klepp0906
-
Posts
120 -
Joined
-
Last visited
-
Days Won
5
Everything posted by klepp0906
-
thank you for the reply. yes i was aware of the scanner settings/backup so thats covered. also dont use cloudrive (at least at current) so less of a concern. drivepool with the way balancers and plugins etc are set up though, really dont want to have any issue with that as i use snapraid and things need to be kept just-so when i make the swap. also curious how the backing up/syncing of settings works with stablebit.cloud. Since i have two licenses (bought an extra just in case) and the site says its designed to sync things between locations, perhaps adding a new pc will automatically pick up the settings that are in the cloud once i log in. just trying to gather more info. based on what youre saying they seem to store in %programdata% which is just as well. wondering if backing up then replacing before install would serve the same purpose. with a setup spanning 30 disks, one needs to think big picture/long term. Im even paranoid about how to handle it that wonderful day hopefully at least a decade down the road when my backplane decices its had enough and i need to get a new chassis and/or backplane lol. anyhow, digressing. perhaps someone who has done a migration between systems will come across this and speak up as to how it went.
-
So its about that time and I have two options im weighing as far as a new pc goes. 1) use macrium to restore a system image to the new pc (which would likely make this post moot for the most part) or 2) start fresh. I'm leaning towards 2 which means I have to back up important settings like the way I have drivepool/scanner configured. Are these things stored in %localappdata%? Is it is simple as placing the backed up files from the current pc in the proper location on the new pc then installing the suite? I know settings are saved in stablebit cloud which I pay for but things get janky as I intend to migrate my current pc into a secondary pc role. stablebit cloud seems to identify the pc based on its host-name and I intend (at some point) in the process of setting up the new one, to give it the hostname of the pc its replacing, and then change the hostname on that one to something different. Just trying to feel out what the safest way forward is. unsure if these things are stored in the registry, or several locations etc but this is something I want to be 100% on before i get my hands dirty.
-
so began to put this to task and even with the service stopped i cant rename the poolpart folder, any ideas? says its in use. so i stopped the scanner/clouddrive services as well to no avail. EDIT: nm found my way around it, dpcmd list-open-files showed me what was hanging it up. a folder therein being autopinned to windows explorer recents/navigation pane. never woulda found it otherwise lol i closed everything under the sun and then some.
-
thank you very much for the thorough answer. So it sounds like the gist of what I was hoping was gonna work is correct. Hopefully this will speed it up substantially. gonna find out today! I do point my snapraid conf to mount points, far too many disks at this point not to. (i have a problem) also do keep my .content files outside of the pools. though this whole "time" thing on the rebuild has me considering how i can alleviate any overhead I have. gonna exclude as much as i can with super small files for one, and the other bit is reducing the number of content files. I have one on each data disk (but i have 30 data disks lol).
-
So ive used snapraid + drivepool to great effect. However i just attempted to upgrade a drive by removing a disk from the pool (after disconnecting it) adding in the new one, and beginning a rebuild with snapraid. Would have worked but it was at 111 hours for the rebuild (for an 12TB > 18TB). Now a rebuild might be necessary if I had a failed disk. However I did not. I thought there must be a better way. Is it possible to 1) disconnect the current 12TB disk with data 2) remove it from drivepool 3) add the new 18TB disk so a poolpart folder is created 4) stop the service so it doesnt pick up the old disk and put it in an external dock 5) move all the data from the 12TB poolpart to the 18TB poolpart 6) restart drivepool and profit?
-
I dunno, i sure hope not. if it were EoL i hope it'd be made open source and someone picked it up lickity split. i depend on the stablebit suite in a pretty big way. to be fair, while support might be lacking I "think" i recall it being more of a "if you have an issue submit a ticket" thing and the forums are more of a user thing. and the stablebit cloud which is i no small thing was released and monetized recently so between that and the regular updates that are pushed to the software its definitely still being developed.
