDIS6.3 Miniport".
File times
Here are the file times of the drivers that are involved in this complicated interaction.
3: kd> lmvm srv2 start end module name fffff880`054ff000 fffff880`055a0000 srv2 (private pdb symbols) c:\symbols\srv2.pdb\B796522F4D804083998D25552950C4202\srv2.pdb Loaded symbol image file: srv2.sys Image path: \SystemRoot\System32\DRIVERS\srv2.sys Image name: srv2.sys Timestamp: Mon Apr 08 22:33:02 2013 (51637DDE) CheckSum: 000A6B64 ImageSize: 000A1000 Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4 3: kd> lmvm vmbkmcl start end module name fffff880`013b0000 fffff880`013c6000 vmbkmcl (pdb symbols) c:\symbols\vmbkmcl.pdb\82188957E5784EDD91906B760767302E1\vmbkmcl.pdb Loaded symbol image file: vmbkmcl.sys Image path: \SystemRoot\System32\drivers\vmbkmcl.sys Image name: vmbkmcl.sys Timestamp: Wed Jul 25 22:28:33 2012 (5010AB51) CheckSum: 000250C9 ImageSize: 00016000 Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4 3: kd> lmvm netvsc63 start end module name fffff880`03f90000 fffff880`03faa000 netvsc63 (private pdb symbols) c:\symbols\netvsc63.pdb\BD38B199A4C94771860A5F2390CC30E61\netvsc63.pdb Loaded symbol image file: netvsc63.sys Image path: netvsc63.sys Image name: netvsc63.sys Timestamp: Sat Feb 02 02:23:05 2013 (510CBED9) CheckSum: 0001B2D9 ImageSize: 0001A000 Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4Possible sequence of events
In short, it seems to me that:
- Some memory was allocated to process a network request.
- That memory was passed to srv2.sys, which is processing that request.
- The original driver has decided that the memory is no longer needed and freed the memory.
- srv2.sys is ignorantly trying to access the now freed memory.
Workarounds
As a potential workaround, turning off Fast I/O should prevent the code that is causing the problem from running.
DrivePool 2.0 doesn't yet contain a setting for this but I'll add it in the next build. Turning on Network I/O Boost should also prevent the problem because we do some extra processing on networked read requests when that is enabled, which bypasses Fast I/O.
Connection to DrivePool
I'm still trying to find a connection to DrivePool in all of this, but I can't. I still can't reproduce this crash on any of the test servers here (4 of them running the windows 8 kernel), nor can I reproduce this on any of my VMs (using VirtualBox).
Fast I/O doesn't deal with MDLs at all, so DrivePool never sees any of the variables that I've talked about here. The Fast I/O code in CoveFS is fairly short and easy to check.
Because of the potential Hyper-V connection shown above, I'll try to test for this on a Hyper-V VM.
As far as what DrivePool was doing right before the crash, I can see from the in-memory logs that it has just completed a Fast I/O read request and has successfully read in 262,144 bytes.
Because I don't have a definitive reproducible case, I can't be 100% certain as to what the issue is. I'll keep digging and will let you guys know if I find anything else.
