


Thronic
-
Posts
67 -
Joined
-
Last visited
-
Days Won
1
Everything posted by Thronic
-
Thx for taking the time to reply Chris. All drives were in perfect SMART condition and zero passed to trigger any potential issues before using. I used the term e-waste loosely because it's what many of my colleagues say for drives that size lately... I do recovery and cloning professionally, so I have access to many used - but not damaged, low capacity drives. This gives me also the special benefit of actively create mechanical damage while spinning, so I can see how the systems react to true SMART problems. Thanks for mentioning your own preferences. There are of course things (tuneables) I would need to study more if using GNU/Linux based software RAIDs, but I've used DrivePool and Scanner so many years that I just trust certain things by now. E.g. how the scanner not only is a very adamant monitoring tool, but also how it will tell you exactly what files were affected upon a pending sector that's not recoverable. This means the difference of replacing all drive data vs a single file. You're absolutely right, simplicity goes a very long way. Still a big fan of StableBit, even if I consider other waters once in a while.
-
PROCESS_NAME: Duplicati.Serv Was probably doing some reading and/or writing on your pool, and by extension, covefs.sys operations. c0000005 is covefs.sys+0x1ad90 doing modifications to memory that's either protected or doesn't exist. Maybe Duplicati is one of them low level doing-special-ntfs-tricks things. I might do a memtest while waiting for official answer.
-
Thx for replying, Shane. Having played around with unraid the last couple of weeks, I like the zfs raidz1 performance when using pools instead of the default array. Using 3x 1TB e-waste drives laying around, I get ~20-30MB/s writing speed on the default unraid array with single parity. This increases to ~60MB/s with turbo write/reconstruct write. It all tanks down to ~5MB/s if I do a parity check at the same time - in contrast with people on /r/DataHoarder claiming it will have no effect. I'm not sure if the flexibility is worth the performance hit for me, and I don't wanna use cache/mover to make up for it. I want storage I can write directly to in real time. Using a raidz1 vdev of the same drives, also in unraid, I get a consistent ~112 MB/s writing speed - even when running a scrub operation at the same time. I then tried raidz2 with the same drives, just to have done it - same speedy result, which kinda impressed me quite a bit. This is over SMB from a Windows 11 client, without any tweaks, tuning settings or modifications. If I park the mindset of using drivepool duplication as a middle road of not needing backups (from just a - trying to save money - standpoint), parity becomes a lot more interesting - because then I'd want a backup anyway just because of the more inherent dangerous nature of striping and how all data relies on it. DDDDDDPP DDDDDDPP D=data, P=parity (raidz2) Would just cost 25% storage and have backup, with even backup having parity. Critical things also in 3rd party provider cloud somewhere. The backup could be located anywhere, be incremental, etc. Comparing it with just having a single duplicated DrivePool without backups it becomes a 25% cost if you consider row1=main files, row2=duplicates. Kinda worth it perhaps, but also more complex. If I stop viewing duplication in DrivePool as a middle road for not having backups at all and convince myself I need complete backups as well, the above is rather enticing - if wanting to keep some kind of uptime redundancy. Even if I need to plan multiple drives, sizes etc. On the other hand, with zfs, all drives would be very active all the time - haven't quite made my mind up about that yet.
-
In other words, do you use file duplication on entire pools? And if so, what makes the 50% capacity cost worth it to you? I'm just procrastinating a little.. I want some redundancy but parity doesn't exist (I have no interest in the manual labor and handholding snapraid requires and Storage Spaces is not practical). So basically if I want parity I'd split the server role into another machine (I'm not interested in a virtualized setup) and dedicate the case holding drives to something like unraid as dedicated NAS - nothing else. Unraid also having the benefit of only loosing data on damaged drives, if parity should fail. Snapraid and Unraid, as far as I know, are the only parity solutions that has that advantage. This matters to me as I can't really afford a complete backup set of drives of everything I will store - at least not if already doing mirror/parity - so I'm floating back to thinking about simple pool duplication as a somewhat decent and comfortable middle road against loss (most important things are backed up in other ways). I would counter some of the loss by using high level HEVC/H265 compression on media via automation tools I've already created. And perhaps in the future head towards AV1 when it's better supported.
-
My own goto for copying out damaged drives (pending sectors) is ddrescue, a GNU/Linux tool available on pretty much any live distro. ddrescue -r3 -n -N -v /dev/sda /dev/sdb logfile.log -f https://www.gnu.org/software/ddrescue/manual/ddrescue_manual.html#Invoking-ddrescue It has a higher than normal percent chance of retrieving data on bad sectors than a regular imaging tool. And it's nice to have visual statistics of exactly how much was rescued. All you need is a drive equal or larger in size to image to, as it's a sector-by-sector based rescue attempt. If there are no pending sectors and just reallocations, you should be able to copy files manually using any file explorer or copy method, really.
