zeroibis
-
Posts
61 -
Joined
-
Last visited
-
Days Won
3
Everything posted by zeroibis
-
OK it does show up when I use Storage Spaces. However, I find that storage spaces is significantly slower than when I was using disk manager and I do not understand why.
-
Looking around it appears the issue is that creating raid 0/1 arrays from disk management is not supported in combination with Drivepool and that you are supposed to be using Storage Spaces instead for that. I will be attempting to create the RAID 0 in Storage Spaces instead.
-
I have a RAID 0 volume (E) but it does not show up in DrivePool as a possible drive. Why is it not showing up and how can I fix this? Is there another software RAID 0 solution I can use that DrivePool will like?
-
I agree that the Scaner would not be able to work if you had your drives behind a hardware raid or anything other than an HBA as the smart data is not passed directly to the OS. As a result you are not able to see drives like that under CrystalDiskInfo either. I think I got some old 1tb drives lying around maybe I could hook them up and see if I can still get SMART data after putting them in software raid 0. Interesting about your LSI 9201-16e that you need to have is pass the SMART data. Is that card flashed to IT mode so it bypasses the internal card firmware? As far as speed goes software raid 0 can be just as fast to even faster than hardware depending on the system. If your using an intel atom your going to be better off with hardware I would suspect. I will be running on a Ryzen 3 1200 which should offer plenty of CPU for simple raid 0 especially on mechanical drives.
-
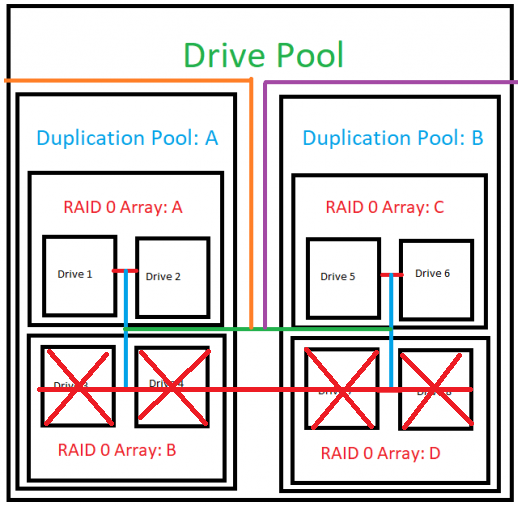
