Salty
-
Posts
10 -
Joined
-
Last visited
Everything posted by Salty
-
Just wondering if there's a way to force a refresh of the Non-pooled drive list in DrivePool? I've created a new cloud drive, its present on E: and I can use the drive fine, I just can't add it to drive pool as it doesn't appear in the list. I've tried the latest stable and beta releases of DrivePool along with the latest beta of CloudDrive. Also tried offlining the disk in windows as well as detaching/reattaching through CloudDrive.
-
I have not had any luck getting the tRAID volumes added to a DrivePool pool. It gets to about 95% and then stops. A drivepool hidden folder is created on the volume but its never added to the pool. I have submitted a request for support to Alex and the team. At this time they have been able to reproduce the problem but this is not something that has been addressed. I also tried passing the tRAID volumes through to a Hyper-V virtual machine and installed DrivePool inside the guest VM. This works and the drives mount successfully. The problem I was having with this approach (other than the added complexity and the fact that Brahim has flat out said he won't support it) is that tRAID reports parity errors. Now I need to do some more testing on this because I assumed this was a tRAID / Hyper-V problem. When I reverted back to tRAID on the host only with tRAID pooling, I was still getting parity errors! Just haven't had time to sort this one out. Would be keen to see if anyone else gets a stable solution for this. Sorry to have blurred the lines here between DrivePool and tRAID but just wanted to let you know where I'm at with a working solution involving both tRAID and DrivePool. Cheers, Salty.
-
Ok cool, Shane's description is how I think it should work, I'm just not seeing the balancing taking place. Two feeder disks - Check Archive Balancer Plugin only - Check If I had to take a stab at this I would start by looking at how the drive ratios are calculated and the subsequent file move actions that occur based on the ratios. Particularly when non-pooled data is present on the feeder disks. I have some system data like Windows indexes that are on these feeder drives. A few other services like MySQL. All of these sit outside the PoolPart hidden folder, they are not pooled files but the total size for a rebalance may be affected. I'm not trying to tell people how to do their job here - this is outstanding work just offering friendly suggestions Ps. I tried to reflect the assemblies but didn't get very far with most of the core logic obfuscated Cheers, Matt.
-
Transient's description is accurate - the new tRAID feature still presents individual data disks. I'd like to get these into DrivePool for Disk pooling. FlexRAID's tRAID will give me parity. I'll endeavour to collect some log files of this tonight. Cheers, Matt.
-
The new tRAID engine hit RC5 so I thought I'd give it a go. I wanted to disable the native tRAID drive pooling in favour of stablebit - I prefer the way stablebit works and I would like to keep using its more robust balancing framework. The tRAID engine virtualises the harddrives so windows sees your original drives as offline and the new tRAID drives are what I would like to add to drivepool. When I click add, it sits at 95% for quite a while and then gives up. The drive's never added to the pool. So two quick questions: * Has anyone else tried tRAID with DrivePool - Can you confirm my results? * To Alex and the team - Is there any chance of this compatibility being addressed in the future if this is indeed a compatibility problem. Cheers, Matt.
