chiamarc
-
Posts
39 -
Joined
-
Last visited
-
Days Won
3
Everything posted by chiamarc
-
Hi Folks, So, I've been uploading to a clouddrive for a couple months now and I wanted to make sure that I have the right encryption key printed out. I also chose to store the key locally for convenience so I could auto-unlock on boot. But here's the thing: I had setup a cloud drive previously then had to destroy it (for irrelevant reasons). Now I can't recall if the PDF I saved was for that previous drive or the current drive. Since I have it saved locally, is it possible to compare the key to the one in the PDF? Where is the key located? If not, can I just print out the key somehow using the locally saved copy? Otherwise, how can I check that I've got the right key in case of a disaster? Thanks, Marc
-
How the StableBit CloudDrive Cache works
chiamarc replied to Christopher (Drashna)'s topic in Nuts & Bolts
I really don't understand why the "to upload" state becomes indeterminate for the entire write cache. Shouldn't it only have to re-upload chunks that it didn't record as being completed? Why is a chunk not treated akin to a block in a journaling filesystem? Of course I understand that if chunks are 100MB in size, it could still take some time to write them, but no way should the entire cache be invalidated upon a crash. This is especially important for me right now because I've got my system locking up on a not infrequent basis that requires me to hard reset (plus the occasional BSOD). A 200G cache on a 10TB drive (100/5 Mbps d/u) always takes 45+ minutes to recover. -
Where do we submit RFEs?
-
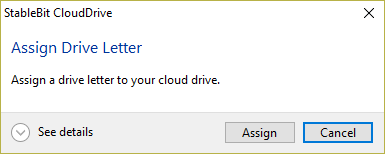
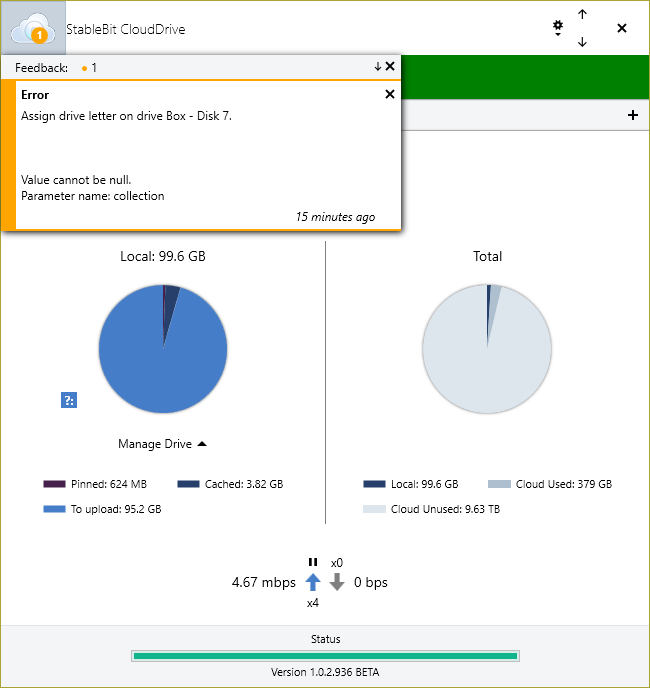
Using CD 1.0.2.936 Beta, I'm unable to assign a drive letter from within the GUI. Clicking on Manage Drive -> Drive Letter... -> Assign (as shown here): Results in a null assignment error: Please advise. Also, where can I check if a similar bug has already been reported?
- 1 reply
-
- 1
-

-
Say I have several disks in my pool and I want to reserve extra space for "other" data on one or more individual disks. That's to say, I don't want Disk x to use more than a certain percentage or byte threshold to store pool data. Is there a way to do this short of splitting the drive into multiple partitions?
-
You could also try running Procmon for a while to capture which processes are deleting anything. The only thing you need to capture are filesystem events and make sure to check "Drop filtered events" under the Filter menu. Then after running for some time, stop capturing (or continue, it's up to you) and search for "Delete: True". The first entry you find should be the result of a SetDispositionInformationFile operation. Right click on the cell in the Detail column and select "Include 'Delete: True'". This will filter every deletion event. Search in the Path column for an instance of a file you didn't expect to be deleted. In the Process Name column you will find which process set the file for deletion. If you have no idea how to use Process Monitor, there are plenty of quick tutorials on the web. Good luck.
-
Hi Guys, Thanks for an absolutely wonderful product. I was just wondering, Comcast limits my data usage to 1 TiB per month (at $10 per 50GiB beyond that). Since many cloud providers do not allow incremental chunk updates (like what I'm using, Box), then depending on the write workload, CD has to download chunks, change them, and re-upload them. While the "To Upload" size measurement is accurate, the tooltip that gives an estimate of how long it will take to drain the upload queue is probably off by quite a bit, especially if one is changing files frequently. Further, the total bandwidth used over a given period of time is not really reflected anywhere. There are tools that allow me to measure (out-of-band) all CD traffic but it would be nice to know how much data was actually read/written in order to empty the upload queue, or for that matter, to do any set of operations. This would help with my bandwidth management (knowing if I need to limit upload/download speed in CD at a given point in the month, or ideally, doing it automatically when I reach a certain threshold). I guess this is a request for enhancement but I'm not sure how many other people have a similar need. Thanks, Marc
- 1 reply
-
- 1
-
-
Brilliant! Tested and satisfied! This gets me *much* closer to my goal and I can now drop files into E: and be sure that they are duplicated locally and into the cloud! This will suffice for the time being as I can always keep important stuff on E: and not so important stuff on D:. Thanks again for being so quick to respond (and change code)!
