


Umfriend
-
Posts
1001 -
Joined
-
Last visited
-
Days Won
54
Posts posted by Umfriend
-
-
Hi. So I had "solved" this by only using one 2TB partiiton of each 4TB HDD and backing up all HDDs in the Pool bar 1. However, over time this became very cumbersome and I recently split of Client Computer Backups onto a seperate Pool consisting of 2 x 4TB HDDs formatted as 4 x 2TB partitions. I am running WHS2011 and DP 2.2.0.738 with x2 Pool File Duplication.
Initially, files were distributed correctly, i.e., each duplicate was placed on the other actual HDD. But now some duplicates are stored on two partitions on the same HDD. All settings are default (no file placement rules, balances are Scarr, Volume Equalisation, Drive Usage Limiter, Prvent Drive Overfill and Duplication Space Optimiser).
What I have noticed is that DP seeks to equalise either the amount of date stored or the amount of data free on each partition (which in this case is the same). Two partitions (G:\ and H:\) on Device 5 have a SIV folder with quite a bit of data (as a result of Server Backup running on these I guess).
I am just wondering whether one of the Balancers, I suspect the Duplication Space Optimizer, is not following the "no duplicates on 1 physical HDD"-rule? Perhaps this makes it easier to solve it and needs no/less in-depth code audit?
I would be willing to simply turn the Duplication Space Optimizer off but I doubt whether it will help. DPCMD does list the duplicates as being stored on the same physical HDD but does not indicate that this is an error/problem so I am not sure DP even realises this is one (just did and did remeasure and rebalance, no effect).
Another thing I notice that is weird is that in the Drive Usage Limiter, volumes G:\ and H:\ (together Device 5) are listed seperately (they have their own Duplicated/Unduplicated check boxes) whereas volumes I:\ and J:\ (together Device 3) hare combined and have one check box. It is Device 3, containing I:\ and J:\ that has both duplicates stored on it.
-
Here my knowledge fails. IIRC DP1 does not have such I/O priority setting and if it does then I would not remember where. I use DP2.x with WHS2011 BTW. Yes, removing, duplicating, re-measuring, checking, it can all take a long time. In my experience, going to bed ussually makes me wake up to a solved situation. But you are hard-coring it now and for that I think you may need Christpher to help out.
What's the hurry? The Pool still works, you have a backup of the non-duped data etc.
-
Actually, I think Alex once wrote a piece on this somewhere here or on stablebit.com. As I understand it, the issue is that when you ask a drive for its status, that will cause the disk to spin up. IIRC there is a state accoriding to the OS which may not be the same as the state according to the actual drive and it is the latter you would want (but peeking would cause it to spin up).
-
Well, it is certainly what I would do if I understand you correctly:
1. Connect old 6TB HDD -> Pool should be OK and not report missing drive but you would have a drive in the Pool with issues
2. Connect new 6TB HDD and add to the Pool
3. Through DPUI, "Remove" old 6TB HDD and let DrivePool do its stuff.
It will take a while and I typically go into the DPUI and increase the priority (wish there was a setting to always let DP have high priority).
4. Physically remove old 6TB HDD. Perhaps destroy the data on it.
5. After you are comfortable that all is alright, delete the backup of the data that you keep on the new 6TB HDD.
-
-
Yes, for shadow copies that works but within SVI, other files are stored as well (which, I think, relate to Server Backup).
-
So I do not use CD and know nothing about this but reading this I wonder whether it would make sense to disable write caching (at least on the drive containing the cache drive)?
-
In WHS2011, I'm pretty sure I can get there through the properties of the volume?
I turned them all off ages ago.
What I would like to be able to do easily is delete all the old files in the SIV folder but there are quite a few where I simply can not get access to (unless perhapsd I more the disks to another machine temporarly). I can not even set myself (or anyone) as Owner.
-
As for the the unduplicated files, if you disconnect the drive, the unduplicated files on that disk will disappear.
I *think* Christopher is meaning to say that the unduplicated files located on the disconnected drive will disappear *from the Pool*.
The files on that disconnected drive will however remain on that drive (and can be found by looking in the hidden PoolPart.xxxxx folders). Moreover, reconnecting the drive will cause the disappeared files to re-appear.
-
He drives? Don't have 'm. But once Drivepool does stripes/strings/groups, I'll build a WS2016 machine and buy 2 of those 10TB HDDs as BUP-HDDs.
-
I've had Seagate and WD fail on me. Not Toshiba and HGST but the I have not had them either ;-). Bought one HGST recently to replace a failing Seagate (which was RMA'ed) and I'll see what knowlegde I can gain from this sample of 1 (one).
