


freefaller
-
Posts
16 -
Joined
-
Last visited
freefaller's Achievements
-
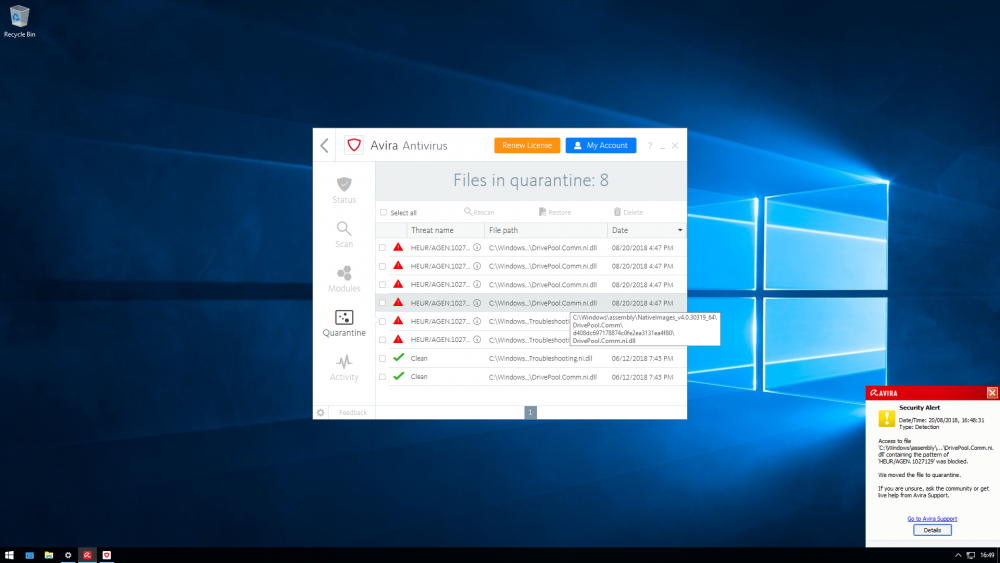
I have the pictured DLL quarantined on my server - just wondering if I should be worried?
-
 Minaleque reacted to a question:
Encrypted Azure Blob Storage
Minaleque reacted to a question:
Encrypted Azure Blob Storage
-
Antoineki reacted to a question:
Encrypted Azure Blob Storage
-
Just wondering how this works with Clouddrive. Any point enabling it at all? Given that the data is already encrypted.
-
Ah, perfect thanks. Cleared it right up.
-
Is there any way to increase the size of the cloud drive? I'm happy with my testing and want to start using the software in earnest, and thought it would be easier to just increase the 100gb test drive I'd created. Also, can someone explain the pie chart figures to me? Where is the "Local: 1,024MB" coming from? I have 90GB of data on my local drive. Also explain pinned please?
-
I'm just running the robocopy job in a batch file on startup on one of my servers. Unless there's a better way?
-
Christopher (Drashna) reacted to an answer to a question:
Clouddrive & Drivepool, Beta
-
Virtualisation! And ye olde question of WHS2011 or WS2012 EssentialsR2
freefaller posted a question in General
I've almost finished virtualising my home infrastructure, with everything running on a backbone of Windows Server 2012 R2 Datacentre. This seemed like such a good idea (and it was!) until the premature arrival of my new Son. Now its going rather slowly...! The last device remaining outside of this is my WHS2011. I have P2V'd my WHS2011 and am preparing to make that transition after some testing this weekend. I'm just wondering though if I might take this opportunity to move to Server 2012 R2 (Essentials or otherwise), especially given the EoL of WHS (though I understand we will continue to receive security updates), I've read a lot about this and will probably opt to test Server 2012 R2 first before moving the box over. A lot of thoughts seem to be along the lines of using Server 2012 if you have access to it? I guess I just want a bit of advice on how to setup the drivepool in a virtual environment. I understand that for SMART I'm going to have to buy two copies and run it as in this thread, but what is the best way to set up the disks for the drivepool? Bearing in mind when moving the live system I won't want to be formatting any disks. Should I set up the drivepool on the physical system (Datacentre) and monitor these drives from within WHS2011 (or WHS2012)? Or does Drivepool work better if I pass through the disks (ignoring why this is becoming a deprecated technology for a moment) and run them exclusively inside the VM? From an infrastructure point of view, I don't really care where I run the Drivepool, other than having a preference for it to not be on the physical host directly, but if this is better all round, than I'll do that. Also, I don't yet have an additional network card as I just haven't gotten round to getting this setup whilst I've been testing things. I will ultimately have two seperate physical network interfaces, is it best for performance and reliability to dedicate one to the Drivepool machine? And on the subject of networking I'd ideally like to go down the route of teaming but with dns round robin. Any issues with Drivepool and that? Or is there a better networking solution? -
I thought I'd stick my robocopy job up that I've been using for testing - succesfully so far - on the chance it might help someone else achieve what I've been trying to achieve . @echo @echo Begin Monitoring @echo robocopy P:\ E:\ /E /Z /XA:H /W:10 /MT:2 /MON:1 This runs on drive P:\ to drive E:\ and the switches do the following: /E - copy subdirectories, including Empty ones. /Z - copy files in restartable mode. /XA:H - excludes hidden files. /W:10 - waits 10 seconds between retries /MT:2 - uses two threads for copying /MON:1 - monitor the source (P:\) and run every 1 minute Because I'm not using the /MIR (mirror) switch, when files are deleted from my Drivepool drive (P:\), the Robocopy job picks this up, but does nothing. This is exactly what I want as I can look back through the job and see if files have been deleted, and if accidental, I can then copy them back down from my cloud storage. Here's a picture for verification of that - I've run a test by deleting (all duplicated test data of course!) a folder to simulate an accidental delete. The job runs every minute and detects the change, that the cloud drive now has all these extra files: So I can work out from here what I need to restore. I'll be working on the batch file so that I can output a proper log file of all folder differences to detect accidental deletes to make things easier, but the jist of this is it works!
