


Jellepepe
-
Posts
45 -
Joined
-
Last visited
-
Days Won
4
Posts posted by Jellepepe
-
-
Well... The issue has reappeared for me - same failures with the same messages.
Dns is already on google dns for this VM so that can't be the issue now.
Do you also experience the same again @Chupa?
If anyone has any insight that would be great
EDIT:
Seems to indeed be the same issue again, manually adding dns records for the www.googleapis.com domain has seemingly resolved the issue.
I assume there is some hetzner customer(s) abusing the google api endpoints causing them to automatically rate limit the hetzner ip ranges, which is also affecting other users - very frustrating.
Not sure there is any way for us to 'fix' this reliably -
I see quite good plex scanning and matching behaviour, so I will describe my setup, hopefully it helps.
I have multiple clouddrives pooled together using drivepool (I don't think this affects scanning but It is worth mentioning)
My clouddrive is running in a windows server 2022 VM (Hyper-v) with 8gb of dedicated ram and 8 dedicated threads (ryzen 9 5950x)
The cache is running from (a virtual disk on-) a pcie gen 4 nvme ssd.
Each individual drive is set to the following:
Chunk size 20MB
Cache chunk size 100MB
Cache Size: 10GB Expandable
File system: NTFS
Data duplication: Pinned data only
Upload verification: Enabled
Pin directories: Enabled
Pin metadata: Enabled
Download threads: 5
Upload threads: 5
Background IO: Enabled
Throttling disabled
Upload threshold: 1MB or 5 minutes
Minimum download size: 20MB
Prefetch trigger: 1MB
Prefetch trigger time window: 30 seconds
Prefetch forward: 100MB
From these, it seems to me that either the prefetch trigger or the pinning might be the cause of the slow scanning/matching.
It is worth noting that plex now includes a feature that detects intros in tv shows (to allow you to skip them) which takes a pretty decently long time to detect, it could also be that this is what you are seeing. If you continue having issues I could share my plex settings with you as well.
-
On 2/2/2023 at 11:04 AM, Vexus said:
Hi, i have the same problem, was the Hetzner support any help? thanks
The issue was resolved for me by changing the dns provider to either cloudflare or google and flushing the dns cache as described above, this will likely work for you too.
I contacted hetzner support to notify them of the issue and they indicated that they could not detect any issues with the dns server (which makes sense since it is not a resolving issue, the issues is perhaps that it is resolving to rate limited servers leading to the errors we are seeing, which is hard to test for)
They also mentioned that they were still looking into the issue and were contacting google to see if they can find the issue.
My personal guess is that the Hetzner dns uses a custom dns resolving for google services to optimize their endpoint usage (a lot of major datacenters do this for major providers like google or amazon AWS) - these google drive endpoints seem to be (perhaps erroneously) rate-limiting access, which is leading to the errors we are seeing.
Whether this issue is due to an issue on googles side (erroneous rate limiting) or on hetzners side (stale dns records pointing to incorrect endpoints) is unclear at this point, but I assume the issue will be determined soon once Hetzner gets into contact with google.
For the time being we can just switch to a different dns provider for google drive api access -
Thank you!!!
I was having this same exact error, though intermittently (about 10-20% of requests were going through without issue) so I did not suspect DNS to be the culprit.
I also already had cloudflare as my secondary DNS server so I assumed any dns failures would be covered. Access to google drive through other tools seemed unaffected. I suppose the hetzner dns is not failing the dns but somehow providing stale data for the specific api endpoint clouddrive is using.
For future reference I also needed to flush my dns cache for clouddrive to start working again, this is done using the command:
ipconfig /flushdns
in an (elevated) command prompt window.
I will also submit a ticket to Hetzner support to make them aware of the issue (my server is in FSN, is that the case for yours as well? @Chupa)
I suggest in the meantime perhaps renaming this topic to include hetzner in the title so others with the same issue can find it easily")
-
1 hour ago, Jellepepe said:
My guess is the new system no longer moves existing files and instead just makes sure any new changes are put in new folders?
That does make sense as it would avoid having to move a shit ton of files, and avoids the issue (as it seems to only affect writing new files, and does not affect existing files)Seems I was correct, existing files are untouched and new files are stored according to the new system, hopefully this remains working as it saves a lot of moving around
-
So i just mounted a 16TB drive with around 12TB used (which has the issue) on .1314
the 'upgrading' screen took less than 5 seconds, and the drive mounted perfectly within a few seconds.
it has now been 'cleaning up' for about 20minutes, and it is editing and deleting some files as expected, but im a little worried it did not do any actual upgrading.
