


servonix
-
Posts
16 -
Joined
-
Last visited
-
Days Won
1
servonix's Achievements
Member (2/3)
3
Reputation
-
Since you don't use/haven't used drivepool I would suggest learning more about how it works so you can see why supporting hardlinks isn't as simple as you might think, and also why having drivepool try to support them conditionally isn't a great idea either. I've been using drivepool for about 12 years now myself. I have full confidence that if there was a simple way for Alex to add support for hardlinks on the pool it would have been done a long time ago. I also want to be 100% clear that I'd love to see hardlinks supported on the pool myself, but I also understand why it hasn't happened yet.
-
Balancing can happen on any pool regardless of duplication level or number of drives (obvious minimum of 2 drives in the pool for balancing to occur) Balancing can/will occur based on critera set be the balancing options, the enabled plugins (the order of the plugins also affects how data will be balanced), any user file placement rules, adding/removing a drive from the pool, etc. Hardlinks would need to be 100% compatible and guaranteed not to break with any pool regardless of disk layout, balancing settings or duplication settings. I'll say it again, trying to support hardlinks under certain conditions and preventing them under others is just a really bad idea when those conditions can change at any time.
-
Your examples seem to only take a 2 disk pool into consideration. Adding a 3rd drive (or more) into the pool immediately complicates things when it comes to the balancing and duplication checks that would be needed to make this possible. Also, even if you try to control the conditions under which hardlinks are allowed to be created, those conditions can change due to adding/removing a drive or any automatic balancing or drive evacuation that takes place. Allowing hardlinks to be created under certain conditions when those conditions could change at any point afterwards probably isn't a good idea. Any implementation to fully support hard links has to work properly and scale with large pools without any (or at least minimal) performance penalties, and be 100% guaranteed to not break the links regardless of dupication, balancing, etc.
-
Given that stablebit drivepool and scanner are relatively uh "stable"peices of software I'd like to think that Alex and Chris are working a lot behind the scenes to fix some of the more esoteric or critical issues with the software. While it would be nice to get some official answers, I wouldn't go all doom and gloom just yet. Remember, it's mainly two people behind the scenes with a couple of volunteer mods for relatively niche (but awesome) software. Regardless I certainly hope stablebit isn't going anywhere anytime soon. It's one of the main reasons I've kept my primary homeserver on windows. After 12+years I can't imagine using anything else. I've got an Unraid server as well. As flexible as it is, it has its own issues/drawbacks, so it's only used for backups. There are some things drivepool just does better (at least for my setup)
-
The requirement for two physical drives (or rather as many physical drives as the duplication level of folders to avoid also writing to hard drives with realtime duplication enabled) is to prevent all copies of data from being stored on only one SSD. If both copies of data are written to two separate partitions of a single SSD and that SSD were to fail before the data is moved to hard drives then you would lose both copies of the data. As for recommended settings, the defaults are mostly fine IMO. You may need to tweak the balancing settings though if you want data moved over to the hard drives quicker or if you want file placement rules to keep some files/folders on the SSD's and not have them moved over to the hard drives.
-
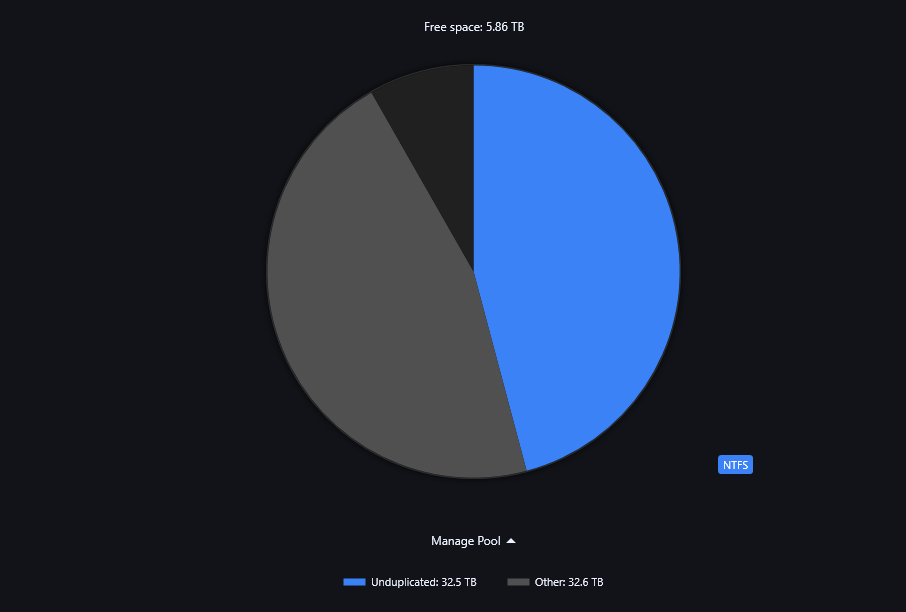
So I am in the process of migrating my single pool to a subpool configuration. I added the single pool to a new pool and seeded the data into the new poolpart folder on the now sub pool. Duplication is enabled on the sub pool. After remeasuring and verifying duplication on both pools, the new top level pool is showing half of the total space as "other" data. Everything on the subpool is showing as normal. I'm not certain if this is expected behavior due to the subpool having duplication enabled or some kind of bug that I've encountered with the UI. I've tried resetting drivepool to defaults and remeasuring but it's still the same afterwards. My plan is to migrate my SSD's to their own subpool so that I can store certain file types from within the same folder on either the SSD subpool or HDD subpool each with their own duplication levels. Ideally I would like to see the top level pool show everything as unduplicated data.
