thnz
-
Posts
139 -
Joined
-
Last visited
-
Days Won
7
Everything posted by thnz
-
It wasn't uploading yesterday evening when it was 80/100GB cache, no. About 2am backups would have been done, and it looks like 25GB was copied to the cloud disk, so at 2am I guess it would have been 80/100GB cache + 25GB to upload. By 9am this morning everything was uploaded and it was at 10/100GB cache.
-
Is there any circumstance where the cache would be expected to clear itself? I've seen it happen a few times over the past few weeks. For instance, last night there was 80GB cached out of a max of 100GB, whereas this morning the cache was only 10.4GB full out of 100GB. Theres plenty of free space (~700GB) on the cache disk. Cache type is expandable.
-
I've noticed a few times the drive will go into recovery even after a clean computer restart, needing to re-upload the entire cache. I get the 'unsafe shutdown' message even though Windows restarted gracefully.
-
Would drive chunk size have an impact on pre-fetching? I've noticed ACD drives have been faster since the increase to 10mb chunks (was 1mb prior), though there may have been other optimizations in play too. It would make sense - the potential to download more than 1mb in a single request - especially with a 4 thread limit.
-
Zipped up and submitted.
-
I've been seeing this error quite often over the past few days: It seems to happen when prefetching. Is it likely to be a throttling thing as the drive is on Amazon Cloud Drive, or is it likely a bug elsewhere? It only ever happens on Read (Prefetch) I/O. Regular reads and writes go through without issue. I can submit logs and drive tracing while it was happening if needed. It seems to happen in waves - I assume whenever prefetching is triggered. Version 1.0.0.560. Not sure if its relevant, but the drive is being used for DrivePool duplication.
-
Done. Will be uploaded shortly. *edit* Uploaded. In this instance the UI client was running on a different machine to the server - both are Windows 10 x64.
-
Occasionally when closing the UI, it will stop responding and need to be force closed. I've seen this happen on three different computers, both when connected to the local CloudDrive service, or when connected to a remote instance on another machine. I'm unsure what triggers it, and I can't make it happen on demand. From what I can tell, it has no effect on the service itself. CloudDrive.UI.exe will max out a single CPU core when it happens. It's been a long standing thing, and isn't only in recent builds. Is there anything I can do the next time it happens to help you guys troubleshoot? I'm unsure if the UI generates log files. Nothing appears in the service logs when it occurs.
-
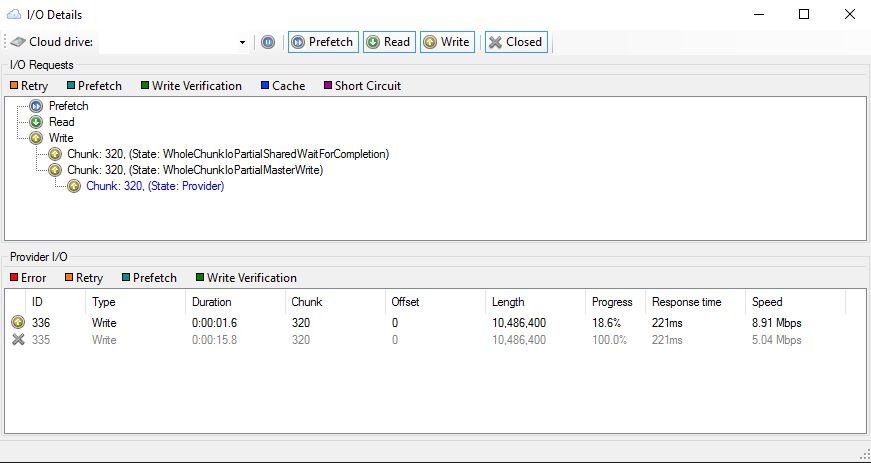
The attachment to post #9 shows what it looks like in the more detailed I/O window in .479. In that case chunk 320 was repeatedly uploading.
-
Amazon Cloud Drive. Currently .479. I'm unsure what version the drive was made with - the timestamp on the folder is Feb 17 2016. At a guess .460, as I think that was when I started trying it out again. It seemed to come right again about the time I enable disk tracing, and as far as I can tell, has been uploading normally since.
