


darkly
-
Posts
86 -
Joined
-
Last visited
-
Days Won
2
Posts posted by darkly
-
-
On 6/15/2018 at 2:09 PM, Christopher (Drashna) said:
Then it sounds like the two issues that you're having is capacity, and IOPS. A good SSD (and better, an NVMe drive) will fix the second issue. But the capacity issue is something I can't really help with. But this also sounds like a case of "throw more money at the problem".
I have to toss in a vote for allowing for multiple cache drives as well, although for different reasons. I'm not really having a I/O issue, but rather, I'd like to be able to transfer large amounts of data to my CloudDrive, such that Windows/applications see the file as being ON the drive, and leave that uploading in the background for however long it takes to actually move the data to the cloud. It's a pain when my single cache drive reaches max capacity and I can only make files visible on the drive at throttled speeds.
-
On 5/1/2019 at 5:05 PM, srcrist said:
It's possible, but provides no benefit over simply using the SSD as the cache drive. The cache is stored as a single file, and will not be split among multiple drives in your pool. Just use the SSD as your cache drive, and the cached content will always be at SSD speeds.
Is this still true? I'm looking at the CloudPart folder in one of my cache drives and I'm seeing over 5000 files in that directory.
Edit: Does this apply to data you have queued to upload as well? For instance could I not use a pool of a small SSD and large HDD as a cache to increase the total amount of data I can "transfer" to the CloudDrive and leave it to upload in the background?
-
I have two SSDs that I want to use as a cache for my CloudDrive. This system will be writing extensively to this CloudDrive so I need it to be durable and reliable over the long term, especially when I neglect to monitor the health of the individual drives. I was considering either using a RAID 1 between the two drives; or pooling the two together using DrivePool and either duplicating everything between the two drives, or utilizing both drives without duplication to spread out the wear. I have Scanner installed as well to monitor the drives, and it could automatically evacuate one of the drives (in the non-duplicated DrivePool) case if it detects anything. Speed isn't as important to me as reliability, but I don't want to unnecessarily sacrifice it either. Which option do you think is preferable here?
- RAID 1
- DrivePool w/ Duplication
- DrivePool w/o Duplication + Scanner
-
I want to set something up a particular way but I'm not sure how to go about it, or if it's even possible. Maybe someone with more experience with more complex setups could offer some insight?
Say I have two separate CloudDrives, each mounted to their own dedicated cache drives (let's call them drives X and Y). Both X and Y are SSDs. Let's also say I have the target cache size for each CloudDrive set to 50% of their respective cache drive's total capacity; for instance, if drive X is 1 TB, the CloudDrive mounted to it has its target cache size set to 500GB. This means (ignoring the time it takes to transfer and any emptying of the cache that happens during that time) at any point I can upload 500GB to that drive before the cache drive is full and I have to wait to upload more. We'll come back to this in a second.
I also have a large number of high capacity HDDs. I plan to pool them in DrivePool. Let's assume I have 4 10TB HDDs. I could pool these into two sets of two. Each pool would then have a total capacity of 20TB. Now I want to use these HDDs as sort of a "cache overflow" for the CloudDrives. In other words, if I attempt to transfer data onto the CloudDrive that exceeds the respective cache drive's available capacity, the data in excess would be stored on the HDD pool instead. Now obviously this is quite simple if I do what I just stated and make two separate pools of HDDs. I can then pool each HDD pool with one SSD and be done. Using the example sizes given previously, that would then give each CloudDrive 20.5TB of unused space available to cache any uploads.However, this doesn't seem very efficient for me, mainly due to one factor. I'm rarely writing to both CloudDrives at the same time. What would be far more efficient is if I could put all the HDDs into one pool, and then put that one pool into two pools simultaneously. One pool with the HDD pool + Drive X, and another pool with the same HDD pool + Drive Y. Unfortunately, this is not possible, as DrivePool only allows drives (and pools) to be in one pool at a time. If this were possible though, that would give each CloudDrive potentially up to 40.5TB of unused space immediately available for caching.
One potential workaround I was considering (but have not attempted yet) is to first pool all the HDDs together, and then to use CloudDrive in Local Disk mode to create two CloudDrives, both using the HDD pool as the backing media (rather than a cloud storage platform). Then pooling each CloudDrive with an SSD, and finally using the resulting pools as the cache for each of the two original CloudDrives. The main thing that worries me about this approach though is excessive I/O and how much that would bottleneck my transfer speeds. It seems like an excessively overkill approach to this very simple problem, and I seriously hope there's a simpler workaround. Of course, this could be a lot easier if DrivePool allowed drives to be in multiple pools, and I'm not quite sure why this limitation exists in the first place, since it looks like the contents of a DrivePool are just determined by the contents of a special folder placed on the drive itself. Couldn't you have two of those folders on a drive? Maybe someone can enlighten me on that as well.I hope I've been clear enough in describing my problem. Anyone have any thoughts/ideas?