-
 Shane reacted to an answer to a question:
File Placement Rules not being respected as pool is filling up
Shane reacted to an answer to a question:
File Placement Rules not being respected as pool is filling up
-
Each file placement rule is set to never allow files to be placed on other disks. Since posting this I have actually been able to correct the issue. I added another file placement rule to the list for .svg images in my media library as I noticed emby fetched one for a newly added movie. When Drivepool started balancing I noticed it placing files onto the SSD's excluded from the media file placement rules. I stopped the balancing, then started again and the issue started correcting itself. All media files on the SSD's were moved to the hard drives, and all images/metadata were moved to the correct SSD's. I strongly suspect that somehow the scanner balancer combined with old file placement rules from using those SSD's with the optimizer plugin were at fault. One of my drives had developed a couple of unreadable sectors a few weeks ago and started evacuating files onto the SSD's. At the time the SSD's were included in the file placement rules from previously being used with the ssd optimizer plugin. I had stopped the balancing, removed the culprit drive from the pool choosing to duplicate later and did a full reformat of the drive to overwrite the bad sectors. When the format completed I did a full surface scan and the drive showed as healthy, so I was comfortable re-adding it back into the pool. Drivepool reduplicated the data back onto the drive and a balancing pass was also done to correct the balancing issues from the drive being partially evacuated. The file placement rules were also changed at this time to exclude those SSD's from being used by my media folders and metadata/images. Everything was working as expected until the other day. For whatever reason only a small portion of newly added files were actually written to the excluded SSD's. It was literally only stuff added within the last couple of days despite a significant amount of data being added since re-adding that drive back into the pool and adjusting file placement rules to exclude the SSD's that were previously used by the optimizer. It's as if some kind of flag set by the scanner balancer or the old file placement rules weren't fully cleared. Regardless of the cause I'm glad that everything seems to be chugging along like normal now. If I start noticing any more weird behavior I intend on enabling logging to help support identify what's going on under the hood.
-
So I've been using file placement rules for years to control which folders or file types are stored on which drives, and up until recently everything has been working perfectly. I've noticed that as my pool is getting closer to being full the file placement rules are not being respected. My main use case is ensuring media such as movies and tv shows are stored on hard drives while images and metadata in the same folder are stored on SSD's, as well as keeping other folders on drives that do not hold my media collection. The only balancing plugin enabled is for stablebit scanner and all drives are healthy. In file placement settings the only option checked is "Balancing Plug-ins respect file placement rules"The order of my file placement rules are setup properly so that the file extension rules for images and nfo files are above the rules that place all other media file types on the selected drives. All other file placement rules for other folders are above the rules for media files and folders with the media drives excluded. Duplication is enabled for the entire pool. There are 9 hard drives for the media library each with around 400-450GB free space, 2 500GB SSD's for images and metadata with around 50GB used, 4 hard drives that are excluded from media and file rules with one pair of 2TB drives having 322GB used and a pair of 3TB drives having only 60GB free space, 2 1 TB SSD's for other micselaneous data that are excluded from media folder and file rules with about 250GB used before this issue started. The SSD's that are excluded from all of the media library rules is where I'm noticing both media files as well as images and metadata being placed. These drives have more availible space than the media drives in the pool, however the media drives have more than enough free space for the files being added. It seems that these SSD's are receiving 1 copy of the media files. No automatic balancing is triggered to correct the file placement. I've double checked all file placement rules and settings, everything is as it always has been. I do plan on upgrading a couple of my smaller media drives to larger ones in the near future, but I don't anticipate completely running out of space before then. I'm really stumped as to why this setup is suddenly having issues when it's worked so well for so long. My assumptiom was that file placement rules will always be respected assuming the correct settings and assuming there's enough free space for the data being added.
