


pofo14
-
Posts
27 -
Joined
-
Last visited
-
Days Won
1
Posts posted by pofo14
-
-
MOVED TO OTHER TOPIC
-
Got it - thanks
-
On 6/12/2020 at 10:54 AM, SPACEBAR said:
I ran WSL2 + Storage Space from August 2019 to March 2020. It works well. I ended up switching from Storage Space to DrivePool because it's really hard to diagnose Storage Space when it misbehaves. And when it does fail (and it will), it does so in spectacular fashion. I was bummed out about losing parity functionality but DrivePool + Snapraid is fine for my use case.
Anyway, I was able to use DrivePool with WSL2 (Docker) by mounting cifs volumes (windows shares). Here's an example:
version: '3.7' services: sonarr: build: . container_name: sonarr volumes: - type: bind source: C:\AppData\sonarr\config target: /config - downloads:/downloads cap_add: - SYS_ADMIN - DAC_READ_SEARCH volumes: downloads: driver_opts: type: cifs o: username=user,password=somethingsecure,iocharset=utf8,rw,nounix,file_mode=0777,dir_mode=0777 device: \\IP\H$$\DownloadsNote that I'm building the image. This is because I need to inject cifs-utils into it. Here's the dockerfile:
FROM linuxserver/sonarr RUN \ apt update && \ apt install -y cifs-utils && \ apt-get clean
There are security considerations with this solution:
1. Adding SYS_ADMIN capability to the docker container is dangerous
2. You need to expose your drive/folders on the network. Depending on how your windows shares are configured, this may be less than ideal.Hope this helps!
I know this is an older post - but I am starting to play around with WSL2 in my setup - and am having these same mounting issue's.
What config file are you showing that configuration in? Apologize for a potential basic question - but I am new to this.
-
I have a 10 drive pool made up mostly of 4TB & 8TB drive . I typically try to leave 10% free on each drive which can add up to a decent amount of "free" space in the pool, even though each drive is near capacity.
Is there any best practice for how much to fill a drive? Should I keep it where it is or can I use more of each drive?
Thanks in advance
-
I got a notification that a disk was no longer available in the pool at 11:07am on 11/10. When I got back home I confirmed the disk was not available.
Further troubleshooting I see the Below are also three errors that start happening repeatedly in the event view starting on 11/08 continuing until the disk went off line. The third error occurred right around the time the disk went offline.
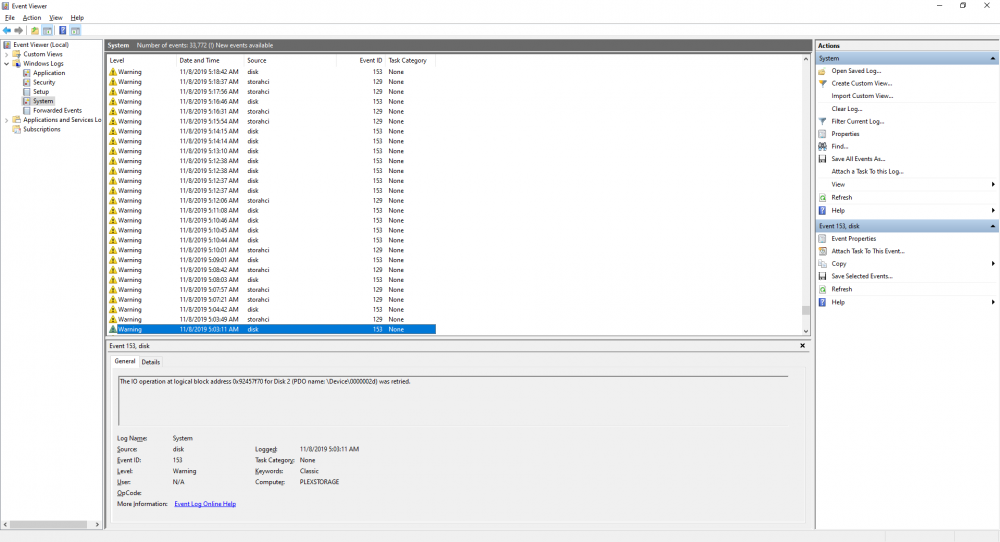
.thumb.png.0ac0a277000f64028cbb79fe94cd1992.png)
.thumb.png.7dfa0ac70896a17353caa416f87e0885.png)
When I open up disk manager I get the a prompt to initialize the disk (see below). If I try to initialize it I get an error stating "Virtual Disk Manager - Incorrect Function ".