-
Yea, unraid was/is a non starter for me due to existing data and the filesystem difference etc. i have a few hundred TB and it would be all kinds of incomprehensible mess I dont have time for with kids. Now had i saw this whole data obsession/hobby thing becoming what it was.. i definitely would have taken a different path if i was starting from scratch but it is what it is. I will concur that the stablebit suite is without parallel windows side. its served me well for quite some time and I honestly hope it will serve me well until that fateful day hopefully some time a reaaaaally long time from now lol. I love it. that being said, the spindown issue is not inconsequential. when youre looking at a chassis with 30x7200rpm disks crammed within a half an inch of one another in an upstairs office spinning 24/7, the summer months prove a huge issue. I just cant run my air cold enough without making the rest of the house a fridge. Theres also the power savings however miniscule from letting them spin down. The age old argument surrounding which is the lesser evil for longevity etc. i know until i began using drivepool, i always had my drives spin down and would still be doing so if i were able.
-
yea this was discussed previously and i'd tried it in the past, does not work for me either. just edited both json and restarted. set my spindown to 1m. drives keep on spinning away. only time i can get them to spindown is stopping the service(s) entirely.
-
i gave up and just set mine to always spin. watching and waiting for a viable solution though. glad you pegged what was doing the polling. will have to wait for staff to respond as far as why goes.
-
perfect! thank you. exactly what i was hoping to hear
-
So i'm about to build a new pc.. which moves the current pc down the line to the backup pc. It got me thinking, if I wanted to access one of the pools over the network and access it from another machine, would it see it as a shared drive and be able to access it? AKA i enable my P: (plex pool) to be shared over the network. I browse to my main pc from my backup pc. would it see P: as a regular ole shared drive or would that require drivepool to be installed on both machines or would it simply not work at all or?
-
Figured it out. in smart health it lets you ignore the warning and will re-present if you so choose upon it getting worse. AKA more reallocated sectors in this case which is absolutely perfect. You guys thought of damn near everything.
-
Just curious how I dismiss it? I intend to run this drive in the array a bit longer and I'd prefer to be able to do so without the notification showing for that particular drive in perpetuity. I certainly dont want to disable scanning or error notifications blanket-style, just the tray icon/notification so i'll keep it and my ocd will deal if thats the only avenue to making it disappear. I have a new drive on the way so it'll be here when needed and plan to keep an eye on the newly discovered 8 reallocated sectors for now. If they start going up in any fashion in any short timeframe ill do the swap at that