I noticed in the web interface all it did was rename the chunk folder to '<id>-CONTENT-HIERARCHICAL' and created a new '<id>-CONTENT-HIERARCHICAL-P' folder.
but this new folder is empty and no files are being moved/have been moved.My guess is the new system no longer moves existing files and instead just makes sure any new changes are put in new folders?
That does make sense as it would avoid having to move a shit ton of files, and avoids the issue (as it seems to only affect writing new files, and does not affect existing files)
Once the status is green and it has definitely stopped doing anything i will test to see if the drive is now functional on my own api keys... -
I had the wisdom 2 years ago when one of the ssds in my server corrupted and took almost a full 50TB of data in a clouddrive with it, that i would mirror all my data over multiple clouddrives and multiple google accounts, i am very happy with my past self at this stage.
I will start a staged rollout of this process on my drives and keep you updated if i find any issues.
-
13 minutes ago, kird said:
you mean "The limit for this folder's number of children (files and folders)" that rule is not new at all, contrary to what some here are saying.
why do you say that? i am many times over the limit and never had any issues until a few weeks ago.
I was also unable to find any documentation or even mention of it when i first encountered the issue, and even contacted google support who were totally unaware of any such limits.
fast forward 2 weeks later and more people start having the same 'issue' and suddenly we can find documentation on it from googles side.
3 hours ago, darkly said:welp, maybe it's just a matter of time then . . . Does anyone have a rough idea when google implemented this change? Hope we see a stable, tested update that resolves this soon.
I first encountered the issue on June 4th I believe, and I have found no mention of anyone having it before then anywhere, it was also the first time the devs had heard of it (i created a ticket on the 6th). I seems like it was a gradual roll out as it initially happened on only one of my accounts, and gradually spread, with others also reporting the same issue.
3 hours ago, darkly said:Any idea if what I suggested in my previous post is possible? I have plenty (unlimited) space on my gdrive. I don't see why it shouldn't be possible for CloudDrive to convert the drive into the new format by actually copying the data to a new, SEPARATE drive with the correct structure, rather than upgrading the existing drive in place and locking me out of all my data for what will most likely be a days long process . . .
it would be possible, but there is a 750gb/day upload limit, so even moving a (smallish
 ) 50TB drive would take well over 2 months to move.
) 50TB drive would take well over 2 months to move.
Currently, moving the chunks, the only bottleneck (should be) the api request limit, which corresponds to a lot more data per day.
That said, it is possible to do this manually by disabling the migration for large drives in settings, creating a new drive on the newer version, and to start copying. -
6 hours ago, Chase said:
on the drive that has completed the upgrade. I can see and access my data but when I try to change my I/O performance on that drive it tells me "Error saving data. Cloud drive not found"
EDIT: Prefetch is not working
This indeed sounds like a bug, the update was probably rushed quite a bit and i doubt it was tested extensively.
Be sure to submit a support ticket so the developers are aware and can work on resolving all the issues -
Just to clarify for everyone here, since there seems to be a lot of uncertainty:
-
The issue (thus far) is only apparent when using your own api key
- However, we have confirmed that the clouddrive keys are the exception, rather than the other way around, as for instance the web client does have the same limitation
- Previous versions (also) do not conform with this limit (and go WELL over the 500k limit)
- Yes there has definitely been a change at googles side that implemented this new limitation
-
Although there may be issues with the current beta (it is a beta after all) it is still important to convert your drives sooner rather than later, here's why:
- Currently all access (api or web/googles own app) respects the new limits, except for the clouddrive keys (probably because they are verified)
- Since there has been no announcement from google that this change was happening, we can expect no such announcement if (when) the clouddrive key also stops working either
- It may or may not be possible to (easily) convert existing drives if writing is completely impossible (if no api keys work)
- If you don't have issues now, you don;t have to upgrade, instead wait for a proper release, but do be aware there is a certain risk associated.
I hope this helps clear up some of the confusion!
-
The issue (thus far) is only apparent when using your own api key
-
4 hours ago, steffenmand said:
Maybe this is related to the issues we have with Internal Error etc. if we are already above the 10 TB mark. Then it fails when trying to write new chunks because we are already above the 10 TB mark
I also doubt this is related to this issue. I have well over 10TB used and i have never had a 'internal error' error.
The only errors i have seen are user rate limit exceeded (when exceeding the upload or download limits) and since about 2 weeks this exceeded maximum number of children error.
