


Midoxai
-
Posts
10 -
Joined
Posts posted by Midoxai
-
-
Thanks for your explanation. Then it makes sense to use only 1 MB as chunk size. I hope Microsoft will add partial download soon.
-
I've seen the public response of Alex in the issue:
That is intentional because OneDrive for Business doesn't support partial downloading of chunks (aka HTTP range requests). This means that for every read, no matter how small, we end up downloading at least the chunk size (1MB maximum currently).
If I understand it correct, there is a big overhead while making small reads. On the other hand I think that the actual max chunk size of 1 MB increases the overhead in download-time for big files, because the maximal number of download threads is limited so it adds one Round-Trip-Time to the download-time for every additional Request.
- Ginoliggime, Antoineki and KiaraEvirm
-
 3
3
-
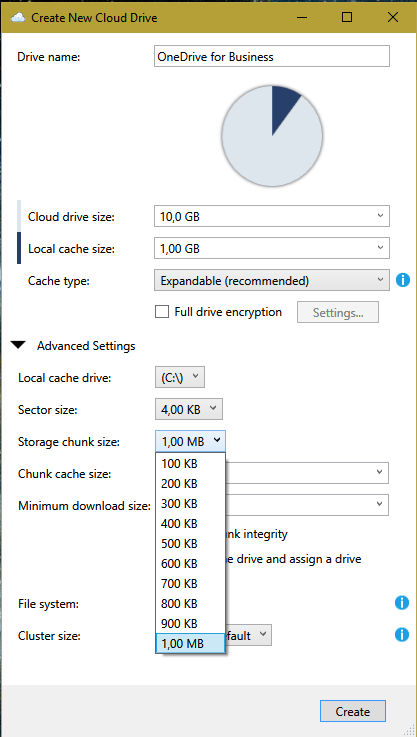
Are there any plans to add increased chunk sizes with Onedrive for Business? I can choose max 1 MB. (v .763)
-
For me that means that the cache should be as little as possible / as little as you can upload in a accepteble period of time.
-
When i add CloudDrive to a DrivePool Pool and i use replication of all Files. For example i have a Hard Disk 'A', which is full of Data and a CloudDrive 'B' with equal Size. No more other Hard Disks.
Does this mean i need a second hard disk with at least the size of A, so that CloudDrive can use this Drive as Cache? Or does DrivePool only replicates as much data as the cache can hold?
-
I did not find information about it...
Would CloudDrive support something like snapshoting?
At the moment Encrypting-Trojans (aka CryptoLocker) are popular and because DrivePool is adding a real Drive, these Trojans can encrypt all files in it too...
I know, that DrivePool supports Volume Shadow Copies, but normally these will get deleted with all original Data
I'm thinking about multiple Versions of the same File and in general the following possibilities:
- revert to a previos snapshot
- mount a read-only Volume out of a previos snapshot
- automatic snapshot rotation (for example with Grandfather-father-son rotation scheme)
- automatic snapshot when no write operation happens (for a consistent filesystem)
- snapshot replication (nice to have, but DrivePool can also be used)
Does Cloud-Drive uses internally a b-tree representation?
-
Deduplication would be a cool feature. It would save bandwidth and storage.
-
Hi,
i suggest Strato HiDrive as the biggest (private and business) Storage Provider from Germany.
General Infos:
Get Started
SDKs
API Refernce
Pricing
Free Account
Best regards
- KiaraEvirm and Ginoliggime
-
2
-
Hi,
I have some Questions about using Drivepool with server 2012.
i'd like to duplicate a lot of files and some Hyper-V VHDs. The files are no Problem, but what can i suppose on VHDs?
Can i store vhds on my pool without worrying about the data, which is written in a vm? One vhd can get a size of 500Gb or more.
What happens when i enable the automatic balancing with the vhds? Do they get balanced without shutting down the vms? Can i exclude the vms/vhds from the balancing process?
What happens when i remove one disk from the pool?
What happens, when i create a vhd which is greater then the free space of the volume on which it is stored?
Can i use the integrated per-volume-deduplication feature of Server 2012 to reduce the data, which is stored on one Volume? Can Drivepool still read the deduplicated files?
Thanks for the answers
best reagrds
Quorum based file movement by hash?
in General
Posted
Hello,
Recently i read about HDFS. I think rebalancing the files on file hashes with a quorum would be a cool feature.
This would work in the following way:
The Balancing could also do the following
This would add a new level of integrity for the files.