point. Also worth mentioning (perhaps as a small bug report) that upon clicking the tray icon, you get the windows notification flyout. upon clicking that, you get the prompt to open stablebit scanner, or close, or check the never warn me box etc. Upon clicking open stablebit scanner, it does not open stablebit scanner I had to open it through the start menu.
-
think i answered my own question based on this, its expected behavior i guess. to my chagrin. anything over 16tb and youre getting 8k and as such losing the compression option https://support.microsoft.com/en-us/topic/default-cluster-size-for-ntfs-fat-and-exfat-9772e6f1-e31a-00d7-e18f-73169155af95
-
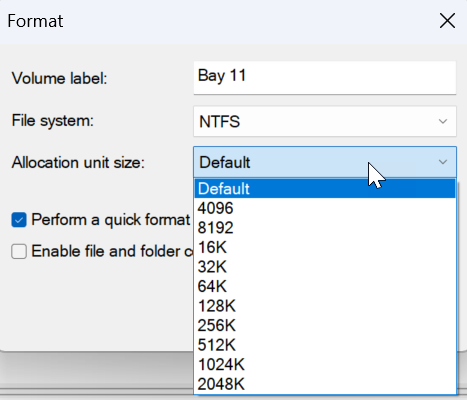
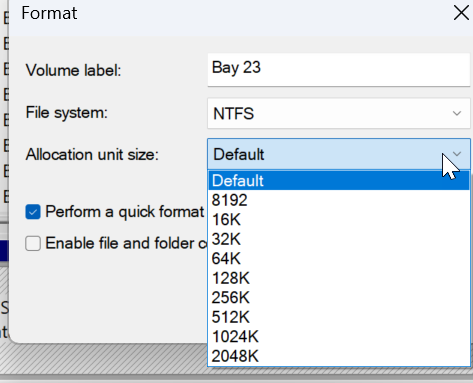
okay, so with some digging it turns out ALL of my new 18TB exos were formatted the same way as the rest of my drives. simple GUI via disk management in windows. setting the allocation unit size to default. this always resulted in 4096/4k clusters. apparently windows sets 8k for drives over a certain size.. or.. something? because these were all set to that as the default, and i tried a dry run format and opening the dialogue doesnt even present 4k as an option. now assuming I wanted to back up 20TB of data then move it back again... how would one (if one could) make 4k cluster size if the GUI doesnt allow it? Would/could you do it in diskpart? Why is it not accepted outside of command line? My 2nd largest drives are 12TB and and 4k all is possible and was set to default there. so somewhere between 