-
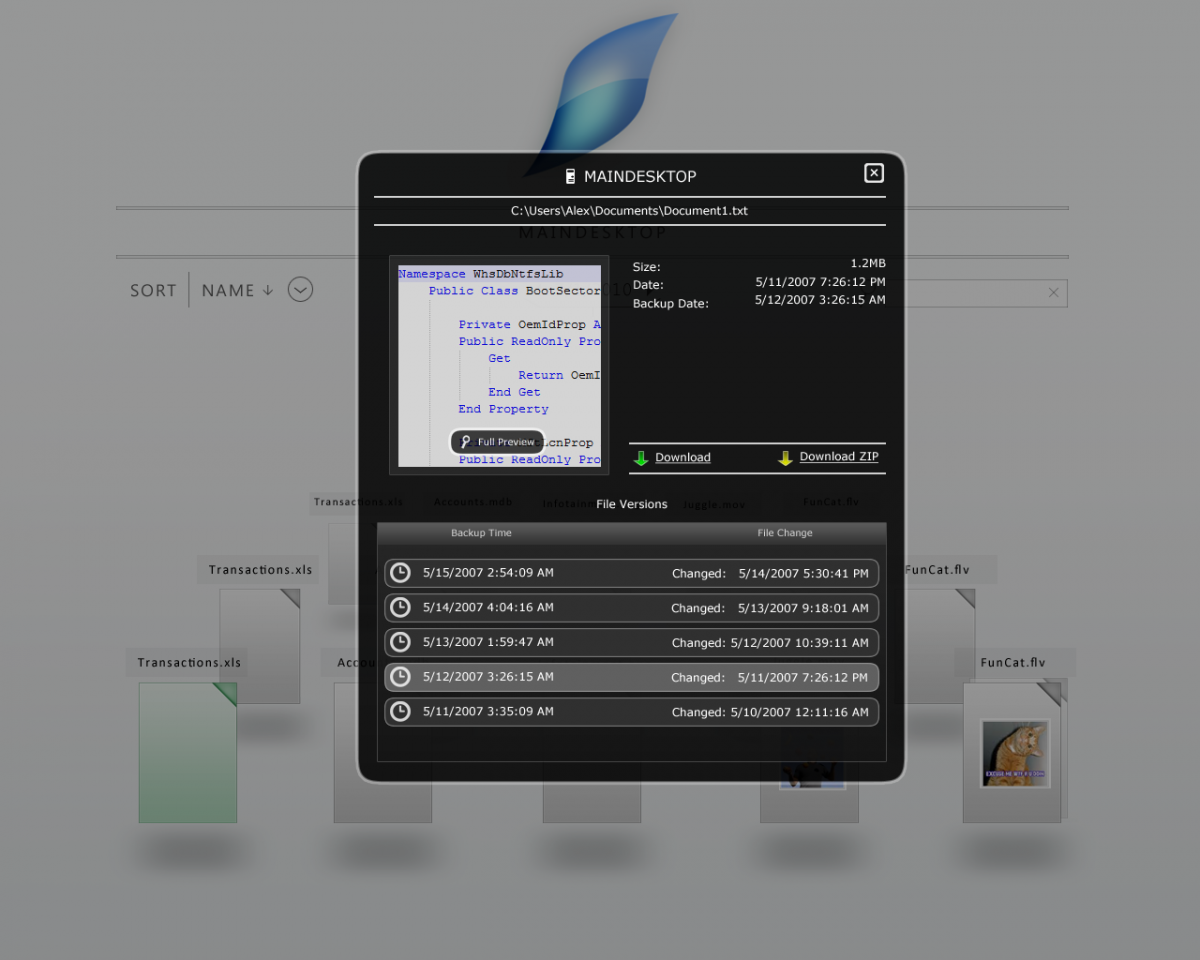
Since this has been a point of discussion on the old forum, I thought that I'd start this forum category by posting about per-folder file duplication in StableBit DrivePool.
Unlike the blog posts, I'll try to keep this brief (and somewhat technical).
File Duplication
What is file duplication?
Simply put, file duplication protects your files by storing 2 copies of a file on 2 separate hard drives. In case one fails, the other will have a copy of all of your duplicated files.
Designing File Duplication
The #1 priority for file duplication was to make the technology behind it as simple as possible, thus avoiding any unnecessary complications (and bugs). The first approach that DrivePool took was to put the duplication count in the folder name itself (you can't get any simpler than that).
For example, "Pictures.2" would duplicate all of your pictures to 2 hard drives.
This was very straightforward but unfortunately didn't work very well with shared folders. The name of a shared folder (as seen on the network) is typically the name of the folder itself, so it doesn't make sense to include the duplication count in the shared folder name. And more importantly, WHS 2011 didn't work well with this scheme.
(DrivePol 1.0 BETA M3 did try to work around the issues with folder links, but that was eventually replaced with a better and simpler system).
Alternate Data Streams
DrivePool 1.0 final shipped with the ability to store "tags" on folders. Although the tags are nothing more than alternate data streams on directories, I still like the word "tags" to describe the approach, because these "tags" describe something about a directory.
One of these tags eventually became a "DuplicationCount".
At first, the idea was to store the actual number of copies in the tag. So if a folder is designated as duplicated it would contain "2" in the duplication tag. But because we needed to enable folder duplication at any level in a directory tree, it was necessary to implement something that's a bit more flexible.
