Jellepepe
-
Posts
45 -
Joined
-
Last visited
-
Days Won
4
Everything posted by Jellepepe
-
I read that yes, interesting that that is the only thing that changed, im running server 2012 r2 myself and have had no such issues, so i doubt its the same. Hopefully it was an issue at google and resolved now, but we'll see in a few hours i suppose. i followed up on my support ticket with a summary of this thread 2 days ago, i haven't had any response since
-
they are under a pretty constant load, im using stablebit drivepool to mirror one to the other, so one drive is downloading about 690gb / day and the other is uploading that again (different domains, different api). the only other thing accessing the drives is radarr/sonarr, which are only adding around 10-20gb a day (to both drives) i was already having the issue before i added the second drive and started doing this, so its not the cause. And due to this constant load i can see exactly when it stops working, there are no jumps in load right before or anything, atleast not that i can see, the speed for every thred just drops to about 150kbps each, then after about a minute maybe 2 clouddrive decides it cant get a decent connection and dismounts the drive. If i try to remoung right away (if i see it happen) the same issue is still there, but if i wait a little longer it will start working again. Yesterday this was only a few minutes before it worked again, but before ive had it take almost half an hour, oad on the drives yesterday compared to the day before is almost exactly identical. Mine usually dismount between 7-10pm, but if you;re in a different timezone that might match up with my dismounts, it seems to often be around a full hour. From what i am able to tell from resource monitor and watching connections, clouddrive connects through a domain, not ip, and the ip behind this isnt static, so it would be hard to check. Also it is showing the connnection to be active, just throttled to 150kbps per thread, i doubt a ping would fail at that point. That's good to hear! (for you atleast) I've also had a HTTP500 return sometimes (which is what that error is), and it doesnt see =m to cause a dismount for me either. I'm not really sure what it means, the translation 'internal server error' is pretty broad, but i dont think its related, just a random request failing for unrelated reasons. I do have to note that i've only ever had this happen once or twice in a day at most, never more than that. Anyway, do keep us updated on if the issues remains gone, or if you just got lucky last night! If they remain gone, it would be interesting to try and figure out what exactly changed...
-
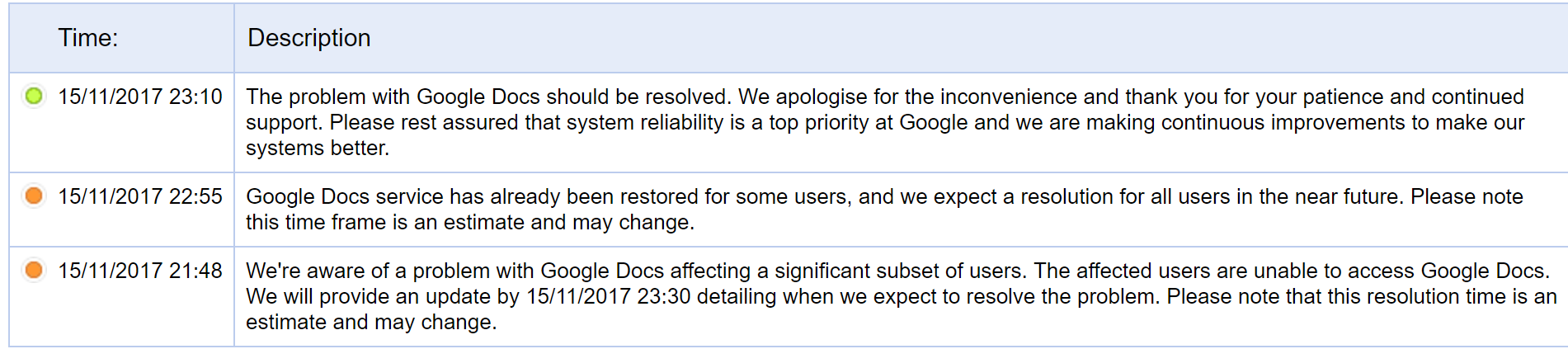
This issue, whatever it was, seems to be resolved.. What is interesting is the time they posted that they became aware of the issue corresponds exactly with a dismount for me. I doubt this was the issue, mainly because i dont want to get my hopes up, but its interesting nonetheless.
