


Bowsa
-
Posts
61 -
Joined
-
Last visited
Posts posted by Bowsa
-
-
I use DrivePool for two pools
Pool 1 - Physical HDDS
* x3 8TB HDDS
* x2 500 GB SSDs as Balancer
Pool 2 - CloudDrives
*x2 StableBit Cloud VHDDs that form a singular drive letter
Now, I restarted a few times to install a new SSD. But my program seems to be detecting the pools, because it shows the "non-pooled" drives. But even then, my drives aren't present in the application or windows explorer.
-
On 12/17/2019 at 2:42 AM, srcrist said:
I mean...you could stop using it, if it loses your data...or at least contact support to see if you can get your issue fixed...
Contacted them... is anyone else getting this error? Has occurred more than 20 times now, where the chunk is unavailable both in my local and duplicate drive.
All that data lost...
-
On 12/15/2019 at 11:47 AM, srcrist said:
Self-healing refers to the structure of the drive on your storage, not your local files or even the files stored on the drive. It simply means that it will use the duplicated data to repair corrupt chunks when it finds them.
Have you submitted a ticket to support? I haven't heard of data loss issues even among those who aren't using data duplication in about 6 months. The self-healing works, in any case. I've seen it show up in the logs once or twice.
Haven't submitted a ticket, I'm used to suffering data loss at least 2-5 time a year with StableBit cloud. Nothing I can do about it
-
It doesn't work. I've still suffered data loss multiple times with this enabled...
-
Is there an actual purpose to pinning? For all intents and purposes it should behave as responsive as any other file, until you need to access said file.
But most of the time, accessing the drive or certain folders freezes Windows Explorer for a few seconds. Isn't pinning supposed to prevent this?
-
On 6/12/2019 at 4:45 PM, Christopher (Drashna) said:
Sorry for the absence.
To clarify some things here.
During the Google Drive outages, it looks like their failover is returning stale/out of date data. Since it has a valid checksum, it's not corrupted, itself. But it's no longer valid, and corrupts the file system.
This ... is unusual, for a number of reasons, and we've only see this issue with Google Drive. Other providers have handled failover/outages in a way that hasn't caused this issue. So, this issue is provider side, unexpected behavior.
That said, we have a new beta version out that should better handle this situation, and prevent the corruption from happening in the future.
http://dl.covecube.com/CloudDriveWindows/beta/download/StableBit.CloudDrive_1.1.1.1114_x64_BETA.exeThis does not fix existing disks, but should prevent this from happening in the future.
Unfortunately, we're not 100% certain that this is the exact cause. and it won't be possible to test until another outage occurs.
Just noticed I have missing data again... and I’ve been on the duplication beta for weeks
-
2 hours ago, srcrist said:
Because on March 13th Google had some sort of service disruption, and whatever their solution was to that problem appears to have modified some of the data on their service. So any drive that existed before March 13th appears to have some risk of having been corrupted. Nobody knows why, and Google obviously isn't talking about what they did. My best guess is that they rolled some amount of data back to a prior state, which would corrupt the drive if some chunks were a version from mid-February while others were a newer version from March--assuming the data was modified during that time.
But ultimately nobody can answer this question. Nobody seems to know exactly what happened--except for Google. And they aren't talking about it.
No amount of detaching and reattaching a drive, or changing the settings in CloudDrive, is going to change how the data exists on Google's severs or protect you from anything that Google does that might corrupt that data in the future. It's simply one of the risks of using cloud storage. All anyone here can do is tell you what steps can be taken to try and recover whatever data still exists.
And "RAW" is just Windows' way of telling you that the file system is corrupt. RAW just means "I can't read this file system data correctly." Raw isn't actually a specific file system type. It's simply telling you that its broken. Why it's broken is something we don't seem to have a clear answer for. We just know nothing was broken before March 13th, and then people have had problems since. Drives that i have created since March 13th have also not had issues.
This happened this month, not in march
-
15 hours ago, Digmarx said:
So I had just managed to reupload the 10 or so TB of data to my google cloud drive, and once again I'm getting the file system damaged warning from stablebit.
Files are accessible, but chkdsk errors out and the unmount, unpin, clear cache, remount process has no effect.
I can't even fix my drive with CHKDSK, because I get an error no one seems to know how to solve. 12 TB of Data.....
