


Mirabis
-
Posts
15 -
Joined
-
Last visited
Posts posted by Mirabis
-
-
The last version of CloudDrive throws an error after authorizing with my own developer keys:
"Error connecting to Amazon Cloud Drive"
"Security error."
ErrorReport_2016_07_19-11_08_21.7.saencryptedreport.zipError report file saved to: C:\ProgramData\StableBit CloudDrive\Service\ErrorReports\ErrorReport_2016_07_19-11_08_21.7.saencryptedreport Exception: System.Security.SecurityException: Security error. at CloudDriveService.Cloud.Providers.Registry.ProviderRegistryEntry.#Cre(ProviderMetadataBase #9we, Guid #2Ae) at #tme.#Kwd.#R5c(TaskRunState #c6c, ConnectTaskState #d6c, IEnumerable`1 #8we) at CoveUtil.Tasks.Concurrent.Task`1.(TaskRunState , Object , IEnumerable`1 ) at CoveUtil.Tasks.Concurrent.TaskGroup..() at CoveUtil.ReportingAction.Run(Action TheDangerousAction, Func`2 ErrorReportExceptionFilter) The Zone of the assembly that failed was: MyComputer
-
If none of the Specfic Method options are working, then it means that it may no be passing the data long via the normal methods. Meaning we'll have to get our hands on one (or more) and see what exactly is going on.
I have the same issue with my P3700 Intel NVMe drives... but have 1 spare. I'm willing to lend u one if shipping is covered, but we'll most likely be on opposite sides of the world xD
-
Got 3 of the He8 HGST SAS drives, but neither show S.M.A.R.T data or temperature

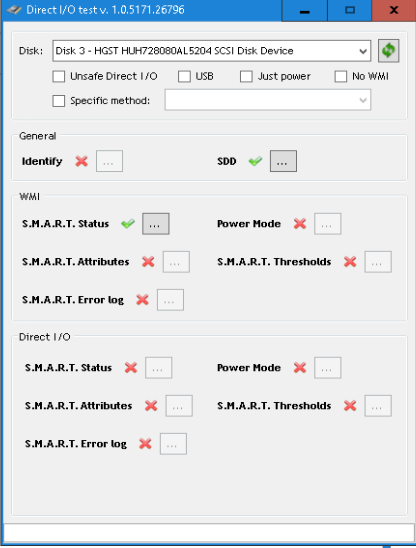
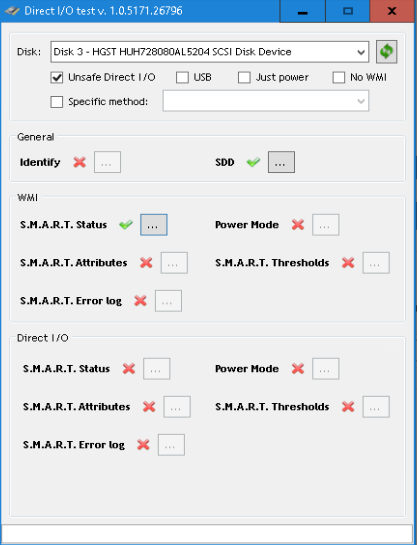
Tried all Specific Methods as well, nothing shows up.
They are connected by a IBM M5210 Raid Card (unconfigured good) -> Intel RES3TV360 (Expander) -> Supermicro Passive Backplanes BPN-SAS-846A / BPN-SAS-826A.I can see the temperature in MegaRaid Storage Manager / Speedfan, but not in Scanner
-
If the process is ongoing, there should be a couple of buttons to the right of the pool condition bar, an "X" to cancel, and an ">>" to boost priority.
however, this is still essentially a file copy. For a normal drive, tht would be roughly 4 hours per TB, under ideal circumstances. With a CloudDrive disk, it may be significantly longer, depending on your connection speed, the free space and size of the cache drives.
Worst case here, if you want, you cloud "forcibly eject" the specific drive from the pool, and then copy it's contents to one of the other drives.
