


zeroibis
-
Posts
61 -
Joined
-
Last visited
-
Days Won
3
Everything posted by zeroibis
-
New Pool: Duplicate before adding data or after?
zeroibis replied to cocksy_boy's question in General
I run quite a few VMs and generally best practice is that you want one VM drive that stores your OS and additional ones to store your files. In this way it is simple to spin up another VM of your OS and load your files over there. If you are not already doing so I would highly recommend splitting your OS vms from your data storage vm files. The risk with a VM lies in data corruption. In a normal system data corruption may cause a file to be lost. In a VM system file corruption may cause the VM which contains everything to be lost. This is a major risk and is why they are generally used on ZFS volumes and things like ECC ram are used. This is not to say you can not pace them on NTFS as the latest versions actually do a way better job of managing data corruption than in the past but this is where things like raid, snapraid and drivepool etc come in. These things are not just used to help mitigate risk from drive failure but from data corruption as well. -
Ah, I understand now that the best candidates are files such as virtual disks that literally contain duplicate files, makes sense. Thanks for the info!
-
Interesting, also thanks for updating with the solution you found. Is there any material you would recommend to read up on the deduplication service. It appears this is a great solution if you have a lot of files that are only accessed but not often modified, such as large sets of videos and photos. I would still imagine that there is a heavy processing and memory cost to this that my present system likely can not pay but it is something to read up on and look into for future upgrades.
-
Ah I understand and yes I had never heard of deduplication before and assumed it was a block level duplication service via storage spaces. I understand now that it is a form of compression. I would presume that the decompression would have a decent performance penalty but it sounds pretty great if you do not need a lot of read performance on old random files. So you have two disks each with deduplication and then both of these same disks added to the same drive pool with real time duplication enabled. I am guessing that MS has changed some APIs with regards to the way you access data from the volume that is effecting drivepools ability to maintain duplicates. A work around could be to temporarily real time duplication and instead have data flow to one drive and then to the second as an archive.
-
I am a bit confused as to what your I/O stack looks like, can you draw a little map in paint or something so we know what is going on? Also a bit confused as to why your using MS deduplication instead of the duplication from DrivePool. One of the main benefits of DrivePool is the duplication feature which eliminates problems such as the exact one your having.
-
New Pool: Duplicate before adding data or after?
zeroibis replied to cocksy_boy's question in General
You basically have the right idea. In essence all the files stored in the VMs virtual drive is in reality stored in a single vhdx/vmdk file which sits on whatever volume it is on. The issue this creates is that just like any single large file the vhdx/vmdk file can not exceed the size limit of the partition it is stored on. -
New Pool: Duplicate before adding data or after?
zeroibis replied to cocksy_boy's question in General
I think part of his problem was that he did not have any empty drives or only has a single drive that is currently empty. Yes copying to the x2 pool with real time duplication would be the fastest it would assume that he has already two blank drives which to my understanding he does not. If you do not have extra space you might need to do this task with duplication off and then after you clear the space by deleting the old VM files you can turn it back on. So you would need to setup the new machine running your ESXi VM without duplication, if your not going to have enough space, and then transfer the files over. Remember that as your VM's are individual files they can only rest on a single drive in a normal pool for example if you had 2x 2tb drives in a non-duplication pool you would have 4tb of free space but your vm can not exceed 2TB. This is different than a raid 0 array where your 2x 2tb drives would give you a 4tb limit for the size of your vm. Understanding this limitation is very important. When using drivepool no individual file (in your case the file that contains a VM drive) can never exceed the size of the physical disk it is placed on. You can get around this by mounting additional VM drives in your environment and splitting up the data. If you need vmdk files that individually exceed the size of your largest HDD then the only solution that is going to work for you is hardware or software based RAID. Note that you can take things like storage spaces and pool those. For example you could create two raid 0 arrays in storage spaces and then pool those to be a duplication pool. This makes recovery less complicated than a RAID 10 storage spaces implementation. Also keep in mind that duplication and RAID is NOT A BACKUP. Please ensure that you have backups before preceding. IF YOU DO NOT HAVE A BACKUP SOLUTION STOP NOW AND GET ONE. -
New Pool: Duplicate before adding data or after?
