Matt173
-
Posts
7 -
Joined
-
Last visited
Everything posted by Matt173
-
Hi, I am experiencing serious issues with the CloudDrive product in connection with my Microsoft One Drive accounts. I have 5 personal OneDrive accounts and successfully added them to the CloudDrive app. However, almost every day when I reboot the computer or wake up the computer from sleep either one or multiple of the accounts disconnected and error messages pop up: "Drive cannot be mounted", "Drive cannot be mounted, the drive was forced to unmount because it could not read data from the provider", "Can't reauthorize drive OneDrive1 - 1.00 TB. Drive data was not found when using provided credentials.", and "There was an error communicating with the storage provider. Sequence contains no matching element". I suspect that there is a bug in StableBit's API to Microsoft's OneDrive authentication process. Even though I authenticated and even successsfully reauthenticate I get constantly disconnected from the accounts. I already tried "CloudDrive_SynchronousServiceStart" to "true" and also tried running the service "StableBit CloudDrive Service" as "Automatic (delayed)" and none solved the problem. Any advice or anyone else in the same boat? Thanks
-
I went with FreeNas on a VM and disk pass through. It provides resiliency in my current setup but also performs well on read striping across mirrors. I know my use case is very specific and unorthodox in that I have 4 copies on 4 different drives but as initially mentioned I do not care about capacity because a single drive capacity is sufficient for what I need. Aso, FreeNas is a pretty mature product and it works so far very well with my 10Gbe network and read performance on 4 HDD disks exceeds 600 megabytes/second (my 4TB Enterprise disks have sequential read performance of 170 megabytes/sec each. )
-
Well, thanks for chiming in. In fact I first came across your thread when I searched for a solution to my problem and I only considered DrivePool after you were assured in your thread that a beta version at that time would resolve the problems. Apparently not much changed since then. Having processed all information and thoughts my conclusion on Drive Pool and Read Striping is as follows: DrivePool intends to be intelligent about selecting the fastest drive for each individual thread that requests reads. And it does seem to work. When two threads or more request data concurrently then DrivePool also seems to do a decent job to service those requests given mirrored data is available. That is all fine. But, calling it even in the remotest Read Striping is at best misleading and false. And I noticed that apparently the owners of this product do not have any intention to add or improve on this feature because several threads, yours included, came across as being silenced with word interpretations and subsequent silence. Its great that DrivePool offers a feature that parallelizes multiple concurrent read requests concurrently. But that is NOT read striping and should not be called as such. Also, the algorithm is way too sensitive about availability and I/O. The understanding I got from explanations by DrivePool owners/reps is that high priority is given to availability. That, however, does not serve anyone and is not even how Windows does it. Windows is very eager in its I/O and bandwidth consumption on reads. It does not leave much overhead for other processes to consume resources when Windows issues a read request on a single resource such as a disk. And that is good that way because it maximizes throughput for the first-come-first served requester. I put this one down as a classic tale of developer arrogance vs subservient owner/management as can be seen in many ventures. Instead of management driving consumer demand and instructing developers what to do , here apparently you have a knowledgeable developer hedge hogging the entire product because he/she believes and insists that his/her work and ideas must be right and by default better than what the consumers demand. Each time Christopher was confronted with hard cold facts and figures (which by the way, Christopher, users actually wasted time on and did mostly in their quest to make YOUR product better, something they don't get paid for but YOU), Christopher promised to get back to the developer and was either never again heard from or replied that the developer insisted the current way was the right way to go about things. No, it is NOT the right way about going things, and I took the time to provide screenshots, test figures, numbers, and facts. Yet, the fact that for a single read DrivePool constantly switches in sub-second fashion from one to another drive, sometimes 2 drives together, sometimes one drive reads at 100 megs/sec , the other drive at 5 meg/sec and so on. That makes zero sense and is a bug or just plain oversight and the wrong way about going things. I am not working at that company so in the end I have to rest my case and as communicated I decided to move on to another product. But the way management handled cases such as this leaves a bitter aftertaste. But then I tend to be a perfectionist and kind of hold others often to similar standards, which is obviously wrong. I do not know, maybe the community of DrivePool at large loves the current way mirrored reads are done, who knows. I cannot for the love of God figure out why that would be the case but this is for management to know and decide. I rest my case.