-
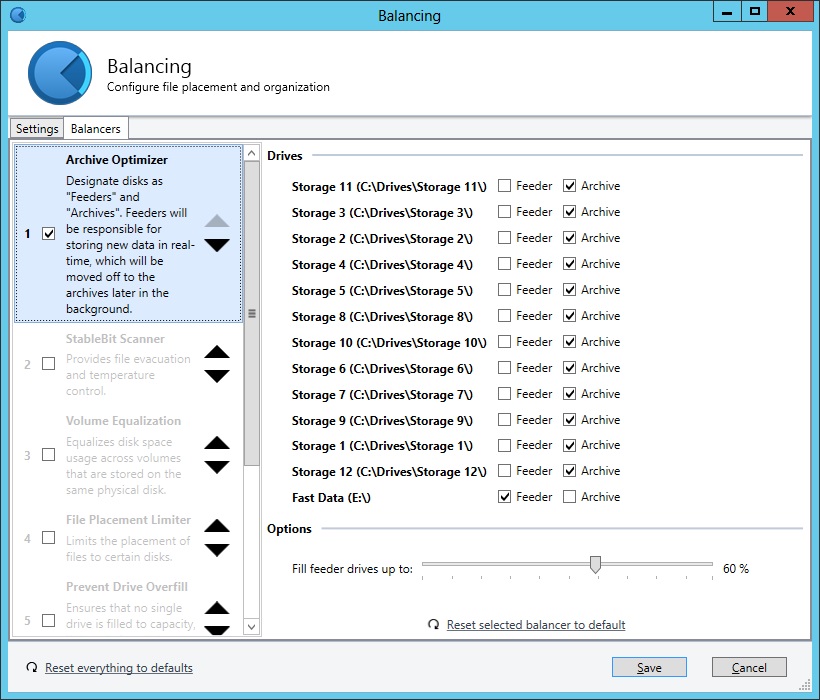
Would definitely like clarification if that's the expected behaviour of this plugin. My thoughts on this are: In the event I start writing a 40GB backup file to the pool, this should be initially written to the feeder disks (if the file is an unduplicated file, it will be written to a single feeder disk). If there is existing data on the feeder disks, its going to take longer if the existing data has to be written to a magnetic archive disk prior to accepting the new 40GB data file. My understanding is that whilst data remains on the feeder disks, the pool's health should remain lower than 100%. During the next balancing schedule, that data should be archived off to the designated archive disks. For me, the pool stays at 100% and the data is never archived. This has the undesired effect of once the feeder disks are full, all new data is written directly to archive disks. Hopefully we can get to the bottom of this
-
Unfortunately playing with the slider hasn't helped - i've logged a support ticket and will see what we can shake loose.
-
I moved all of the files that were stuck on the feeder disks to non-pool disks. Added a second feeder disk and did a full remeasure. Copied the files back into the pool and they correctly stored onto the feeder disks. It looks like some of the files were then moved from the feeders to archive but there's still about 45GB that remain on the feeders. Some files were destined for duplicated folders some were not. I tried another remeasure after this and the pool health returns to 100%. Not really sure what else I can try, any suggestions?
-
Hi all, I've been trying out the Archive Optimizer on my Drive Pool installation. I find that after a couple of hours the Feeder disk (SSD) becomes full. The pool remains in a 100% healthy state even though the bar graph beside the Feeder disk indicates that it has exceeded the limit. I guess the first thing is understanding what I expected the Archive Optimizer to do and if this actually aligns with its implementation. I would have expected that with Balancing settings configured to allow for immediate balancing, any data on the SSD Feeder disk would be scheduled for archive to the other disks in the pool. Furthermore, whilst unduplicated or duplicated data remains on the Feeder, the pool's health would be less than 100%. My pool's health remains at 100%. I do have some extra data on the drive outside of the Pool - Windows indexing database etc. I've tried a remeasure and trace logging. The only log entry is: "[Rebalance] Cannot balance. Requested critical only." Am I expecting this to do something that's not actually intended? Any configuration settings changes anyone can recommend that they find works well? Cheers, Salty. Edit: Running version 2.0.0.345 Beta, Server 2012.

-
Just wanted to weigh in on this discussion, interestingly for me my DrivePool instance is installed on a physical server which is also the Hyper-V host for around 8 VMs. I found Alex's correlation to the Hyper-V drivers interesting due to my use of Hyper-V on this host. I have always had Network IO boost enabled on this server and I would say that my BSODs occur far less than some of my colleagues - we didn't realise this correlation with Network IO boost but I'll be letting them all know tomorrow I'm not sure of the frequency for other people but I have only had 2 BSODs in the last 3 weeks which definitely produces a stack trace almost identical to the one described above. So from my perspective, the Network IO boost enabled hasn't eliminated this issue but may be reducing its frequency.