-
22 hours ago, srcrist said:
Chkdsk can never do more harm than good. If it recovered your files to a Lost.dir or the data is corrupted than the data was unrecoverable. Chkdsk restores your file system to stability, even at the cost of discarding corrupt data. Nothing can magically restore corrupt data to an uncorrupt state. The alternative, not using chkdsk, just means you would continue to corrupt additional data by working with an unhealthy volume.
Chkdsk may restore files depending on what is wrong with the volume, but it's never guaranteed. No tool can work miracles. If the volume is damaged enough, nothing can repair it from RAW to NTFS. You'll have to use file recovery or start over.
How does a Virtual Volume even get damaged? It makes no sense to me. I had the drive running normally, no power outages, and upload verification was on.
So why does StableBit connecting 200 times (user-rate limit exceeded) cause a drive to even become RAW in the first place, what's the point of Upload Verification? In some software it can still detect the drive as NTFS, but it still makes no sense. It's a virtual drive reliant on Chunks (that should be safe due to upload verification). I detached the drive, and mounted it again, and the Drive was still RAW.
How do chunks even become RAW in the first place, it's like mounting the drive on another computer and it being raw too.
-
On 5/16/2019 at 9:16 PM, Christopher (Drashna) said:
CHKDSK may do this, if the damage isn't too severe.
Otherwise, it's disk recovery tools like Recuva or TestDisk.
Nope. Chkdsk totally scrambled all my files into video142.mkv, so recovering 12TB is as good as useless. CHKDSK did more harm than good
-
-
3 hours ago, steffenmand said:
Recuva can recover it. It takes time, but most if not all should be recoverable
I think it's just a matter of Recovering the Partition Table. I ran TestDisk, and it reports the drive as "NTFS", and more additional information, but it gets stuck on the "analyze" part. I'm sure that if I can find reliable software to recover the table, I should be back in business.
-
Pertinent Information:
I had a major data loss weeks ago when Google had their downtime and made sure not to repeat the same mistake by enabling upload verification. I noticed the other day that Google was having issues, and the CloudUI reported the error more than 250 times.Today I checked and saw that a huge chunk of my are missing. I saw that my Cloud "Pool" was still working and there were a number of files, but then I had the intuition that this wasn't normal data loss like last time; it was isolated to one of the disks in the pool.
Pool Setup: Initially I had a 10TB Drive that had filled up, and to enlarge it, I went through the steps in the UI and it created another partition instead of enlarging the existing one. I pooled these two together to have them under the same Name and Drive Letter for organization purposes. In addition, I removed drive letters for the "pool drives" to prevent clutter.
Keeping the above in mind, I checked DrivePool, and it confirmed that the first Drive was "missing" and checking in Disk Management, the Drive is marked as "RAW". The first thing I did was follow these steps:It doesn't seem to have done anything, as the drive is still RAW. I also assigned a Drive Letter to the problem disk, and ran "CHKDSK /f". It deleted index entries, and didn't complete due to "insufficient disk space to insert the index entry" it also placed unindexed files in "lost and found".
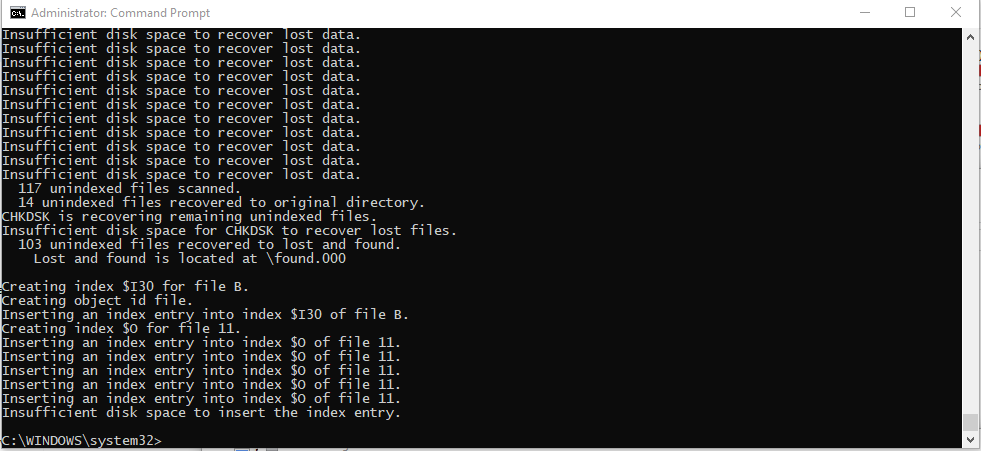
I need some advice on how to go forward with this, I don't want to lose 10 TBs of Data again. What can I do to recover my data?