-
This is what is written on the website :"read striping : when reading a duplicated file, StableBit DrivePool can read from multiple hard drives at the same time in order to achieve better performance" Without wanting to engage in word plays the advertised feature describes exactly read striping across mirrors for individual file reads (notice the use of singular in the feature description of "file" . It clearly advertises performance improvements, read, throughput, of single individual file reads. Well, you mentioned this is not the case with this app and for that I am thankful as it has become clear that this software app is not solving my problem. I need reasonably fast read speeds over large data sets, large enough that SSDs cannot be considered, with the requirement of some basic resiliency. Drive pool unfortunately does not provide the hoped for read throughput on individual file transfers. Why I bothered to in detail describe the behavior I experienced was because the algorithm is way too sensitive (I argue its borderline buggy) to small changes in various variables that cause the algorithm to switch from drive to drive during single file reads with zero other overhead. If some windows internal process or S. M. A. R. T probes the disks and that throws the algorithm off guard then I consider that a bug. At least I as senior developer see zero reason why not to improve the algorithm and offer a feature that enforces concurrent single file reads from all available copies. It looks to me that the app is already capable of performing striped reads it is just that the algorithm seems to currently overweigh availability to multiple transfers over single transfer optimization . Given my assessment is true then this is something a capable developer can solve in a few days and it would offer a feature hardly any other competitor offers. (read striping across user specified numbers of mirrors at throughout that approach n * single disk throughput.)
-
I tried that and did not get much of a speed up even with 4 drives and 4 copies of all files, one copy on each drive. I copied a folder of multiple larger files and I could not tease the "secret" algorithm to bite. Nor did it seem to recognize the advantage of multiple copies when I initiated 2 different file transfers. Picking optimum drives is ok if it is intended. Constantly