zeroibis replied to cocksy_boy's question in General
The data copy via duplication when you add a second drive to the pool is extremely fast. Nothing will transfer your data to a second drive faster than this method. Just be sure to enable duplication as soon as you add the second drive to the pool so that it will start copying the files rather than moving them to balance right away. Then you can also press the >> button so that it goes faster. From my own experience the transfer rates were very good and I was about to duplicate a few TB of data in half a day. -
I have ordered a second 970 EVO and a x1 gpu so I will have those in later this week. I will re-test with that installed and I will split up the drives between the two caches as so to avoid the double read/write penalty. I am hoping that by using the ssd that will be using the PCH PCI 2.0 x4 connection as the cache for the HDDs that are also on the same PCH it will avoid any bandwidth issues. My understanding is that the PCH to CPU connection is at 32Gb/s. The x4 slot is at 20Gb/s and I also assume my integrated 10Gb/s nick is on there as well. So even with them all saturated I should not run into a PCH bottleneck on that side if I am lucky. Not running over-provisioned but I will also look into the benefits of that as well. Note though that I was using only a 111GB partition for the tests.
-
Here are the test results. ssd to raid 0: ssd to raid 0 cache 8kb buffer 60: ssd to raid 0 cache 8kb normal 60: ssd to raid 0 cache 32kb normal 60: ssd to raid 0 cache 128kb normal 60: ssd to raid 0 cache 512kb normal 60: ssd to raid 0 mirror cache 8kb normal 60: ssd to raid 0 mirror cache 512kb normal 60: ssd to raid 0 mirror cache 512kb normal 300:
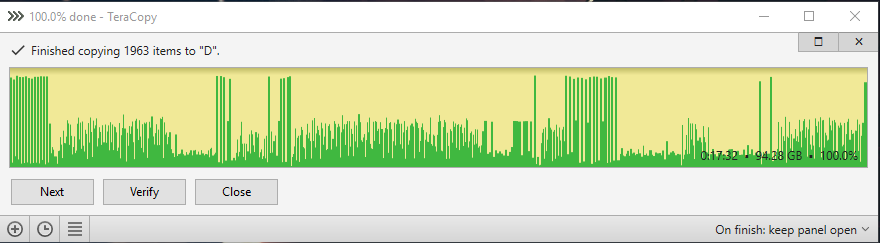
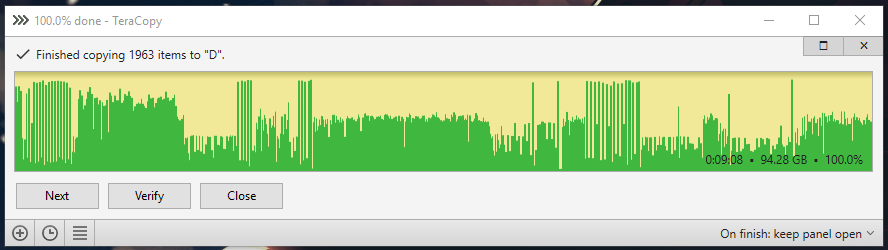
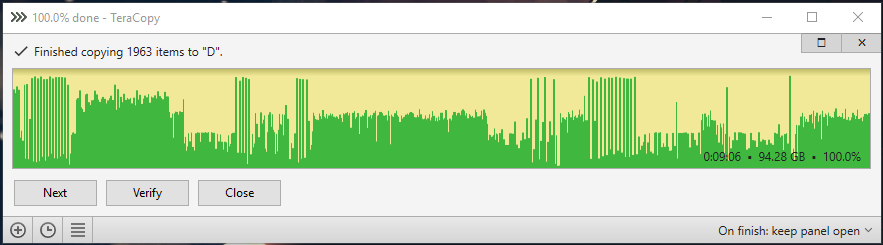
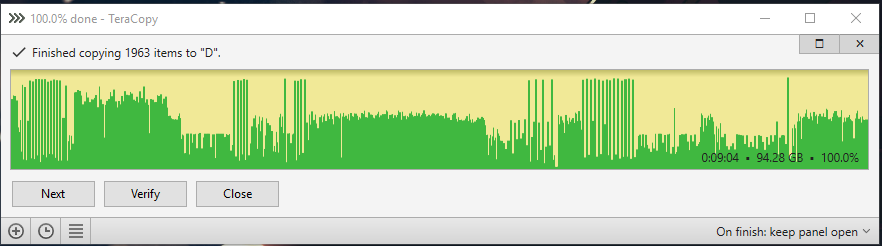
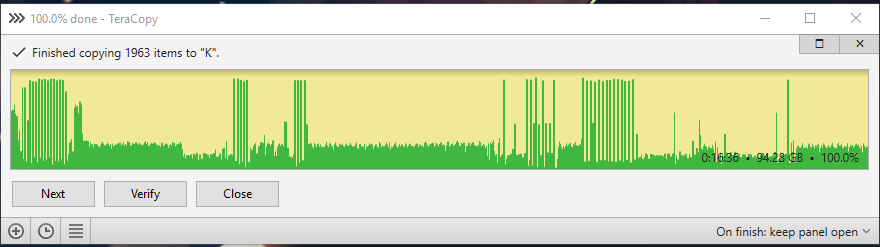
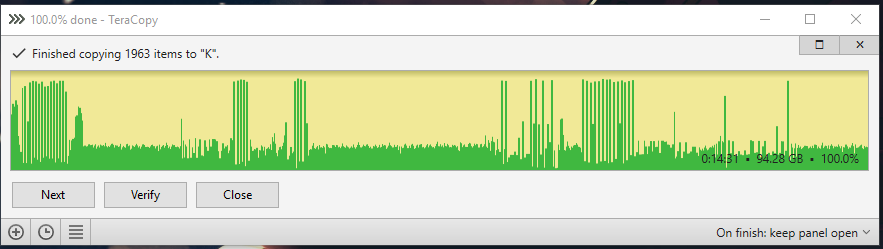
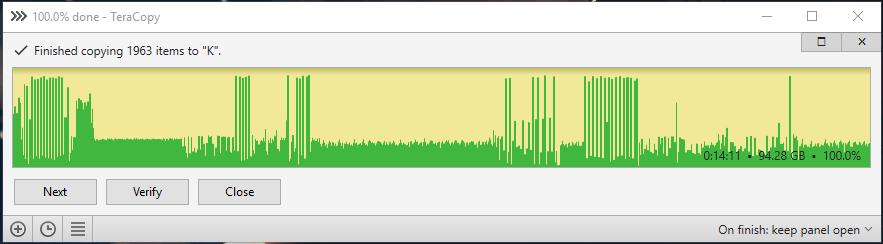
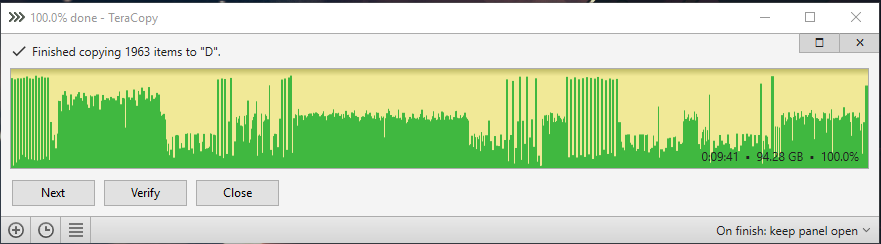
-
I think it could be that my real limiting factor is that I could be using a faster SSD, from what I can see the larger sizes do have faster to 2x the read/write speeds compared to the 250gb 970 evo. I have a 960 EVO 1TB that I could toss in there and run all the benchmarks again. I will try that later and see how it goes. In the mean time I have gotten it down to 14min transfer times (3min improvement over no cache) using 512k blocks.
