


eujanro
-
Posts
12 -
Joined
-
Last visited
-
Days Won
1
Posts posted by eujanro
-
-
Only my 2 cents here, I'm using DrivePool over 10 years and never had any issues as reported here.
In my case, there are two geographically different located systems that are kept in sync state (NTFS formatted HDD/SSD's, 80TB+), using Syncthing app. Nevertheless, Syncthing has it's own internal mechanism for the files sync mechanism, using a self "index-*.db" of all the hashed files/folders, using SHA-256 algorithm. Some folders in my Syntching configuration, have also the "fsWatcherEnabled" option, that "detects changes to files in the folder and scans them" automatically, and this is also working flawlessly, never had any issues with.
Still, I have very rarely discovered some hashing warnings (eg "File changed during hashing..") especially with new files, but the warnings disappeared after a second re-hash/scan of files/folders.
Should I assume that if such issues were critically problematic between the DrivePools, I should have seen reports of Syncthing struggling to keep the files in a clean synced state? -
UPDATE:
With Server 2016 everything is working as expected, so I think the issue is with the Server 2022 itself.Also there seems to be issues reports, with the Adaptec 72405/71605 card Windows driver on the Server 2022:
Bug in Adaptec ASR-72405 driver for Windows 11/Server 2022 | Born's Tech and Windows World (borncity.com) -
Hi Doug,
Thank you for your answer. I was using the Adaptec 72405 with Server 2016 Essentials and has worked flawlessly.
Now I have tried the "Adaptec RAID Driver v7.5.0.52013 for Windows, Microsoft Certified" dated Aug 2017, from the Microsemi site, but this also was provided by the Operating System. It didn't work either. I think it has do to with the Server 2022 or something. My Scanner settings are nothing but the default one, aside the Unsafe and NoWMI option which I manually checked, to see if bring something to my issue in question. But nothing is working.
In the end, I think it's a Server 2022 issue, because under Server 2016, the same controller and disks, worked without issues.I will try further with the same Stablebit Drivepool/Scanner version, that was on the Server 2016 (same Adaptec RAID Driver v7.5.0.52013 also) installed, but I don't think it will change something
-
Tried also the "Advanced Settings > Direct I/O > Unsafe" checked, together with the "NoWmi" option for Smart section.
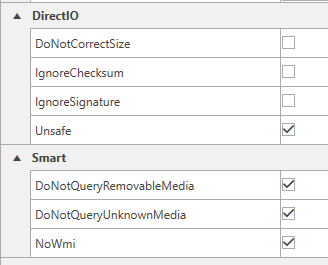
But it didn't help!
Anyone with further ideas? -
Hi everyone,
Using Server 2022 Standard with Stablebit Scanner v2.6.2.392 with a controller card Adaptec 72405 (HBA Mode), I'm missing the Temperature, Performance, DiskQueue, DiskActivity infos.
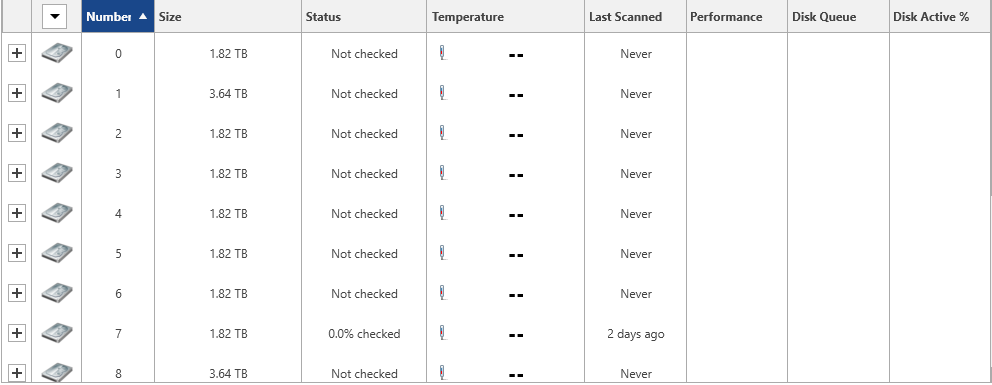
Is there a incompatibility between Server 2022 or the Adaptec card, with the Stablebit software.
Best regards
-
[Update 2]
After adding a 16TB new HDD, the Balancing rules have wonderfull worked, and the replacement rules have been respected.
I had to really further set exclusions file placement rule for other non /MUSIC /PICTURE root structure directories also. It's really wonderfull how this is working. A real state of the art software.
In summary, it was the over 90% usage of other pooled hard drives that forced an Overflow of data, to the SSD.
-
On 5/17/2022 at 5:03 AM, gtaus said:
I have found that DrivePool balancing and duplication often have problems when I hit that 90% threshold. I have seen my SSD cache get kicked offline as well. Fortunately, adding more HDD storage and/or removing unused files corrects the problems on my system. I have to manually recheck my SSD to tell DrivePool that it should be used as an SSD cache and not an archive disk. But it seems to work again without any problems.
If you are happy with your current custom SSD cache settings, I would write them down because it seems to me that I had reenter my settings. After many months of not looking at DrivePool (it just works), I had forgotten my custom SSD cache settings and had to play around with it again until I got it back to where it works best for my system. If you use the default settings, then it might not be an issue.
Actually I'm not using the SSD's as "cache" on my configuration. Their are just (faster) storage devices in my pool, an therefore I just wan't them to hold only data that must be delivered as quickly as technically possible.
In my case, the Plex Photo library just skyrocketed in responsiveness and browsing speed, by delivering the content, from where it is stored, the SSD drives, no matter of inside or out of my home network. Couch-time family photos browsing is a delight now.
SSD caching works great and make a difference indeed when direct file level access/delivery on the network is required. But that's not my model usage for now.
-
Total Commander is allowing you to search on the Pool itself or on the drives (letter or mountpoints). You can also Save the searches as templates, and use them quickly later.
Is also supporting attributes, Text, conditions, time based attributes, Regex ...
It's a shareware application, and if your bothered by the startup message, you could register it.
-
[Update]
I think I have identify the reason behind the file placement rule violation (overflowing).
It seems that all other HDD's total used space is 90% filled or more, and the default Pool Overflow rule is permitting this:

I will add another 8TB to the pool, rebalance, and will check afterwards, if the disk total used space will drop under 90%, the SSD data will also be properly rebalanced.
-
Hi covecube,
Using Windows 10 Pro, DP 2.3.1.1410 BETA, Scanner 2.6.2.3869 BETA
One Pool under letter B:\ with over 40TB size
Long time user of Covecube solutions, just wanted to optimize speed for certain files, by using two SSD for \PICTURES and \MUSIC folders.
For that, I just added the two SSD drives into the Pool and configure a "File Placement" rule using "File Placement Option" to USE only the 2 drives for mentioned folders.
Looking on the SSD's root GUID PoolPart directory and lo-and-behold, other files\Folders (eg. BACKUP, MOVIES, ...) landed there, and no matter I do, they love to stay on the expensive NAND. The \PICTURES Folder is 2x Duplicated (around 900GB including duplication usage) and the \MUSIC is 770GB not duplicated. The SSD are reporting 1.31TB and 932GB free.
Everything under "Balancers" Plugins, is set to Default and active are the: Stable Bit Scanner, Volume Equalization, Drive Usage Limiter, Prevent Drive Overfill, Duplication Space Optimizer
The follwing are "Disabled": Disk Space Equalizer, SSD Optimizer, Ordered File Placement Rules.
Why are the "File Placement Rules" not working ?!?
-
Hi everyone,
First, I would like to share that I am very satisfied with DP&Scanner. This IS a "State of the art" software.
Second, I have personally experienced 4 HDD drives fail, burned by the PSU,(99% data was professionally $$$$ recovered) and a content information, would have been comfortable, just to rapid compare and have a status overview.
I also asked myself, how to catalog the pooled drives content, logging/versioning, just to know, if a pooled drive will die, if professional recovery make sense (again), but also, to check the duplication algorithm is working as advertised.
Being a fan of "as simple as it get's", I have found a simple free File lister, command line capable.
https://www.jam-software.com/filelist/
I have build up a .cmd file to export Drive letter (eg: %Drive_letter_%Label%_YYYYMMDDSS.txt), for each pooled drives. Then I scheduled a job to run every 3hours, and before running, just pack all previous .txt's into an archive, for versioning purposes.
I get for each 10*2TB, 60% filled pooled HDD's, around 15-20MB .txt file (with excluding content filter option) in ~20minute time. An zipped archive, with all files inside, is getting 20MB per archive. For checking, I just use Notepad++ "Find in Files" function, point down to the desired .txt's folder path, and I get what I'm looking for, on each file per drive.
I would love to see such options for finding the file on each drive, built up in DP interface.
Hopefully good info, and not a long post.
Good luck!



Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
in General
Posted
Some are uni-directional an some are bi-directional. But as I understand check-summing is deterministic by input in the end. So, I suppose a SHA-256 in Syncthing is expected to be same globally and therefore is atomically the same on both sides. And as per the Syncthing documentation "There are two methods how Syncthing detects changes: By regular full scans and by notifications received from the filesystem (“watcher”)" and in my case full scan of ALL (80TB+) data is taking place around each 24h timeframe.
Moreover, I'm using the versioning option for each of the synced critical directories. This means that if change has been detecting by reading the file the, updated file will be moved to .stversion folder, inside of the root synced directory in question. But beside self modified data, I have never found in the last 5 years, massive corrupted data that has been "corrupted" and propagated, and therefore moved in the .stversion folder, because let's say has been "changed/corrupted" silently on source and then replicated on target, and thus deleting the "good" file presumably.
Meantime, I have executed your watcher.ps1 script, and I confirm that "change" operation is reported indeed on files when opened. But in my case there is a "catch": i'm doing 95% percent of file level operations using Total Commander, and surprisingly opening/managing the same file, through TC on watcher.ps1 monitored path, does NOT report any change using TC! Only Windows Explorer is reporting it changed. So could it be that by using TC exclusively, I avoided the issue/bug amplification. Now is the question if Windows Explorer has issues or DP, or both...
It is in the end still concerning and disturbing having trust issues and doubts in this case, and everything should be treated and expected by @Alex as soon as possible.