-
20 hours ago, srcrist said:
I can, however, vouch for the stability of at least beta .1316, which is what I am still using on my server.
I can second this. Been using beta .1316 on my Plex server for months now and things have been running smoothly for the most part (other than some API issues that we never determined the exact reason for but those have mostly resolved themselves).
The only reason I brought any of this up is I'm finally getting around to setting up CloudDrive/DrivePool on my new build and wasn't sure what versions I should install for a fresh start. Looks like I'll just stick with beta .1316 for now. Thanks! -
23 hours ago, srcrist said:
Both. We were both talking about different things. I was referring to the fix for the per-folder limitations, Christopher is talking about the fix for whatever issue was causing drives not to update, I believe. Though it is a little ambiguous. The fixes for the per-folder limitation issue were, in any case, in the .1314 build, as noted in the changelog: http://dl.covecube.com/CloudDriveWindows/beta/download/changes.txt
confusing cuz v1356 is also suggested by Christopher in the first reply to this thread. Also the stable changelog doesn't mention it at all (https://stablebit.com/CloudDrive/ChangeLog?Platform=win), and the version numbers for the stables are completely different right now to the betas (1.1.6 vs 1.2.0 for all betas including the ones that introduced the fixes we're discussing).
-
On 10/19/2020 at 2:07 PM, srcrist said:
.1318 is the latest stable release on the site, and it has the fix (which was in .1314). You don't need to use a beta version, if you don't want.
On 10/27/2020 at 3:55 PM, Christopher (Drashna) said:The fix is in the beta version, but that hasn't shipped yet. The simplest method to fix this is to grab the beta version:
Sooooo which is it?
-
Just now, srcrist said:
Sure. Presently using:
- 12 down threads, 5 up threads
- Background I/O Disabled
- Upload throttling at 70mbits/s
- Upload threshold at 1MB or 5mins
- 20MB Minimum download size
-
Prefetching enabled with:
- 8MB trigger
- 150MB forward
- and a 15 second window
Are you using this for plex or something similar as well? I've been uploading several hundred gigabytes per day over the last few days and that's when I'm seeing the error come up. It doesn't seem to affect performance or anything. It usually continues just fine, but that error pops up 1-3 times, sometimes more. My settings are just about the same with some slight differences in the Prefetcher section. I've seen a handful of conflicting suggestions when it comes to that here. This is what I have right now:
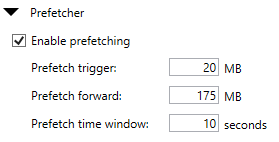
Don't think that should cause the issues I'm seeing though... Are you also using your own API keys? -
On 7/22/2020 at 12:07 PM, srcrist said:
I'm still not seeing an issue here. Might want to open a ticket and submit a troubleshooter and see if Christopher and Alex can see a problem. It doesn't seem to be universal for this release.
Might do that if it keeps happening. Out of curiosity, can you share your I/O Performance settings?
-
On 7/20/2020 at 10:49 PM, srcrist said:
I haven't had any errors with 1316 either. It might have been a localized network issue.
still going on. Happens several times a day consistently since I upgraded to 1316. Never had the error before unless I was actually having a connection issue with my internet.
-
7 minutes ago, KiLLeRRaT said:
I also upgraded to 1315 and it looks like everything is working the way that it should. I have not had issues that @darkly have reported where gets the insufficient bandwidth errors.
My disk upgrade went instantly, even through I was getting the API limit error before. I did revert back to standard API keys (not using my own) before upgrading.
I haven't yet tried 1316 yet.
Cheers,
I should probably mention I'm using my own API keys, though I don't see how that should affect this in this way (I was using my own API keys before the upgrade too). I'm also on a gigabit fiber connection and nothing about that has changed since the upgrade. As far as I can tell, this feels like an issue with CD.
-
I'm noticing that since upgrading to 1316, I'm getting a lot more I/O errors saying there was trouble uploading to google drive. Is there some under the hood setting that changed which would cause this? I've noticed it happen a few times a day now where previously it'd hardly ever happen.
Other than that, not noticing any issues with performance.EDIT
Here's a screenshot of the error:

-
6 hours ago, srcrist said:
I finally bit the bullet last night and converted my drives. I'd like to report that even in excess of 250TB, the new conversion process finished basically instantly and my drive is fully functional. If anyone else has been waiting, it would appear to be fine to upgrade to the new format now.
I had the same experience the other night. I'm just worried about potential issues in the future with directories that are over the limit as I mentioned in the comment above. Overall performance has become much better as well for my drives shared over the network (but keep in mind I was upgrading from a VERY old version so that probably played a factor in my performance previously).