12 & 18 for whatever reason its not a thing? trying to understand if i have an issue and something went awry or if this is expected/normal behavior? If its the latter I can leave it, if it is not.. its likely ill have to spend days transferring data around and reformat the things via whatever avenue will afford me the ability to get a 4k cluster size if its possible. even outside of the shown T pool (2 18tbs) I also have 2 more 18TB disks which are parity drives. No pooling and nothing on them except a parity file each. Those too are set to 8k cluster by default with no option for 4k. what does it all mean? all drives but the 18tb'ers all the 18tb disks
-
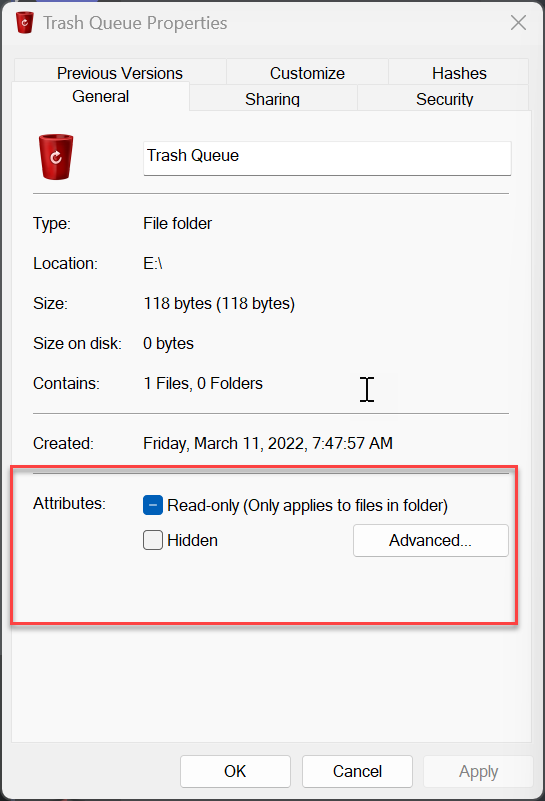
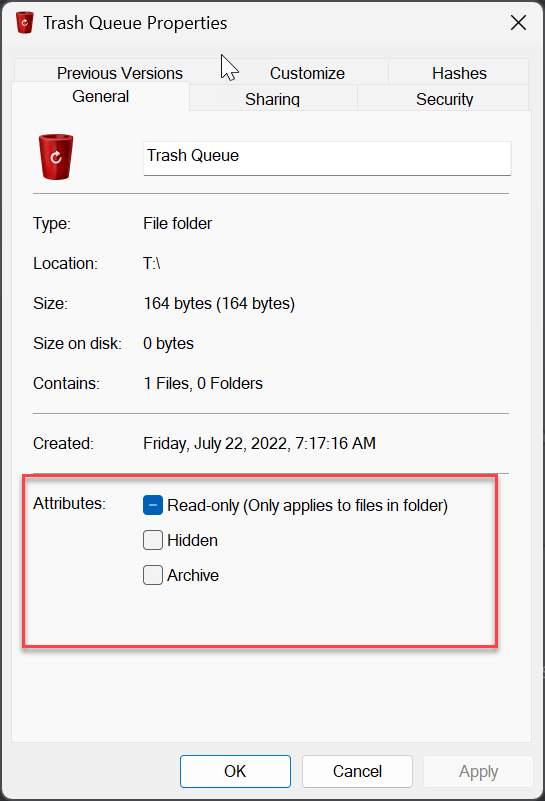
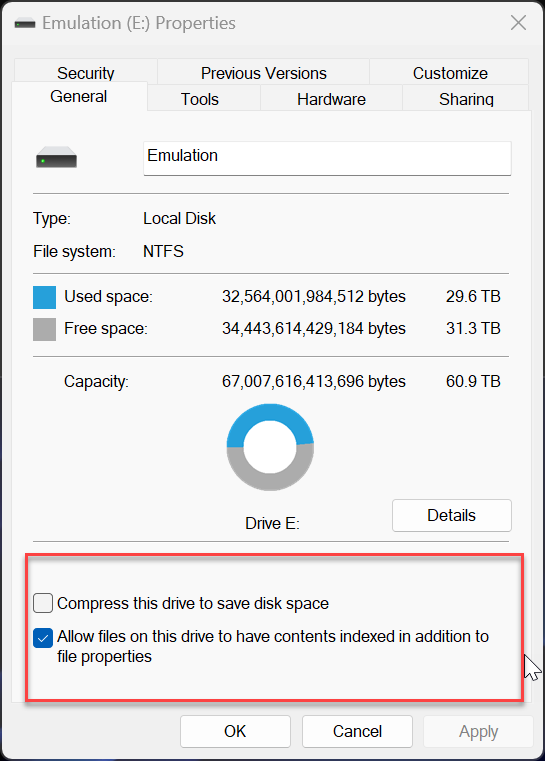
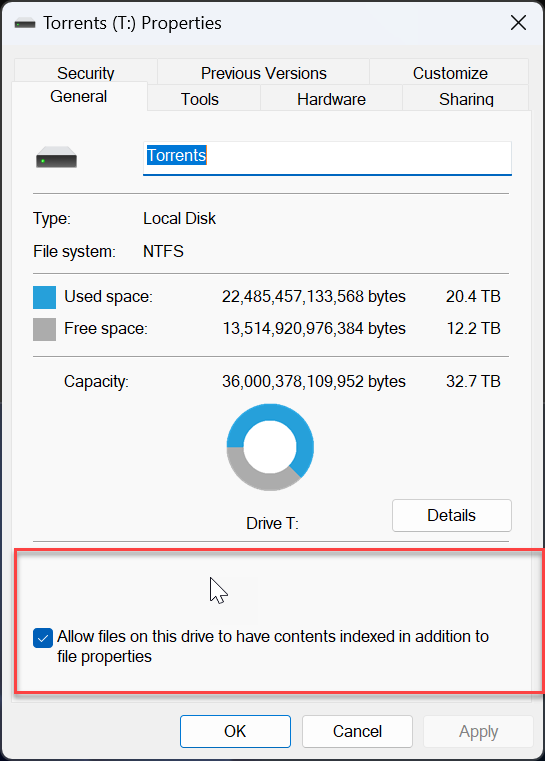
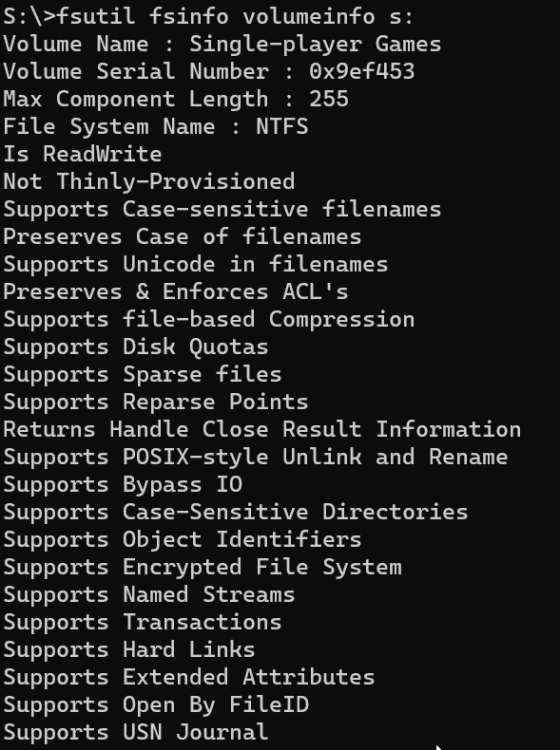
I use drivepool and have had no major issues until this oddity cropped up. All my non pooled drives seem to support file-based compression fine. all my pools have supported it fine as well (until now) but i recently purchased 2 seagate exos 18tb and made another pool. for some reason the new pool with the 18tb exos do not support file based compression. checked with fsutil and checked via right click > properties on folders therein. I'm unsure if this is something expected from enterprise drives or? (all my others are non enterprise). The file system is NTFS so no idea what is going on. Anyone have anything for me? non pooled drive pool with compression working pool with compression working pool with compression not working results in this on the drives and pools working properly (aka all but my T: pool) and this on the problem child