-
Actually it looks like that may not be the case; however, I have started testing and using it on a single raid 0 it is great it takes a 17min transfer down to 9min. I also found that normal was the fastest and that the size had no real impact on transfer times. Unfortunately, the double W/R penalty of using a single cache on a mirrored raid 0 was a disaster. You had everything working against it. First doubling the W/R rate killed most of the performance benefit of the SSD and then the double space requirement finished it off in the end. I will be posting images later of the benchmarks. Using the write cache allowed for a speed improvement of 1min for a transfer time of 16min vs 17min without the cache. I do believe there is a workaround although the best case workaround can not be achieved on Ryzen Your going to need threadripper. However, I will still attempt this solution in the future as I am sure it is better than nothing. What you need is a minimum number of SSDs equal to the number of duplication sets in drivepool. So if your using 2x real time duplication you need a minimum of 2 SSDs. Then you set each one to independently handle a different set of underline drives so they never get hit with the double penalty. I am still running some other tests and will post up all the results when they are finished. If the SSD cache for drive pool could resolve 1 single issue then it would be the best method. That issue is the size limit that you can not transfer more data than the size of the ssd cache. If that could be fixed then it would blow primocache out of the water. Also you might wonder about the non real time duplication issue when using the drivepool duplication cache but I realized that you can get around that by adding an existing duplication pool with real time duplication instead of the underline drives and do it that way. Basically: Pool with SSD cach -> Pool with Duplication -> underline volumes.
-
I think I found where my issue was occurring, I am being bottle necked by the windows OS cache because I am running the OS off a SATA SSD. I need to move that over to part of the 970 EVO. I am going to attempt that OS reinstall move later and test again. Now the problem makes a lot more sense and is why the speeds looked great in benchmarks but did not manifest in real world file transfers.
-
Yea thanks for the info most files on the system are going to be 512MB-2GB. I will test with various block sizes. I am limited in how large the cache be with small blocks as I only have 8GB of total system ram to work with.
-
For the dynamic disks stuff: Yea that makes sense and I understand more why MS considers dynamic disks to be decrepit (as they stated with Win Server 2012 release). Also good point about all the volume options, I had forgotten about that possibility. For the scanner stuff: You have it show up as one unit like it does now as logically your going to scan the array and not the individual drive but you can just show data for each drive within that section. Think of how storage spaces itself displays the info you can see what drives are in the underline pool. You could even make it so there is just pages and you page though each drive you want to view data on. Honestly though, the data pages are not that important compared to the alerts themselves. As long as the scanner can tell me which of the underline drives is having a problem or if it is overheating etc that is super useful. It is not as though someone sits there all day looking at all the pages anyways. What they do care about is getting the various alerts and having as much detail about the source of the problem in the alert as possible. If you wanted to see the array and the part of the block display for each drive you could just make boxes to represent what part belongs to what drive assuming that info can be known.
-
The actual transfer speeds for file transfers when using the cache was rarely over 200MB/s. I was getting around the same speeds with the cache off as with on. Obviously it was a bit faster for the first few seconds. (This is for primocache). Now when benchmarking it would look like there was big differences but I virtually never saw those in real life. Here is an example config that I used: Block size: 16-512MB L1 Cache: 0-2GB Latency: 10-300 Write Mode: Native/Average (Moved the bar all the way to write and also tested with it off) Verified strategy was write only. I had an extremely high number of transfers going to multiple different volumes and background crc checks going on so it could be that I just had the system way overloaded as well. The CPU was thrashing into the 90%+ utilization. Once I finish moving everything over and get all my data settled I will do a much more in depth test of moving a sample directory around and time exactly how long it takes to transfer with different settings.
-
Tested with the SSD Cache plugin and yea it is a lot faster. Problem is that once the cache fills up your file transfer literally hits a brick wall and everything stops. What should happen is that once the cache fills up my transfer should bypass it and go to the underline dives directly. Hopefully when that issue is addressed in the future I can use the cache option but until then it is not worth it. After looking at primocache it is also not worth it as there is little to no speed benefit in the transfers. Now if the SSD was 2-4x faster it would be but we are not there yet.