-
On 7/12/2020 at 11:28 AM, Patrik_Mrkva said:
Heureka! Beta 1314 is solution! All disks are mounted, converted in moment. No errors, everething works perfectly! Thanks, Chris!
Are there any other under the hood changes with 1314 vs the current stable that we should be aware of? Someone mentioned a "concurrentrequestcount" setting on a previous beta? What does that affect? What else should we be aware of before upgrading? I'm still on quite an old version and I've been hesitant to upgrade, partly cuz losing access to my files for over 2 weeks was too costly. Apparently the new API limits are still not being applied to my API keys, so I've been fine so far, but I know I'll have to make the jump soon. Wondering if I should do it on 1314 or wait for the next stable. There doesn't seem to be an ETA on that yet though.
Afterthought: Any chance google changes something in the future that affects files already in drive that break the 500,000 limit? Could a system be implemented to move those file slowly over time while the clouddrive remains accessible in case something does get enforced in the future?
-
6 hours ago, Jellepepe said:
why do you say that? i am many times over the limit and never had any issues until a few weeks ago.
I was also unable to find any documentation or even mention of it when i first encountered the issue, and even contacted google support who were totally unaware of any such limits.wayback machine confirms the rule did not exist last year. Sorry, but at this point, I've just given on what he's saying.
6 hours ago, Jellepepe said:I first encountered the issue on June 4th I believe, and I have found no mention of anyone having it before then anywhere, it was also the first time the devs had heard of it (i created a ticket on the 6th). I seems like it was a gradual roll out as it initially happened on only one of my accounts, and gradually spread, with others also reporting the same issue.
I've been uploading this whole time and I still have yet to see this error so . . . really not sure when it's going to hit me. As far as staged rollouts go, this is remarkably slow lol.
6 hours ago, Jellepepe said:it would be possible, but there is a 750gb/day upload limit, so even moving a (smallish
 ) 50TB drive would take well over 2 months to move.
) 50TB drive would take well over 2 months to move.
Currently, moving the chunks, the only bottleneck (should be) the api request limit, which corresponds to a lot more data per day.
That said, it is possible to do this manually by disabling the migration for large drives in settings, creating a new drive on the newer version, and to start copying.Do the limits apply to duplicating files directly on Google Drive? Regardless, I was hoping more for a built-in option for this, not to do it manually, but I have no problem doing it manually. If I upgrade to the beta, does it automatically start trying to migrate my drives or prompt you first? How would I go about disabling the migration so I can keep using my drive while copying data.
Honestly, I don't care at all if it takes 2 months or 8 months or 12 months to migrate my data to a new format, if it means having access to it the entire time... For my use case, that still wins out over even 2-5 days of inaccessible downtime.
5 hours ago, srcrist said:A Google search returns precisely zero results for that API error prior to this month. The earliest result that I can find was this result from a Japanese site 20 days ago.
. . .
Note also that this API error code (numChildrenInNonRootLimitExceeded) was added to Google's API reference sometime between April and June.Yeah that's all consistent with my findings as well
5 hours ago, srcrist said:I am also not having errors at the moment (which might be related to the fact that my account is a legitimate account at a large institution, and not a personal GSuite Business account) but I anticipate that we will all, eventually, need to migrate to a structure conformant with this new policy.
Thinking it's just a super slow staged rollout like I said before, cuz I'm just a single user business account, and I'm still having no problems as of right now.
5 hours ago, srcrist said:I don't know why you seem so resistant to the notion that this is a change in Google's API that will need to be addressed by all of us sooner or later, but the objective information available seems to suggest that this is the case.
I tried. I gave up.
-
3 hours ago, JulesTop said:
I don't believe that this is the case. Clouddrive would organize it all as one single cloudrive and everything would be in the same directory.
I do the same exact thing you do, but with 55TB volumes in one clouddrive, and they were all in the same folder.welp, maybe it's just a matter of time then . . . Does anyone have a rough idea when google implemented this change? Hope we see a stable, tested update that resolves this soon.
Any idea if what I suggested in my previous post is possible? I have plenty (unlimited) space on my gdrive. I don't see why it shouldn't be possible for CloudDrive to convert the drive into the new format by actually copying the data to a new, SEPARATE drive with the correct structure, rather than upgrading the existing drive in place and locking me out of all my data for what will most likely be a days long process . . .
-
14 hours ago, srcrist said:
Hey guys,
So, to follow up after a day or two: the only person who says that they have completed the migration is saying that their drive is now non-functional. Is this accurate? Has nobody completed the process with a functional drive--to be clear? I can't really tell if anyone trying to help Chase has actually completed a successful migration, or if everyone is just offering feedback based on hypothetical situations.
I don't even want to think about starting this unless a few people can confirm that they have completed the process successfully.