-
This issue appeared for me over 2 weeks ago (yay me) and it seems to be a gradual rollout.
The 500.000 items limit does make sense, as clouddrive stores your files in (up to) 20mb chunks on the provider, and thus the issue should appear somewhere around the 8-10tb mark depending on file duplication settings.
In this case, the error actually says 'NonRoot', thus they mean any folder, which apparently can now only have a maximum of 500.000 children.I've actually been in contact with Christopher since over 2 weeks ago about this issue, and he has informed Alex of the issue and they have confirmed they are working on a solution.
(other providers already has such issues, and thus it will likely revolve around storing chunks in subfolders with ~100.000 chunks per folder, or something similar.)It is very interesting that you mention reverting to the non-personal api keys resolved it for you, which does suggest that indeed it may be dependent on some (secret) api level limit.
Though, that would not explain why adding something to the folder manually also fails...
@JulesTop Have you tried uploading manually since the issue 'disappeared' ? If that still fails, it would confirm that the clouddrive api keys are what are 'overriding' the limit, and any personal access, including web, is limited.Either way hopefully there is a definitive fix coming soon, perhaps until then using the default keys is an option.
-
So i saw this notice;
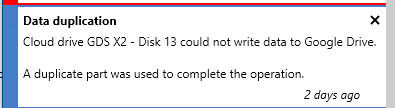
And i am curious to learn what it means, from what i understand a duplicate part could not help when there is a write issue?
I'm probably misunderstanding something and the drive is fine otherwise i am just curious what it is actually doing.
-
On 12/24/2019 at 1:45 AM, Bowsa said:
Contacted them... is anyone else getting this error? Has occurred more than 20 times now, where the chunk is unavailable both in my local and duplicate drive.
All that data lost...
Sounds to me like you may just have a failing drive in your system or a really shitty network connection causing corruption. A drive definitely should not normally introduce corruption without something affecting the data.
-
1 hour ago, kird said:
For those who have two Google drive accounts in different domains in the same program (StablebitCD), how can we indicate in the .json file the two APIs generated for each account? Or how should we do it in this case?
I do not believe that is it currently possible to use two different API keysets for seperate drives within 1 clouddrive installation
On 12/18/2019 at 11:09 AM, Historybuff said:And while i sounded angry really i was just a bit flustered and worried and cannot really see how i could protect myself from loosing my data.
back up the data, google drive cannot provide the amount of data integrity assurance you seem to be looking for and should not ever be the only place you store any data you mind losing.
-
just set up your downloader to download to a local drive and move the completed downloads to the cloud drive..?
-
Hi, if you (like me) are struggling to mount a clouddrive to your system due to cache drive limitations, this might be a (workaround) solution;
-
Hi everyone,
After dreading that i would have to add an additional drive to my server to be able to mount my clouddrives (which would cost me a lot, as it is not local to me), I tried a lot of possible workarounds.
While i understand the reasoning for not allowing certain drives to be pooled, and I do not recommend doing this unless you understand the risks, I am happy to report it definitely works, with no issues in my testing.
So a as a TL;DR;
You can create a VHD(X) file on a dynamic volume, mount that, then create a storage space with this mounted VHD(X) file, which can then be pooled and/or used as clouddrive cache.
The performance decrease is quite minor, as you can see from some quick testing on a old 840 evo drive;

[LEFT: local disk mounted directly, RIGHT: mounted VHDX -> Storage Space -> Drivepool]
Step-By-Step:
Doing this is easy, and it only takes a few steps;
- Create the VHD(X) file
- Mount the VHD(X) file as a drive
- Create a storage space with the mounted VHD(X) drive(s)
- Use the storage space as clouddrive cache or add it to a drivepool pool
1. First we make the VHD(X) file if you do not have one yet, which we can simply do from disk manager; Action -> Create VHD
you are then presented with the following prompt, in which you can choose the size and location of the VHD(X)
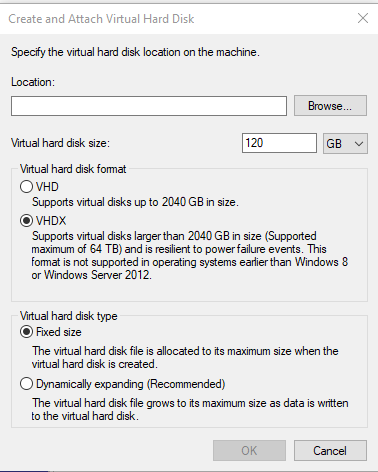
For optimal performance it is recommended to choose 'VHDX' and 'Fixed size'
2. Next we need to mount the VHD file if it hasn't done so already, which we can also do from disk manager; Action -> Mount VHD
We don't need to initialize or format the drive, it will undo this in the next step anyway.