Oh for reference I 100% plan to be running Stablebit Scanner that was one of the major draws of moving away from hardware raid. Would the scanner still not work when using software raid 0 as the underline drives are still accessible by the system directly? Also want to point out that with raid 50% of the drives could fail and you lose nothing just like it is possible for 50% of the drives to fail in the duplication pool as seen in attached image. Just to verify if I can pull the drive data in a program like CrystalDiskInfo than Stablebit Scanner will work? Because if I create a software raid 1 in diskmanagement I am able to see the underline drives in CrystalDiskInfo and get smart data. I assume the same would be true if I was to create a raid 0 in diskmanagement instead.
-
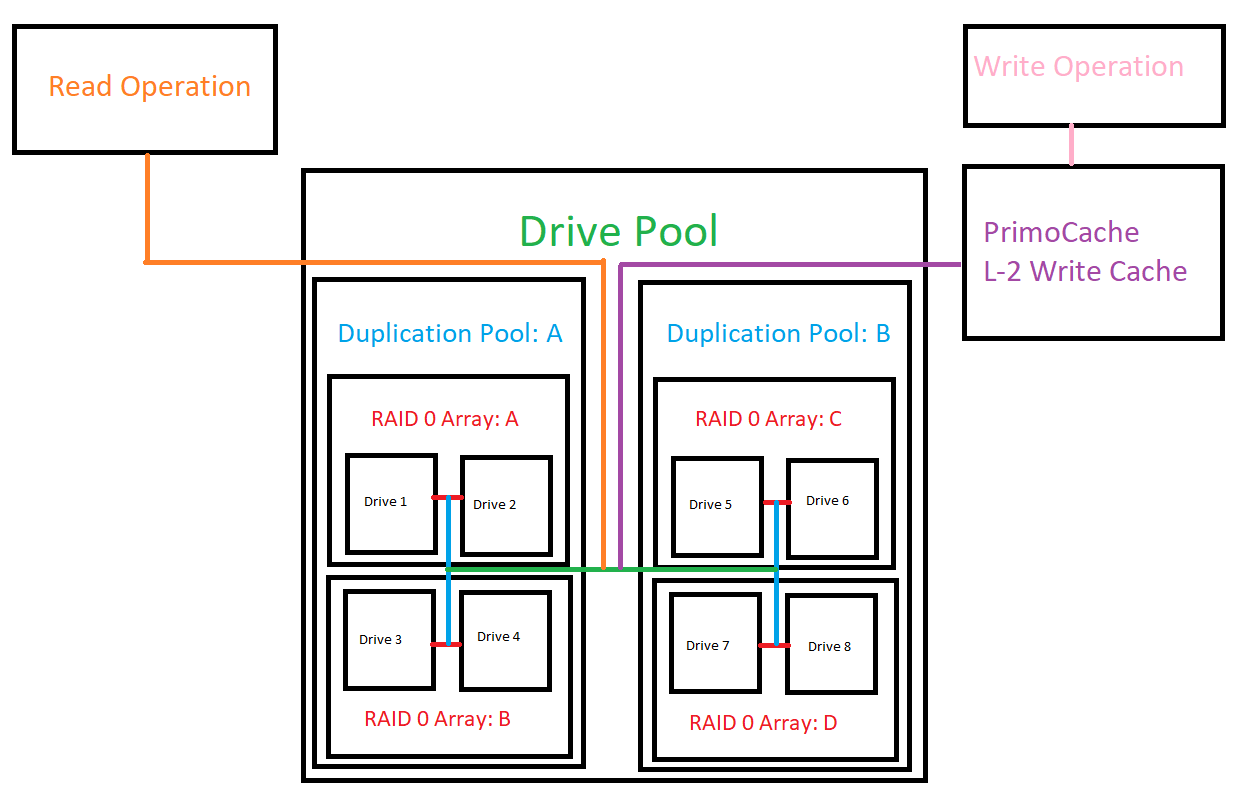
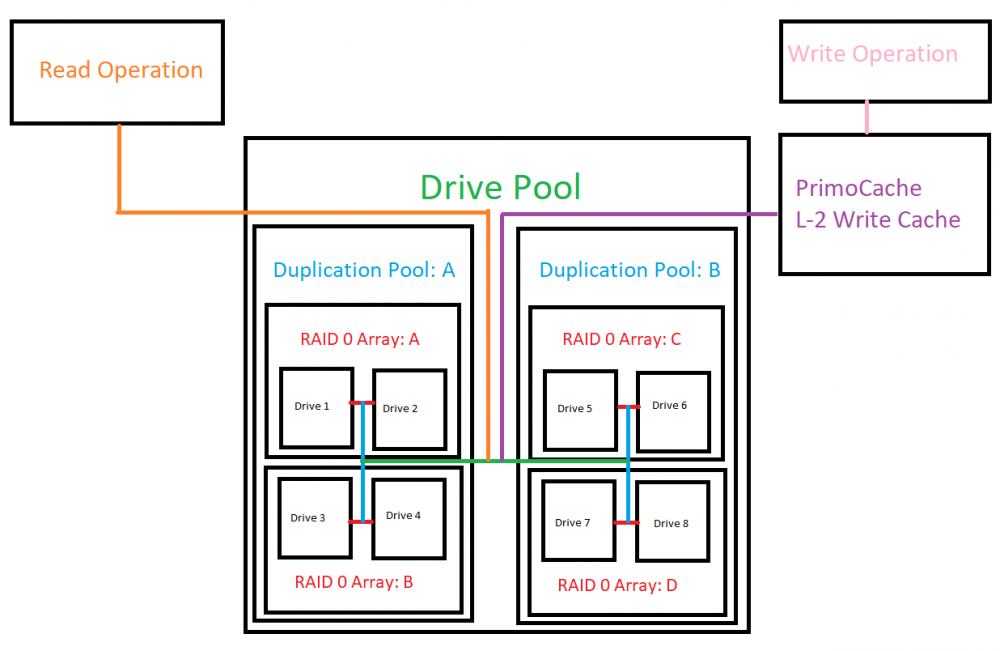
Just for those who happen across this thread I decided to include a diagram of option C from my earlier post. This is an I/O logic map of using 8 drives which are paired off into RAID 0 arrays and then paired off into Duplication pools and then paired off into a resultant drive pool with PrimoCache being used for a SSD write cache. The advantages of this system is that in the event of data loss you only need to restore data from your backup of the given Duplication pool that experienced a failure instead of the entire drive pool. You also get the performance benefits of the raid 0 array. Additionally you can improve reliability at the hardware level with the following logic: Raid 0 Array A can not use drives which are connected to the same controller and or PSU/PSU line as Raid 0 Array B. Raid 0 Array C can not use drives which are connected to the same controller and or PSU/PSU line as Raid 0 Array D. This would make the resultant pool immune to a failure resulting from the controller or the PSU/PSU line.