switching between drives and reading then from random drives at 5 megabytes per second and 130 mb/second from other drives in a completely unpredictable random like fashion for a single large file transfer rakes of a big fat bug. But I understand that the overall intend seems to be different from optimizing throughput (though it's still not clear to me what the intend really is judging from the actual behavior of the software).
-
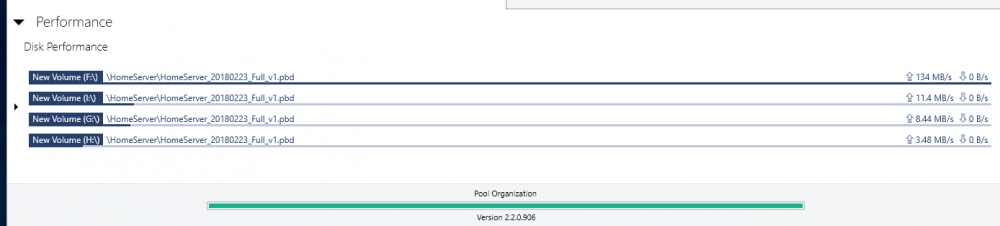
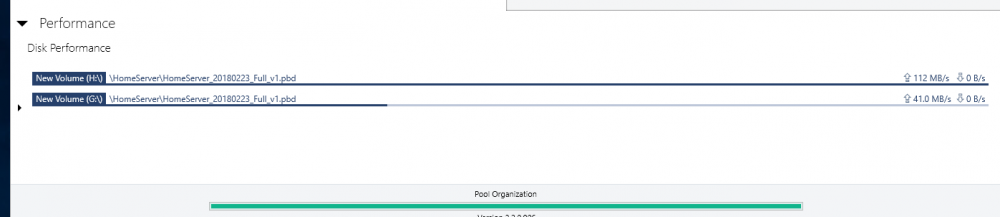
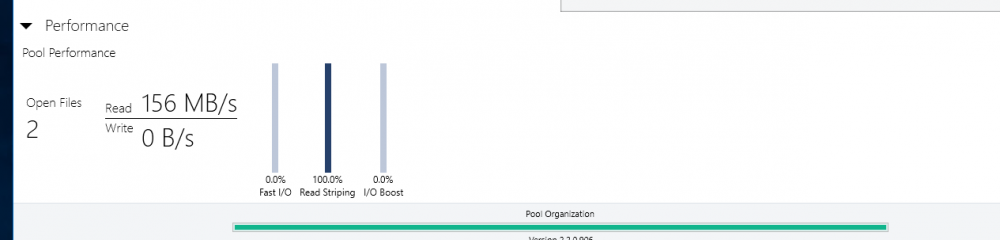
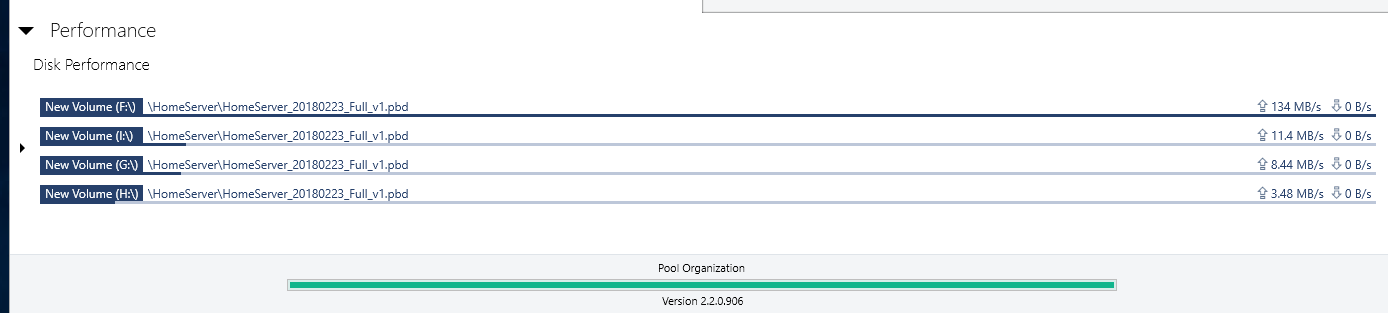
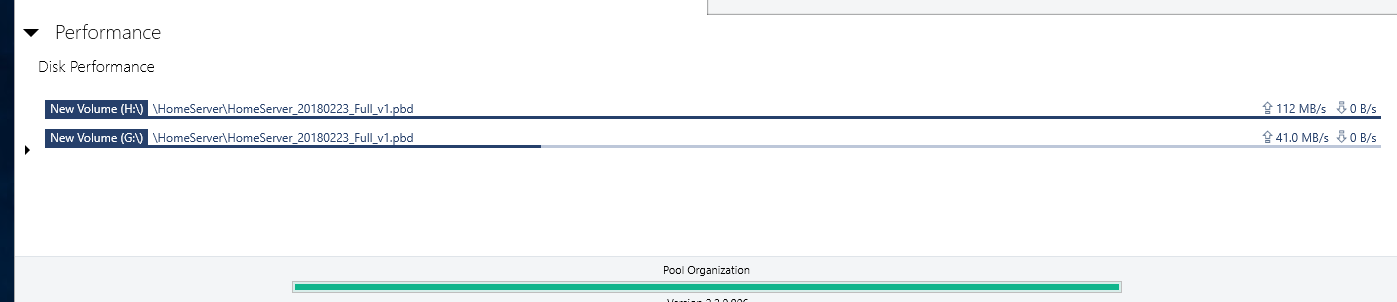
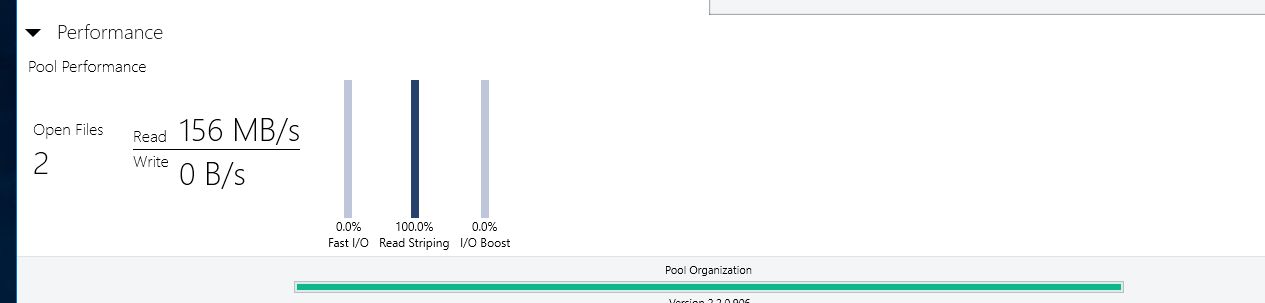
Thank you but this does not explain the erratic behavior I described and documented with screenshots. No other I/O takes place on those drives other than this single file transfer. Also all disks are 100% identical in terms of latencies and even if they differed it does not make sense that the software constantly switches and reads from different combinations of drives but never from all at the same time. Also it makes no sense for the algorithm to choose one or more drives and to then read at some abysmally slow throughput rates from some drives at the same time as reading at higher throughput from another driver. Seconds later different drive combinations are picked for combined reading and the choice of drives is in a seemingly random fashion and random individual throughput. This happens constantly throughout a large single file transfer. I am describing some wild switching back and forth around 100 or more times for a single file read of size 10 gigabytes or so and ending up at almost the exact time, consumed, as if I read from a single disk. That is complete waste of resources and if you insist this is intended behavior then I don't know what else to say. I am absolutely sure this is unintended, at the very least I would not know of a single use case where this would make sense. I am OK you don't consider this a bug but I am somewhat unconvinced by your explanation because it does not account for the erratic behavior I explained. In any case, if I cannot enforce parallel/concurrent reads from all drives in the pool then this is not the product I am looking for. I just took the time to reply to point out that this is most likely a bug.