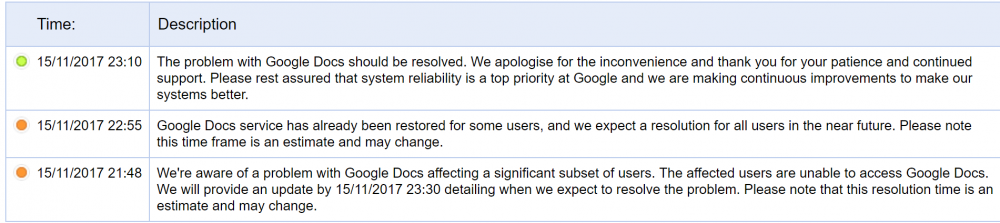
-
Thats really interesting!! I have not received this email on either Gsuite domains nor the backup email adresses, internally i think Drive and Docs are not the same, but this might be related nontheless. Assuming i dont get the email myself, please do give updates on whatever they announce!
-
Interesting, i did notice the drives were able reconnect much quicker this time (only a few minutes) so depending on your usage during this time, it might not have disconnected since it wasnt active. (clouddrive only disconnects when it tries downloading data and fails, so if theres no activity on the drive it wont disconnect) I'm running server 2012 R2 myself, and havent had any issues aside from coulddrive, so im not sure if this is related, but worth making a note of! Great to hear, would love to hear back on your setup and if you run into anything feel free to ask, also if you want drop me a private message for discord or whatever if you want some more tips, will try to keep this topic focused on the dismounting issues. Again, since you seemingly didn't remount the drive (or there was no activity) during the rest of the 'trouble zone' its hard to tell if its the exact same issues, but it does seem very suspect its always this general 7-10pm timeframe. ---------------------------------------------------------------------------------- My drives have been on a pretty high load due to drivepool duplicating all the time, so my graph very clearly shows when the connection drops(?) Its an interesting trend to see the issue is much less apparent as it was yesterday & the day before hopefully this continues and the issue is completely gone by the end of the week
-
After the remount yesterday at 22:54 the drives remained mounted and fully functional at 200mbps+ The issues started again though today; 19:08 - dismount 19:31 - remount (i was in transit so it possibly started working again earlier, this is when i remounted though) 19:53 - dismount (only the old drive) 19:56 - remount 20:49 - dismount 20:55 - remount
-
In that case you can set up a connection between radarr/sonarr and the plex server, allowing it to tell the server when new content is added, making full library refreshes unneccessary to do this - (sonarr and radarr is both the same) go to settings->connect & add plex media server then fill out the login, ip, port and give it a name. Enable on download, on upgrade & on rename, and also enable update library. This will make radarr/sonarr notify the server of new files, making library scans unneccesary Next, in plex under settings->server->library enable advanced settings and disable all library scanning (assuming you dont have any other libraries that require this) Then just manually run a library refresh every week or so just in case it missed anything due to outages etc. (recommended to temporarily disable prefetch or increase the trigger size and watch drive usage with this, its more likely to crash on this, though if pinning metadata & directories are both enabled this shouldn't be too much of an issue) I forgot to mention that yes, i am using encryption with the drive - as long as you;re not storing small files, and your bandwidth allows for it, recreating the drive with larger chunks will increase performance, though it will probably still function fine with 10mb chunks. Cache chunk size can be changed by simply detaching and reattaching the drive.
-
it would be nice to compare times in particular, since it seems to be time related. The plex settings depend on how new content is added (do you use sonarr/radarr etc?). For clouddrive, (since i figured out its unrelated to the api calls), ive set it to the following: download threads 10 w/ no throttle - upload threads 5 w/ 175mbps throttle (due to plex streams) - background I/O checked. Minimum download size 10mb - prefetch trigger 1mb - prefetch forward 100mb - prefetch window 30sec Cache chunks are 100mb, drive chunks are 20mb (size 100TB) upload verification and pinning are all enabled cache is 90gb expandable on a 120gb SSD (dedicated to just this drive), but if you;re using HDD's with a lot more storage, increasing this will increase performance for everything thats cached, just dont fill it completely, as windows will complain.