This is definitely a more advanced bit, and requires much more "hands on", as you're essentially doing the disk removal manually (where as the UI automates it).
However, to do so requires installing one of the more recent StableBit DrivePool builds.
http://dl.covecube.com/DrivePoolWindows/beta/download/StableBit.DrivePool_2.2.0.676_x64_BETA.exe
Also, check the disk in question, and look at the "PoolPart.xxxxx" folder. the "xxxxx" part is the pool part ID, and is needed for the next part.
With the newer version, open up a command prompt, and run "dpcmd ignore-poolpart x: xxxxx" (where, "x:" is the pool drive, and the "xxxxx" is the Pool Part ID listed above). This will disk from participation from the pool, causing it to show up as "missing" in the UI, where you'd want to remove it.
From here, you can copy the contents of the PoolPart folder of that disk to whichever you want. In this case, you could add the new disk to the pool, and copy the contents of the PoolPart folder on the old disk to the new Poolpart folder on the new disk.
Updated the DrivePool but receive:
PS C:\Users\Administrator> dpcmd ignore-poolpart Y: f61eddb3-5d7d-4a0b-9f8f-dcdbf0661d92 dpcmd - StableBit DrivePool command line interface Version 2.2.0.676 Error: Incorrect function. (Exception from HRESULT: 0x80070001)
Tried Y: Y:\ "Y" "Y:" etc, no luck
-
Brilliant, Thankyou!
Sent from my iPhone using Tapatalk
-
Hello,
I recently started upgrading my 3TB & 4TB disks to 8TB disks and started 'removing' the smaller disks in the interface. It shows a popup : Duplicate later & force removal -> I check yes on both...
Continue 2 days it shows 46% as it kept migrating files off to the CloudDrives (Amazon Cloud Drive & Google Drive Unlimited).- I went and toggled off those disks in 'Drive Usage' -> no luck.
- Attempt to disable Pool Duplication -> infinite loading bar.
- Changed File placement rules to populate other disks first -> no luck.
- Google Drive uploads with 463mbp/s so it goes decently fast;
- Amazon Cloud Drive capped at 20mbps... and this seems to bottleneck the migration.
- I don't need to migrate files to the cloud at the moment, as they are only used for 'duplication'...
It looks like it is migrating 'duplicated' files to the cloud, instead of writing unduplicated data to the other disks for a fast removal.
Any way to speed up this process ?CloudDrive: 1.0.0.592 BETA
DrivePool: 2.2.0.651 BETA
-
Try installing the 605 beta. See if that helps.
Otherwise, yes, please do enable logging and reproduce the issue:
http://wiki.covecube.com/StableBit_CloudDrive_Log_Collection
I have the same problem, running (.592) but the update check gave nothing. Going to the site, last 'beta' is 463... Is there a special Beta Beta spot somwhere?
-
Are you storing the *.vhd(x) files on the DrivePool as well? Is that supported fine?
-
The 2.2.0.651 version should disable the "Bypass file system filters" option if the deduplication feature is installed.
The option is under Pool Options -> Performance. The "Bypass file system filters" option should be unchecked. if it isn't, then please do uncheck it.
As for the BSODing, this looks to be a hardware related issue, and not strictly related to our software.
Specifically, some of the crash dumps indicate a DPC Watchdog error, which definitely indicates a hardware issue.
I'd recommend running a memory test on the system, to start off with.
And I'd recommend running a CHKDSK pass of the system disk, to make sure.
Ah okay, did the following:
- CHKDSK on C:/ , seems to have removed the StableBit Scanner notification of filesystem issue
- DPC Watchdog was probably related to a supermicro driver ( no official support for 2016 yet <i know, shrug>)
- Manually disabled File System Bypassing....