The current system supports an "Inherit" and a "Multiple" flag in addition to an explicit duplication count, and supports setting a duplication count on any arbitrary folder on the pool.
Complications
The new tag based system is not without complications.
We have issues with the read-only attribute on directories (which came up recently). And what happens if you move a duplicated folder to a location that's not duplicated? Well, we're handling all of these cases for you in a (hopefully) intelligent manner.
DrivePool 2.0
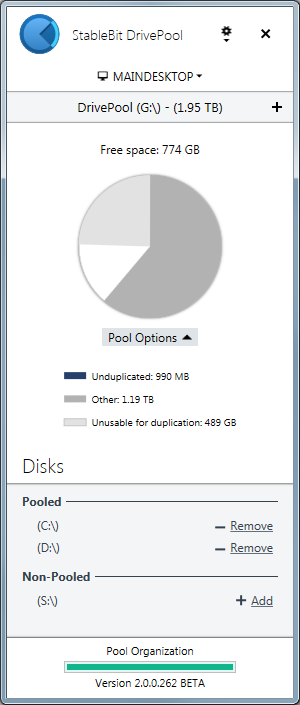
I've considered scrapping per-folder duplication in DrivePool 2.0. The reason is because you can create duplicated pools and non duplicated pools, and I feel that this is sufficient flexibility for most people. If we got rid of per-folder duplication it would make a lot of thing much simpler (such as balancing).
Feedback
What do you think of per-folder duplication?
Let me know. I'm listening.
-
Yep, or just use Quick Settings, which will set up the time for you.
-
Honestly, I really do like the clear, concise nature of the 2.x user interface. It doesn't feel cluttered or way too busy. But it still manages to provide enough info to be useful.
The stylistic inspiration for DrivePool 2.X came from Windows 8, and some mockups that I did for a potential cloud backup solution for the Windows Home Server years ago (way before Metro). This product was meant to follow up the StableBit Scanner, but MS decided to kill drive extender and so we have StableBit DrivePool instead.
The functional inspiration came from programs like ICQ (the first IM client), Hamachi (before they got bought by logmein) and Skype.
Here's a mock up of the potential OmniBackup web interface:
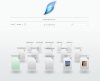
And the file details:
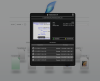
The mockups are rough and not finished, but you can already kind of see the "Metro" style in this design. I did this before I ever saw MS's metro.
-
Just throwing my two cents in here. I agree that the little arrow to manage duplication is very hard to find. I actually spent an hour trying to figure out where the settings were until I finally gave in and searched google and it brought me to this post. I think it needs to be labeled a little better. (Please and thank you!)
To be honest, I wasn't 100% comfortable with the arrow not having any text next to it, but I doubt that any designer ever is 100% satisfied with their design. You always want to keep tweaking it to make it perfect, but there are time constraints (plus, we can't exactly afford Johny Ive here).
I decided to ship it and listen for feedback, and based on that feedback I've slightly modified the pool options menu.
It looks like this now:
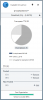
Let me know what you think.
-
Well, DrivePool is really tested to be strictly compatible with NTFS.
In theory, DrivePool should be able to work with any file system, but in practice you really need to test very thoroughly against any new file system or else bugs will crop up (and you can think of network shares as different file systems).
But...
I am thinking about networked pools, and I believe that we can solve this problem with a different approach and a new product which is in the works.
-
Ok. Great.
As far as which disk, the error reports don't show. Everything about the disk was coming up blank from VDS.
-
I've done some more testing with the SiL based cards and have posted a updated builds (2914 / 2915 BETA), along with some other fixes and features.
Download:
http://stablebit.com/Scanner/Download
These builds will use the VID hardware identifier of the controller and the driver name in order to decide when to apply the SiL workaround. The VID that I've put in is 1095.
-
Ok, thanks for posting that.
I'll take a look at why that is.
That on-board controller is not using a Silicon Image chip, is it?
-
Looks like one of your disks is not reporting any name at all.
I've posted a new build for you to try in the support request that you've opened. Let me know.
-
@weezywee
Very cool.
That APC box looks familiar (I think).
