Search the Community
Showing results for tags 'metadata'.
Found 3 results
-
I have been troubleshooting an issue with erratic timestamps when attempting to backup my pool using Bvckup2. Due to timestamps being different between the backup source and backup destination, files are needlessly copied, even though they are actually the same. Only a small percentage of files in my pool are affected, but some are huge (>50 GB) so this eats up backup disk space quickly. For some of these files, timestamps are incorrect but consistent. For other files, the timestamps change almost every time the file is accessed/queried. The Bvckup2 thread below contains all of my troubleshooting information so far, and a potentially related DrivePool bug thread is listed below. Bvckup2 Form Thread: https://bvckup2.com/support/forum/topic/1274 File Watch/Timestamps Unavailable:
-
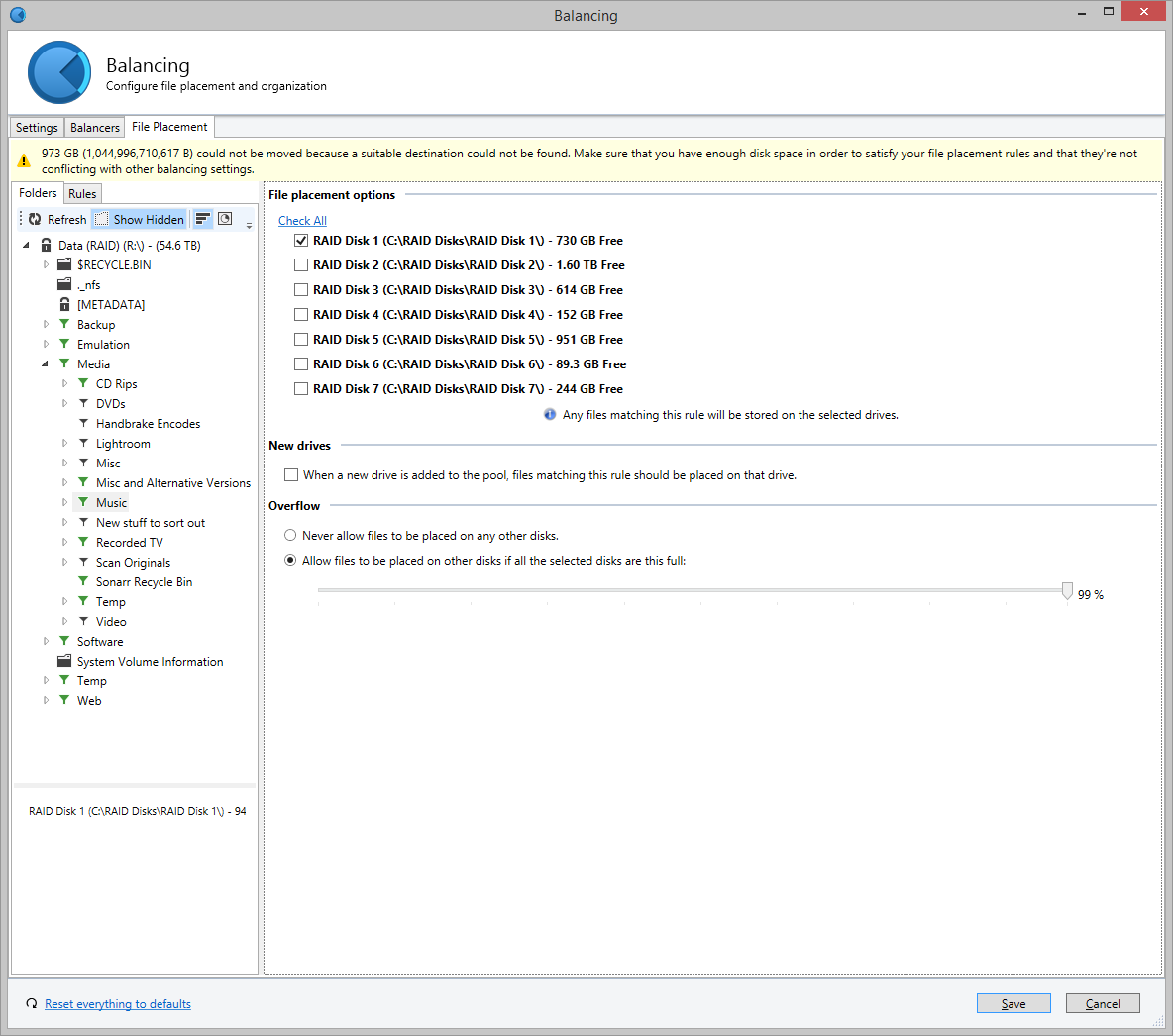
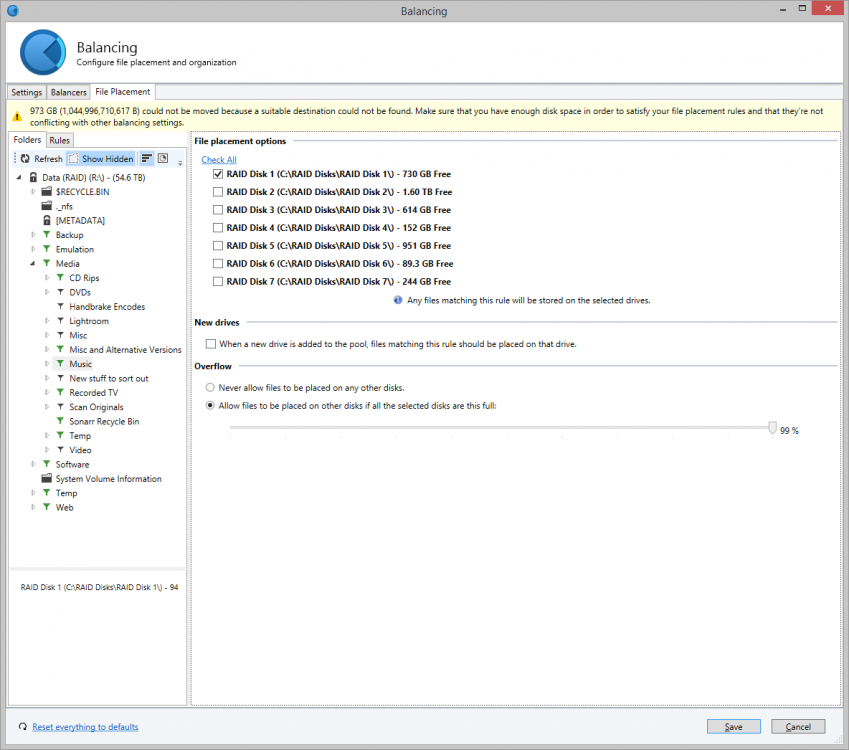
Hi there I've been using Drivepool for a couple of years now and it's been really stable and has generally great. However, I have noticed an issue over the past few months in relation to file watches. Specifically, in relation to Subsonic server that is running on my machine. The scenario is as follows: I have 7 data disks in my pool and most of my music collection is placed only on disk 1, as per a file-placement rule (see attached screenshot). Subsonic (which is a Java application) has code that keeps a watch on the filesystem so that when new music files are added into my music folder, it will automatically detect it, scan the files and add to my music libary. This was working fine, but I noticed that sometimes the files were never detected, even after I forced a scan. Long story short - because disk 1 was getting full, some music files were being placed onto disks 2 and 3 when I copied them to my pool drive. Subsonic