.png.d899fcd3bc365595601e8420f23c7659.png)
Do I assume this disk is dead - even though previously it didn't report any SMART errors - or had any issue in Scanner?
-
I read through all the forum posts and am still not clear the best setup to use BackBlaze with Drivepool. Should I configure Backblaze to backup the individual data drives, or the pool drive itself?
I thought I should back individual data drives, so if any one of them go I can just put in a new drive and restore only those files.
If I backup the entire Pool drive does it make it more complicated to determine the files that could have been "lost" if any one drive does fail?
Any suggestions form the group is appreciated.
-
I have been running Scanner & DrivePool along with SnapRAID for years, and everything has been running flawless for a long time.
One of my data drives needed to be replaced (started getting smart errors) and somehow during this process my OS drive got corrupted prompting me to have to reinstall Windows 10 and start fresh.
Now I am seeing many errors in the event log complaining for Disk Collisions and SnapRAID syncs are unable to complete and get hung.
I understand this probably has nothing to do with DrivePool, but am hoping some of the experts here can help. I read how to change the drive is using diskpart, it seems straight forward enough. I am not clear though how I would create a new ID, do I just use a random hexadecimal number?
Would performing another clean install of windows resolve this issue? If it would I may just go that route but wanted to see if anyone here can help.
One additional note is that these disks are online in the disk management tool. From what I am reading if there is a collision they should be offline - which further adds to my confusion.Thanks in advance,
Ken
-
Hi,
My Windows boot disk had some issue's and I couldn't boot into windows. I installed a fresh copy on a new drive, and plugged in the old OS drive into the PC. I have access to all the files from the old install.
My question is after I install StableBit Scanner, can I copy over some program data so it won't have to rescan all the drives - or am I better off just letting it go through each drive again. I have like 14 drives it has to scan so I was trying to just save some time.
Thanks,
Ken
-
1 hour ago, Christopher (Drashna) said:
Yeah, I would.
Though, if you want to double check, clear the status and rescan the sectors.
https://stablebit.com/Support/Scanner/2.X/Manual?Section=Disk Scanning Panel#Sector Map
If they come back, then they're still an issue. And I would DEFINITELY recommend RMAing the drives. If they don't come back, then it's a good chance that they were fixed.
Thanks for this input. I cleared the status, and did a rescan and the errors cleared out. I will continue to monitor.
As always thanks for the help and great support.
Ken
-
On 10/10/2018 at 1:00 PM, Christopher (Drashna) said:
@pofo14 I would recommend running the "Burst Test" on the drive. You can right click on it to do so.
If that comes back with issues, it may be a bad connection. Try reseating the connectors for the drive, or maybe swap out the cable. Then re-run the test. If that comes back with issues, you may have an issue with the drive or controller.If it comes back clean, then yes, definitely RMA the drive.
So I have run a burst test for 24 hours with no issues. Scandisk /R returned no errors but it still shows damaged in Scanner.
There are no SMART errors.
Should I RMA this disk?
-
I have a new drive that Scanner is detecting 234295 unreadable sectors. I started a filescan and things came back from that OK - but the error obviously is still there. This drive is under warranty - should I be looking to replace this drive or are these unreadable sectors OK.
-
Thanks. I will find a way to work around it.
-
Hello,
I am experiencing an error in The Amazon Drive desktop application when i try to set the default sync folder on my PC as a folder on a pooled Drive in drivepool.
I have a basic drivepool setup and basically just have one JBOD Drive. When I set the Drive in the Amazon desktop tool, it never loads up and eventually say “this Drive is not supported”.
I was wondering if anyone else experienced this issue, and if there is something I need to tweak in my drivepool setting.
Thanks,
Ken
-
Well, I'm glad to hear that StableBit Scanner helped you to identify the bad SATA cable (I've experienced this and weirder, as well).
Asf or the LBA errors, I'm guessing that the drives were asleep/idle and being woken up (LAB sector 1... the first sector on the disk...). But I'm not 100% sure.
And I'm glad that everything appears to be working fine now!
Your guess seems correct, as usual.
I knew something was running at that time, and realized that I have an Acronis daily backup that runs at 12:30, exactly the time the errors occur. While Acronis doesn't backup the drivepool drives, or any of the "data" drives (only backing up the system drive), it does wake the computer which I assume is what triggers the error.