-
Thanks again Chris for making things much clearer! This is my last message for a while because I don't want to tax you good folks at CoveCube any longer. With a set of simple tests I have now confirmed at least part of what I thought might be true. It's unfortunate because it means that I can't really use the DP/CD combo to do exactly what I want (and I don't think it's an unreasonable use case). I've moved a x2 folder mytest from D:\ to D:\PoolPart.xxyy and remeasured E:. Initially, it remained on HDD1 and HDD2 and I could see it being duplicated to B:. But then, something got to rebalancing (probably the D: pool) and I watched as mytest was quickly removed from HDD1. At this point, mytest only resides on HDD2 and on B:\. This clearly breaks my requirement that I have at least 2 copies on local drives. I should mention that all my balancing rules are defaults. What's more, dropping files onto the E: pool does not duplicate them on local hard drives either. I can confirm all of this both from the File Placement tab in the balancing panel for D: and by confirming where these files exist on HDD. Unless you have any further suggestions, I'll just have to "backup" to my cloud drive using a traditional program.
-
OK, thanks again Chris for your patience (I'm starting to sound like what we call in Yiddish a "pechech"). There still seems to be an impedance mismatch here. Please correct my understanding as I walk through what I put together from the very beginning of this thread and what I'm currently seeing (I know I wrote this in a previous post but I'd like you to refer specifically to what's laid out here): I have existing files in a DrivePool, D: comprising only local HDDs. This pool has 2x duplication on several folders, but let's just assume for simplicity that the entire pool is duplicated. So, there are 2 copies of every file somewhere on the local HDDs. I've created a CloudDrive, B: I've created a new DrivePool, E: I've added D: and B: to the "master" pool E: and set 2x duplication on the entire pool. At this point, looking at E: in the GUI shows me that 4.57TB is Other and 7.78TB is unusable for duplication. Specifics aside, I assume the 4.57TB is the data in D: If I do nothing else from this point on, the 4.57TB that's located inside D: will never be duplicated to B: because E: doesn't see that data as something that needs to be duplicated. I assume this is correct based on your comment above about "seeding" the master pool. If I instead move a folder out of D: and into the hidden PoolPart folder for the master pool and re-measure, then that folder will exist locally on D: (on some HDD that's part of that pool) and also be duplicated on B:. However, it will no longer be duplicated on multiple local HDDs because the D: pool doesn't know about it (i.e., it doesn't show up in a listing of the D: drive). The same applies to any future data that I write to E:. In fact, if I look at the folder tree in the Folder Duplication panel for D:, DrivePool (E:\) shows up as disabled. In addition, any future data that I write to D: will not be duplicated on B: So I find that there is no situation in which files stored in any pool will be guaranteed to have 2+ copies locally and 1+ copies in the cloud. Please tell me which statements above are incorrect.
-
Hi Chris, Thanks for that answer and I don't want to be a PITA but I'm still not seeing a method for what I'm trying to achieve. Specifically, using DrivePool and CloudDrive, how do I ensure that at least one duplicate of specified folders exists on local drives and another duplicate exists on my cloud drive?
-
But Drashna, the problem with this is that once the files are moved off Pool 1, they are no longer protected by local duplicates, only the cloud duplicate. Neither will new files added to the master pool be protected by local duplicates. This is actually hurting my brain!
-
I'm still not understanding this properly. To Pool 3, any data stored in other pools (directly) simply look like blobs that are unusable space. If I drop something into Pool 3 then it will be duplicated in Pools 1 and Pools 2 but is inaccessible from within those pools. Because of this, it also will not be duplicated on multiple HDDs *within* Pool 1. This does not serve the original purpose, which is to keep something safe by dropping it in Pool 1 (comprised of local HDDs) and make certain it will *always* be duplicated at least once in Pool 2 (containing just the single cloud drive). As has been done in other forum posts, I will outline my (what I think are fairly simple) requirements here and I hope someone can tell me how to achieve this using hierarchical pools (or some other method that's not "breaking the rules" or inadvisable). I'm willing to move stuff around: I currently have a pool, D: comprising several HDDs with several folders duplicated (not the whole pool). I have a Clouddrive, B: on Box I would like all existing and future files in D: to always be duplicated to B: at least once, regardless of whether they are already duplicated in D: That's it. I've seen people in other posts mess around with drive usage limiting and balancing, and I know I can always just "backup" to B: using another program, but it seems I should be able to do this via the stellar combination of these two products. I hope @Christopher can chime in soon on this.
-
So, just to be clear on this, suppose I have all my data in Pool 1, with various folders duplicated across multiple HDDs. I now create Pool 2 from a cloud drive. Pool 2 is completely empty and it will remain unduplicated. I now create the master pool, Pool 3 and add Pools 1 and 2 to it. Pool 3 will show all the data in Pool 1 as "other". But if I enable pool duplication on Pool 3 (for now the only one I can enable since there are no folders), then *everything* in Pool 1 will be duplicated to the cloud drive in Pool 2? I did this, but obviously "other" data in Pool 1 will not be duplicated. I don't quite understand how this can be made to duplicate across HDDs and also to the cloud drive inside Pool 2. Thanks.