-
Can someone make a complete summary of all settings needed to make e.g. Windows Server 2025 allow inactive drives to spin down after N time? I've always allowed my drives to spin, but as I get more and more I'm beginning to think maybe I can allow spin downs to save some power over time. Server is in a storage room that will always be between 15/30c winter/summer. I'll be using latest stable DrivePool and Scanner.
-
A lot of open-ended threads as well - some pretty serious. Maybe they're getting a bit overwhelmed, they're only 2 after all. AFAIK.
-
Was curious about what makes DP technically no longer compatible with 2012R2?
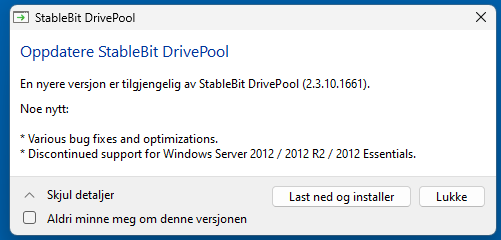
-
Guess that's that then, pretty much. A compromise made for having every drive intact with its own NTFS volume, emulating NTFS on top of NTFS. I keep thinking I'd prefer my pool to be on block level between hardware layer and file system. We'd loose the ability to access drives individually via direct NTFS mounting outside the pool (which I guess is important to the developer and at least initial users), but it would have been a true NTFS on top of drives, formatted normally and with full integrity (whatever optional behavior NTFS is actually using). Any developer could then lean on experience they make on any real NTFS, and get the same functionality here. If not using striping across drives, virtual drive could easily place entire file byte arrays on individual drives without splitting. Drives would then still not have to be reliant on eachother to recover data from specific drives like typical raids, one could read via the virtual drive whatever is on them by checking whatever proprietary byte array journal data one designs to attach to each file on block level. I'd personally prefer like something like that, at least from a glance when just thinking about it. I'm pretty much in the @JC_RFC camp on this. Thanks all for making updates on this.
-
Thanks @MitchC Maybe they could passthrough the underlying FileID, change/unchanged attributes from the drives where the files actually are - they are on a real NTFS volume after all. Trickier with duplicated files though... Just a thought, not gonna pretend I have any solutions to this, but it has certainly caught my attention going forwards. Does using CloudDrive on top of DrivePool have any of these issues? Or does that indeed act as a true NTFS volume?
-
As I interpreted it, the first is largely caused due to second. Interesting. I won't consider that critical, for me, as long as it creates a gentle userspace error and won't cause covefs to bsod. That's kind of my point. Hoping and projecting what should be done, doesn't help anyone or anything. Correctly emulating a physical volume with exact NTFS behavior, would. I strongly want to add I mean no attitude or any kind of condescension here, but don't want to use unclear words either - just aware how it may come across online. As a programmer working with win32 api for a few years (though never virtual drive emulation) I can appreciate how big of a change it can be to change now. I assume DrivePool was originally meant only for reading and writing media files, and when a project has gotten as far as this has, I can respect that it's a major undertaking - in addition to mapping strict NTFS proprietary behavior in the first place - to get to a perfect emulation. It's just a particular hard case of figuring out which hardware is bugging out. I never overclock/volt in BIOS - I'm very aware of its pitfalls and also that some MB may do so by default - it's checked. If it was a kernel space driver problem I'd be getting bsod and minidumps, always. But as the hardware freezes and/or turns off... smells like hardware issue. RAM is perfect, so I'm suspecting MB or PSU. First I'll try to see if I can replicate it at will, at that point I'd be able to push in/outside the pool to see if DP matters at all. But this is my own problem... Sorry for mentioning it here. Thank you for taking the time to reply on a weekend day. It is what it is, I suppose.