-
I appreciate the fact that you've already looked into it, I figured you might would have. I could see a Scanner WinPE disk as useful though, so that is some good news. In theory I think you could do the restore from another machine mounted to the cloud drive and with the target disk inside using the Server Backup console. Is that something you've personally tested? The end goal is to have the backups on a network share on a separate machine rather than an external HD. My pool is actually full and I have no single spare drive large enough for the server backups, and due to budget constraints I can't buy another drive just yet.
-
I have been running 2 copies of scanner for a while now....Hyper-V on standard with an essentials VM, and separate DC, along with a few other VM's booting from raid 1 Velociraptors and a 240GB ssd as primary VM storage. All data drives are passed through to the essentials VM due to the Client backup limitations. I was merely suggesting a software work around so that when drives are passed through directly to the VM the host copy of scanner can communicate the SMART data to the guest, restoring full functionality of drive evacuation, etc. It still won't solve the failure to boot the VM when a drive dies in a weird way lol. I guess this topic got derailed, While PCIE passthrough would be ideal, it has it's own issues.
-
I think I'm gonna try it on my backup server if i can ever get enough time away from work. I'm hoping to be able to stick with Hyper-V as my host. Drashna, I think I mentioned something a while back about implementing a feature for remote control that would allow the host to pass SMART to the VM in a scenario where the disk is passed through.How hard would that be to implement? that may be a more elegant solution than trying to mess with iommu and all that, especially considering that Microsoft will probably never officially support it, so it is likely to be buggy if it works at all.
-
Has anyone successfully passed through an LSI based controller under Hyper-V to a VM so that Scanner can get all SMART data off of each drive? Even though Server 2016 has been out for a while I'm still finding little documentation on DDA/PCIE passthrough under Hyper-V, and most of it seems GPU centric. I'm running Essentials 2016 as a VM with each individual drive passed through, and would really like to just pass through the entire controller to the guest to alleviate headaches when a drive dies/drops out.
-
I was just wondering what the recovery scenario would be when using a CloudDrive drive as the server backup target disk under Windows Server 2016 Essentials, particularly with regards to doing a bare metal restore. My assumption is that the CloudDrive would have to be mounted on another system, along with the disk being restored to, do the recovery, then boot off of the restored disk. Someone please confirm or deny whether my assumption is correct. Furthermore, if that is the recovery scenario, would it theoretically be possible to have a WinPE based boot disk that has a version of CloudDrive baked in that would allow a more seamless recovery, and if so is that something someone with a little more skill working with images would be willing to make?
-
Glad to hear you're not having any issues with it. I know the support isn't quite there yet, but the pros seem to outweigh the cons with regards to file integrity. Well for WSUS I intend to keep the sql database on a drive outside of the pool, I just want the actual content files on the pool, and that requires a drive that reports as NTFS. As of now Drivepool is still reporting the pool drive itself as NTFS, so in theory it should work even with the underlying drives as REFS. I guess you might not have a clear answer to whether or not it does as that's something you probably haven't tested. I might either bite the bullet and make the transition, or do a small-scale test in a VM and see the results for myself. Assuming that it works, would it be possible to implement a way to specify what the pool reports as (NTFS or REFS) with a pool consisting of REFS formatted drives in later versions of Drivepool? All that aside, write performance isn't terribly important, as I will have multiple ssd cache drives. What I'm really concerned about is if there is any penalty reading with integrity checking on vs NTFS.
-
So I have my server migrated to 2016E and I'm contemplating shuffling my pool around and reformatting my drives as REFS with integrity streams on.. I know I've seen Drashna post somewhere that his pool is using REFS now, so I'm assuming that development is far enough along to be fairly stable. My server is primarily a media and backup server, and the data integrity stuff REFS should provide would be a major plus. I'm just wondering which build version of DP I should use, as well as any caveats I should know about before making the move(especially if there are any drastic hits to performance VS 64K NTFS) Also on the same note, one of the few services I haven't set up yet on the server is WSUS. I have run the content store on the pool before with success, but was wondering if that would still be possible with REFS as the underlying filesystem of the drives since WSUS requires an NTFS formatted partition. Thanks in advance to Drashna and anyone else who can provide some input! Edit: I should also note that my network is 10Gb capable, and although I'm not quite maxing it out, I am taxing it a bit at times, so read performance is quite important, write not quite as much since I'll be adding a few SSD's for cache before too long.