- Hyper-V drive checkpoints are now forced to another location ( REFS + SSDs) as they bugged out on the pool
- Enabled deduplication per drive ( see 100-200GB save atm)
- Can probably force Hyper-V files 3x duplicated to 3 specific drives & to gain some more dedup savings;
Absolutely liking the flexibility with Folder specific deduplication vs what I achieved on Storage Spaces
- Hyper-V VM's are still a bit slow though;
- Some won't start as an individual drive is full - yet pool shows space (prob have to wait for balancing);
@ CloudDrive:
- All Cloud Drives have a dedicated 64GB SSD for local cache with 10GB pinned and 'expandable' as config, formatted as NTFS. ( Tried NTFS + dedup.. it showed an odd 2TB savings...xD - disabled it)
- I'll probably pick Folder specific duplication & x drives, to have 2 copies go to two seperate clouds, and 2 local
- OR i'll have another tool / sync from the DrivePool to the Cloud;
- Amazon keeps detaching itself... i'll try later on.
@Scanner
- I have enabled some of the heat throttling options ( works great as my cache drives shoot up to 60*C on bulk transfers);
- It keeps throttling with 'bus saturated', but an M1015 SAS with only 8 HDD's (WD Reds)... doing 120MB/s... don't think that saturates it? Any way we can manually configure that bus limit?
- EDIT: Found your recommendations on: http://community.covecube.com/index.php?/topic/1990-difference-between-versions/?hl=backupand disabled 'do not interfere with same bus' and scans turbo'd up from 120 to 450MB/s per disk ( /B/sec DISK I/O
Thanks for the great responses!
-
For the BSOD, check to see if the memory.dmp file exists, (ignore wincrashreport). Also, try seeing if any minidumps have been created.
As for the read striping, you're definitely not seeing activity in Resource Monitor?
10TB over 256KB/s .... ouch.
When this happens, could you do this:
http://wiki.covecube.com/StableBit_DrivePool_UI_Memory_Dump
This depends on your bandwidth (upstream and downstream).
Try setting the storage chunk size and the minimum download size to larger values. This may improve performance, as this may help get up to "full speed" with the download/upload.
Deduplication on the pool (the large drive itself) would be best.
The reason for this is that it would get all of the files, and not just some of them.
However, because it's not a block based solution, it doesn't work on the pool at all.
As for the individual drives in the pool, yes it does work.
And it only works per drive (well, per volume). So if some of those linux VHDs were on a different drive, they wouldn't get dedup-ed "fully". It would occur per disk.
The issue here is that StableBit DrivePool's default placement strategy is to place new files on the disk with the most available free space. So the linux VMs may not end up on the same disk, and then couldn't be deduplicated.
That means that you won't save as much space with deduplication, as you would if you were able to dedup the entire pool.
But as I said, it does work on the underlying disks. However, there are caveats here, because of how the software works.
Since you're using the public beta build, you're fine. We introduced a check into it that looks for the deduplication filter.
Why is this important? Deduplication works by *actually removing* the duplicate data in each file and placing the raw, duplicate blocks in the System Volume Info folder.
It then uses the aforementioned "deduplication filter" to splice the partial file and the rest of the raw data back together, into a single, full file.
The issue here is that by default, the pool bypasses the filter for the underlying disks. Meaning that we would only see the unique data, and not the duplicated data in the file. This is done for performance and compatibility reasons, but it completely breaks deduplication.
Disabling the "bypass file system filters" features can cause issues (and a slight performance hit), it fixes the issue. And the 2.2.0.651 version automatically does this when it detects the Deduplication feature.
By " Disabling the "bypass file system filters" features can cause issues (and a slight performance hit), it fixes the issue. And the 2.2.0.651 version automatically does this when it detects the Deduplication feature." u mean that it will automatically disable/enable the Bypass file system filter option OR regardless of the setting, it will detect the deduplication filter? Right now i have dedup enabled on all individual drives, but 'Bypass File System Filters' is still enabled.
@ BSODS I had both the memory.dmp and minidump files, uploaded both to: http://wiki.covecube.com/StableBit_DrivePool_System_Crashes#Submit_a_crash_dumpwidget.
-
On the forum everyone is talking about Deduplication on the DrivePool and it may or may not work - but why is no-one using deduplication on the individual drives that form the pool? That way we keep the file duplication across drives, but dedupe on each drive.
e.g. Save 10x *.vhdx to 3 disks (file duplication). And as they are all Ubuntu 16.04, deduplication saves space on each individual volume - while keeping the files on 3 disks as well.