-
Gonna wake this thread just because I think it may still be really important. Am I right in understanding that this entire thread mainly evolves around something that is probably only an issue when using software that monitors and takes action against files based on their FileID? Could it be that Windows apps are doing this? quote from Drashna in the XBOX thread: "The Windows apps (including XBOX apps) do some weird stuff that isn't supported on the pool.". It seems weird to me, why take the risk of not doing whatever NTFS would normally do, or is the exact behavior proprietary and not documented anywhere? I only have media files on my pool, has since 2014 without apparent issues. But this still worries me slightly; who's to say e.g. Plex won't suddenly start using FileID and expect consistency you get from real NTFS? Only issue I had once was with rclone complaining about time stamps, but I think that was read striping related. I have had server crashes lately when having heavy sonarr/nzbget activity. No memory dumps or system event logs happening, so it's hard to troubleshoot, especially when I can't seem to trigger it on demand easily. The entire server usually freezes up, no response on USB ports or RDP, but the machine often still spins its fans until I hard reset it. Only a single time has it died entirely. I suspect something hardware related, but these things keep gnawing on my mind... what if, covefs... I always thought it was exact NTFS emulation. I haven't researched DrivePool in recent years, but now I keep finding threads like this... Seems to me we may have to be careful about what we use the pool for and that it's dangerous conceptually to not follow strict NTFS behavior. Who's to say Windows won't one day start using FileID for some kind of attribute or journaling background maintenance, and cause mayhem on its own. If FileID is the path of least resistance in terms of monitoring and dealing with files, we can only expect more and more software and low level API using it. This is making me somewhat uneasy about continuing to use DrivePool.
-
Did you try turning read striping off?
-
Thanks so much for reminding me.. I had entirely forgotten about Bypass file system filters, I used to have that on and I remember now that it had a good effect. I don't think I had network IO boost on, but I'm turning that on as well, seems safe if it's just a read priority thing.
-
If I'm watching something on Plex, and e.g. Sonarr or Radarr has downloaded something, once it gets copied to the pool, I have strong buffering issues, even with just me watching. Anything I can turn off to make drivepooling a bit faster/more responsive? Running pretty much a default, and fresh, install now on Windows 11 Pro. Or are we in ssd cache territory?
-
Used gsuite for 5 years or so, been through most of the hurdles, ups and downs, their weird duplicate file spawns. Had a clean rclone setup for it that worked as well as could be expected, but I have to say, never been happier to go back to local storage the last couple years, mostly due to performance. And also don't have to sorry about all this anymore..
-
I got the same mail a few days ago and the change to Workspace Enterprise Standard with a single user was entirely painless, just changing from "more services" under invoicing. I have 22 TB and everything still works like usual. It seems Google support evade the question as much as possible, or try not to directly answer it. I personally interpret is as they want the business as long as it doesn't get abused too much. Only people I've heard about being limited or cancelled are those closing in on petabytes of data.
-
Any way to check if the pool state is OK via CLI?
Thronic replied to Thronic's question in Nuts & Bolts
Good point. But doing individual disks means more follow-up maintenance... I think I'll just move the script into a simple multithreaded app instead so I can loop and monitor it in a relaxed manner (don't wanna hammer the disks with SMART requests) and kill a separate sync thread on demand if needed. If I'm not mistaken, rclone won't start delete files until all the uploads are complete (gonna check that again). So that creates a small margin of error and/or delay. Thanks for checking the other tool. -
Any way to check if the pool state is OK via CLI?
Thronic replied to Thronic's question in Nuts & Bolts
Ended up writing a batch script for now. Just needs a copy of smartctl.exe in the same directory, and a sync or script command to be run respectively of the result. Checks the number of drives found as well as overall health. Writes a couple of log files based on last run. Commented in norwegian, but easy enough to understand and adapt to whatever if anyone wants something similar. @echo off chcp 65001 >nul 2>&1 cd %~dp0 set smartdataloggfil=SMART_DATA.LOG set sistestatusloggfil=SISTE_STATUS.LOG set antalldisker=2 echo Sjekker generell smart helse for alle tilkoblede disker. :: Slett gammel smart logg hvis den finnes. del %smartdataloggfil% > nul 2>&1 del %sistestatusloggfil% > nul 2>&1 :: Generer oppdatert smartdata loggfil. for /f "tokens=1" %%A in ('smartctl.exe --scan') do (smartctl.exe -H %%A | findstr "test result" >> %smartdataloggfil%) :: Sjekk smartdata loggen at alle disker har PASSED. set FAILEDFUNNET=0 set DISKCOUNTER=0 for /f "tokens=6" %%A in (%smartdataloggfil%) do ( if not "%%A"=="PASSED" ( set FAILEDFUNNET=1 ) set /a "DISKCOUNTER=DISKCOUNTER+1" ) :: Kjør synkronisering mot sky hvis alle disker er OK. echo SMART Resultat: %FAILEDFUNNET% (0=OK, 1=FEIL). echo Antall disker funnet: %DISKCOUNTER% / %antalldisker%. set ALTOK=0 :: Sjekker at SMART er OK og at riktig antall disker ble funnet. if %FAILEDFUNNET% equ 0 ( if %DISKCOUNTER% equ %antalldisker% ( set ALTOK=1 ) ) :: Utfør logging og arbeid basert på resultat. if %ALTOK% equ 1 ( echo Alle disker OK. Utfører synkronisering mot skyen. > %sistestatusloggfil% echo STARTING SYNC. ) else ( echo Dårlig SMART helse oppdaget, kjører ikke synkronisering. > %sistestatusloggfil% echo BAD DRIVE HEALTH DETECTED. STOPPING. ) -
I'm planning to run a scheduled rclone sync script to the cloud of my pool, but it's critical that it doesn't run if files are missing due to a missing drive, because it will match the destination to the source - effectively deleting files from the cloud. I don't wanna use copy instead of sync, as that will recover files I don't want to recover when I run the opposite copy script for disaster recovery in the future, creating an unwanted mess. So, I was wondering if there's any CLI tool I can use to check if the pool is OK (no missing drives), so I can use it as a basis for running the script. Or rather, towards the scanner. Halting the execution if there are any health warnings going on.