-
I can see backups over USB (2 or 3). I would not however run USB connected HDDs in a Pool due to the connection that may be dropped (even within spec) where you want/expect 24/7 uninterrupted connection.
But hé, if it works it works.
-
So I have been running .672 BETA for a while now and it worked until...
I got bad sectors on one HDD. I removed it from the Pool and added another. Everything has been duplicated/rebalanced. However, the dashboard reports 34.8MB as Unduplicated. I also get 3.00GB Unusable for duplication which I do not understand as the Pool is x2 and there are 4 ~2TB volumes (2 x 2TB HDDs and 2 x ~2TB partitions on seperate 4TB HDDs)
I am running WHS2011, DP 2.2.0.672 BETA, x2 Pool file duplication
All HDDs are 4K/512e AF, 4K bytes per Cluseter and 1K bytes per FileRecord Segment.
DPCMD does not report any duplication errors. Exactly x2 File parts over Files, both in number and size. That seems fine but it is a hassle and a worry that the dashboard continues to give unduplicated data.
=====
Seperately, I now have 2 HDDs in my 4HDD Pool where I use 2TB partitions on a 4TB HDD. I use 2TB partitions so Server Backup works and do not use the other 2TB partitions on the 4TB HDDs due to the issue that DP does not guarantee duplicated on different physical devices (see http://community.covecube.com/index.php?/topic/1681-unduplicated-files-with-pool-file-duplication/&do=findComment&comment=12330).DPCMD does report duplicates on the same Device but does not raise an error. I have been thinking of automating this but for that the output must be readable into Excel of a database. Would you consider including an option to output to a piped format?
All it would need is a record/line type indicator, e.g.
11 = Free text Line
21 = Directory Duplication Line
22 = File Part Line (Directory)
31 = File Duplication Line
32 = File Part Line (File)
And the file would like something like this
11|Scanning...||||
21|+|[4x/2x M]|P:\||
22|->|\Device\HarddiskVolume7\PoolPart.cebbee37-e4b5-4b4e-881d-0b8fc7a87241\|[Device 1]||
22|->|\Device\HarddiskVolume8\PoolPart.d6c8abad-68f9-4b49-ae2c-b356e5f056d6\|[Device 2]||
22|->| \Device\HarddiskVolume10\PoolPart.c497213b-b1fe-4187-963b-ff1b5ed0e730\|[Device 3]||
22|->|\Device\HarddiskVolume13\PoolPart.ac08c794-b981-42eb-b05b-3994ade7f64b\|[Device 5]||
31|-|[2x/2x]|P:\ServerFolders\A-ALL\DPCMD-V01.LOG|83.0 MB|87,012,010 B
32|->|\Device\HarddiskVolume8\PoolPart.d6c8abad-68f9-4b49-ae2c-b356e5f056d6\ServerFolders\A-ALL\DPCMD-V01.LOG|[Device 2]
32|->|\Device\HarddiskVolume13\PoolPart.ac08c794-b981-42eb-b05b-3994ade7f64b\ServerFolders\A-ALL\DPCMD-V01.LOG|[Device 5]
This could easily be read into Excel or a database for analysis and it would allow me to check (easily) whether duplicates exist on the same physical device.Edit: It would also be of a great help to determine whether the upcoming String/Stripe/Group functionality (which I am very much looking forward to) works.
-
Uhm, I believe experiences with USB-connected HDDs are rather bad. Connections dropping sometimes mostly. Christopher will know and may say but my guess is you'd be better off with other solutions...
-
I can not find the icon to increase the priority.
I drew a red circle around it for you but can not upload the pic (it says "You can upload up to Uploading is not allowed of files")...
So when you are in the DP GUI, at the bottom there is a long bar just above version number? To the right of that is an "X" and a doubled arrow (Fast forward sign). Use the latter.
-
Well, a parity solution takes a long time to recover I would think. Some argue that it also puts additional stress on the remaining HDDs, increasing probability of cascading failure (but, IMHO that is quite a stretch). I use duplication solely as a means to increase uptime. Backup for loss due to accidental deletions, viruses, fire, theft etc. And yes, I rotate Server Backups (which include client backups) offsite.
What is you setup?
-
Next to the prgress bar ther are two icons, one is a cross to cancel the operation, the other increases priority. I alwasy press that on when I have something going on, IMHO it makes a lot of difference (at a cost of performance to other tasks).
-
Duplication <> Backup. And if you are not protected against accidental deletions then it isn't really a backup.