-
Christopher (Drashna) reacted to an answer to a question:
Clouddrive & Drivepool, Beta
-
Thanks, all very helpful answers and certainly enough for me to start trialling the software .
-
Hi, I've a few questions which are probably simple to answer. I've had a search but not found anything concrete. Firstly, any news on when it will leave Beta (how longs a piece of string, right)? I'm not particularly keen on using beta software for the type of data I want to store remotely. Secondly, any issues using it with in a Hyper-V client sitting on Server 2012 R2 Datacentre (I'm probably going to be running WHSv2011 as a virtual machine assuming I can get the P2V working)? Unlikely I'd have thought but I'm in the process of moving everything to virtual "hardware" so worth checking. Thirdly, when adding a cloud storage account, does setting the limit of the drive size (eg I've just selected 10GB for my testing) prevent uploads after this? You can then of course resize the drive, but just wondering what the point of this figure is, if not a hard limit. And if it is a limit, does this raise warnings or alerts, and if so, where? WHS Dashboard, EventVwr? Any plans to integrate into the Dashboard in WHS? I presume closing the GUI doesn't prevent the Clouddrive from operating as normal (I'm assuming the service does all the work)? Lastly for informational purposes, it's not immediately clear how I retrieve files. I'm using Azure blob storage, and everything gets uploaded in 10MB chucks as thats what I happened to select in configuring the drive. Lets say disaster occurs, and my local machine burns down, or blows up or whatever. I can retrieve these blobs...how? Ok I can log into Azure and download the seperate data chunks, but that would take ages and then I've still only got the data in blob.data format. Is it just a case of rebuilding the server, reinstalling CloudDrive, and reconnecting to my cloud hosting (a bit like recreating an existing Drivepool I suppose)? After installing this on a test box, it looks good. Where does the cache drive store the cache? Can't find it on the disk I chose. Also as a suggestion: is it possible to have a feature that doesn't replicate deletes? I'm thinking that the best solution at present might be to have the CloudDrive sat outside my Drivepool, that is mirrored from a share within the Drivepool using something like an Rsync job that runs regularly only copying over new files. That way I can negate the risks of accidental deletes from the DrivePool, as the Rsync job would not delete from the CloudDrive. Whilst I can't see why this wouldn't work, it's a bit of a faff!
-
It does sound like what I'm after. Now to try and automate a process to convert it to html...
-
I think your only option is going to be the hope that data recovery software will be able to at least scrape filenames, if not recover the actual files. I'd recommend Recuva64, I've used this successfully in the past, and it's free. FWIW I'd like something in Drivepool to dump a list of files to a handy format, eg html once a month or at the click of a button. I've now built my own using a crude batch file that I'll just update monthly or so but it would be nice to have a built in feature. For example, I'd like to know what in my drivepool isn't duplicated. Sure I know what folders aren't but that isn't enough granularity for me. I understand that this might be considered outside of the scope of Drivepool though.
-
Sorry for the semihijack, but does anyone know of a defragger that works on volumes without drive letters? I don't assign pool drives a letter.
-
freefaller reacted to an answer to a question:
Recreating a pool
-
freefaller reacted to an answer to a question:
Recreating a pool
-
For anyone else who hits this problem...yes it really was this simple. Removed the new drivepool letter, change the old one, reboot. Et voila. However...if anyone has any ideas it would be really good to know if this might have any repercussions, I really can't think why it would...
-
So I've been having some hardware issues, and I've had to reinstall WHS 2011. My drivepool is largely intact though, albeit with a few missing files, I'm having issues recreating my old drivepool though. The install has created the new drive pool on D:\, my old drivepool has been assigned K:\. So I want to move the folders across so that music. Here's the new (default) pool: The view from Windows...where D:\ is the new pool, K is the old pool, M and Z are backup disks outside the pool. When I add a folder that exists in my old pool, but not the default, so in effect a new folder, it's no problems: You can see, Software adds to the existing pool on K:\. So I want to move Music and Videos back to my old pool, as they're the only folders from the default lot that I use, but can't: Can anyone help me here? Do I need to do some jiggery pokery with the drive letters in disk management? Will simply removing the drive letter of the new pool and moving K:\ to D:\ work?
-
The above worked fine, thanks .