-
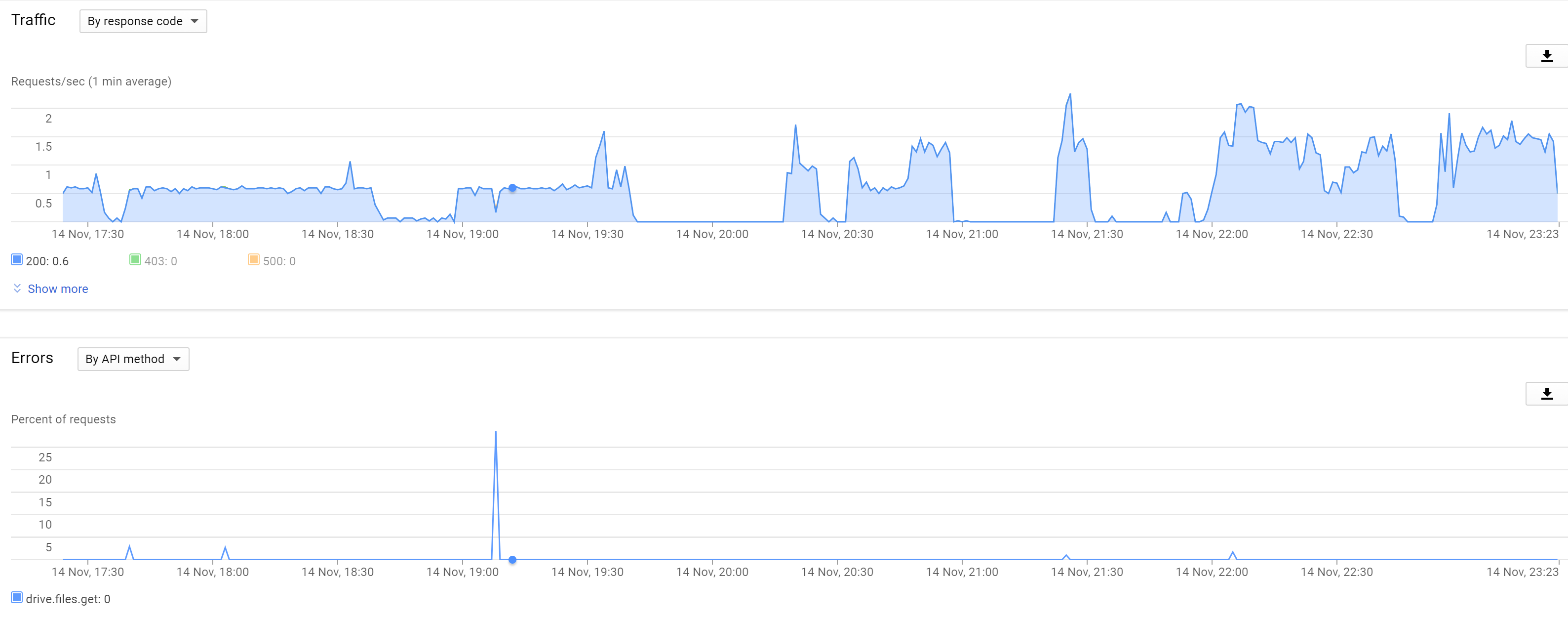
If your issue is actually the same as we are experiencing (same time-based stuff) we've already ruled out that usage is part of it, or atleast our usage, it could ofcourse be related to the total drive network usage, but that is yet to be determined. outside the 'dismount' time window i can max out my connection at over 300mbps down and 250mbps up with around 20 threads without issue, at the same time with even a single thread at low speed the drive dismounts, so i doubt disabling these features and/or trying to reduce api calls will resolve the issue (as it didnt for me). PS. i am also using plex, and when there are no issues (been using clouddrive for Quite a while) its actually Great! - the only cloud mounting software that can reliably allow for library scans etc. + if you have a decent cache size and/or fast download speeds, it can easily handle a lot of streams. you would have to create your own api keys Go here: https://console.developers.google.com/apis/library/drive.googleapis.com/ Create a project and enable the drive API for it. Then generate OAuth keys - these should consist of a client ID and Secret then edit the 'providersettings.json' under C:\ProgramData\StableBit CloudDrive and fill out the client ID & secret under google drive. When you reauthorize your drive, it should no longer display clouddrive(number) but the name you gave your project. You can now go to the drive api overview for your project and see the chart for all requests coming in. ----------------------------------------------------------------------------------------------------------------- since i ruled out the api calls being part of the issue, my graph now looks a lot clearer, i dont really need to point out when the dismounts occur. Needless to say - when comparing the dismount times as i laid out in my previous (updated) post, its clear to see it has nothing to do with the api calls, as they are simply not going through when this happens (instead of 403 responses which you would get when a quota or rate limit is reached)
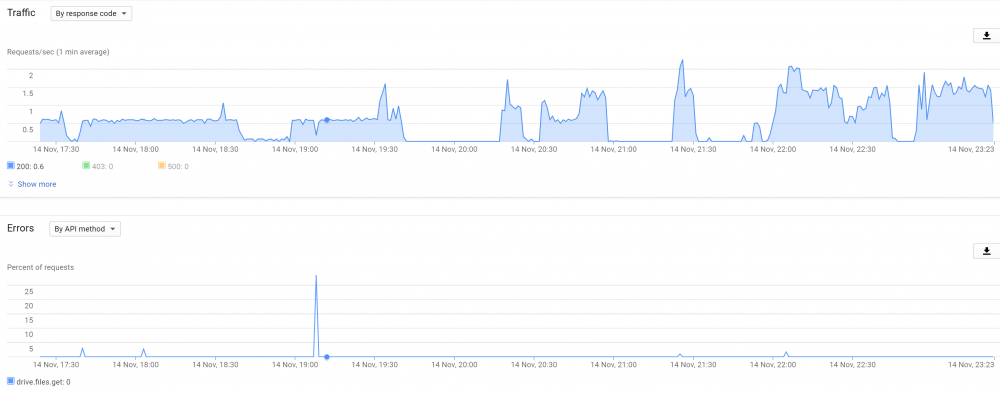
-
Since i wanted to be extra sure i disabled all applications aside from drivepool (which is duplicating from one drive to the other) - this means there is exactly the same load on the drives all day long (throttled). The drives are still dismounting at seemingly the exact same times as you - i would say this 100% rules out any local system or usage related issues
-
my drives just dismounted also - exactly at the same time, this cannot be a coincidence
-
'good' to hear its indeed the same time (so very likely the same issue) when affecting us. the server is running on a 1gb down/250mb up connection (250mn down guaranteed) - i dont assume its the provider itself throttling, but it might be something in between google and our servers/home connections that is causing the connection drop... i am unsure at this point. EDIT: also worth noting, since there was no other activity i can much more clearly isolate the errors im getting, in addition to the thread closed message i seem to be getting right before the drive dismounts, it spams the lg with this error for a good few minutes right before: CloudDrive.Service.exe Warning 0 [CloudDrive] Error getting write requests from driver. The system cannot find the file specified 2017-11-14 19:04:33Z 243712906469 CloudDrive.Service.exe Warning 0 [CloudDrive] Error updating statistics. The system cannot find the file specified 2017-11-14 19:04:33Z 243714996761
-
