I'm using Windows Server 2016 TP5 (Upgraded from 2012R2 Datacenter..for containers....) and have been trying to convert my Storage Spaces to StableBit Pools. So far so good, but I'm having a bit of an issue with the Cloud Drive.
Current: - Use SSD Optimizer to write to one of the 8 SSDs (2x 240GB / 5x 64GB) and then offload to one of my harddisks ( 6x WD Red 3TB / 4x WD Red 4 TB). - I've set balancing to percentage (as the disks are different size)
- 1x 64GB SSD dedicated to Local Cache for Google Drive Mount (Unlimited size / specified 20TB)
Problem 1: I've set my Hyper-V folder to duplicate [3x] so I can keep 1 file on SSD, 1 on HDD and 1 on Cloud Drive... but it is loading from CLoud Drive only. This obviously doesn't work as it tries to stream the .vhd from the cloud.
Any way to have it read from the ssd/local disk, and just have the CloudDrive as backup?
Problem 2: Once the CacheDisk fills up everything slows down to a crowl..... any way I can have it fill up an HDD after the ssd so other transfers can continue? After which it re-balances that data off?
Problem 3:
During large file transfers the system becomes unresponsive, and at times even crashes. I've tried using Teracopy (which doesn't seem to fill the 'modified' RAM cache, but is only 20% slower... = less crashes.... but system still unresponsive.
Problem 4:
I'm having
I/O Error: Trouble downloading data from Google Drive.
I/O Error: Thread was being aborted.
The requested mime type change is forbidden (this error has occurred 101 times).
Causing the Google Drive uploads to halt from time to time. I found a solution on the forum (manually deleting the chunks that are stuck). But instead of deleting I moved them to the root, so they could be analysed later on (if neccesary).
Problem 5 / Question 1: I have Amazon Unlimited Cloud Drive, but it's still an experimental provider. I've tried it and had a lot of lockups/crashes and an average of 10mbits upload - so I removed it. Can I re-enable it once it exists experimental and allow the data from the Google Drive to be balanced out to Amazon Cloud Drive (essentially migrating/duplicating to the other cloud)?
Question 2: Does Google Drive require Upload Verification? Couldn't find any best practices/guidelines on the settings per provider.


Question
Mirabis
Hello,
I'm using Windows Server 2016 TP5 (Upgraded from 2012R2 Datacenter..for containers....) and have been trying to convert my Storage Spaces to StableBit Pools. So far so good, but I'm having a bit of an issue with the Cloud Drive.
Current:
- Use SSD Optimizer to write to one of the 8 SSDs (2x 240GB / 5x 64GB) and then offload to one of my harddisks ( 6x WD Red 3TB / 4x WD Red 4 TB).
- I've set balancing to percentage (as the disks are different size)
- 1x 64GB SSD dedicated to Local Cache for Google Drive Mount (Unlimited size / specified 20TB)
Problem 1:
I've set my Hyper-V folder to duplicate [3x] so I can keep 1 file on SSD, 1 on HDD and 1 on Cloud Drive... but it is loading from CLoud Drive only. This obviously doesn't work as it tries to stream the .vhd from the cloud.
Any way to have it read from the ssd/local disk, and just have the CloudDrive as backup?
Problem 2:
Once the CacheDisk fills up everything slows down to a crowl..... any way I can have it fill up an HDD after the ssd so other transfers can continue? After which it re-balances that data off?
Problem 3:
During large file transfers the system becomes unresponsive, and at times even crashes. I've tried using Teracopy (which doesn't seem to fill the 'modified' RAM cache, but is only 20% slower... = less crashes.... but system still unresponsive.
Problem 4:
I'm having
Causing the Google Drive uploads to halt from time to time. I found a solution on the forum (manually deleting the chunks that are stuck). But instead of deleting I moved them to the root, so they could be analysed later on (if neccesary).
Problem 5 / Question 1:
I have Amazon Unlimited Cloud Drive, but it's still an experimental provider. I've tried it and had a lot of lockups/crashes and an average of 10mbits upload - so I removed it. Can I re-enable it once it exists experimental and allow the data from the Google Drive to be balanced out to Amazon Cloud Drive (essentially migrating/duplicating to the other cloud)?
Question 2:
Does Google Drive require Upload Verification? Couldn't find any best practices/guidelines on the settings per provider.