Or did I understand wrong xD -
What version of StableBit CloudDrive are you using?
Is read striping enabled?
Also, are you using the UI to confirm access? Or using something like RESMON?
**********snip*********
By crash, you mean BSOD? If so, please grab the memory dumps.
http://wiki.covecube.com/StableBit_CloudDrive_System_Crashes
And if you're not already, could you see if the 1.0.0.592 works better?
http://dl.covecube.com/CloudDriveWindows/beta/download/StableBit.CloudDrive_1.0.0.592_x64_BETA.exe
Ah, you're using an older version, are you not?
1.0.0.463, correct?
If so, this is due to a weird API issue (meaning, it's one that Google didn't actually include in their well written documentation, and no, there is no sarcasm here, actually). Specifically, we cannot query the same drive more than 20 times in a short period of time (seconds, IIRC). It's a known issue and it's been addressed in the newer beta builds.
However, it may require you to recreate the drive, as it's partially an issue with the "format" that the raw data is using.
As for Amazon Cloud Drive, again, try the newer build. There are a lot of stability, reliability and performance fixes. It may cause the Amazon Cloud Drive provider to run better.
And as for re-enabling it, with the newer version, you should be safer to do so. Though, I'd recommend making sure that you use different drives for the cache, to optimize performance.
For Google Drive, it may not be necessary. Some providers, like Amazon Cloud Drive, it's essentially required (it loses data if you don't verify, but if you always verify, it seems to be fine ....)
Basically, it changes the upload process. Instead of clearing out the update data, it downloads it, and verifies that it uploaded properly. If it did, it clears the data. But if it doesn't, it will reupload it.
If you have the bandwidth (500/500, mbps, I'm assuming), then it's worth having on, as it's another integrity check.
- Read striping is enabled in the DrivePool and I've checked the DrivePool and Resource Monitor GUI's to check for activity.
- Yes, BSODS - I tried to grab the memory dumps but WinCrashReport didn't show any...
Versions I'm using: (Started using StableBit with those... 3rd day now - and created the drives with them.)
- CloudDrive: Version 1.0.0.463 BETA
- DrivePool: Version 2.2.651
- Scanner: Version 2.5.2.3103 BETA
I thought I downloaded the latest beta's from the web ;S.
Amazon Cloud Drive: I'll try and re-enable it after I've converted my pools to StableBit... server been down for days now.. and still 10TB to transfer... which with 256KB/s....is hopeless.
Another Issue: At times after closing the DrivePool.UI.exe it will not show on re-launch, but does open another process (task manager)
As for Chunk Size: Any recommended links to find the proper 'chunk' size for Google Drive/amazon/providers? a search on the forum gave nothing
-
Hardware Specs:
2x E5-2650v3
128 GB DDR4 ECC RAM
6x WD RED 3TB
4x WD RED 4TB
2x Sandisk Ultra II 240GB SSD
4x Sandisk 64GB SSD
NIC Teaming / 2Gbit LAN500/500 WAN
-
Hello,
I'm using Windows Server 2016 TP5 (Upgraded from 2012R2 Datacenter..for containers....) and have been trying to convert my Storage Spaces to StableBit Pools. So far so good, but I'm having a bit of an issue with the Cloud Drive.Current:
- Use SSD Optimizer to write to one of the 8 SSDs (2x 240GB / 5x 64GB) and then offload to one of my harddisks ( 6x WD Red 3TB / 4x WD Red 4 TB).
- I've set balancing to percentage (as the disks are different size)- 1x 64GB SSD dedicated to Local Cache for Google Drive Mount (Unlimited size / specified 20TB)
Problem 1:
I've set my Hyper-V folder to duplicate [3x] so I can keep 1 file on SSD, 1 on HDD and 1 on Cloud Drive... but it is loading from CLoud Drive only. This obviously doesn't work as it tries to stream the .vhd from the cloud.