never mind - at exactly 19:39 (CET) both drives dismounted within 2 minutes of each other. This cannot be due to change in usage, as the only thing accessing the drives was drivepool which was duplicating the old drive to the new one. It had copied 450gb so far that day, so it also has nothing to do with the 750gb/day upload limit. The new drive is running on clouddrive's own api keys. The old drive is running on my own credentials, this is showing 24 HTTP 500 responses (backend error) at 19:08 (CET) - other than that all requests are honoured (HTTP 200) For me this kind of concludes it has nothing to do with bad filesystems or old/new drives. as it seems to 100% be either external throttling or an issue at google. PS; i've also been changing threads and throttle settings for up/download - while this does affect the number of api calls / sec - it doesnt have any effect on the dismounts (also not getting any 403 responses) ==== if i try to reconnect straight after, the detailed information screen shows uploads going at normal speed, but failing. Downloads are going at max 150kbps per thread, they also seem to be failing (or too slow for clouddrive to consider valid) the errors are: cloud drive <name> is having trouble downloading data from Google Drive. Make sure that you are connected to the Internet and have sufficient bandwidth available. Continuing to get this error can affect the stability of your cloud drive. Cloud drive <name> is having trouble uploading data to Google Drive. Error: the system cannot find the file specified This error has occured < keeps counting while mounted > times. Make sure you are connected to the Internet and have sufficient bandwidth available. Your data will be cached locally if this problem persists. these appear for both drives, and they dismount again after about 1 minute (no data actually gets down or uploaded.) If anyone has any further suggestions, i'd be extremely interested. @Christopher (Drashna) -------------------------------------------------------------------------------------------------- @ntilegacy I'm personally hosted at OVH (through soyoustart) in france - if this is a thottling issue, it would be intersting to learn if you're in a similar location. Secondly, it would be interesting to see if the errors are occuring at exactly the same time, or only roughly the same timeframe, and if the issues are actually the same, or only mostly similar. Hope to hear from both of you! ---------------------------------------------------------------------------------------------------- Will update a list of dismounts/remounts here: 19:39 - dismount (both drives) ~20:00 - succesful remount (both drives) 20:27 - dismount (both drives) 20:33 - successful remount (both drives) 21:02 - dismount (old drive) 21:22 - successful remount (old drive) 21:27 - dismount (both drives) 21:59 - successful remount (both drives) 22:40 - dismount (both drives) 22:54 - successful remount (both drives)
-
Good to hear im not the only one experiencing this, it is currently 7pm for me, and the drives have not dismounted (YET). Ill report back in a few hours when the regular dismount window has fully past to see if the issue is still there. (Through my private support ticket i was recommended to install newer beta builds; .951 - .866 & .3129 for clouddrive, drivepool and scanner respectively) So the only things that changed was fixing filesystem, updating to beta builds, and reattaching the drives. If you want to keep an eye on it, id recommend installing drivepool, adding the drives and setting up email alerts; that way you can see exactly when they dismount.