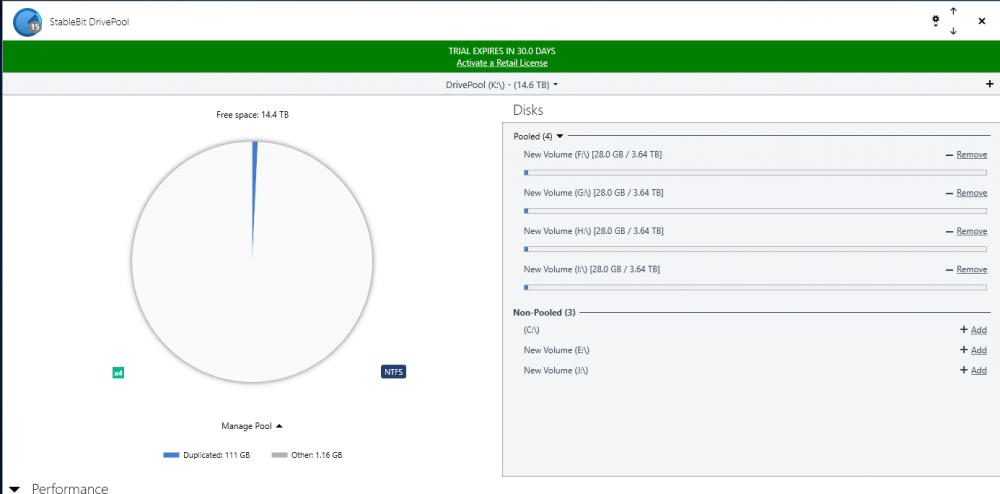
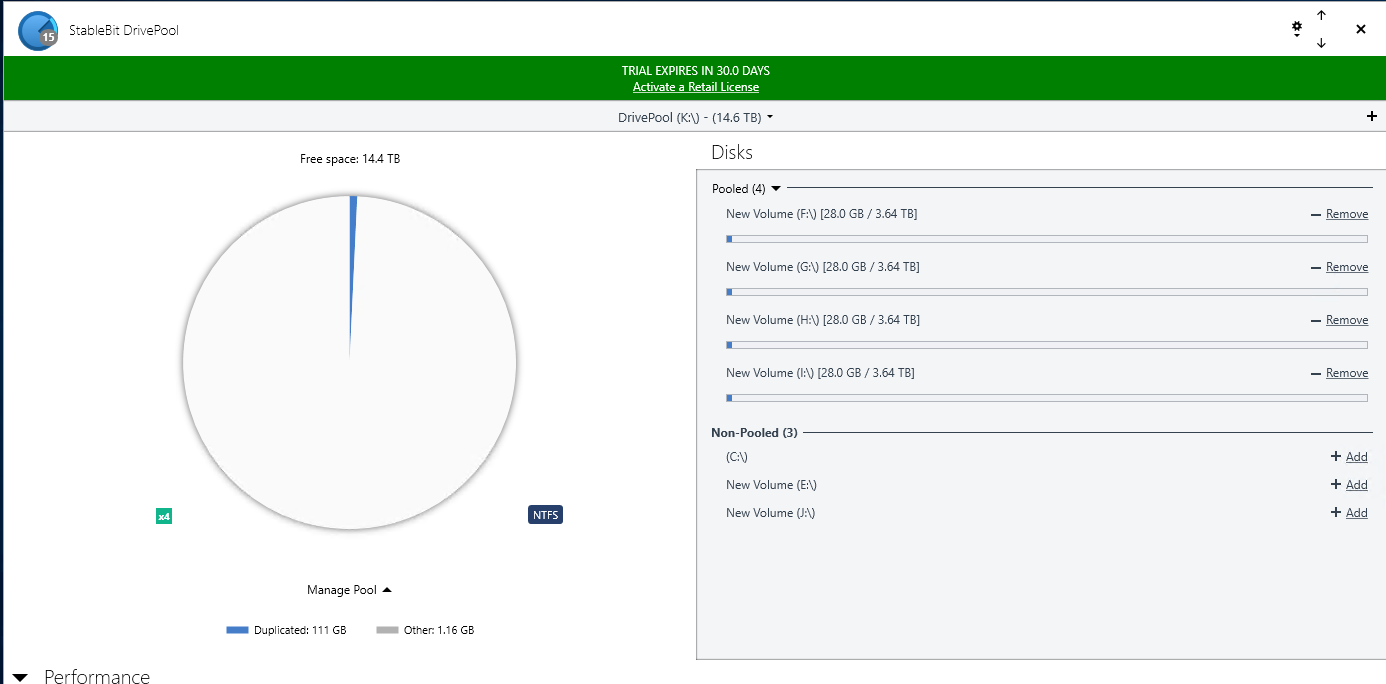
-
Hi, I am currently evaluating DrivePool and mostly consider it because of its advertised read striping feature. However, there seems to be a bug or an existing bug (I have read related issues by other users dating back to 2015) has never been fixed. Here is my setup: I run on the latest Windows 10, 4 HDDs (WD Re 4TB, 170 Megabytes/second read performance for sequential data), which I pooled and chose 4x duplication. I copied several files and folders onto the pool and selected the following options: * Duplication -Enabled * Number Duplications: 4 ( I verified that the files and folders are in fact on each of the 4 hard drives - so DrivePool did its job at duplicating the data written into the pool) * Read Striping - Enabled * Realtime-Duplication - Enabled *Bypass file system filters - Enabled * File Protection - Pool File Duplication I ensured the data are in fact on each of the 4 drives. I then copied a single large file and also an entire directory, containing several multi GB large files to an NVME SSD drive (1.8 GB write performance so definitely no bottleneck here) with the same disappointing result: File transfer speed maxes out at around 150 Megabytes per second. Here some observations: * Initially I could see how only one drive was read from. But what points me to hint at this being bug (or at least a highly undesirable solution) is that DrivePool then jumped all over the place by reading for a second or two from 2 drives, then 2 others, then 3, then 1, then all four in a completely unpredictable manner. When >1 drives were read from the read performance on each individual drive most of the time dropped to <10 mb/second though 1 drive had larger throughput (not always the