Search the Community
Showing results for tags 'archive'.
Found 2 results
-
Hello together, I just optimized my Drivepool a bit and set a 128 GB SSD as write cache. I had another SSD with 1GB I had left I put into the pool and set drivepool to write only folders on it which I use most and should be fast available. This folders have also a duplication (the other Archive drives are HDDs). I'm not sure if this is working or the SSD is useless for more speed. How is drivepool working: - does drivepool read both the original und the duplicated folders if I use them from the Client? - will drive pool recognize which drive is faster and read from this first? best regards and thanks for your answers
-
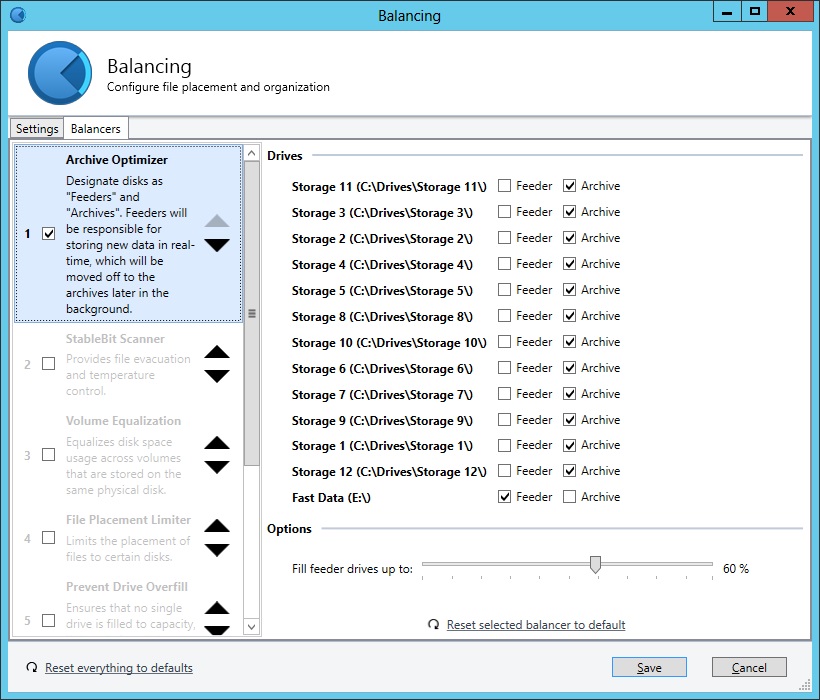
Hi all, I've been trying out the Archive Optimizer on my Drive Pool installation. I find that after a couple of hours the Feeder disk (SSD) becomes full. The pool remains in a 100% healthy state even though the bar graph beside the Feeder disk indicates that it has exceeded the limit. I guess the first thing is understanding what I expected the Archive Optimizer to do and if this actually aligns with its implementation. I would have expected that with Balancing settings configured to allow for immediate balancing, any data on the SSD Feeder disk would be scheduled for archive to the other disks in the pool. Furthermore, whilst unduplicated or duplicated data remains on the Feeder, the pool's health would be less than 100%. My pool's health remains at 100%. I do have some extra data on the drive outside of the Pool - Windows indexing database etc. I've tried a remeasure and trace logging. The only log entry is: "[Rebalance] Cannot balance. Requested critical only." Am I expecting this to do something that's not actually intended? Any configuration settings changes anyone can recommend that they find works well? Cheers, Salty. Edit: Running version 2.0.0.345 Beta, Server 2012.