-
Thank you for the reply! I was not getting the user rate was exceeded - or any other rate/quota exceeded response codes (as visible in the api log) what i am getting, in addition to the thread aborted issues, is: CloudDrive.Service.exe Warning 0 [CloudDrive] Error getting write requests from driver. The system cannot find the file specified 2017-11-13 19:46:56Z 310252861197 CloudDrive.Service.exe Warning 0 [CloudDrive] Error updating statistics. The system cannot find the file specified 2017-11-13 19:46:57Z 310253222849 i've since installed scanner as well, as to complete the trilogy this reported file system issues on both clouddrives & the pool, but more importantly also on the cache SSD for the old drive - correcting this seemed to have been successful and the drive is mounted and working as of now (though not sure for how long) Is it safe to simply tell stablebit scanner to correct the clouddrives also? or is this not recommended? I REALLY REALLY hope this was the issue, and the drives will go back to functioning normally after this
-
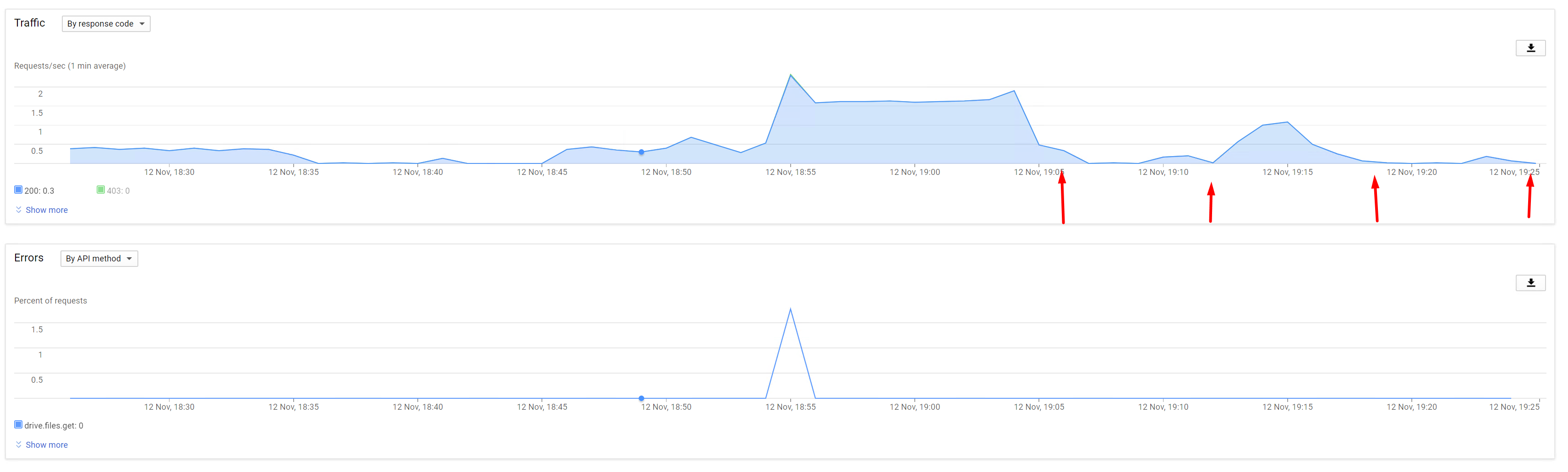
Hi all, I've recently started getting a bunch of dismounts on my google clouddrive (made in prerelease) - i've done a lot of troubleshooting, and reduced the threads, speed, prefetch etc etc. Nothing worked, im still getting seemingly random dismounts between approx 6-7pm and 10pm (CET). I've tested this, and it seems completely unrelated from drive usage, ive not had any dismounts outside this timeframe, even with a lot of traffic, and ive had dismounts with nothing but a single file being accessed. I have since gotten a second domain (seperate account) and made a new drive, i'm now using drivepool to copy the drive, and notify me when the old drive gets dismounted. I have also switched the old drive to my personal api keys, to watch the api calls and possibly confirm what sort error responces im getting. the weird thing is, there seem to be basically none (arrows are when it dismounted (retried mounting immediately after) the log just states: CloudDrive.Service.exe Warning 0 [IoManager:104] Error performing I/O operation on provider. Retrying. The read operation failed, see inner exception. 2017-11-12 18:18:21Z 24268242550 CloudDrive.Service.exe Warning 0 [IoManager:104] Error processing read request. Thread was being aborted. 2017-11-12 18:18:21Z 24268568126 (different timezone) Im starting to suspect the only possible explanation is the ports/requests just outright being blocked, and not by google. This is weird, since its on a server hosted by ovh (250/250 guaranteed) and ive never experienced any sort of blocking + they shouldnt be. Is there any way i can confirm/disprove this theory? And if anyone has some other suggestions for trying to resolve the issues, Please let me know! Thanks in advance, Pepe