Settings Screenshots:
- Balancing Settings:
https://gyazo.com/2cfe5c10e0f6fc45774a2e01d1a1f67a
- Balancers: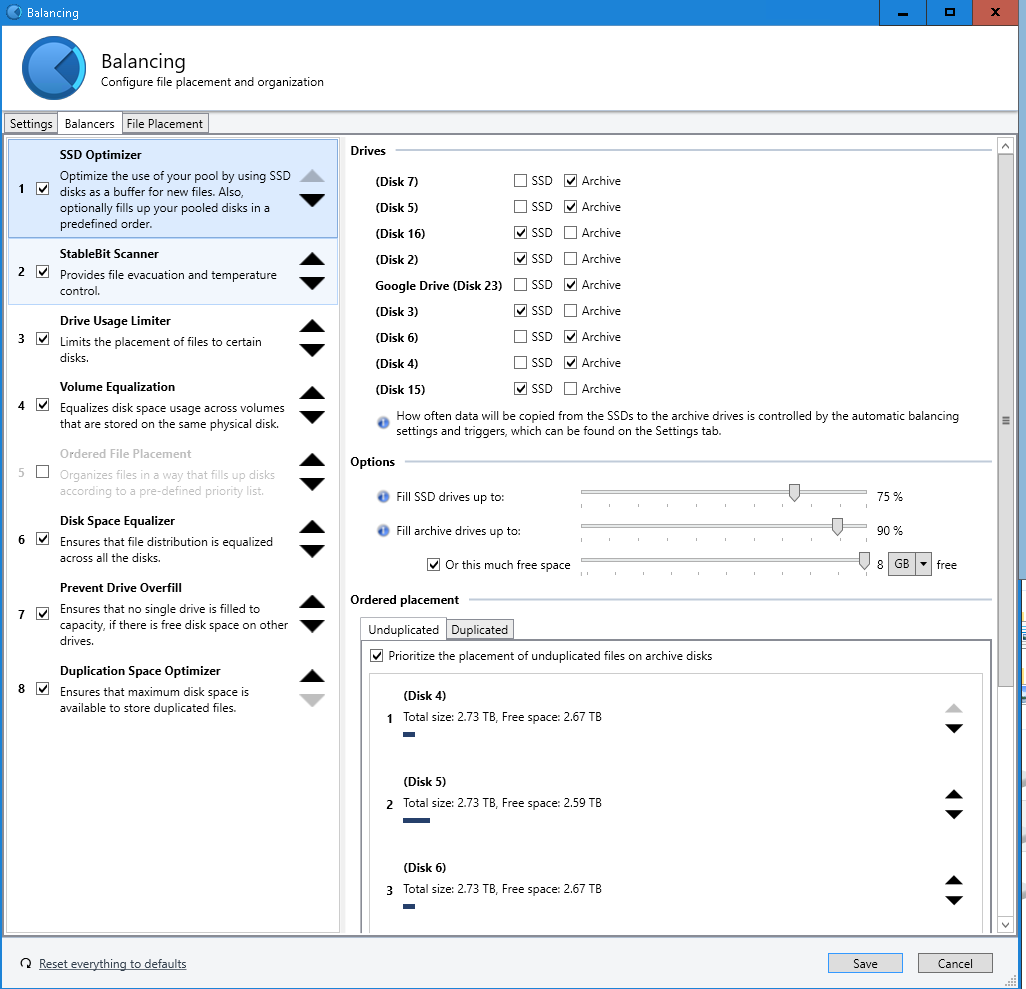
https://gyazo.com/1a72a73fe463238fe917806d7ea9ec0a
- File Placement: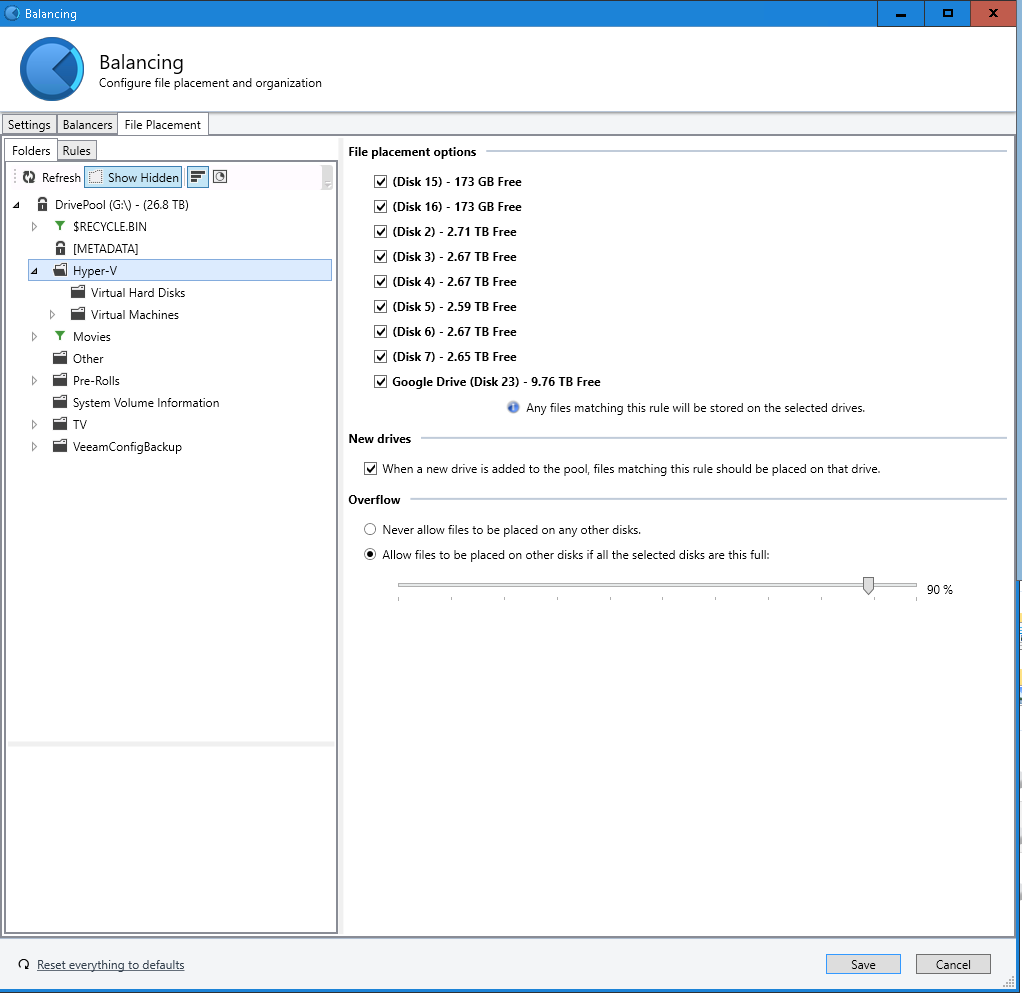
https://gyazo.com/f74187029ad0fe924fc6cd41fddfa519
- Folder Duplication:
https://gyazo.com/704c6264922c064ae7fae5b021ddb664
8 answers to this question
Recommended Posts
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.