Having said this, it is understandable if one does not backup everything as some things are either unimportant or can be regenerated rather easily.
-
Many higher betas as well.... I don't like but will do one. Which one do you advise? It is WHS2011 BTW.
-
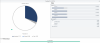
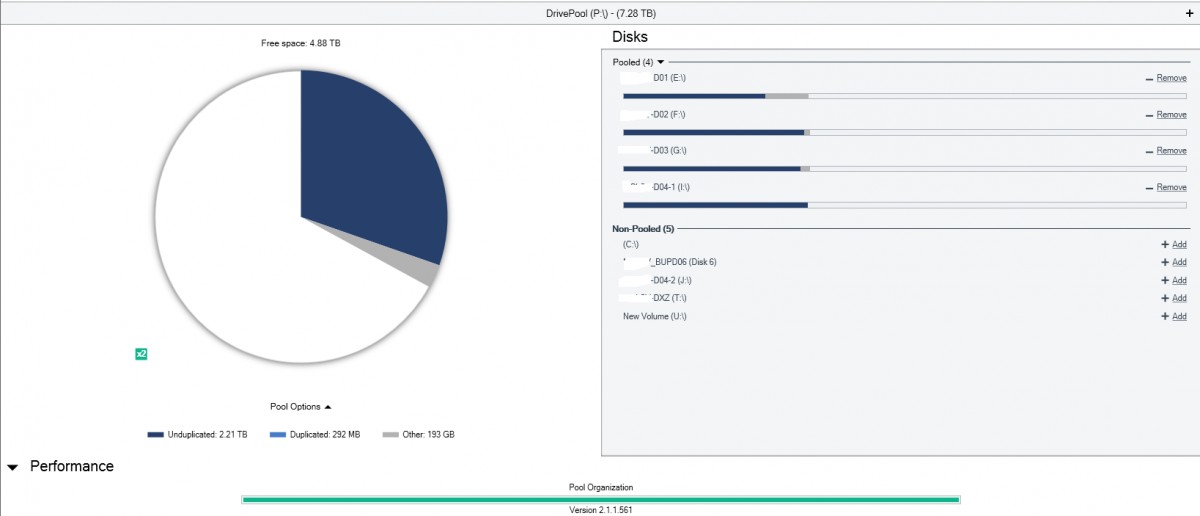
OK, so I had been on version .659 but there I had the re-duplication issue. So I reverted to the latest public release .561. I had no issues, except for a small unduplicated files which did not actually exist (based on dpcmd).
Today I accidently log on and see no duplication at all while the "x2" flag is listed! See attached. I have Pool File Duplication set (x2). Standard balancers, everything default, no file placement rules. The only thing that may be non-default is that I have Balance immediately.
I do not know how long this situation has lasted already. I do know that because of it, my Server Backups are incomplete (I backup 3 of the 4 volumes).
I can not find .672 or .673 betas and given that I had reduplication issues with the .659 beta I am reluctant to try TBH. (http://community.covecube.com/index.php?/topic/1627-duplication-removed/page-2&do=findComment&comment=13380)
I remeasured and I get the same result.
Given that I am at .561, I can not do the dpcmd check-pool-fileparts but I can do a dpcmd get-duplication and if I do that on a file in the pool, it says expected and found copies: 1...
-
If you just remeber one three character set of a capital, a number and a special character and end all your long normal sentences with these you're all set.
Having said that, I do not disagree with OP.
-
Just bumping this up to check whether there is some sort of progress? As it is, I am using 4x2TB HDDs and using Server Backup to backup three of them to be sure I have a copy of everything (this is different from before when I had 2x2TB partitions on 1 4TB HDD). But it is less efficient then it could be. Also, I am still hoping we'll get to see grouping/strings someday.
On a side note, I could do a little SQL (or Excel/VBA) on output of dpcmd if that output could be delimited (e.g. pipe-delimited). I realise the output may appear not structured enough (text, numbers, varying lengths etc) but that can be solved/dealt with easily (have designed and programmed solutions to such issues in the past and would be willing to provide ideas).
-
I see. Still, if the advice is to periodically check the event log for issues like these,it is perhaps a nice service to have Scanner do it for you and present any messages. A notification that messages have been presented that may warrant inspection (and possibly adding priority flags for certain strings such as "controller X had an error on device Y" over time) might help users?
Ah yes, so much to do, so little time.
-
Ah, that actually brings me to a new feature request for Scanner: To scan the system log for "atapi", "disk" and "ntfs".

Drive Pool on WHS 2011 - Drive Order/Replacing Drives
in General
Posted
No problem at all. Just restart, it'll be fine.