At this point it's no harm no foul.
-
To be blunt:
LBA retries and raid port resens are entirely common. These happen all the time, and may be perfectly normal.
Though the "flush logs" isnt' as common, it can still happen, in certain circumstances.
However, if youre seeing a large number of these in short succession, ESPECIALLY when accompanied by disk and/or NTFS errors, then it may indicate an issue.
As for what drive this is, run "msinfo32", and check the "component" section, and this may help you to identify the disk in question.
Though, IIRC, the "Disk9" woudl be the same "disk 9" in Disk Management.
Also, running a "Burst test" in StableBit Scanner may reveal issues, as well.
That said, does SnapRAID not indicate the specific drive? even it its logs?
Thanks for getting back. All these steps were helpful, and I believe my issue was a bad SATA cable. I ran the burst test, on the new drive connected in the old port, with the old cable and had errors reported. After changing the cable the burst test was successful. I was also able to successfully complete a sync command in snapraid.
This has also removed most of the errors from the event log, with the exception of the following. But as you stated this may not be an issue. Interestingly though, they seem to consistently appear at 12:30 consistently, so I am not sure there is something firing off in Scanner or Drivepool that causes them. Or perhaps there is another job/process running that causes them.
Event 153, disk - The IO Operation at logical block address 0x1 for Disk12 (PDO Name: \Device\00000036) was retired
Event 153, disk - The IO Operation at logical block address 0x1 for Disk13 (PDO Name: \Device\00000037) was retired.
Presumably the old drive may have been fine, and I probably could / should hook it back up to validate it was the cable, but since everything is working I am not going to mess with it. I'll just say this all was a good opportunity to get a new drive.
Thanks again for the help.
-
That's the thing. The drives on the rocket raid (2680) are just general drivesfor me, and just passed through, meaning I am not using any raid on the card. The drive on the rocketraid card are not in the snapraid array. They are however pooled together in Drive pool as a big drive for general / temporary data.
-
I think it must be a drive pool or possible LSI thing as i am getting the same thing i.e. 129 and 153 events
for me the 153 are on the pool drive same as you i think - and Chris indicated when i raised it a while back as not something to worry about - some days i get lots of warnings some none - i updated the drivers, bios and firmware on my LSI card yesterday and only have one so far today but 40 in last 7 days.
as for 129 - none so far today - so possibly thats cured(?) only difference from you was iaStorA rather than storachi - possible SAS vs SATA difference - i have only had 5 in the last 7 days
used to get a lot of 153 when i had Rocket Raid cards which i have replaced - but they had loads of other issues so never bothered with these warnings
Good to hear the 153 are nothing to worry about. Interestingly I do have a RocketRaid card installed, although I don't think the errors are happening for the drives attached to that. If there was a way someone could intruct me how to figure out the physical volume for the \Device\RaidPort2 it would be helpful.
Regarding the 129 error, I haven't had it happen again today, but I think if I try to run anything against the disk I am suspecting I will see it happen.
-
To simplify this post:
What is the cause of these errors, which are happening on my virtual DrivePool Drives? Do I need to worry about them?
Event 153, disk - The IO Operation at logical block address 0x1 for Disk12 (PDO Name: \Device\00000036) was retired
Event 153, disk - The IO Operation at logical block address 0x1 for Disk13 (PDO Name: \Device\00000037) was retired.
Is error I get below when I run a snapraid sync, as well as when Scanner checks the drive, a problem with the drive or the connection? It seems to happen regardless of what drive I attach to that specific cable / port.
Event 129, storachi - Reset to Device \Device\RaidPort2, was issued.
-
First just wanted to start by thanking the community, great support and a lot of useful info in the forums.