-
Bumping this a little instead of starting a new one.. I'm still running GSuite Business with same unlimited storage as before. I've heard some people have been urged to upgrade by Google, but I haven't gotten any mails or anything. I wonder if I'm grandfathered in perhaps. Actually, they didn't: If they did, I'd just upgrade to have everything proper. I have 2 users now, as there was rumors late-2020 that Google were gonna clean up single users soon who were "abusing" their limits (by a lot) but leave those with 2 or more alone. I guess that's a possible reason I may not have heard anything as well. 2 business users is just a tad above what I'd have to pay for a single enterprise std. The process looks simple, but so far I haven't had a reason to do anything ..
-
What I meant with that option is this: Since I haven't activated duplication yet, the files are unduplicated. And since the cloud pool is set to only duplicated, they should land on the local pool first. And when I activate duplication, the cloud pool will accept the duplicates. Working as intended so far, but I'm still hesitant about this whole setup. Like I'm missing something I'm not realizing, but will hit me on the ass later.
-
Sure is quiet around here lately... *cricket sound*
-
DrivePool doesn't care about assigned letters, it uses hardware identifiers. I've personally used only folder mounts since 2014 via diskmgmt.msc, across most modern Windows systems without issues. Drives "going offline for unknown reason" must be related to something else in your environment. Drive letters are inherently not reliable. The registry key MountedDevices under HKLM that's responsible for keeping track can become confused at random unknown drive related events, even to the point where you can't even boot the system properly. Doesn't need stablebit software for this to happen. Certain system updates mess around with the ESP partition for reboot-continuation purposes and may actually cause this if disturbed by anything during its process.
-
Seems tickets are on a backlog, so I'll try the forums as well. I've setting up a new 24 drive server and looking first at stablebit as a solution to pool my storage since I already have multiple licenses and somewhat experience with it, just not with clouddrive. I've done the following. Pool A: Physical drives only. Pool B: Cloud drives only. Pool C: A and B with 2x duplication. Drive Usage set to B only having duplicate files. This let me hold off turning on 2x duplication until I have prepared local data (I have everything in the cloud right now), so the server doesn't download and upload at the same time. Pool A has default settings. Pool B have turned off balancing, I don't want it to start downloading and uploading just to balance drives in the cloud. It's enough with the overfill prevention. My thought process is that if a local drive goes bad or need replacement, users of Pool C will be slowed down but still have access to data via the cloud redundancy. And when I replace a drive, the duplication on Pool C will download needed files to it again. Is read striping needed for users of Pool C to always prioritize Pool A resources first? This almost seems too good to be true, can I really expect it to do what I want? I have 16TB download as well as Pool B having double upload (2x cloud duplication for extra integrity) before I can really test it. Just wanted to see if there are any negative experiences with this before continuing. My backup plan is to just install a GNU/Linux distro instead as a KVM hypervisor and create a ZFS or MDADM pool of mirrors (for ease of expansion) with a dataset passed to a Windows Server 2019 VM on a SSD (backed up live via active blockcommit) and hope GPU passthrough really works. But it surely wouldn't be as simple ... I know there is unraid too, but it doesn't even support SMB3 dialect out of the box and I'm hesitant to the automatic management of all the open source software stacks involved.. Heard of freezes and lockups etc.. Dunno about it. Regardless, any of the backup solutions would simply use rclone sync as I've used so far for user data backups. Which would not provide live redundancy like hierarchical pools, so I'd loose local space for parity based storage or mirroring. I wont have to loose any local storage capacity at all, if this actually works as expected.
