Search the Community
Showing results for tags 'recovery'.
Found 6 results
-
This is almost certainly my own error, and part of the problem may be that I can't find the exact words to describe the problem. I have gradually been moving some local storage into the CloudDrive framework, because it's on a second networked machine, and I wanted to use DrivePool. I run 3 different DrivePools, and it's taken me a bit of organising and reorganising to get the right drives in the right pool. I think that's where things may have gone wrong. Situation: I have a physical HDD, mounted on its host machine as W:\. On my CloudDrive host machine, I have created a 4TB File Share Cloud Drive on the network share of that drive, named Cloud-SS-W. I have mounted that drive locally as C:\MountCloudW, so I can browse to it. CloudDrive says that Cloud-SS-W has 3.15TB 'Cloud used'. This makes sense to me, given the data that I believed was on it. When I browse to W:\ in the filesystem of the drive's host machine, it has 3.15TB of files in a StableBit Cloud Share Data folder. When I browse to C:\MountCloudW in the filesystem of the CloudDrive host machine, it says it has 4TB free, and no files beyond the Recycle Bin and System Volume Information system folders. How do I recover the files that have been chunked by CloudDrive, and are sitting in the Cloud Share Data folder? The attachment and metadata files are still there too, along with 32999 100MB part1-chunk-###.dat files
-
I recently had Scanner flag a disk as containing "unreadable" sectors. I went into the UI and ran the file scan utility to identify which files, if any, had been damaged by the 48 bad sectors Scanner had identified. Turns out all 48 sectors were part of the same (1) ~1.5GB video file, which had become corrupted. As Scanner spent the following hours scrubbing all over the platters of this fairly new WD RED spinner in an attempt to recover the data, it dawned on me that my injured file was part of a redundant pool, courtesy of DrivePool. Meaning, a perfectly good copy of the file was sitting 1 disk over. SO... Is Scanner not aware of this file? What is the best way to handle this manually if the file cannot be recovered? Should I manually delete the file and let DrivePool figure out the discrepancy and re-duplicate the file onto a healthy set of sectors on another drive in the pool? Should I overwrite the bad file with the good one??? IN A PERFECT WORLD, I WOULD LOVE TO SEE... Scanner identifies the bad sectors, checks to see if any files were damaged, and presents that information to the user. (currently i was alerted to possible issues, manually started a scan, was told there may be damaged files, manually started a file scan, then I was presented with the list of damaged files). At this point, the user can take action with a list of options which, in one way or another, allow the user to: Flag the sectors-in-question as bad so no future data is written to them (remapped). Automatically (with user authority) create a new copy of the damaged file(s) using a healthy copy found in the same pool. Attempt to recover the damaged file (with a warning that this could be a very lengthy operation) Thanks for your ears and some really great software. Would love to see what the developers and community think about this as I'm sure its been discussed before, but couldn't find anything relevant in the forums.
- 8 replies
-
- 4
-

-
- interoperability
- scanner
- (and 3 more)
-
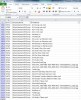
I've been seeing quite a few requests about knowing which files are on which drives in case of needing a recovery for unduplicated files. I know the dpcmd.exe has some functionality for listing all files and their locations, but I wanted something that I could "tweak" a little better to my needs, so I created a PowerShell script to get me exactly what I need. I decided on PowerShell, as it allows me to do just about ANYTHING I can imagine, given enough logic. Feel free to use this, or let me know if it would be more helpful "tweaked" a different way... Prerequisites: You gotta know PowerShell (or be interested in learning a little bit of it, anyway) All of your DrivePool drives need to be mounted as a path (I chose to mount all drives as C:\DrivePool\{disk name}) Details on how to mount your drives to folders can be found here: http://wiki.covecube.com/StableBit_DrivePool_Q4822624 Your computer must be able to run PowerShell scripts (I set my execution policy to 'RemoteSigned') I have this PowerShell script set to run each day at 3am, and it generates a .csv file that I can use to sort/filter all of the results. Need to know what files were on drive A? Done. Need to know which drives are holding all of the files in your Movies folder? Done. Your imagination is the limit. Here is a screenshot of the .CSV file it generates, showing the location of all of the files in a particular directory (as an example): Here is the code I used (it's also attached in the .zip file): # This saves the full listing of files in DrivePool $files = Get-ChildItem -Path C:\DrivePool -Recurse -Force | where {!$_.PsIsContainer} # This creates an empty table to store details of the files $filelist = @() # This goes through each file, and populates the table with the drive name, file name and directory name foreach ($file in $files) { $filelist += New-Object psobject -Property @{Drive=$(($file.DirectoryName).Substring(13,5));FileName=$($file.Name);DirectoryName=$(($file.DirectoryName).Substring(64))} } # This saves the table to a .csv file so it can be opened later on, sorted, filtered, etc. $filelist | Export-CSV F:\DPFileList.csv -NoTypeInformation Let me know if there is interest in this, if you have any questions on how to get this going on your system, or if you'd like any clarification of the above. Hope it helps! -Quinn gj80 has written a further improvement to this script: DPFileList.zip And B00ze has further improved the script (Win7 fixes): DrivePool-Generate-CSV-Log-V1.60.zip
- 50 replies
-
- 2
-
-

-
- powershell
- drivepool
- (and 3 more)
-
Story Short... I had 15TB of data to re-duplicate after multiple failures... Now im at 8TB left and need a "dedupliation tool" or just a list of some sort. I found this thread: Links to this: https://stablebit.com/Admin/IssueAnalysis/18743 Is it done yet? I want to prioritize my recovery process. Or at least se what files i will lose if i lose one more drive....
-
Hello guys, So, I came home from work today and found out that there was power in my area. I turned on my devices and my PC booted without any problem. After launching Clouddrive I got a message: "This drive is performing recovery" and "Recovering..." on bar, at the bottom. So... I had a local cache of about 50 GB and on RAID5 partition and clouddrive's reading data at 240 MB/s constantly. So far it read 3,54 TB and counting... can't see the end of it, it's still recovering and it got me nowhere close to mounting my drive. What can I do except waiting? It already took hours... Can't I just decide I don't care about local cache recovery (there was nothing important for sure) and just mount the drive without recovering? Chunks are still on my GDrive so, theoretically, drive should be fine.
-
I've read Drashna's post here: http://community.covecube.com/index.php?/topic/2596-drivepool-and-refs/&do=findComment&comment=17810 However I have a few questions about ReFS support, and DrivePool behavior in general: 1) If Integrity Streams are enabled on a DrivePooled ReFS partition and corruption occurs, doesn't the kernel emit an error when checksums don't match? 2) As I understand it, DrivePool automatically chooses the least busy disk to support read striping. Suppose an error occurs reading a file. Regardless of the underlying filesystem, would DrivePool automatically switch to another disk to attempt to read the same file? 3) Does DrivePool attempt to rewrite a good copy of a file that is corrupt? Thanks!