I recently posted this topic because I was having some issue's getting my "snapraid sync" command to complete and was asking about other options for my setup. I got some good advice from you guys, as well in the snapraid forum here. Turns out, one of my parity drives was bad. Scanner wasn't reporting any issue's with it, and even the snapraid smart command, didn't have any errors. The snapraid command did say that the parity drive had a 100% chance of failing in the next year, which gave me enough of a clue. I confirmed this drive was the culprit after running the sync command again, I saw that this specific disk (x:\) was stuck as 100% usage in Task Manager and the snapraid process was "hung". I also checked the event log to find the following errors happening:
Event 129, storachi - Reset to Device \Device\RaidPort2, was issued. It appears every 30 seconds, from about the time I started the sync commamd (or it "hangs), until I restarted. Event 140: NTFS - The system failed to flush the data to the transaction log. Corruption may occur in VolumeID: X:, Devicename: \Device\HarddiskVolume8 Event 153, disk - The IO Operation at logical block address 0x1 for Disk9 (PDO Name: \Device\00000036) was retired Event 153, disk - The IO Operation at logical block address 0x11 for Disk9 (PDO Name: \Device\00000036) was retired Event 153, disk - The IO Operation at logical block address 0x21 for Disk9 (PDO Name: \Device\00000036) was retired
I understand that drives can go bad without Scanner reporting an issue as described in this forum here. The errors from that post seem identical to one of the errors I have listed above. Actually I have been struggling with the 129 & 153 warnings for a while as described in this post. One main question I have is how can I determine the actual physical drive that the 129 and 153 errors are happening for? I believe based on this experience I have now determined it, but it was really the Event 140 that made it obvious as it listed the drive letter. Without that I may not have known which drive was causing these problems. Essentially how can I determine the drive for \Device\RaidPort2 and \Device\00000036? I am hoping that they are one and the same, and they also point to the drive from Event 140 (x:\).
For those interested I got around the snapraid sync issue, but removing the bad drive from my configuration, and reverting to a single parity drive. After doing that the I ran a full sync, which seems to have completed successfully. I have a new drive en route to replace the bad parity drive.
I really am asking as I want to verify that the three errors above all pertain to the drive I am replacing and not another one currently in my PC.
Any help is much appreciated.
EDIT-----
I got the brand new drive. Put it in. Configured this new drive as a parity drive, tried to run a sync command, and it froze. In the Event Log I again see the "Event 129, storachi - Reset to Device \Device\RaidPort2, was issued." So this seems to be an issue when I connect a drive to that SATA Port, or at least when a drive connected to that port attempts to be read / write to.
Does this mean it may not be the drive, and perhaps the sata port / controller on the motherboard?
Additionally I still get the error below (although the Disk changed from 9 to 12). If I look in disk Management Tool, Disk 12 is actually one of my Pooled drive in DrivePool, meaning it is one of the Virtual Drives Drivepool creates.
Event 153, disk - The IO Operation at logical block address 0x1 for Disk12 (PDO Name: \Device\00000036) was retired
I also notice now :
Event 153, disk - The IO Operation at logical block address 0x1 for Disk13 (PDO Name: \Device\00000037) was retired.
Disk 13 in Disk Management is another virtual drive Drivepool creates.
The 153 warnings nay not be related to the other issue, as they have nothing to do with snapraid, but I am not sure if those errors are masking an issue with an underlying disk.
Thanks in advance,
Ken
-
Hmmm, that is a helpful comment. I recently added a drive and this is my first sync after adding the drive, and some files to it. Maybe I try that tonight and see if it resolved my issue.
Thanks!
-
Hello All,
I have an opinion question to ask the forum. For years I have been using Drivepool for pooling, and snapraid for protecting myself against drive failure.
I am currently running into an unknown issue with snapraid, where my sync command gets stuck at 0%, which I am unable to figure out.
That leads me to a point where I am questioning whether I need snapraid. Since I have Scanner along with Drivepool, I am wondering if the evacuation functionality in Scanner can protect me against the drive failures. Essentially if I always ensure that I have at least the capacity of one drive of free space available in my Drivepool I would survive one drive failure.
Currently I am running 6 data drives in the pool, along with 2 drives for parity. If I were to just add the parity drives to the pool I would have more than 2 drives worth of "free capacity" for scanner to evacuate to if there was a drive failure.
While snapraid has serve me well, and allowed me to recover files, just leveraging scanner / Drivepool could simplify my setup slightly.
Just wanted to get the communities thoughts on this.
Thanks in advance
-
Interesting you had issue's with Win 10. I am getting random lock ups, where I then can't do anything on the PC. My event log is full of storachi EventID 129 errors, which say "Reset to device, \Device\RaidPort1, was issued."
I tried reinstalling my chipset drivers, installed the Intel RST drivers but this error still persists. It appears in the log 30-60 times as hour. at this point I just want to try a clean start.
Can you give a little more details on "change the ownership of some of the directories" - I think I did this once before and had access issue's for some of the sub folders in my drive pool. Is there an easy way to do this?
Thanks
-
Is there a way I can just remove my drives, without any duplication to happen.