Any way to have it read from the ssd/local disk, and just have the CloudDrive as backup?
Problem 2:
Once the CacheDisk fills up everything slows down to a crowl..... any way I can have it fill up an HDD after the ssd so other transfers can continue? After which it re-balances that data off?Problem 3:
During large file transfers the system becomes unresponsive, and at times even crashes. I've tried using Teracopy (which doesn't seem to fill the 'modified' RAM cache, but is only 20% slower... = less crashes.... but system still unresponsive.
Problem 4:
I'm having
- I/O Error: Trouble downloading data from Google Drive.
- I/O Error: Thread was being aborted.
- The requested mime type change is forbidden (this error has occurred 101 times).
Causing the Google Drive uploads to halt from time to time. I found a solution on the forum (manually deleting the chunks that are stuck). But instead of deleting I moved them to the root, so they could be analysed later on (if neccesary).
Problem 5 / Question 1:
I have Amazon Unlimited Cloud Drive, but it's still an experimental provider. I've tried it and had a lot of lockups/crashes and an average of 10mbits upload - so I removed it. Can I re-enable it once it exists experimental and allow the data from the Google Drive to be balanced out to Amazon Cloud Drive (essentially migrating/duplicating to the other cloud)?
Question 2:
Does Google Drive require Upload Verification? Couldn't find any best practices/guidelines on the settings per provider.