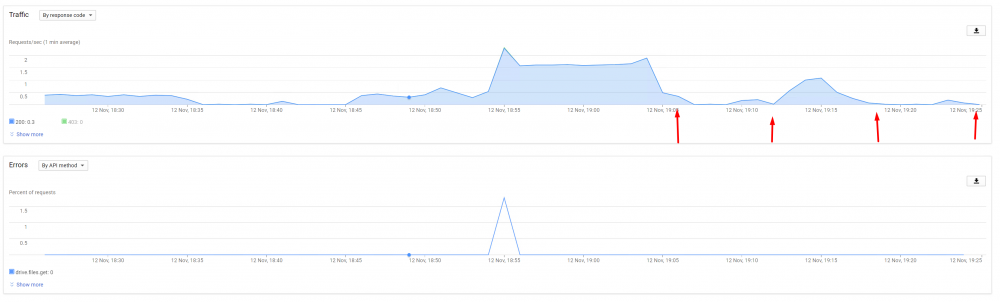
-
Thanks for responding, i seem to have fixed it by force attaching the drive to a different pc (was unable to detach too), then reinstalling clouddrive and reattaching it to the old pc. i've turned it down to 6 up threads and 20 down now, which still seems to fill up my bandwidth (33mbps up, 330 down) it seems to have somehow crashed in the authorization, in such a way i was unable to reauthorize it. If it stops working again i will definitely report back
-
UPDATE2: After browsing and reading around some, i tried Reauthorizing the connection to google drive, which did not really work. It is now stuck on 'authorising' with the same error still occurring.
-
UPDATE: it is now attempting to upload 1 thread(?) ever 1 minute or so, making absolutely 0 progress. According to the google drive stats files are actually being accessed, but nothing is really added. It is also adding this error everytime: I/O error Cloud drive (G:/) - GDS is having trouble uploading data to Google Drive in a timely manner. Error: De thread is afgebroken ("The thread has been broken off.") This error has occurred X times. (keeps going up, every time it tries uploading.) What does this mean exactly? my connection seems fine.. does this mean google (or my ISP) is throttling me?
-
Hi there, I have a 100TB google drive drive (overkill i know, but 10TB didnt cut it and i just added a 0, hopefully this isnt the cause of the issue ) chunk size is 20mb, 100GB expandable cache, upload and download threads are both 20, no throttling. I'm running .777. I recently somehow cause an error with it weirding out, so its now saying it needs to upload the full 205GB (to upload & cache), due to it doing a recovery. Now for some reason, a day or 2 ago the pc it was running on decided it needed windows updates, cause the upload to fail. I only found out a few hours later (upload in 100GB chunks of data, only check on the pc once a day). But the issue seems to be that now, after reboot it only uploads around 1-2minutes then completely fails and goes to 0bps upload (no threads either). My max upload is only around 30mbps, so it usually takes a while to upload, but this is just very annoying as it means i have to check up with it very often. Is there any way i can figure out what the cause of this is? Thanks in advance, and let me know if you need any more info!