-
It's doing it again right now shortly after a restart. The new UI stuff shows a bit more detail. I'll leave drive tracing on for 5mins or so and submit logs again.
-
That sounds like the exact issue I encountered, but haven't been unable to reliably reproduce. After the computer crashed while CloudDrive was uploading, some files were corrupted (same size, different hash than the originals). They had been written to disk many hours before the crash. I've been unable to reliably reproduce it - last time it took over 30 resets for it to trigger.
-
http://community.covecube.com/index.php?/topic/1610-how-the-stablebit-clouddrive-cache-works/ Might be by design:
-
FWIW nothing out of the ordinary was showing in the log file, and nothing that coincided with it occurring. Just the occasional 'throttling' message, but that appears normally. I did enable disk tracing while it was happening, though AFAIK there was no actual reads or writes during the minute or so I had it enabled - it was just uploading previous writes. I'll zip it up and submit it anyway. From memory, what had happened: Copied several GBs of files onto the cloud disk via a windows share. Cancelled the copy prior to completion, and deleted the files that were copied (via windows share). Restarted the computer immediately after deletion (graceful restart from the start menu). The computer took an abnormally long time to restart, but there was no crashing or anything. Redone the copy. I think this is when it started happening, as over the next 18 hours or so 'to upload' had only gone down by a few GB. I don't know if any of this is relevant or not. I haven't tried reproducing it. It lasted until I updated to .470 and restarted yesterday evening (2016-02-24 09:13:02Z in the logfile), after which uploading has resumed at the normal rate.
-
It was on .463, and that behavior carried on for just under a day. However, after installing .470 this evening and restarting it went back to uploading as normal. I'm unsure if it was the update or the restart that fixed it, but its been working as expected ever since.
-
I copied a large amount of data to the cloud drive last night, and it's still uploading today. I just had a look at the I/O Threads window and it appears to be uploading the same chunk over and over again, before moving on to the next one. Is this expected behavior under any circumstance? I've caught it happened several times today. Nothing has been written to the drive since last night. Here's what I mean: http://webmshare.com/play/Gy33A
-
Is there any chance of having the thread limit increased slightly when using a custom Amazon security profile? If the purpose of the thread limit was to allow more concurrent users on the dev status profile, then this shouldn't be an issue with a custom profile.
-
Also, I'm getting the same speeds with my own (dev status) custom security profile, so I guess that rules out throttling from lots of people on a single profile.
-
FWIW .460 seems to be usable atm, much moreso than it was when I last tried several months ago. While not line-speed, speeds are much improved. Whether this is due to optimisations you guys have done recently (chunk sizes, chunk caching etc), less people using it with ACD, or I just got lucky when I tried it I guess its hard to say. Regardless, I won't be storing anything worth losing on it until its no longer experimental.
-
Is there any news on this? I see we can now use custom ClientIDs and ClientSecrets - I assume to use our own dev profile with Amazon. Also trying the latest beta (.456) and it's throwing 'Chunk 0 was not found' errors when creating a new drive on ACD.
-
Is the first/default method not the same as what you guys are doing?
-
They're probably running in production status. Perhaps the 'chunky' nature of clouddrive makes it stand out with high calls/sec, even though the intelligent caching side of it will cause less data to be transferred. Storing a 100mb file in 1mb chunks could mean 100 upload requests rather than just 1. Also the upload verification would cause a double up in data used when uploading, though IIRC this is necessary as files sometimes 'disappear' unexpectedly at Amazon's end.
-
IIRC it reuploads whatever is in your local cache after an ungraceful shutdown. I've only seen this happen after BSODs, but I guess it'll happen after power failures too. I've actually seen some data corruption occur when this happens during an active upload, though have struggled to reliable reproduce it. That is has the potential to happen on a clean shutdown is a bit worrying!
-
Was it uploading at the time the power went off? I've seen data loss happen on a hard restart while uploading was active, though its been a right pain to reproduce reliably.
-
https://forums.developer.amazon.com/forums/thread.jspa?forumID=73&threadID=9355