-
Ah very good to know, that setting eliminates the issue! Good to know and also another reason just to use Primocache instead and just avoid any complication.
-
Ah that is a good point about rebalances! I did not even consider that! Perfect example of why I am double checking my understanding of all of this. Is there perhaps any log of when these rebalances occur. If this is the case if you had data loss you could simply check the log and see that there was a reblanace since the last backup state and if so then you need to run a full restore instead. A possibly better solution would be if there is a way to control how the balancing works. For example I have DrivePool configured so that data is evenly distributed on drives based on their capacity %. However, I configure it to never move files that are already placed. So if I delete some files it will be out of balance and stay out of balance until I put some new files in the system. At this time those new files would logically be placed first on the drive that is lower than the others. So I guess the question is if it is possible to completely disable rebalencing and have the balancing only take place when your adding files to the pool.
-
Yea I know that hierarchical pools are not required it is that they are ideal from a backup perspective. Take the following scenarios: A) You have 8x 2tb drives in one big pool with file duplication. You have it set so there is 2 of every file. Now two drives in this pool fail. Only the data that was contained on both of these drives was lost. You however have no idea what this data was and so to recover you will need to pull an 8tb recovery and then tell it to skip any files it finds so that your restore will give you the files you are missing. Problem is that you need to have an 8tb recovery image sent to your house or download it. You have 8x 2tb drives separated into 4 pools of 2 drives each where each pool has duplication. You configure backups to run on each of these individual pools. You then join these 4 pools into 1 large storage pool. You know that the data on each of the 4 smaller pools are exact copies of each other so now when 2 drives fail in a scenario that created data loss you can simply download the 2tb recovery of that individual pool. Also if you really want to increase performance you could do: C) You have 8x 2tb drives and separate them into 4x raid 0 arrays in disk manager. You then take the 4x 4tb arrays and create 2x duplication pools of 4tb each. You then configure backups to run on the duplication pools. You create a final pool of the 2x duplication pools. If two drives fail which are in the same duplication pool and on different raid 0 arrays you will need to restore 4tb of data but because you know what data was stored on that array you can easily obtain a 4tb recovery of just what you need. In addition you get a ~2x performance advantage. D) You have 8x 2tb drives and separate them into 2x raid 0 arrays in disk manager. You then take the 2x 8tb arrays and create a duplication pool of 8tb total. If two drives fail and each is on a different raid 0 array you lose 8TB of data. You need to restore from your 8TB size backup. Risk Analysis: A) Lowest risk with up to 2tb lost but with a chance in single drive failures to evade file loss altogether if backup to other drives can be completed and same performance as B except that file restores will take longer and are more expensive if you need to have a restore drive shipped to you. Slightly more or less risky then A although in worst case for both you lose 2tb of data each and for the same performance you could actually under the right conditions lose 4 drives at the same time without data loss as long as none of them share a duplication pool. Benefit is that restores are significantly faster than A C) Riskier than B in that you could lose twice as much data in the event of worst case two drive failure but it is still more reliable on average then A in that you could sustain up to 4 drive failures at the same time without any data loss if your lucky. You also get twice the performance. Your restore will be twice as slow as B but still twice as fast as option A. D) The most risky option you can lose everything if one drive in each raid 0 fails. Restoring is the same process as with A but your actually restoring everything instead of just what is missing. For my needs C may be the best option because I am transferring unedited RAW files and master video files from the server to client systems fir editing. The client systems are loading them on to 960/970 EVOs over 10GE network. So both read and write speeds are important to me. Trying to do an emergency recovery from parity data is too slow, it is faster to just have a backup HDD overnighted. Key here is what you find to be acceptable redundancy weather it be 2 drives or 6 drives the next step is figuring out how when all that redundancy fails how long and how complicated is it to restore from backup. In this case options A and D are the worst in that you need to pull a backup from everything and B and C are superior in that you know what you need to pull. If I did not need the performance from C I would use option B because of the simpler recovery as opposed to option A. I suppose in theory you could also create 4x 2tb duplication pools and then create a single raid 0 array across all of them. In theory that would be the highest possible performance as you would get even higher write speeds but I do not think that the underline duplication pool would work if you did it this way. Lastly, you are 100% correct that anything like option C and D are completely insane for a normal file server where read speeds are not an issue especially if your only on a 1gb/s network.