-
My only use of the SSD cache is to improve write performance. I am going to be comparing the performance of PrimoCache to that of using the SSD cache from DrivePool as well. My main concern is that using the drivepool ssd write cache I can not enable real time file duplication unless I have two SSDs. Regardless, what I really want is basically a write buffer that fills up when needed and constantly empties itself. Hard part is figuring out the best way to achieve this. (using a 250GB 970 EVO)
-
Thanks for the info! One note about the issue with dynamic disks, why not just assume that the underline physical disks do not matter to the user insofar as file placement goes. For example if I am creating dynamic disks to have a raid 1/0/5 etc and then trying to place such a volume into drivepool I am saying that I want that entire volume to be treated as a singe disk (basically exactly how it works in storage spaces). Thus the duplication check does not need to be looking at the underline drives. I am sure it is actually a lot more complex than that and you are likely greatly simplifying the explanation so that we can understand it but just wanted to put up some food for thought. Interesting that the Scaner issue is actually UI related. I suppose this must be also why the UI looks different when viewing the smart data for the same drive when connected to a HBA vs the motherboard.
-
I am intending to use PrimoCache L2 write cache in combination with DrivePool. So far in testing it appears that for it to work I need to apply the cache to the underline drives that make up a given DrivePool. I wanted to verify that this is the correct implementation. My tests so far: Apply cache to the DrivePool volume = cache does not work Apply cache to each of the underline drives/volumes that make up the drive pool = cache works
-
Your random access might have been due to being over USB and the related overhead. In my testing I did not observe a change to random access performance.
-
The issue I had with Storage Spaces was not that it did not show up, it was that it did not achieve RAID 0 performance by default. I tested my speed with disk management raid 0 and got for example 368MB/s Write speeds. When I setup a Storage Space just like you I ended up with the performance of only a singe drive 18XMB/s. So I created it again using the CLI method so that I could define the Columns as 2. When I retested after this I once again had raid 0 like performance and was achieving 368MB/s writes.
-
Interesting that RAID 0 in Disk Management worked for you as I found here it explicitly is not supposed to work: " Dynamic Disks. Because of the added complexity of Dynamic disk, we don't support them being added to a pool. Specifically, we take into account the physical disk when determining where duplicates reside, and that adds a lot more complexity and overhead when you start dealing with Dynamic Disks due to the complex arrays that you can create with them." When you create a RAID 0 in Disk Management the disks become Dynamic and should not work. This is why I switched to using Storage Spaces. However if you create a normal pool in the Storage Spaces GUI it is not RAID 0 but instead just a pool of disks as the default value for -NumberOfColumns is 1 when using simple in the GUI. Thus the only way to use Storage Spaces for RAID 0 performance is to use the CLI so you can enter the correct settings in manually. Problem with using Storage Spaces is then the underline drives can not be accessed by Stablebit Scanner as referenced here: You can also see it listed as an official limitation: SMART Data from Storage Spaces array. Because of the low level implementation of Storage Spaces, the disks in the array are hidden from access normally. This makes getting information about the disk (including SMART data) significantly more difficult. We are looking into implementing this feature in the future, but there is no ETA. Now I will state that HWInfo is still able to see the disks when they are being used in Storage Spaces so hopefully it is not to hard to get working. It appears that both of these issues came up in the past but there was no Dev time to spare due to work being done on CloudDrive but now that it has released hopefully we will see some progress made on both of these issues.
-
Now that StableBit CloudDrive is out can we hope for this issue to be addresses in the near future? Also I do not see this issue in the issues listed under the development status section.
-
Ok solution is that you need to manually create the virtual drive in powershell after making the pool: 1) Create a storage pool in the GUI but hit cancel when it asks to create a storage space 2) Rename the pool to something to identify this raid set. 3) Run the following command in PowerShell (run with admin power) editing as needed: New-VirtualDisk -FriendlyName VirtualDriveName -StoragePoolFriendlyName NameOfPoolToUse -NumberOfColumns 2 -ResiliencySettingName simple -UseMaximumSize