Settings Screenshots:
- Balancing Settings: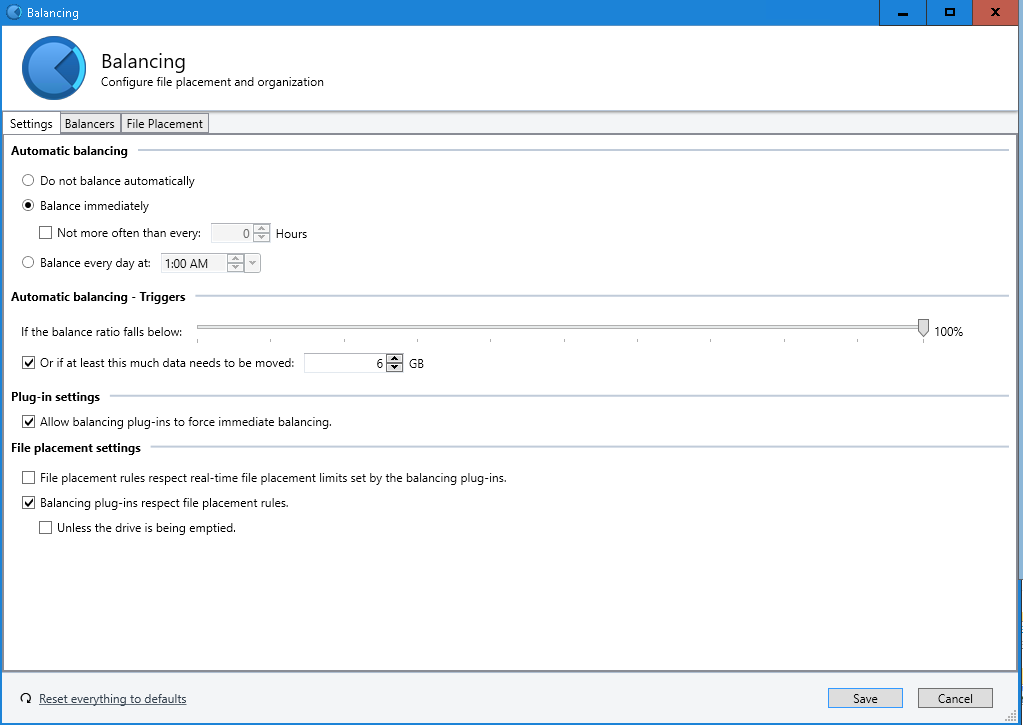
https://gyazo.com/2cfe5c10e0f6fc45774a2e01d1a1f67a- Balancers:
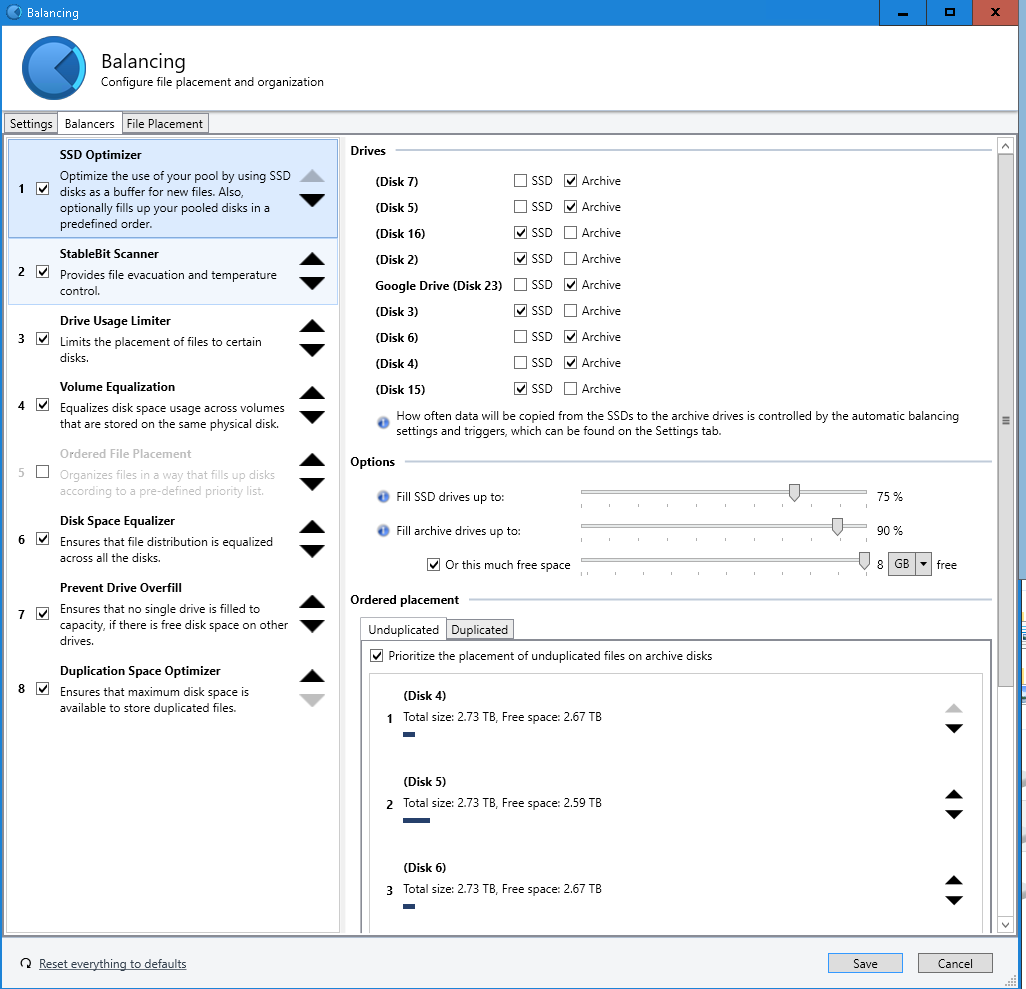
https://gyazo.com/1a72a73fe463238fe917806d7ea9ec0a- File Placement:
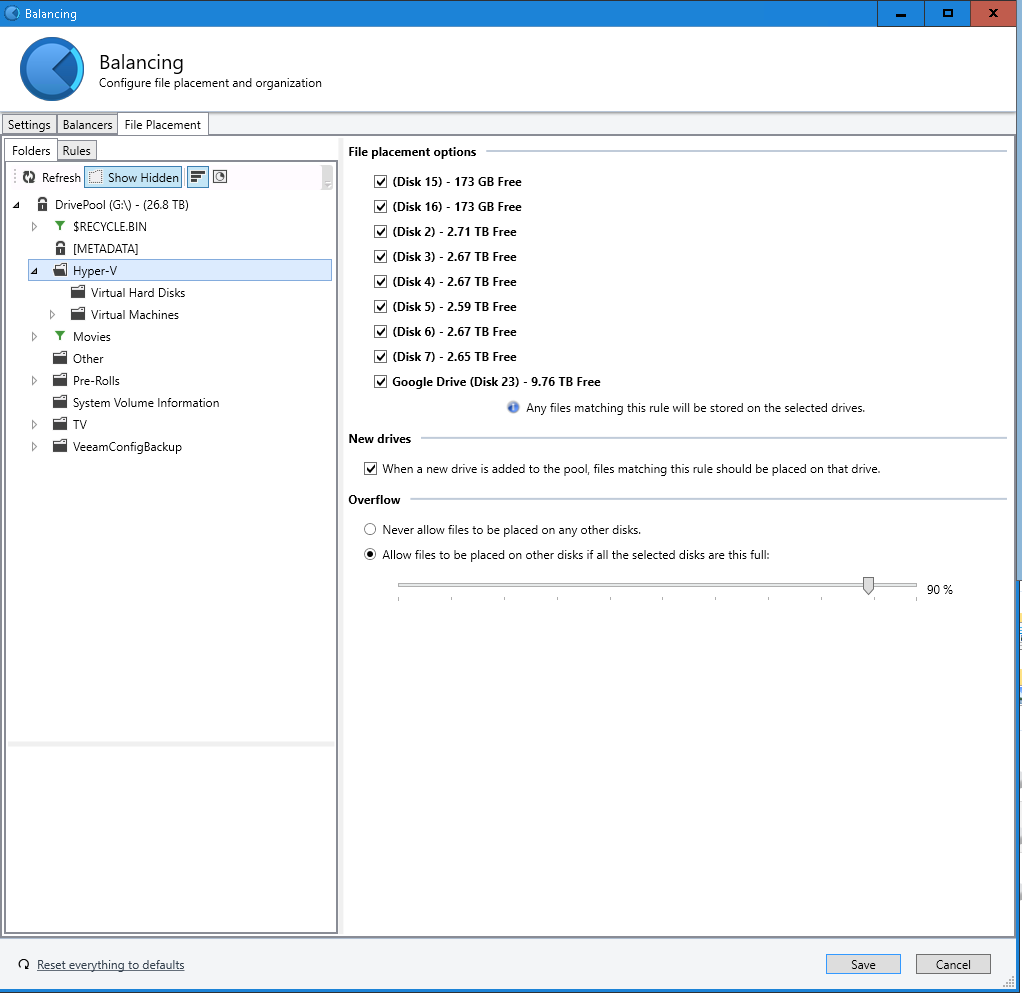
https://gyazo.com/f74187029ad0fe924fc6cd41fddfa519- Folder Duplication:
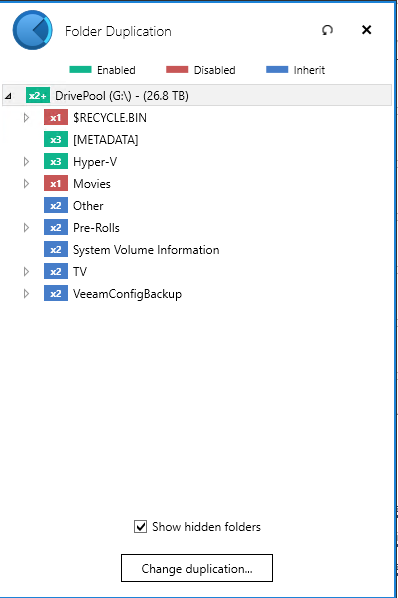
https://gyazo.com/704c6264922c064ae7fae5b021ddb664
NVMe smart
in General
Posted
Yeah didn't show anything, same for my he8 SAS drives on the MegaRaid M5200. A little bit busy this week, but will try to post a ticket, screenshots and stuff end of the week.
Sent from my iPhone using Tapatalk