3. Almost done! We now need to create a storage space, as the mounted VHD(X) still cannot be used by clouddrive/drivepool
To do this, we open the storage spaces configuration screen (search 'storage spaces'), and choose 'create a new pool and storage space'
in the following screen select the mounted VHD drive ("Attached via VHD"), which should show up under "Unformatted drives" be careful to not select a different drive, this will wipe all data!
In the wizard we can now select the size, parity settings, and format settings, in this example we are using 'simple', but you can choose other settings if you're using multiple VHDs.
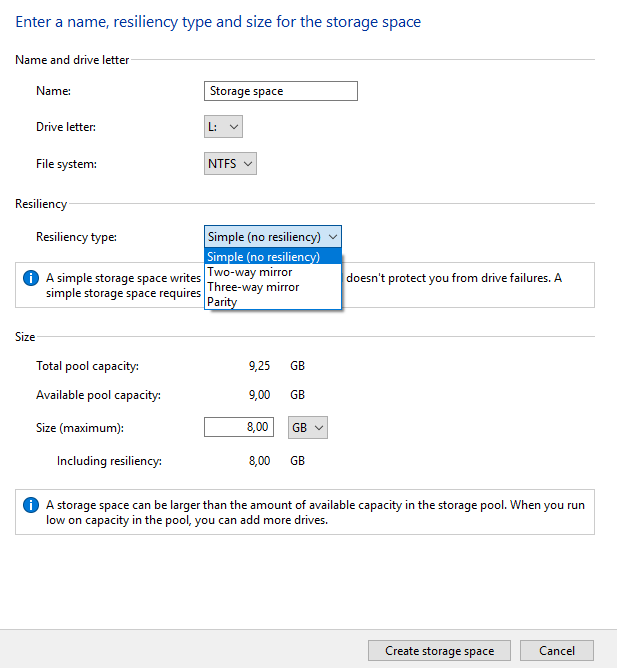
4. If everything went well, we should now be able to detect the new storage space drive in both clouddrive and drivepool, ready to be used!
And we are done!
For some reason because we created a storage space, we no longer need to manually mount the VHD drives on reboot, so the system keeps working.
-
This really is not an intended use case for this software...
I guess i dont really understand why you need the extra step of the clouddrive and cannot just directly download the files from your vps to your computer?
If storage is an issue you could permanently mount the clouddrive to the vps, and access the files through there from your main computer without mounting the drive right?
I might be misunderstanding the situation

-
open task manager, go to services and find the service 'CloudDriveService' , it is probably 'Stopped'.
Rightclick and choose start, that should fix the issue.
If you get the message that it is disabled, press 'Open Services' on the bottom of the task manager window, then find 'StableBit CloudDrive Service' and open its properties.
Here make sure it is set to 'Automatic' instead of Disabled/Manual - then try to start it again.
If that also fails i'm not sure but you could try look in the service log to see if there is any reported issues.
19 hours ago, pedges said:Am I going to lose all the data on my drives, and how can I prevent this in the future?
As long as the encryption key (if the drives are encrypted) is stored somewhere safe, you won't lose data.
Do make sure to not delete or modify any files in the clouddrive folders on whichever provider the drives are stored on
-
8 hours ago, chrillex said:
Question number two. I have big problems with disconnects when uploading to my GSuite container. I do have to manually reconnect it many times during a 100GB upload (~20 * 5GB files). Chunk size is set to 20MB and here are the other settings:
you say the drive disconnects when uploading your files? what is the error you get when this happens?
8 hours ago, chrillex said:The third question is also about my GSuite container. Whenever I upload anything my connection to internet is totally killed for all other clients in my LAN. I can't even browse any sites. Which settings should I use? I've got a 100Mbit/100Mbit connection. Settings see above.
have you tried running a speedtest to see your actual connection speed? this sounds like either your connection isnt actually able to handle 100mbps or some router/switch is having a hard time. clouddrive will use as much of the 85mbps limit you set, so if your real world speeds are 90mbps or lower the rest of your network will have a hard time keeping a solid connection
4 minutes ago, Jaga said:I'll leave the tuning and disconnect questions for someone with more Cloud Drive experience (a.k.a. Christopher).