a) didn't notice the new files and b) would not recognise the files as new even when I forced a scan. Now, my assumption was that the software used NTFS file watches to detect new files, but that doesn't explain why files are not detected on a forced scan, which I believe from looking at the code is based on file/folder last modified timestamps. If I manually move the music files from disks 2 or 3 on to disk 1, or clear up space so that the file placement rules move the files when I re-balance, then Subsonic detects the files. My hypothesis is that Drivepool isn't properly reporting timestamps or filewatch system events when files are placed on to disks that are not the one(s) chosen in file placement rules. It's taken months to work this out and I spent ages on the Subsonic forums (and talking to its developer) because I assumed that it was a problem with Subsonic. I've now conclusively (and repeatably) shown this is a Drivepool issue. Thanks, Steve. PS: I'm running Windows Server 2012R2 with all the latest updates. I have no AV installed at the moment (I got rid of it while testing this, just in case). I also use Snapraid for parity across my Drivepool disks, not that I expect that makes any difference!
-
I have 10TB expandable drive hosted on Google Drive with a 2TB cache. Whenever I add a large amount of data to the drive (for example I added 1TB yesterday) CloudDrive will occasionally stop all read and write operations to do "metadata pinning". This prevents Plex from doing anything while it does its thing, and took over 3 hours to do yesterday. I don't want to disable metadata pinning, but I would like to be able to schedule it, if necessary, for 3AM or something like that. In the meantime, is there a drawback to having such a large local cache? Would it improve operations like metadata pinning and crash recovery if I decreased it?