I recently update my server to windows 10. I am experiencing some weird behavior where it just seems to lock up from time to time. I haven't been able to track down the reason, and decided I just want to do a fresh install of the OS.
In addition to that I wanted to just recreate my DrivePool, meaning not have Drivepool recognize the existing pool. When I try to remove a drive, not matter what settings I have it is trying to move files to other drives.
How can I go about getting a fresh start on the new OS?
Do I just move all data folders out of the PoolPart folder to a root folder on the drive and then delete the PoolPart folder?
-
So here is my scenario.
I have a drivepool setup with 5 data drives pooled together. My intention was to not use the scanner / drivepool evacuation feature, as I run snapraid daily.
But, I must not have turned that setting off, so when scanner detected the drive failure it evacuated the drive and copied the files to the other drives available.
Snapraid never ran successfully after this happened.
When I got a new drive and added it to the PC, not knowing what drivepool copied successfully I ran a snapraid fix command and recovered all the files from the failed drive.
Now, there are obviously duplicate files across the 5 data drives.
Since my setup was in a state of flux, I decided to do fresh install, upgrade to Windows 10, and run this setup on a dedicated PC rather than in a VM as before.
My question is how will drivepool behave when I re-setup the new pool? Will it detect duplicate files and keep only one copy? Or is de-duping them something I need to take care of manually?
Thanks in advance,
Ken
.png.677de3ee60b1b84b05e7f5c5ce2cbf9c.png)
.png.60ef054f0c71519cfdcebb411e7e7c51.png)

Slow Drive Write Speed on DrivePool
in General
Posted
Hello,
I recently got around to setting up my SuperMicro DAS (link below). I purchased a Dell 200e card, popped it into my PC connected the cables and everything just "worked". I added two brand new drives they were picked up immediately and everything seemed to be working OK. Both new drives were fully scanned by StableBit Scanner and had no issue's reported. The initial scan took a very, very long time (weeks). Once it completed, I added the drives into Drivepool, and everything was working as expected.
I noticed last night that copying a simple 8GB file took around 45 minutes. This prompted my to perform some tests with Crystal Mark - and it confirmed I am getting extremely slow read / write speeds on both drives in the DAS. This may have been happening since the first setup - as most of my downloading / copying is automated, so I may not have noticed it right away.
I am looking for some help / assistance on steps to troubleshoot this. I have done basic steps such as restarted the main PC and checked the cable connections. I have seen that if this card is not flashed into IT mode that the drives can be passed in to the host all as RAID 0, but I don't know how to tell if that is the case. I can see all SMART details in Scanner, which leads me that they are just being passed through in JDOB.
If this card is not the best option, I am option to suggestions, as I got it cheap and can replace it.
Thanks in advance
DAS:
https://www.supermicro.com/en/products/chassis/4U/847/SC847E16-RJBOD1
Card:
https://techmikeny.com/products/dell-perc-h200-raid-controller?gclid=CjwKCAjw55-HBhAHEiwARMCszoj7JQn9sxgIKKLSGurUBgxjWLtMf026BR4-tJH9sM_tsm4rC-KVWBoCdOYQAvD_BwE
CrystalMark Results:
CrystalDiskMark 5.2.1 x64 (C) 2007-2017 hiyohiyo
Crystal Dew World : http://crystalmark.info/
-----------------------------------------------------------------------
* MB/s = 1,000,000 bytes/s [SATA/600 = 600,000,000 bytes/s]
* KB = 1000 bytes, KiB = 1024 bytes
Sequential Read (Q= 32,T= 1) : 64.519 MB/s
Sequential Write (Q= 32,T= 1) : 1.073 MB/s
Random Read 4KiB (Q= 32,T= 1) : 1.154 MB/s [ 281.7 IOPS]
Random Write 4KiB (Q= 32,T= 1) : 0.232 MB/s [ 56.6 IOPS]
Sequential Read (T= 1) : 22.636 MB/s
Sequential Write (T= 1) : 5.869 MB/s
Random Read 4KiB (Q= 1,T= 1) : 0.579 MB/s [ 141.4 IOPS]
Random Write 4KiB (Q= 1,T= 1) : 0.315 MB/s [ 76.9 IOPS]
Test : 1024 MiB [F: 0.0% (0.3/5589.0 GiB)] (x5) [Interval=5 sec]
Date : 2021/07/09 9:19:29
OS : Windows 10 [10.0 Build 19043] (x64)