


beatle
-
Posts
21 -
Joined
-
Last visited
beatle's Achievements
Member (2/3)
1
Reputation
-
 beatle reacted to an answer to a question:
SMART info not available - any other advanced options?
beatle reacted to an answer to a question:
SMART info not available - any other advanced options?
-
Ahh, I did not know that. I'll keep that in mind when shopping for drives though. Is this a feature on the roadmap or a permanent limitation with how Scanner works?
-
I just popped a new drive into my R720XD, a SAS 14TB from MDD. It started scanning right away and the drive seems healthy, but I'm unable to pull any SMART info from it. I looked through the wiki and found a few options in advanced settings that I've tried: IgnoreSignature Unsafe NoWmi I restarted the Scanner service after enabling each one of these, but the drive still won't pick up SMART info. Thinking it might be the drive, I tried out HD Sentinel which has no problem reading the SMART info. Are there any other things to try? I've had dozens of drives through the years but this is the first one to have this issue.
-
This pool is mostly used as a Steam library, and anything not Steam related is already backed up. Would not be a problem to redownload the library, just kind of a pain. Chkdsk /scan /v doesn't work on the pool drive since it's considered raw, but no errors were found on either of the underlying drives.
-
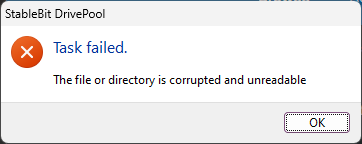
Tried moving files to a newly created folder and setting duplication on the new folder. Same error. I can't even set folder level duplication on an empty, newly created folder.
-
I'm attempting to make some changes on my pool on a Win11 machine (two NVMe partitions, separate drives) and I'm running into this error every time I try to enable or disable duplication on a folder. The pool seems to be behaving itself and duplicating data in folders where I have it set, but I am not sure why I am getting this error. All the underlying drives are healthy, I've rebooted, disabled Windows antivirus, disabled read striping, and disabled realtime duplication. Not sure what the problem is.
-
Maybe it works now, but my trial expired last week. What a shame.
-
Well, I haven't tried it with Amazon S3, just iDrive. I basically gave up on this.
-
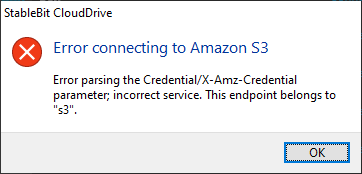
I'm trying to create a new drive and connect it to an iDrive e2 bucket. I started by creating an access key on iDrive, and then went into CloudDrive and created new Amazon S3 drive, then selected "Use Amazon S3 compatible third party service" and punched in the keys and service URL. Had to add https:// to the front of the service URL that iDrive provided. Hit Save and was greeted with this message: Not sure what this means, but it's like it's expecting this to be for Amazon and not a third party provider that uses S3. I found this reference to making some changes in a json file to get it to work, but I think it might be outdated since it's over 2 years old: https://stablebit.com/Admin/IssueAnalysis/28540
-
Right, as I mentioned I would be a touch short. Though with everything duplicated I wouldn't lose data if a drive fails; I just wouldn't be able to automatically recover from hazcon state of having some of my data on only one drive. I think of this like running RAID 5 without a hot spare. If I lose a drive from a RAID 5 group, the data is still there and accessible by calculating the block using parity data, but the rebuild to full redundancy won't be able to occur automatically - a spare drive would have to be installed. With Drivepool the data at risk before a full duplication would be whatever the remaining disks couldn't duplicate from the failed drive. To save a few bucks on electricity I am leaning towards having a few cool spares in drive caddies that I could pop into the box while a full size spare is sourced.
-
I currently have 7 drives in my pool (3, 5, 8, 8, 8, 14, 14) and I have just shy of 12TB free. My most full drive (a 14TB) has 8.26TB of data on it, so if it were to crash, the other drives would need to pick up the duplication slack, so I think I could be just a touch short if I lose a big drive. Of course I wouldn't lose data, but I'd need another drive pronto to get out of hazcon state. How full does everyone else let their pools get?
-
Try this: https://winaero.com/blog/hide-drive-windows-10-file-explorer/
-
I use DrivePool for my servers and love it, but performance there isn't that important. On my desktop, I want the fastest performance possible, though I would also like better use of my two 500GB SSDs. I'd like to shave off my OS into a separate partition and then pool the remaining space with the other drive. I'd then install my software, VMs, etc. on the pool. No need for duplication here, all my important stuff goes on my server. I suppose I could test this myself, but I'm sure I'm not the first person to do this. Is there a penalty to this configuration? If so, how much?
-
Thanks, I figured that might be the case. No big deal. I use SnapRAID for protection, so no duplication in my pool. Now, what's the best way for me to remove the drive from the pool without rehydrating all of the data? I'd like to just keep the contents of this drive as they are and just remove it from the pool. I'm thinking I should just power down, pull it out, then remove the drive from Drivepool when the server reboots. I can then move the files out of the "poolpart" folder and back into root of that drive.
-
I might have a niche case here, but maybe others would benefit as well. I run Server 2016 with deduplication on one of my volumes. All of my backup jobs go there, and I get pretty good deduplication savings from all of the fulls and diffs. For ease of management, this drive is a part of my pool. I also run Scanner, and I know it will evacuate a drive if it detects SMART errors (a great feature). However, in this case if I try to move all of my backups off the deduplicated volume, it will need to rehydrate them all. Due to the savings, I'll need an extra TB to place them all elsewhere in the pooled drives. I'd like to be able to exclude this drive from this particular plugin. If I lose my backups due to a SMART error, no big deal. I guess I could also exclude the drive from the pool altogether and just run my backups to a separate drive... but I figured I'd ask if this were already possible with Drivepool.
-
I have a couple of the popular 8TB WD external drives pooled together as the offline backup for my NAS. I bring them on every few weeks to sync my NAS data to them, so they're off most of the time. With that in mind, they're never scanned by Scanner. In addition, whenever a scan actually starts, they overheat and throttle the drive anyway. I decided to put them "through the wringer" and cool them with a fan so I could complete a scan and see how they do. Unfortunately, after a few hours, the scan will restart on a drive and start over at 0%. At an average read speed of ~130MB/sec, one will take ~18 hours to scan. Any idea why the drive resets? It doesn't seem to drop off or lose USB connectivity.