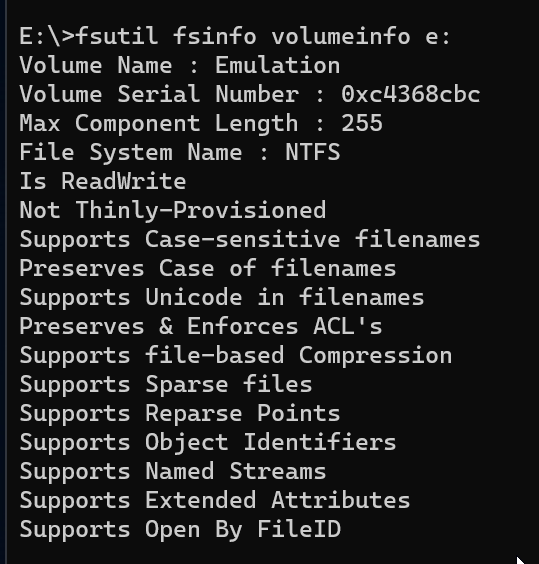
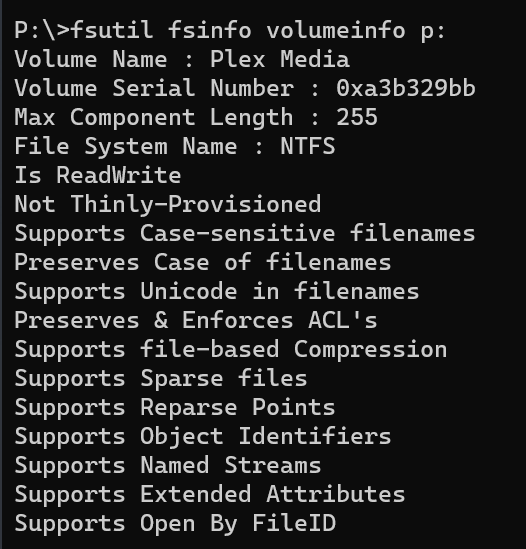
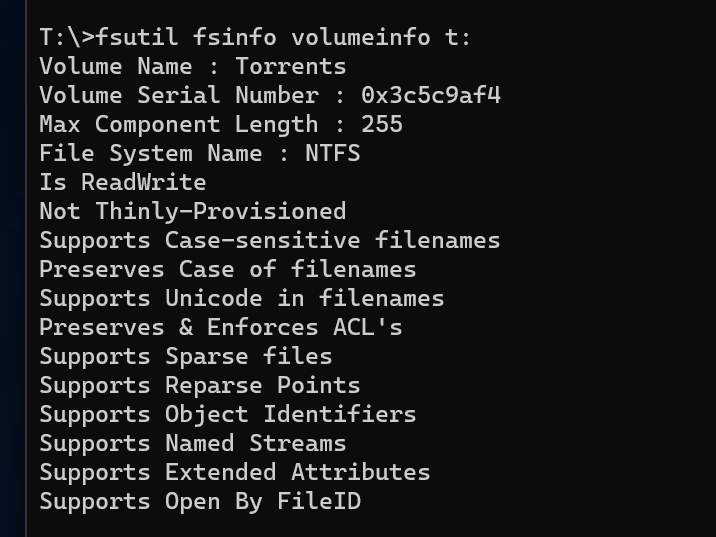
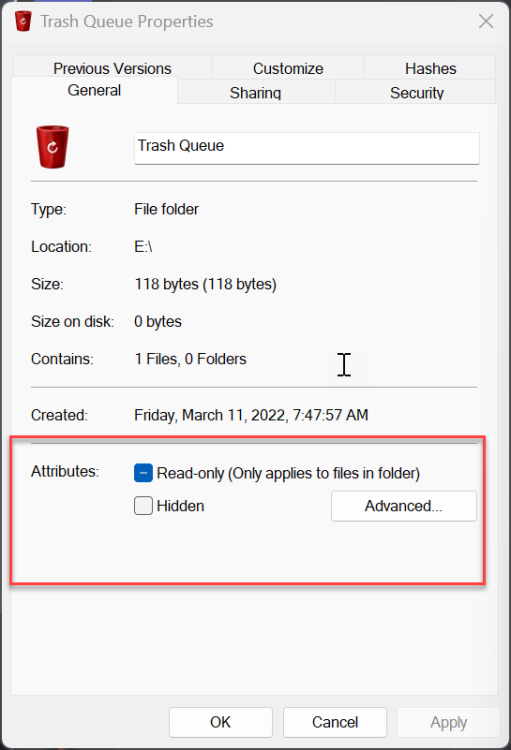
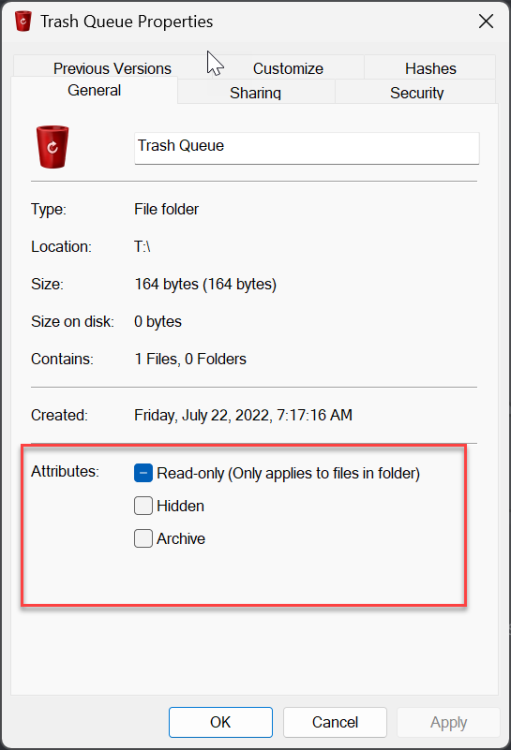
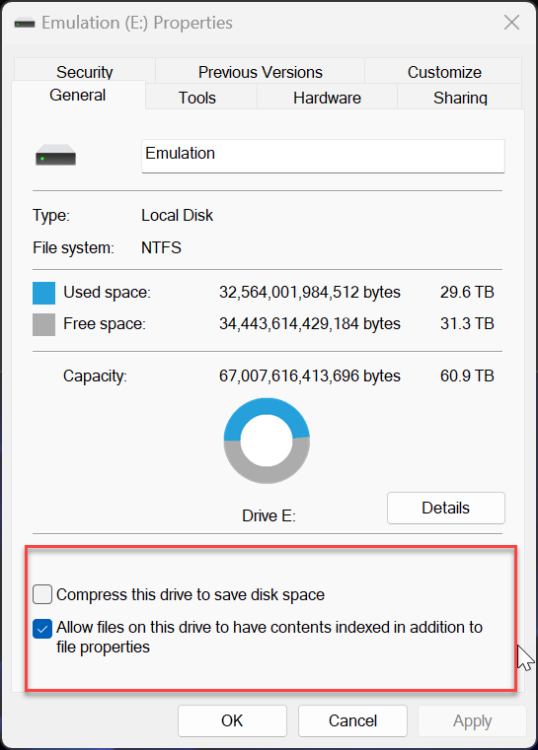
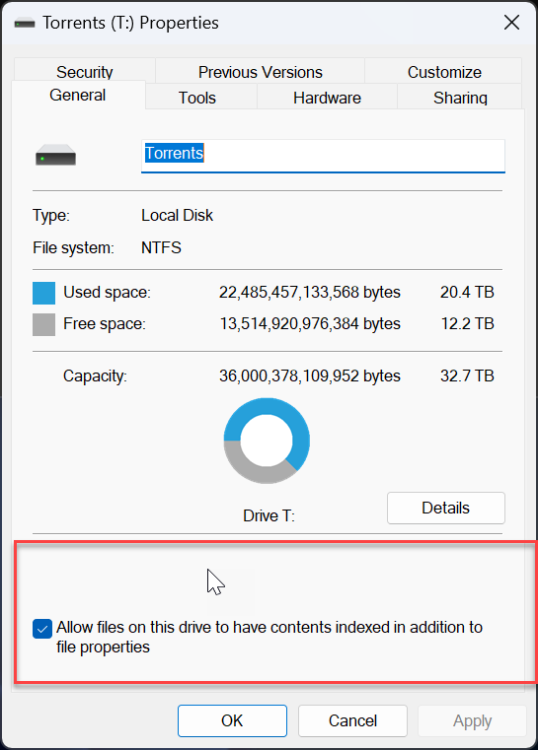
-
But why was it not present before? The data on that pool has been unchanged apart from a few MB for a loooong time. Moreso why is there duplicated “metadata” showing on that pool but not the other pool which holds roughly just as many tb and the same number of disks etc? thanks for the reply regardless <3
-
I have 2 pools. Neither uses any type of duplication. Both are the same size, both are made up of the same number of drives. my plex media pool shows Unduplicated and Other my emulation pool shows Unduplicated and Other AND Duplicated even though I have it disabled. it's only 454 kb worth so its not like im losing meaningful space. i still want to know how i can tell what is being duplicated and why and make that not the case. it wasnt like this last i checked but I did just restore a macrium image from this morning, unsure if that mucked something up somehow or if this automagically happened at some point along the way and I'm just now noticing. ill take any insight i can get.
-
So this is my first rodeo with any drive pooling solution, and with snapraid, and with an external chassis. i've been sort of learning as i go. In my time with the new setup/config ive upgrade and replaced several drives. I've been taking the ones that were just upgrades and bagging em with the power on days and date of purchase and taking the ones i replaced due to age and/or errors and adding the error count to the former info. what I have not been doing (perhaps unfortunately?) is formatting them before I pull them. meaning the ones that were simply size upgrades but had lower power on hours and no errors I could potentially use as replacements for failures down the road. backups if you will. I also have some very small drives (2tb) that have no errors I could take one of my cold 10 or 12tb and decide to add in for more space at any point. the problem is those drives I pulled that are otherwise good, have existing poolpart folders. its my understanding those will be picked up by drivepool the minute I connect them to the pc? this would result in data being added to the pool that is redundant with what is on the drive that it was replaced by. I have no idea what the consequence of this would be? files with something appended? overwrites? errors? how would i avoid this or remedy whatever havoc it would wreak? Is my only option should I decide to use one of them again either A) connect it in another pc to erase it first or b) connect it to my main pc but disable the drivepool service when I do until I format it? Just looking for some insight so when that day inevitably comes I know what I'm getting into ahead of time.
