I've recently started getting a bunch of dismounts on my google clouddrive (made in prerelease) - i've done a lot of troubleshooting, and reduced the threads, speed, prefetch etc etc.
Nothing worked, im still getting seemingly random dismounts between approx 6-7pm and 10pm (CET).
I've tested this, and it seems completely unrelated from drive usage, ive not had any dismounts outside this timeframe, even with a lot of traffic, and ive had dismounts with nothing but a single file being accessed.
I have since gotten a second domain (seperate account) and made a new drive, i'm now using drivepool to copy the drive, and notify me when the old drive gets dismounted.
I have also switched the old drive to my personal api keys, to watch the api calls and possibly confirm what sort error responces im getting.
the weird thing is, there seem to be basically none
(arrows are when it dismounted (retried mounting immediately after)
the log just states:
CloudDrive.Service.exe Warning 0 [IoManager:104] Error performing I/O operation on provider. Retrying. The read operation failed, see inner exception. 2017-11-12 18:18:21Z 24268242550
CloudDrive.Service.exe Warning 0 [IoManager:104] Error processing read request. Thread was being aborted. 2017-11-12 18:18:21Z 24268568126
(different timezone)
Im starting to suspect the only possible explanation is the ports/requests just outright being blocked, and not by google.
This is weird, since its on a server hosted by ovh (250/250 guaranteed) and ive never experienced any sort of blocking + they shouldnt be.
Is there any way i can confirm/disprove this theory?
And if anyone has some other suggestions for trying to resolve the issues, Please let me know!


Question
Jellepepe
Hi all,
I've recently started getting a bunch of dismounts on my google clouddrive (made in prerelease) - i've done a lot of troubleshooting, and reduced the threads, speed, prefetch etc etc.
Nothing worked, im still getting seemingly random dismounts between approx 6-7pm and 10pm (CET).
I've tested this, and it seems completely unrelated from drive usage, ive not had any dismounts outside this timeframe, even with a lot of traffic, and ive had dismounts with nothing but a single file being accessed.
I have since gotten a second domain (seperate account) and made a new drive, i'm now using drivepool to copy the drive, and notify me when the old drive gets dismounted.
I have also switched the old drive to my personal api keys, to watch the api calls and possibly confirm what sort error responces im getting.
the weird thing is, there seem to be basically none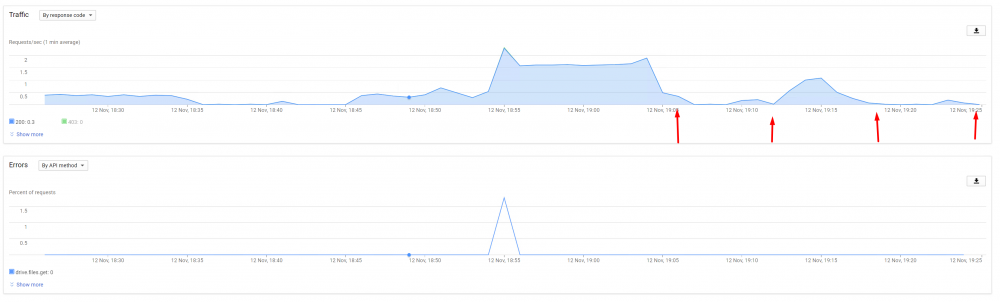
(arrows are when it dismounted (retried mounting immediately after)
the log just states:
CloudDrive.Service.exe Warning 0 [IoManager:104] Error performing I/O operation on provider. Retrying. The read operation failed, see inner exception. 2017-11-12 18:18:21Z 24268242550
CloudDrive.Service.exe Warning 0 [IoManager:104] Error processing read request. Thread was being aborted. 2017-11-12 18:18:21Z 24268568126
(different timezone)
Im starting to suspect the only possible explanation is the ports/requests just outright being blocked, and not by google.
This is weird, since its on a server hosted by ovh (250/250 guaranteed) and ive never experienced any sort of blocking + they shouldnt be.
Is there any way i can confirm/disprove this theory?
And if anyone has some other suggestions for trying to resolve the issues, Please let me know!
Thanks in advance,
Pepe
Link to comment
Share on other sites
38 answers to this question
Recommended Posts
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.