Should I detach the disk, and reattach it?
-
Ok, but how do you convert the disk from RAW back to NTFS...?
-
5 hours ago, Christopher (Drashna) said:
Do you have multiple drives attached to this account?
Also, are you accessing this account anywhere else?
Both count against the limit.
No I have 2 accounts, with its respective drive. Everything is uploaded now, but I have no idea what could've caused this to happen in the first place. Maybe it was my upload/download threads that caused it?
-
I have automations set-up for the management of my media, and noticed in Plex that a few media articles were showing up "blank". Upon investigating CloudDrive, I noticed that it was being throttled and that it triggered the User-rate limit 252 times! I inspected my download history, and I've only downloaded 100GB this entire month, so I know for a fact it's not throttled due to the daily upload limit.
Does anyone know what might have caused this?
Is it possible Data got unpinned, and that Plex accessing it again messed things up due to the API calls?
-
2 hours ago, srcrist said:
You'll need to use the CreateDrive_AllowCacheOnDrivePool setting in the advanced settings to enable this functionality. See this wiki page for more information. The cache being full will not limit your upload, only your copy speed. It will throttle transfers to the speed of your upstream bandwidth, so it should make effectively no difference, aside from the fact that you won't be able to copy new data into the drive faster. That data will still upload at the same rate either way.
It does make a difference, CloudDrive doesn't start uploading at full speed until a certain amount of data is copied/cached, so having to go through the process for every 400GB isn't ideal.
-
-
6 hours ago, steffenmand said:
Just remember your hard upload max of 750 GB /day at GDrive. So if upload is your concern, you won't be able to do more on a single account pr. day
Fortunately, I'm not subject to this upload max of 750 GB a day...so the point still stands
-
3 hours ago, steffenmand said:
My guess is that you have the same "issue" as me where the response times pr. download thread is long, causing the time pr. thread to increase and thus slowing down speeds.
As GDrive works with maximum 20 MB chunks, it has to request a chunk and await the reply from google. in my case this takes 2300-2800 ms pr. chunk.
You can see details under "Technical details" (Found top right on the settings wheel) and then select your drive. Details are shown in the bottom.
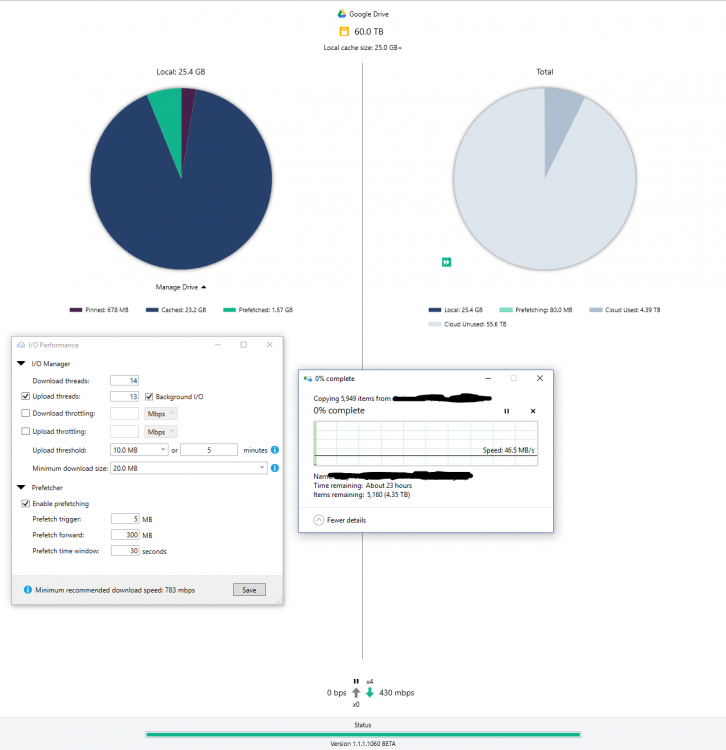
I have requested 100 MB chunks for GDrive with a minimum required download size of 20 MB or more to help speed it up for us high-speed users.
Thing is, if I set the Minimum DL to like 40 MB, enable 18 threads, and 3000 MB of pre-fetch, I get 600-700 Mbps
-
On 4/29/2019 at 7:11 PM, Christopher (Drashna) said:
You could use the File Placement rules to limit where the software places the new files.
This way, you can make sure that the files end up on a specific disk. That may help with this.