-
well, that will only half present an issue I guess. worst case id have to do some shuffling to and fro. moving bash scripts off the pool is easy, unfortunately most data i use bash scripts against is also on the pool. i suppose we'll see what comes first, an unrelenting need to use those scripts or the means and implementation from the stablebit side. time will tell
-
worst developers ever! joking aside, what does that mean exactly? i assume when using WSL it will only present an issue if you try to access a virtual disk/pool? anything else will be business as usual? i still havent re-installed WSL after moving to 11 but its on my shortlist. trying to know what im getting into because moving away from drivepool certainly wont be an option. if i just have to move some bash scripts off my pool to a standalone disk or something, I can live with that.
-
so...is WSL support in now? i cant quite tell via the banter here but i know i was just checking out the most recent beta patch notes and it says no support up top... does no support mean no support or does it mean does not work? or is that old info that hasnt been whittled from the changelog template? :P
-
Hey, good suggestion. I did find that it was incredibly hot. Holy smokes. I’ve long since added kryonaut TIM and mounted a noctua to it though lol. that being said, after a whole slew of drive replacement, recreation of the pools, chkdsks, permissions resets, basically everything I could throw at it. so far so good lol
-
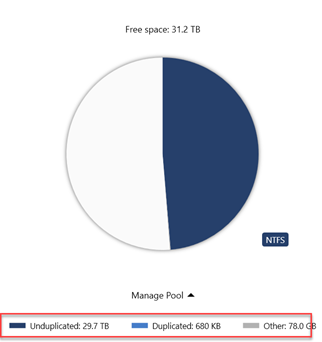
So I'm trying to ascertain what is going on with one of my pools. It seems to be functioning more or less, but relative to my other pool which is in the same chassis, made up of largely the same drives, connected via the same means to the same controller, its behaving differently in a few ways. 1) it re-measures on every restart 2) it displays as having 0 "duplicated" now my line of thinking is that somehow 2 is tied to 1. I do not enable duplication but metadata is set to 3x by default. this (i assume) accounts for the 680kb worth of "duplicated" on my 1st pool which also does not re-measure on every restart. my second pool has 0 duplicated showing and as such I can only deduce it has no metadata stored so its not duplicating it. I'm unsure if this is... possible? as im not wholly familiar with which metadata drivepool stores or uses. basically curious if anyones pool looks like this screenshot? or they all look like this? If the former exists for anyone, is it presenting any issue like re-measuring after restarts? Outside of the constant re-measuring which I already know is incorrect, I also want to know if the apparent lack of metadata on my pool is abnormal and try to rectify it before I reformat my pc as i'd like to start problem free.
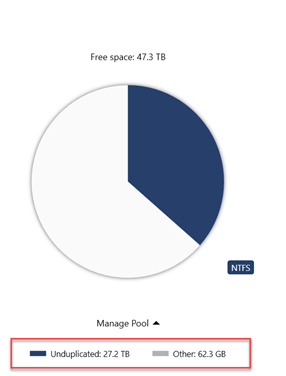
-
yea im fairly novice myself. still working my way through trying to get everything functioning in the way i prefer. mostly there but a few crucial things evading me. namely the inability to get drives to spin down whatsoever and a constant remeasuring on restart of my pool. other than that im ready for the long haul. i did try to disable scanner services entirely as well as clouddrive services entirely. neither had any effect on my drives sleeping. The minute i killed the drivepool service they immediately started spinning down though so its exclusively drivepool and drivepool alone.