I don't have most of these answers, but something did occur to me that might explain why I'm not seeing any issues using my personal API keys with a CloudDrive over 70TB. I partitioned my CloudDrive into multiple partitions, and pooled them all using DrivePool. I noticed earlier that each of my partitions only have about 7-8TB on them (respecting that earlier estimate that problems would start up between 8-10TB of data). Can anyone confirm whether or not a partitioned CloudDrive would keep each partition's data in a different directory on Google Drive?
-
6 minutes ago, kird said:
The logic suggests that the version you've been in most of the time has never had this problem... it's totally compatible with google limitation/imposition, in fact this one has always been there, it's not new, another thing is that we (not the developers) didn't know it.
again, this makes no sense. Why would they conform to google's limits, then release an update that DOESN'T CONFORM TO THOSE LIMITS, only to release a beta months later that forces an entire migration of data to a new format THAT CONFORMS TO THOSE LIMITS AGAIN?
-
Is there no possibility of implementing a method of upgrading CloudDrives to the new format without making the data completely inaccessible? How about literally cloning the data over onto a new drive that follows the new format while leaving the current drive available and untouched? Going days without access to the data is quite an issue for me...
-
5 minutes ago, kird said:
Here one with 121 TB used and without any problem, so i don't need anything and even less to lose my data by doing an upgrade that i don't need at all. Perhaps the secret lies in not having configured any personal API (I've always been with the standard/default google api).
that doesn't change the fact that versions prior to the beta mentioned above don't respect the 500K child limit that is forced directly by google...
unless one of the devs wants to chime in and drop the bombshell that earlier versions actually did respect this and only the later versions for some reason stopped respecting the limit, only to have to go back to respecting it in the betas . . . /s
-
1 hour ago, kird said:
my advice, don't even think about upgrading.
I mean, I'd imagine I'd have to sooner or later. The child directory/file limit still exists on google drive, and 1178 isn't equipped to handle that in any capacity. I'm just wondering why I haven't gotten any issues yet considering how much data I have stored.
-
Soo..... I'm still on version 1.1.2.1178 (been reluctant to upgrade with the various reports I keep seeing), but my gdrive has over 100TB of data on it and I've never seen the error about the number of children being exceeded. I use my own API keys. Have I just be extremely lucky up until this point?
-
3 hours ago, srcrist said:
I'm not 100% positive on this, but I believe that once the cloud drive is added to the pool, if the system boots up and the drive is still locked, Drive Pool will see the locked drive as "unavailable" just like if you had a removable drive in your pool that was disconnected. That means that balancing would be disabled on the pool until all of the drives are available. It won't start rebalancing without the drive being unlocked, unless you remove the drive from the pool. It should be aware of all of the drives that comprise the pool, even if some of the drives are missing. The information is duplicated to each drive.
Bottom line: no special configuration should be necessary. DrivePool should function perfectly fine (accepting data to local drives) while the cloud drives are missing, and then balancing rules will be reapplied once the drives become available. Though, the part I'm not sure about is whether or not the pool will be placed into read-only mode as long as a drive is missing. It may simply not accept any written data at all--and, if that's the case, I'm not sure if there is a way to change that. You may just have to wait until all of the drives are available.
Thanks. I've actually tested having parts of a pool absent before and I'm pretty sure you can still write to the remaining drives. My problem is that once the cloud drive comes online, I don't want to simply "balance" the pool. I don't want the local disk(s) in the pool to be used at all. Ideally, once the CloudDrive comes back online, all data is taken off the local disks and moved to the CloudDrive. I'm just not sure how I'd configure that behavior to begin with. If the first part of what you said is correct (that balancing would be paused), then that's great, as that's exactly the behavior I'd want while the CloudDrive is not mounted, as I'd still want to be able to move files onto the pool's local disks (even though those local disks are somehow configured to hold 0% of the data once "balanced"). Any idea how to set up DrivePool to balance in this way?
-
I'm currently using a CloudDrive that is partitioned into many smaller parts and pooled together with DrivePool. The CloudDrive is encrypted and NOT set up to automatically mount when the OS loads. One downside of this is that if any applications are expecting a directory to exist, it won't be able to find it until I unlock the CloudDrive and DrivePool picks up at least one partition. I have an idea on how to resolve this, but I'm not sure exactly how to implement it. I'm thinking that if I either add a local drive to the existing pool, or create a new pool consisting of just the local drive + the existing pool (nested), and somehow set the balancing rules so that the local drive is always 0% utilized, then 1) that pool would always be available to the system (at least once DrivePool services load), 2) once the CloudDrive is unlocked, the local drive (in the pool) would not be utilized at all, and 3) if the CloudDrive is NOT unlocked, then writes to the pool would be forced to the local drive, but immediately offloaded to the CloudDrive once it IS unlocked. Does this make sense? And how (if possible) could I configure DrivePool to do this?
SMART TOOLS WITH SAS drives
in Compatibility
Posted
Any word on this yet?