Otherwise, personally, I use a dedicated drive for temp storage, and only import completed files to the pool.
I sorta have that enabled, my SSD drive is my "intermediary" folder, but when it extracts, it extracts to the Pool. How do you limit it to completed files only>
-
I have 1000/1000, and regularly get download speeds of 950-970 mbps. There's a hard drive I backed up in its entirety, and now I want to transfer it to another external drive. The problem is that copying the entire folder to my new external is delivering less than stellar results.
Usenet maxes out my connecting at 80-90 MBps, but it seems that through GDrive it's so much slower and very sporadic as there is no "real" transfer rate due to the pre-fetching mechanism. I was wondering if there where any other ways to optimize this?
-
On 9/15/2017 at 1:38 PM, Christopher (Drashna) said:
To be honest, hierarchical pooling is probably one of our most complicated features. Second only to the file placement rules.
So don't feel bad if it has you confused.
That said, hierarchical pooling allows you to add a pool... to another pool as if it was a normal, physical disk. In all regards it's treated like normal.
Well, that's a lie. If a pool contains CloudDrive disks, there is some special handling for those drives, and the entire pool (we avoid reading from CloudDrive based pools to minimize internet usage).
As for using a CloudDrive disk to back up the pool... it's simple, really:
Add your existing pool to a new pool.
Add a CloudDrive disk to that new pool.
Enable duplication on the top level pool.
... Seed your new pool, just like you'd do so with a normal drive:
http://wiki.covecube.com/StableBit_DrivePool_Q4142489
This will cause the data to show up in the new, top level pool. And once you've remeasured, it will start duplicating the data from the local disk pool, to the CloudDrive disk.
This will keep a copy locally, and on the cloud. And because the software avoids reading from the CloudDrive disk....
That said, this is redundancy, and not a backup. If you delete files, they're gone. Period.
Alternative, you could just not add the CloudDrive disk to any pool, and use something like Free File Sync, SyncToy, GoodSync or the like to copy the contents of your pool to the CloudDrive disk.
The "Drive Usage Limiter" balancer would work better for this.
That said, this shouldn't happen any longer in the new public beta build. We've completely reworked the drive removal, so the pool should stay writable while removing a drive.
.757 * When a drive is being removed from the pool, and there are in use unduplicated files preventing the drive removal, a dialog will show exactly which files are in use and by which process. * [D] Fixed crash when cloning an exceptionally long path due to running out of stack space. * [D] Rewrote how drive removal works: - The pool no longer needs to go into a read-only mode when a drive is being removed from the pool. - Open duplicated files can continue to function normally, even if one of their file parts is on the drive that's being removed. - Open unduplicated files that reside on the drive that's being removed will need to be closed in order for drive removal to complete successfully. An option to automatically force close existing unduplicated files is now available on the drive removal dialog. When not enabled, the service will move everything that's not in use before aborting drive removal.
Well, DrivePool definitely isn't obsolete, We're just a small company, and didn't really have plans for "if CloudDrive took too long". Which is what happened.
That said, we have plans in place to prevent this from happening again. But it's bad that it happened in the first place. Hence why the plans to make sure it never happens again.
As for Windows, that's a much more complicated topic. But basically, just because you don't use it, doesn't mean it's not a well used feature. And the opposite is true (such as WMC :'( )
I'm not sure what you mean here.
Though, the "dpcmd" utility has a number of tools to enumerate drives.
Between that, and "mountvol", identifying drives and file locations should be relatively easy.
(dpcmd list-poolparts, dpcmd check-pool-fileparts, namely)
However, a more graphical, friendly utility would be nice. And this may be something that ends up in StableBit FileVault.
What would be the fastest/best option of backing up a physical DrivePool?
As I understand, going the route of Hierarchical pooling is automatic and serves as a mirror which helps repopulate data in the event of a drive failure.
But is an ACTUAL backup a better solution, and is it faster?
If so, what software do you recommend for it
-
On 4/29/2019 at 7:23 PM, Christopher (Drashna) said:
It may not rely on VSS, but it may still be using it.
@Bowsa Have you tried pointing it at the underlying disks in the pool?
No, but won't that be problematic in the following scenarios?
1) Purpose of "Physical" DrivePool is the organization, structure, and distribution of files between the pool of drives. Backing up the underlying drive would be out of order?2) Pointing it towards my "CloudDrive" doesn't do anything either, it doesn't backup my CloudDrive.
DrivePools gone, but still detected?
in General
Posted