-
Ah very good to hear about the folder mount points, I suspect I will need to use a demo and verify that backblaze is able to to backup files discovered in such a folder. If that is the case it should be very easy to use backblaze as a backup solution for protecting individual mirrored pools. My focus here was to ensure that there was a simple to implant disaster recovery for when local file loss actually occurs. It seams the issue here is you need to make sure that you create all your duplication pools individually and then pool your pools so you can have 1 big drive. The con with this approach is that if and when 1 drive does fail the reaming drive that has the files will not automatically duplicate the files to other drives because those drives are outside the duplication pool. In this way it is not any better or worse than raid 10 from a reliability perspective except that unlike true raid 10 your not going to lose everything if two drives with the same content fail at the same time. Now as far as extreme performance goes I suppose one could make a software raid 0 of X drives and a second raid 0 of X drives in windows disk management and then add the two resultant raid 0 drives to a duplication pool to create an effective raid 10 which would have the performance of X write speed and ~2X read. Logically in this case if you lost a drive from both raid 0 sets at the same time you would lose everything. Nice to hear about Primocache that sounds like a great option!
-
I have been looking at DrivePool for sometime and as I get closer to a new build I had some things I wanted to verify: 1) Drive pool will work with backblaze and I can backup my pool just as if it was a normal HDD. 2) It is not possible to have real time duplication enabled and only use a single physical SSD for caching. (I wish you could just use a single drive as a literal write cache where it taking the data off the cache as fast as it can and placing it on a pool with real time duplication, in this way your SSD functions the same as the DDR cache on a raid controller where there is no duplication in the DDR.) 3) Close to real time duplication is possible when using a single physical SSD for caching. Can I still have real time on the drives it is writing to? How close to real time can we get? 4) Can not preform a single move operation that is larger than the SSD cache to any pool using said SSD cache. Now I use terracopy so I can override this and preform the move operation anyways but what will occur in this case? What if I am moving a single file that is larger than the SSD cache? 5) Read operations take advantage of multiple drives and can do so at the block level. If I have a large file that is on a pool containing 2 drives with duplication it will read the file from both drives. If I had a file on a pool with duplication and 4 drives (assuming there is only 1 duplicate) it would read at the same speed because the file is only stored on 2 of the 4 drives and thus read speeds are limited by the number of duplicates and not the number of drives in the pool (as compared to raid 10). 6) In a raid 10 like pool where you have at least 4 drives and file duplication on if you were to lose two drives at the same time and those drives were duplicates of each other there is no function of the program that can tell you what files you have now lost. (This seems like something that would make a great feature) 7) Possible solution to ensure you have backups for the scenario in #6 would be to have backblaze backup each duplication pool individually so that if you lost all the drives in that pool the restore is very simple. A problem with this is that windows can only have 26 drive letters. Thus you could have a maximum of 24 duplication pools 1 pool of the duplication pools and your C: drive. Perhaps it is possible to get around this if you link a duplication pool to be a folder on your C drive, I am not sure if Backblaze would follow it. Basically at minimum for example I could do the following: Create duplication pool named "D Pool 1" of >=2 drives and assign it to drive Z Create duplication pool named "D Pool 2" of >=2 drives and assign it to drive Y Create pool containing D Pool 1 and D Pool 2 and assign it to drive D Set backblaze to backup drive Z and Y (can it do this or will it fail to see the files?) Now if you lose a duplication pool that was part of a larger pool it is easy to pull a backup of just that D Pool # from backblaze. In this way you do not need to worry about what files from the larger pool are missing because those files are in their own backup. If you have the freespace you can simply restore the files from your D Pool # backup to your larger pool and bam all your files are there now. Sorry for so many questions, I just want to ensure that my understanding of how DrivePool operates is correct so that I am able to plan accordingly.