same drive). All in all, the read performance stayed relatively stable between 140-150 mb/second, but read striping is definitely not working as intended or desired on my end. With 4x duplication I expect at the very least 400 mb/sec throughput when reading identical data from 4 drives. Please note that all 4 HDDs are 100% identical brands/models/capacity. All are on 1 SATA 6 controller. I also eliminated the possibility of bottlenecks of my hardware components. I setup a Windows StorageSpaces Simple Virtual Disk with 4 columns (basically striping across all 4 HDDs) and I got a persistent read performance above 600 megabytes/second when reading from the virtual disk that comprised the 4 HDDs in Storage Space's Raid0 version. So, definitely no bottlenecks on my hardware/SATA controller/HDDs. What particularly worries me is the inconsistent jumping between different drives in the pool when reading in (read-striping enabled mode). Whether this is a bug in read-striping itself or a bug in the evaluation of the controller bandwidth or a an advanced setting that has to be enabled but is not by default I do not know, but I know that the current read-striping is not what is promised. Could some of you share whether this feature works for you and what throughput increase you see when you read from 2x, 3x, 4x, ... duplicated files in your pools? Also if the developer or support could chime in this would be awesome. I am urgently looking for a product that provides read-performance improvements and mirrored data resiliency at the same time. But I cannot consider this product for purchase with such currently abysmal read-striping performance. Any hints are welcome and maybe it is just me who overlooked a setting or feature that needs to be enabled but which I forgot to enable.