") Though I will say this: if you are planning on a 5TB Cloud Drive, you'd do yourself a big favor figuring out why it's disconnecting, since it'll be much more difficult to keep a 5TB volume current compared to a 100GB volume.
Though I will say this: if you are planning on a 5TB Cloud Drive, you'd do yourself a big favor figuring out why it's disconnecting, since it'll be much more difficult to keep a 5TB volume current compared to a 100GB volume.
currently running 2 100TB volumes from 2 seperate google drives mirrored using drivepool (w/ ssd cache), so i feel like i have some experience
 but it will be important to figure out the cause first
but it will be important to figure out the cause first
-
On 17/11/2017 at 11:17 PM, ntilegacy said:
Yeah. The changes for .953 only state :
.953 * Fixed rare performance sampling error.
... I don't know what this means.... Do you think that as anything to do with our recent problem?
I was away all weekend, so sorry for not posting. Im not sure, i checked and im still running .951, so i doubt its related.
The issues have seemed to go away, i can see it struggle still during the general 7-10pm window, but its not enough to force a dismount of the drive.
This mostly leads me to believe it was some sort of issue at google, but it does disappoint we never managed to figure out exactly what the cause was.
I will get back to this if theres any more issues, and if you or anyone else is having a similar issue please do so also
-
1 minute ago, ntilegacy said:
Hello
No dismounts yet....... in the meantime i update cloudrive to latest beta 953 ...... and can be just me, but seems that things run much better with this latest beta.... today i made a big stress test (upload very big files, download very big files , watch 2 movies at same time , update emby library .... everything at the same time on diferent drives and somethings on same drive .... and no problems at all)
At 8:24 i have a red flag notice on one drive (drive can not download data on timely maner blah blah) and that's all.
i had the same at that time, but not enough to dismount, its 22:48 for me now, so past the window it has dismounted all previous days.
It would seem like today is the first day in over a month that i havent had any dismounts, i REALLY hope this means the issue was at google and is now resolved.
i also switched to using the latest beta builds around when i posted this thread, i also noticed performance seemingly being much better. i assume something changed in the way I/O works?
-
Drives just dismounted again (19:42)
issue definitely isnt gone
EDIT:
They only dismounted the one time, so there seems to be an improvement :?


Problems with Google Drive in Hetzner server
in General
Posted
Right, as I mentioned the errors are the same as before, the 429 error is an endpoint rate limit error. The endpoints that are returned by the dns (at first only Hetzners own dns, but it seems now also the ones returned by Google and Cloudflare dns. What exactly is the cause of these endpoint rate limits is unclear though, presumably something on the Hetzner network is producing an abusive amount of requests which results in the endpoints rate limiting the entire Hetzner ip ranges.
@Christopher (Drashna) Perhaps it would be possible to add a slightly more comprehensive error handling for 429 errors for the google drive provider? E.g. a clearer error message and more aggressive backoff behaviour (perhaps limit the entire provider connection to 1-2 threads & disable auto-remount) It seems the current implementation doesn't deal with this situation super well as a small amount of requests do still succeed. I am seeing some filesystem corruption (luckily recoverable) due to my drives brute force trying to get through the throttling almost a full day before I was able to manually unmount them & diagnose the issue.
Right, this is what I mentioned in the edit to my post. Manually adding dns records to other endpoints that are not rate limiting is a temporary workaround.
This is definitely not ideal though as when not relying on dns there is no way to guarantee these won't become stale & these won't be the closest endpoints to begin with. Let alone the original issue of whatever is causing the rate limiting to begin with may very well appear here as that service/actor may also start abusing other endpoints
Why are you trying to apply this if the speed is normal without adding these records? this is a temporary workaround for a rate limit error, the speeds I'm seeing with the rate limit active is a few kb/s at most (and 90%+ failures)
The speed being lower is normal as this is manually targeting the 'wrong' google api endpoints, which are likely not very close / connected ideally to the Hetzner data center.
Your friend likely isn't using a Hetzner server or at least not at the same location. I'm only seeing the error in Hetzner Falkenstein (FSN1), I'm not sure if its only that datacenter or the entire Hetzner ip ranges.
There's not really any way for us to actively fix this issue. Hetzner and/or Google are the only ones able to identify the cause of the rate limiting and stop it, and they are likely both going to blame the other party and say they are the ones that should fix it. We can try opening a ticket with either/both but I'm not very hopeful.