I have a APC UPS that I've hacked to use 4x deep cycle marine batteries to provide 3 to 4 hours backup for my entire office (instead of the built in Li-Ion which would only last 15 min.).
- Christopher (Drashna), Shane and johnnymc
-
 2
2
-
 1
1
-
Migrated from WHS2011 to WS2012E the other day and that required upgrading SB DP from the 1.x version to the 2.x BETA version. With all due respect, I really don't like the new Metro (?) UI. It isn't as informative and it seems to be lacking a lot of 1.x functionality.
I didn't realize it for a while that my server storage requirements were so low, and it took a while for me to figure out that duplication was off. Then it took even longer to figure out where the duplication setting is. And then I was confronted with file or folder duplication, and nothing in the FAQ seems to address this.
I understand the concept of BETA - I hope 2.x evolves to resemble 1.x
Thanks for your feedback, I'm definitely listening.
While strictly speaking this is not a "Metro UI", I agree, it is similar.
I thinks that one of the major problems with Metro is discoverability, it is nearly non-existent. If you're not familiar with it then you don't know what to click and where. Other than that, it's pretty neat.
So I'll try to add more "discoverability" to DrivePool to make it easier to use.
-
Can we see some pictures

-
Ok, I've put in a fix and it looks like it's working over here.
Try this build and let me know if that fixes the S/N problem.
Download:
- Windows: http://dl.covecube.com/ScannerWindows/beta/download/StableBit.Scanner_2.4.0.2911_BETA.exe
- WHS 2011: http://dl.covecube.com/ScannerWhs2/beta/download/StableBit.Scanner_2.4.0.2912_BETA.wssx
It may take a few minutes for the new S/N data to funnel down to DrivePool.
-
This is actually a very interesting issue.
According to the testing that I've been doing with the SiL3132 (3.0 Gb/s SATA II) card, it seems like the Si drivers do not respond properly to the Disk IDENTIFY and the SMART querying command that we're using. I bet this is what you're seeing.
The StableBit Scanner tries multiple ways of communicating with the disk and the only one that goes through on some of these Si controllers is what's called the SMART_RCV_DRIVE_DATA (http://msdn.microsoft.com/en-us/library/windows/hardware/ff566204(v=vs.85).aspx).
Unfortunately, the controller driver seems to only be able to query the drive connected to the first port, regardless of where we're sending the command.
This means that all the drives connected to a single Si controller will identify as the same drive. I've also verified this with other software that uses SMART_RCV_DRIVE_DATA, and it too is seeing the same problem, so it doesn't look like we're doing anything wrong on this end.
I think this is the problem that you're seeing.
Now the question is, why was this working before?
I've setup a test rig with a few Si3132 cards and have just discovered that WMI and the very basic storage device descriptor (which both provide far less detailed data about the drive) actually return the correct model / serial number for drives on those cards.
So the answer is to somehow detect this condition and avoid using the invalid IDENTIFY and SMART data, when dealing with these broken Si drivers.
I'm working on this right now and a fix should be out in the next build of the StableBit Scanner.
-
Yeah, unfortunately this is a restriction of build 260. I'm pretty sure that we can fix this in a future build.
The file performance UI uses the PhysicalDisk performance counters to get the disk activity time, and it expects to find a drive letter in the instance name. But there's no reason why it has to look for the drive letter.
BSOD in srv2.sys on Windows 8 / 2012
in General
Posted
Ok, here are new builds that have Fast I/O reads disabled on the Windows 8 kernel:
This should prevent this crash from occurring while I keep investigating.
Thanks everyone for helping out and being patient with this issue.
Changes
2.0.0.263 --------- * [D] Disabled Fast I/O network reads on Windows 8 / 2012 as a workaround for a system crash. * Added "Pool options" text to the pool options button. * [D] When moving a directory with an explicit per-folder duplication (or that has sub-directories with explicit per-folder duplication counts set) to a new folder on the same pool, make sure to correctly re-propagate the M/I flags. * [D] Deleting a directory that had per-folder duplication enabled, and then recreating a new directory with the same name would incorrectly mark the new folder as duplicated as well (usually until a reboot). * [D] Fixed setting per-folder duplication on read-only folder (or folders whose parents may be read-only).